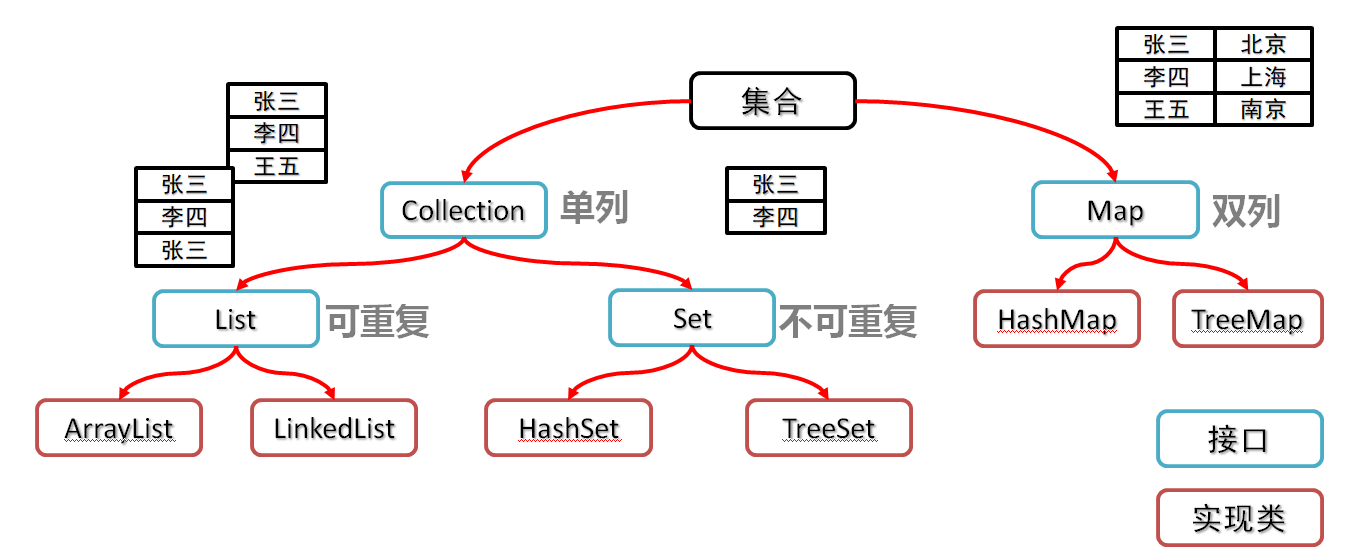
Collection集合
Collection集合
-
都是容器,可以存储多个数据
-
不同点
-
数组的长度是不可变的,集合的长度是可变的
-
数组可以存基本数据类型和引用数据类型
-
-
迭代器,集合的专用遍历方式
-
Iterator<E> iterator(): 返回此集合中元素的迭代器,通过集合对象的iterator()方法得到
-
-
Iterator中的常用方法
boolean hasNext(): 判断当前位置是否有元素可以被取出 E next(): 获取当前位置的元素,将迭代器对象移向下一个索引位置
-
public class IteratorDemo1 { public static void main(String[] args) { //创建集合对象 Collection<String> c = new ArrayList<>(); //添加元素 c.add("hello"); c.add("world"); c.add("java"); c.add("javaee"); //Iterator<E> iterator():返回此集合中元素的迭代器,通过集合的iterator()方法得到 Iterator<String> it = c.iterator(); //用while循环改进元素的判断和获取 while (it.hasNext()) { String s = it.next(); System.out.println(s); } } }
增强for循环【应用】
-
-
它是JDK5之后出现的,其内部原理是一个Iterator迭代器
-
实现Iterable接口的类才可以使用迭代器和增强for
-
简化数组和Collection集合的遍历
-
-
格式
for(集合/数组中元素的数据类型 变量名 : 集合/数组名) {
// 已经将当前遍历到的元素封装到变量中了,直接使用变量即可
}
- 代码
public class MyCollectonDemo1 { public static void main(String[] args) { ArrayList<String> list = new ArrayList<>(); list.add("a"); list.add("b"); list.add("c"); list.add("d"); list.add("e"); list.add("f"); //1,数据类型一定是集合或者数组中元素的类型 //2,str仅仅是一个变量名而已,在循环的过程中,依次表示集合或者数组中的每一个元素 //3,list就是要遍历的集合或者数组 for(String str : list){ System.out.println(str); } } }
-
栈结构
先进后出
-
队列结构
先进先出
数据结构之数组和链表【记忆】
-
数组结构
查询快、增删慢
-
队列结构
Java 的集合中给出了底层结构采用哈希表数据结构的实现类,按照时间顺序分别为第一代Hashtable、第二代 HashMap、第三代 ConcurrentHashMap(concurrent 并发)。相同点:底层结构都是哈希表,都是用来存储 key-value 映射,都实现了 Map 接口。



Hashtable 线程安全,但是效率太低,底层使用 synchronized 同步方法,已不再使用。HashMap 线程不安全, 效率提升, 适用单线程情况下。可以借助 Collections. synchronziedMap()保证线程安全, 底层使用 synchronized 同步代码块,效率比Hashtable 高。在大量并发情况下如何提高集合的效率和安全呢? ConcurrentHashMap:JDK7 底层采用 Lock 锁,但是 JDK8 的 ConcurrentHashMap 不使用 Lock 锁,而是使用了CAS + synchronized 代码块锁。保证安全的同时,性能均也很高。
哈希值【理解】
-
是JDK根据对象的地址或者字符串或者数字算出来的int类型的数值
-
如何获取哈希值
Object类中的public int hashCode():返回对象的哈希码值
-
哈希值的特点
-
同一个对象多次调用hashCode()方法返回的哈希值是相同的
-
-
-
节点个数少于等于8个
数组 + 链表
-
节点个数多于8个
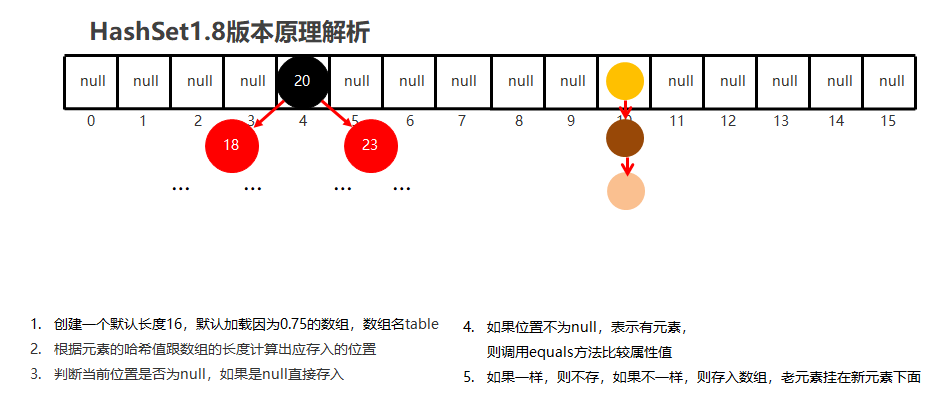
哈希冲突
如果两个不同的元素,通过哈希函数得出的实际存储地址相同怎么办?
也就是说,当我们对某个元素进行哈希运算,得到一个存储地址,然后要进行插入的时候,发现已经被其他元素占用了,其实这就是所谓的哈希冲突,也叫哈希碰撞。
那么哈希冲突如何解决呢?
哈希冲突的解决方案有多种:
开放定址法(发生冲突,继续寻找下一块未被占用的存储地址),再散列函数法,链地址法,而HashMap即是采用了链地址法,也就是数组+链表的方式。
1.1、List集合子类的特点【记忆】
-
ArrayList集合
底层是数组结构实现,查询快、增删慢
-
LinkedList集合
ArrayList 数据结构:底层实现是object数组(动态数组,可以扩容),它的随机访问速度极快,但是插入和删除的操作需要移动数组中的元素,比较麻烦。
注意:(1)它在没有初始化长度的时候,默认长度是10
(2)如果向ArrayLIst添加元素,超过了原来的容量,那么扩容方案:扩容到原数组的1.5倍,如果扩容完之后还是小于返回到mincapacity(最小容量)
(3)ArrayList是线程不安全的,在多线程的情况下不要使用
如果非要使用list,就推荐使用vector,它基本上和ArrayList一样,区别在于vector中大部分方法都使用了同步关键字synchronized修饰,这样在多线程不会出现并发错误,扩容区别vector默认扩容就是原来的2倍。
ArrayList遍历的几种方式:1:使用foreach遍历list 2:将list转化为数组,在进行遍历 3:使用迭代器遍历
linkedlist的add方法添加元素的操作:
LInkedList添加操作时每个新添加的对象都会被放到新建的Node对象中,Node对象中包含加入的对象和前后指针属性(pred和next,pred和next其实都是Node对象,直接存放的就是当前对象的前一个节点对象和后一个节点对象,最后一个及节点的next值为null),然后将原来最后一个last节点的next指针指向新加入的对象。
linkedlist的get方法,查询元素:
判断给定的索引值,若索引值大于整个链表长度的一半,则从后往前找,若索引值小于整个链表的长度的一般,则从前往后找。 这样就可以保证,不管链表长度有多大,搜索的时候最多只搜索链表长度的一半就可以找到,大大提升了效率。
2.1、Set集合概述和特点【应用】
-
不可以存储重复元素
-
没有索引,不能使用普通for循环遍历
2.2、TreeSet集合概述和特点【应用】
-
不可以存储重复元素
-
没有索引
-
可以将元素按照规则进行排序
-
TreeSet():根据其元素的自然排序进行排序
-
-
2.3、HashSet集合概述和特点【应用】
-
底层数据结构是哈希表
-
存取无序
-
不可以存储重复元素
-
没有索引,不能使用普通for循环遍历
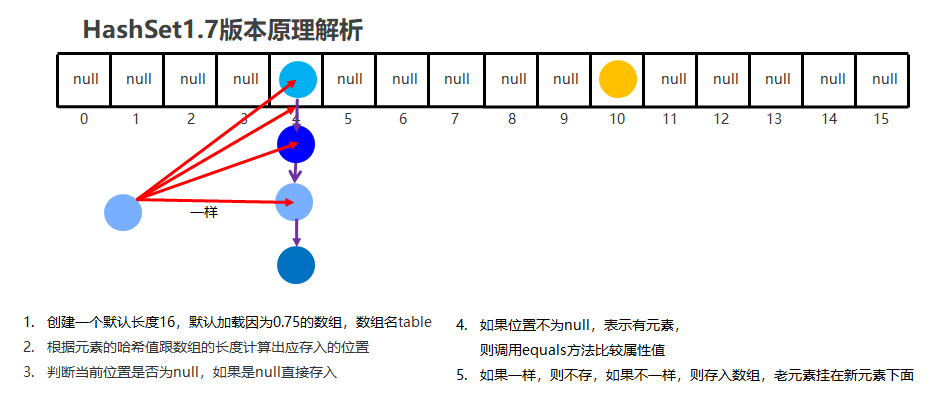
hashset存储原理?
1、将要传入的数据根据系统的hash算法得到一个hash值
2、根据hash值计算出数据在hash表中的位置
3、判断该位置是否有值,没有值就将数据插入进来,如果有值则再次判断传入的值与已经存储的值的equals结果是否相同,如果相同则不存,如果不相同则通过单链表的形式存储
判断hashset中是否是重复的对象?
先判断两个对象的hashcode是否相同(如果两个对象的hashcode相同,不一定是一个对象,如果两个对象的hashcode不同,一定不是一个对象)如果两个hashcode相同,在进行equals方法判断,如果equals相同则是同一个对象,如果equals判断不相同,那么就不是一个对象
3.1、Map集合概述和特点【理解】
-
Map集合概述
interface Map<K,V> K:键的类型;V:值的类型
- Map集合的特点
- 双列集合,一个键对应一个值
- 键不可以重复,值可以重复
-
HashMap底层是哈希表结构的
-
依赖hashCode方法和equals方法保证键的唯一
-
HashMap的内部结构
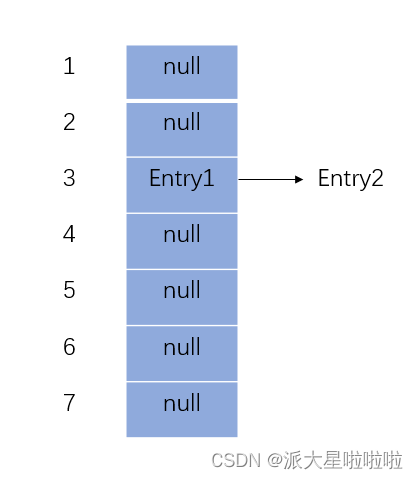
HashMap是数组加链表组成的复合结构,HashMap的主干是数组,其中数组被分为一个个桶(bucket),每个桶存储有一个或多个键值对,每个键值对也称为 Entry ,通过哈希值决定了Entry对象在这个数组的下标;哈希值相同的Entry对象(键值对),则以链表形式存储。HashMap中数组长度的原始大小为16,且数组的初始值都为null,默认的负载因子为0.75。当HashMap中元素个数超过容量乘以负载因子的个数时,就创建一个大小为前一次两倍的新数组,再将原来数组中的数据复制到新数组中。
当数组长度到达64且链表长度大于8时,链表转为红黑树。
JDK1.7月JDK1.8中HashMap的区别
在jdk1.7中HashMap主要结构为:数组+链表。
在jdk1.8中HashMap主要结构为:数组+链表+红黑树。
为什么要加入红黑树呢?学过的人都应该知道,红黑树查询是非常快的。
设想一个情况,当我们插入的Entry非常多时,我们的链表会长的可怕,这个时候去遍历链表寻找对应的key,所花费的时间可想而知的恐怖。
加入红黑树可以优化查询的时间,使查询效率快上不少。
那么在jdk1.8的HashMap中,当数组长度到达64且链表长度大于8时,链表会自动转化为红黑树,优化查询速度。
同时还有一个区别:发生“hash冲突”时,我们上面的做法是“头插法”,这是jdk1.7的做法,而在jdk1.8中,使用的是“尾插法”。
hashmap是如何插入数据:
(1)、先判断数组是否为空,要是为空,初始化数组,可以自定义数组大小(默认是16),先根据数据的key,求出哈希值
(2)、再将此数据的hash值取余(%)数据的长度(默认长度是16),得到数据对应的下标
(3)、再根据下标,将数据插入数组中对应的位置(此时我们要考虑是否要扩容,如果容量超过数组大小的0.75倍,就需要扩容,最大容量是2的30次方)
(4)、如果插入数据时,发现此下标对应位置已经有元素,我们有两种办法(hashmap使用链表法):
1)链表:那么我们就要用到hashmap的单链表了。将这个数据的next指针(指针域)指向此下标对应的节点,作为链表的头部,再将这个节点放到此下标对应的数组的位置,便成功插入数据。如果说下标对应的位置上有链表。此时,就会拿着k和链表上每个节点的k进行equal。如果所有的equals方法返回都是false,那么这个新的节点将被添加到链表的末尾。如其中有一个equals返回了true,那么这个节点的value将会被覆盖。
2)再次求哈希值,再取余,一直求到下标对应的位置为空,插入数据
注意:我们插入数据之前会判断key是否存在,利用for循环,从该数据对应下标的链表的头部,开始比较key值,如果我们插入数据的key和链表某个节点的key相同,那么我们将老的value返回出去,将新的value插入进去覆盖老的value
- 当我们调用
put(key, value)方法将键值对存入HashMap时,HashMap会先对键进行哈希操作,通过哈希函数将键映射为一个整数值。 - 接着,通过该整数值计算出具体的存储位置索引。如果该位置上已经存在其他键值对,则可能会发生哈希碰撞(两个不同的键映射到了同一个索引位置)。
- 在发生哈希碰撞时,HashMap会使用一种链表或红黑树等数据结构来解决碰撞问题,将碰撞的键值对添加到对应位置的链表或树中。
- 如果哈希表中不存在碰撞,则直接将键值对存储在对应的位置处。
hashmap取出数据:
(1)、先根据数据的key,求出哈希值
(2)、再将此数据的hash值取余(%)数据的长度(默认长度是16),得到数据对应的下标
(3)、再根据下标,去数组中找出对应位置的数据,利用将数组中数据的key和自己搜索的数据的key相比较,如果相等就返回value。如果第一次找的不是自己想要的数据,便根据此节点的指针,去链表下一个节点找数据,直到找到为止,返回数据的value
- 当我们调用
get(key)方法来获取键对应的值时,HashMap首先对键进行哈希操作,然后通过哈希函数计算出存储位置的索引。 - 如果该位置上存在哈希碰撞(即链表或树不为空),HashMap会遍历该链表或树,根据键的equals方法进行比较,直到找到对应的键值对。
- 如果找到了匹配的键值对,则返回对应的值;如果没有找到匹配的键值对,则返回null。
-
TreeMap底层是红黑树结构
-
依赖自然排序或者比较器排序,对键进行排序
-
interface Map<K,V> K:键的类型;V:值的类型

 浙公网安备 33010602011771号
浙公网安备 33010602011771号