
Java讲义第四章学习笔记
chapter 4 流程控制与数组
4.1 顺序结构
顺序结构就是程序从上到下逐行地执行,中间没有任何判断和跳转。
4.2 分支结构
Java 提供了两种常见的分支控制结构:if语句和switch语句,其中if语句使用布尔表达式或布尔值作为分支条件来进行分支控制;而switch语句则用于对多个整型值进行匹配,从而实现分支控制。
--4.2.1 if条件语句
形式1:
if( logic expression )
{
statement...
}
形式2:
if( logic expression )
{
statement...
}
else
{
statement...
}
形式3:
if( logic expression )
{
statement...
}
else if( logic expression )
{
statement...
}
// .....
else
{
statement...
}
注意:使用 if...else...语句时,一定要先处理包含范围更小的情况。
--4.2.2 Java 11 改进的 switch 分支语句
switch 语句由一个控制表达式和多个 case 标签组成和 if 语句不同的是,switch 语句后面的控制表达式的数据类型只能由byte、short、char、int四种整数类型,枚举类型和java.lang.String 类型,不能是 boolean 类型。
switch语句往往需要在case标签后紧跟一个代码块,case标签作为这个代码块的标识。形式如下:
switch (expression)
{
case condition1:
{
statement(s);
break;
}
case condition2:
{
statement(s);
break;
}
case condition3:
{
statement(s)
break;
}
default:
{
statement(s)
}
}
这种分支语句的执行是先对 expression 求值,然后依次匹配condition1、condition2、condition3、...、conditionN等值,遇到匹配的值即执行体;如果所有case标签后的值都不与expression表达式的值相等,则执行default标签后的代码块。
和if语句不同的是,switch语句中各case标签后代码块的开始点和结束点非常清晰,因此完全可以省略case后代码块的花括号。与if语句中的else类似,switch语句中的default标签看似是没有条件的,其实是有的,条件就是expression表达式的值不能与前面任何一个case标签后的值相等。
从Java 7开始增强了 switch 语句的功能,允许 switch 语句的控制表达式是java.lang.String类型的变量或表达式———只能是java.lang.String类型,不能是StringBuffer 或 StringBuilder 这两种字符串类型。
public class StringSwitchTest
{
public static void main(String[] args)
{
//声明变量season
var season = "夏天";
//执行 switch 分支语句
switch(season)
{
case "春天":
System.out.println("春暖花开.");
break;
case "夏天":
System.out.println("夏日炎炎.");
break;
case "秋天":
System.out.println("秋高气爽.");
break;
case "冬天":
System.out.println("冬雪皑皑.");
break;
default:
System.out.println("季节输入错误");
}
}
}
4.3 循环结构
--4.3.1 while 循环语句
[init_statement]
while (test_expression)
{
statement;
[iteration_statement]
}
--4.3.2 do while 循环语句(至少执行一次)
do while 循环与 while 循环的区别在于:while循环是先判断循环条件,如果循环条件为真则执行循环,而 do while 循环则先执行循环体,然后才判断循环条件,如果循环条件为真,则执行下一次循环,否则终止循环。do while 循环的语法格式如下:
[init_statement]
do
{
statement;
[iteration_statement]
}while (test_expression);
与while循环不同的是,do while 循环的循环条件后必须有一个分号,这个分号表明循环结束。
--4.3.3 for循环
for([init_statement];[test_expression];[iteration_statement])
{
statement;
}
--4.3.4 嵌套循环
public class NestedLoopTest
{
public static void main(String[] args)
{
//外层循环
for(var i = 0;i < 5;i++)
{
//内层循环
for(var j = 0;j < 3;j++)
{
System.out.println("i的值为:" + i + " j的值为:" +j);
}
}
}
}
以上为两层嵌套循环,原则上还可以更多层。
4.4 控制循环结构
--4.4.1 使用 break 结束循环
某些时候需要在出现时强行终止循环,而不是等到循环条件为 false 时才退出循环。此时,可以使用 break 来完成这个功能。break用于完全结束一个循环,跳出循环体。不管是哪种循环,一旦在循环体中遇到break,系统将完全结束该循环,开始执行循环后的代码。
public class BreakTest
{
public static void main(String[] args)
{
//一个简单的for循环
for(var i =0; i < 10; i++)
{
System.out.println("i的值是" + i);
if(i == 2)
{
//执行该句话时将结束循环
break;
}
}
}
}
break 语句不仅可以结束其所在的循环,还可以直接结束其外层循环。此时需要在 break 后跟一个标签,这个标签用于表示一个外层标签。
Java中的标签就是一个紧跟着英文冒号(:)的标识符。与其他语言不同的是,Java中的标签只有放在循环语句之前才有作用。
public class BreakLabel
{
public static void main(String[] args)
{
//外层循环,outer作为标识符
outer:
for(var i = 0; i < 5;i++)
{
//内层循环
for(var j = 0;j < 3;j++)
{
System.out.println("i的值为:" + i +" j的值为:" +j);
if(j == 1)
{
//跳出outer标签所标识的循环
break outer;
}
}
}
}
}
运行上面程序,看到如下运行结果:
i 的值为:0 j的值为:0 i 的值为:0 j的值为:1
程序从外层循环进入内层循环后,当 j 等于 1 时,程序遇到一个break outer ;语句,这行代码将会导致结束outer标签指定的循环,不是结束 break 所在的循环,而是结束 break 循环的外层循环。所以看到上面的运行结果。
值得提出的是,break后的标签必须在 break 语句所在的循环之前定义,或者在其所在循环的外层循环之前定义。当然,如果把这个标签放在 break 语句所在的循环之前定义,也就失去了标签的定义,因为 break 默认就是结束其所在循环。
--4.4.2 使用 continue 忽略本次循环剩下语句
continue 的功能和 break 有点相似,区别是 continue 只是忽略本次循环剩下语句,接着开始下一次循环,并不会终止循环;而 break 则是完全终止循环本身。
与 break 相似的是,continue后也可以紧跟一个标签,用于直接跳过标签所标识循环的当次循环的剩下语句,重新开始下一次循环。
public class ContinueLabel {
public static void main(String[] args)
{
//外层循环
outer:
for(int i = 0;i < 5;i++) {
//内层循环
for(int j = 0;j < 3;j++)
{
System.out.println("i 的值为:" + i + " j的值为:" + j);
if(j == 1)
{
//忽略outer标签所指定的循环中本次循环所剩下的语句
continue outer;
}
}
}
}
}
运行上面程序可以看到,循环变量 j 的值将无法超过1,因为每当 j 等于1时,continue outer;语句就结束了外层循环的当次循环,直接开始下一次循环,内层循环没有机会执行完成。
与 break 类似的是,continue 后的标签也必须是一个有效标签,即这个标签通常应该放在 continue 所在循环的外层循环之前定义。
--4.4.3 使用 return 结束方法
return 关键字并不是专门用于结束循环的,return 的功能是结束一个方法。当一个方法执行到一个 return 语句时,这个方法将被结束。
4.5 数组类型
--4.5.1 理解数组:数组也是一种类型
Java的数组要求所有的数组元素具有相同的数组类型。因此,在一个数组中,数组元素的类型是唯一的,即一个数组里只能存储一种数据类型的数据,而不能存储多种数据类型的数据。
一旦数组的初始化完成,数组在内存中所占空间将被固定下来,因此数组的长度将不可改变。即使把某个数组元素的数据清空,但它所占的空间依然被保留,依然属于该数组,数组的长度依然不变。
Java的数组既可以存储基本类型的数据,也可以存储引用类型的数据,只要所有的数组元素都具有相同类型。值得提出的是,数组也是一种数据类型,它本身是一种引用类型。例如int 是一个基本类型,int[](这是定义数组的一种方式) 就是一种引用类型。创建int[]类型的对象也就是创建数组,需要使用创建数组的语法。
--4.5.2 定义数组
Java语言最标准的定义数组格式:type[] arrayName
理解: 定义一个变量,变量名为 arrayName。数组是一种引用类型的变量,因此使用它定义一个变量时,仅仅表示定义了一个引用变量(也就是定义了一个指针),这个引用变量还未指向任何有效的内存,因此定义数组时不能指定数组的长度。而且由于定义数组只是定义了一个引用变量,并未指向任何有效的空间,所以还没有内存空间来存储数组元素,因此这个数组也不能使用,只有对数组进行初始化后才能使用。
--4.5.3 数组的初始化
所谓初始化,就是为数组的数组元素分配内存空间,并为每个数组元素赋初始值。

数组的初始化有如下两种方式。
静态初始化:初始化时由程序员显式指定每个数组元素的初始值,由系统决定数组长度。
动态初始化:初始化时程序员只指定数组长度,由系统为数组元素分配初始值。
1.静态初始化
静态初始化的语法格式如下:
arrayName = new type[]{element1, element2, element3, element4 ...}
除此之外,静态初始化还有如下简化的语法格式:
arrayName = {element1, element2, element3, element4 ...}
在这种语法格式中,直接使用花括号来定义一个数组,花括号把所有的数组元素括起来形成一个数组。
在实际开发过程中,可能更习惯将数组定义和数组初始化同时完成,代码如下(程序清单同上):
//数组的定义和初始化同时完成,使用简化的静态初始化写法
int[] a = {5, 6, 7, 9};
2.动态初始化
动态初始化只指定数组的长度,由系统为每个数组元素指定初始值。动态初始化的语法格式如下:
arrayName = new type[length];
在上面语法中,需要指定一个int类型的length参数,这个参数指定了数组的长度,也就是可以容纳数组元素的个数。与静态初始化相似的是,此处的type必须与定义数组时使用的type类型相同,或者是定义数组时使用的type类型的子类。
//数组的定义和初始化同时完成,使用动态初始化语法 int[] prices = new int[5]; //数组的定义和初始化同时完成,初始化数组时元素的类型是定义数组时元素类型的子类 Object[] books = new String[4];
执行动态初始化时,程序员只需指定数组的长度,即为每个数组元素指定所需的内存空间,系统将负责为这些数组元素分配初始值。指定初始值时,系统按如下规则分配初始值。
- 数组元素的类型是基本类型中的整数类型(byte、short、int和long),则数组元素的值是0。
- 数组元素的类型是基本类型中的浮点类型(float、double),则数组元素的值是0.0。
- 数组元素的类型是基本类型中的字符类型(char),则数组元素的值是'\u0000'。
- 数组元素的类型是基本类型中的布尔类型(boolean),则数组元素的值是false。
- 数组元素的类型是引用类型(类、接口和数组),则数组元素的值是null。
注意:不要同时使用静态初始化和动态初始化,也就是说,不要在进行数组初始化时,既指定数组的长度,也为每个数组元素分配初始值。
--4.5.4 使用数组
数组最常用的用法就是访问数组元素,包括对数组元素进行赋值和取出数组元素的值。访问数组元素都是通过在数组引用变量后紧跟一个方括号([]),方括号里是数组元素的索引值,这样就可以访问数组元素了。访问到数组元素后,就可以把一个数组元素当成一个普通变量使用了,包括为该变量赋值和取出该变量的值,这个变量的类型就是定义数组时使用的类型。
值得指出的是,Java语言的数组索引是从0开始的,也就是说,第一个数组元素的索引值为0,最后一个数组元素的索引值为数组长度减1。
--4.5.5 foreach 循环
从Java 5之后,Java提供了一种更简单的循环:foreach循环,这种循环遍历数组和集合(关于集合的介绍请参考本书第8章)更加简洁。使用foreach循环遍历数组和集合元素时,无须获得数组和集合长度,无须根据索引来访问数组元素和集合元素,foreach循环自动遍历数组和集合的每个元素。
foreach循环的语法格式如下:
for(type variableName : array | collection)
{
//variableName自动迭代访问每个元素...
}
在上面语法格式在中,type是数组元素或集合元素的类型,variableName是一个形参名,foreach循环将自动将数组元素、集合元素依次赋给该变量。下面程序示范了如何使用foreach循环来遍历数组元素。
public class ForEachTest
{
public static void main(String[] args)
{
String[] books = {"轻量级Java EE企业应用实战" ,
"疯狂Java讲义",
"疯狂Android讲义"};
//使用foreach循环来遍历数组元素
//其中book将会自动迭代每个数组元素
for (String book : books)
{
System.out.println(book);
}
}
}
从上面程序可以看出,使用foreach循环遍历数组元素时无须获得数组长度,也无须根据索引来访问数组元素。foreach循环和普通循环不同的是,它无须循环条件,无须循环迭代语句,这些部分都由系统来完成,foreach循环自动迭代数组的每个元素,当每个元素都被迭代一次后,foreach循环自动结束。
当使用foreach循环来迭代输出数组元素或集合元素时,通常不要对循环变量进行赋值,虽然这种赋值在语法上是允许的,但没有太大的实际意义,而且极易引起错误。例如下面程序:
public class ForEachErrorTest
{
public static void main(String[] args)
{
String[] books = {"轻量级Java EE企业应用实战" ,
"疯狂Java讲义",
"疯狂Android讲义"};
//使用foreach循环来遍历数组元素,其中book将会自动迭代每个数组元素
for (String book : books)
{
book = "疯狂Ajax讲义";
System.out.println(book);
}
System.out.println(books[0]);
}
}
运行上面程序,将看到如下运行结果:
疯狂Ajax讲义 疯狂Ajax讲义 疯狂Ajax讲义 轻量级Java EE企业应用实战
从上面运行结果来看,由于我们在foreach循环中对数组元素进行赋值,结果导致不能正确遍历数组元素,不能正确地取出每个数组元素的值。而且当再次访问第一个数组元素时,发现数组元素的值依然没有改变。不难看出,当使用foreach来迭代访问数组元素时,foreach中的循环变量相当于一个临时变量,系统会把数组元素依次赋给这个临时变量,而这个临时变量并不是数组元素,它只是保存了数组元素的值。因此,如果希望改变数组元素的值,则不能使用这种foreach循环。
4.6 深入数组
--4.6.1 内存中的数组
数组引用变量只是一个引用,这个引用变量可以指向任何有效的内存,只有当该引用指向有效内存后,才可通过该数组变量来访问数组元素。
与所有引用变量相同的是,引用变量是访问真实对象的根本方式。也就是说,如果我们希望在程序中访问数组对象本身,则只能通过这个数组的引用变量来访问它。
实际的数组对象被存储在堆(heap)内存中;如果引用该数组对象的数组引用变量是一个局部变量,那么它被存储在栈(stack)内存中。
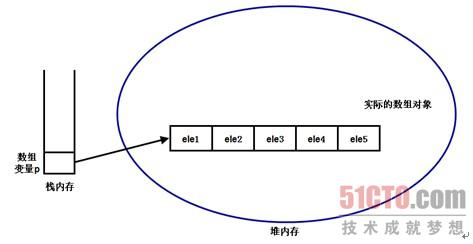 如果需要访问图所示堆内存中的数组元素,则程序中只能通过p[index]的形式实现。也就是说,数组引用变量是访问堆内存中数组元素的根本方式。
如果需要访问图所示堆内存中的数组元素,则程序中只能通过p[index]的形式实现。也就是说,数组引用变量是访问堆内存中数组元素的根本方式。

如果堆内存中数组不再有任何引用变量指向自己,则这个数组将成为垃圾,该数组所占的内存将会被系统的垃圾回收机制回收。因此,为了让垃圾回收机制回收一个数组所占的内存空间,可以将该数组变量赋为null,也就切断了数组引用变量和实际数组之间的引用关系,实际的数组也就成了垃圾。
只要类型相互兼容,就可以让一个数组变量指向另一个实际的数组,这种操作会让人产生数组的长度可变的错觉。如下代码所示:
public class ArrayInRam
{
public static void main(String[] args)
{
//定义并初始化数组,使用静态初始化
int[] a = {5, 7 , 20};
//定义并初始化数组,使用动态初始化
int[] b = new int[4];
//输出b数组的长度
System.out.println("b数组的长度为:" + b.length);
//循环输出a数组的元素
for (int i = 0 ,len = a.length; i < len ; i++ )
{
System.out.println(a[i]);
}
//循环输出b数组的元素
for (int i = 0 , len = b.length; i < len ; i++ )
{
System.out.println(b[i]);
}
//因为a是int[]类型,b也是int[]类型,所以可以将a的值赋给b。
//也就是让b引用指向a引用指向的数组
b = a;
//再次输出b数组的长度
System.out.println("b数组的长度为:" + b.length);
}
}
运行上面代码后,将可以看到先输出b数组的长度为4,然后依次输出a数组和b数组的每个数组元素,接着会输出b数组的长度为3。看起来似乎数组的长度是可变的,但这只是一个假象。必须牢记:定义并初始化一个数组后,在内存中分配了两个空间,一个用于存放数组的引用变量,另一个用于存放数组本身。下面将结合示意图来说明上面程序的运行过程。
当程序定义并初始化了a、b两个数组后,系统内存中实际上产生了4块内存区,其中栈内存中有两个引用变量:a和b;堆内存中也有两块内存区,分别用于存储a和b引用所指向的数组本身。此时计算机内存的存储示意图如图所示。
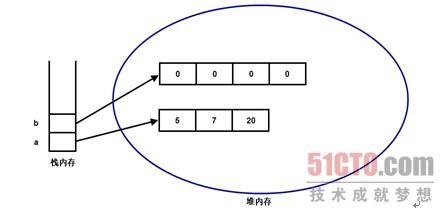
从上图中可以非常清楚地看出a引用和b引用各自所引用的数组对象,并可以很清楚地看出a变量所引用的数组长度是3,b变量所引用的数组长度是4。
当执行上面的粗体字标识代码b = a时,系统将会把a的值赋给b,a和b都是引用类型变量,存储的是地址。因此把a的值赋给b后,就是让b指向a所指向的地址。此时计算机内存的存储示意图如下图所示。
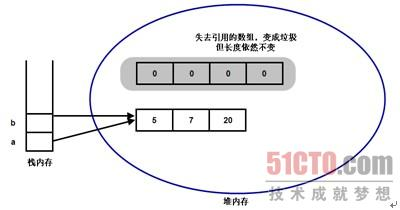
从图中可以看出,当执行了b = a之后,堆内存中的第一个数组具有了两个引用:a变量和b变量都引用了第一个数组。此时第二个数组失去了引用,变成垃圾,只有等待垃圾回收机制来回收它--但它的长度依然不会改变,直到它彻底消失。
提示:程序员进行程序开发时,不要仅仅停留在代码表面,而要深入底层的运行机制,才可以对程序的运行机制有更准确的把握。当我们看一个数组时,一定要把数组看成两个部分:一部分是数组引用,也就是在代码中定义的数组引用变量;还有一部分是实际的数组对象,这部分是在堆内存里运行的,通常无法直接访问它,只能通过数组引用变量来访问。
--4.6.2 基本类型数组的初始化
对于基本类型数组而言,数组元素的值直接存储在对应的数组元素中,因此,初始化数组时,先为该数组分配内存空间,然后直接将数组元素的值存入对应数组元素中。
下面程序定义了一个int[]类型的数组变量,采用动态初始化的方式初始化了该数组,并显式为每个数组元素赋值。
public class PrimitiveArrayTest
{
public static void main(String[] args)
{
//定义一个int[]类型的数组变量
int[] iArr;
//动态初始化数组,数组长度为5
iArr = new int[5];
//采用循环方式为每个数组元素赋值
for (int i = 0; i <iArr.length ; i++ )
{
iArr[i] = i + 10;
}
}
}
上面代码的执行过程代表了基本类型数组初始化的典型过程。下面将结合示意图详细介绍这段代码的执行过程。
执行第一行代码int[] iArr;时,仅定义一个数组变量,此时内存中的存储示意图如图所示:
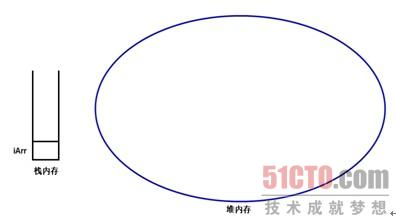
执行了int[] iArr;代码后,仅在栈内存中定义了一个空引用(就是iArr数组变量),这个引用并未指向任何有效的内存,当然无法指定数组的长度。
当执行iArr = new int[5];动态初始化后,系统将负责为该数组分配内存空间,并分配默认的初始值:所有数组元素都被赋值为0,此时内存中的存储示意图如图所示:
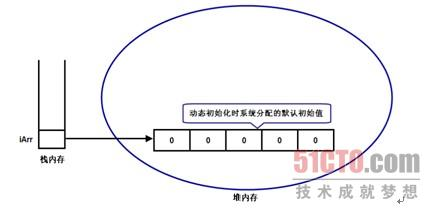
此时iArr数组的每个数组元素的值都是0,当循环为该数组的每个数组元素依次赋值后,此时每个数组元素的值都变成程序显式指定的值。显式指定每个数组元素值后的存储示意图如图所示:
 从图中可以看到基本类型数组的存储示意图,每个数组元素的值直接存储在对应的内存中。操作基本类型数组的数组元素时,实际上就是操作基本类型的变量。
从图中可以看到基本类型数组的存储示意图,每个数组元素的值直接存储在对应的内存中。操作基本类型数组的数组元素时,实际上就是操作基本类型的变量。
--4.6.3 引用类型数组的初始化
引用类型数组的数组元素是引用,因此情况变得更加复杂。每个数组元素里存储的还是引用,它指向另一块内存,这块内存里存储了有效数据。
为了更好地说明引用类型数组的运行过程,下面先定义一个Person类(所有类都是引用类型)。
class Person
{
//年龄
public int age;
//身高
public double height;
//定义一个info方法
public void info()
{
System.out.println("我的年龄是:" + age
+ ",我的身高是:" + height);
}
}
下面程序将定义一个Person[]数组,接着动态初始化这个Person[]数组,并为这个数组的每个数组元素指定值。
public class ReferenceArrayTest
{
public static void main(String[] args)
{
//定义一个students数组变量,其类型是Person[]
Person[] students;
//执行动态初始化
students = new Person[2];
//创建一个Person实例,并将这个Person实例赋给zhang变量
Person zhang = new Person();
//为zhang所引用的Person对象的age、height赋值
zhang.age = 15;
zhang.height = 158;
//创建一个Person实例,并将这个Person实例赋给lee变量
Person lee = new Person();
//为lee所引用的Person对象的age、height赋值
lee.age = 16;
lee.height = 161;
//将zhang变量的值赋给第一个数组元素
students[0] = zhang;
//将lee变量的值赋给第二个数组元素
students[1] = lee;
//下面两行代码的结果完全一样,因为lee
//和students[1]指向的是同一个Person实例
lee.info();
students[1].info();
}
}
上面代码的执行过程代表了引用类型数组初始化的典型过程。下面将结合示意图详细介绍这段代码的执行过程。
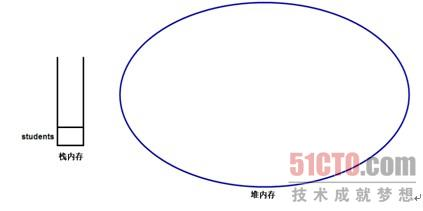
执行Person[] students;代码时,这行代码仅仅在栈内存中定义了一个引用变量,也就是一个指针,这个指针并未指向任何有效的内存区。此时内存中存储示意图如图所示:
在上图所示的栈内存中定义了一个students变量,它仅仅是一个引用,并未指向任何有效的内存。直到执行初始化,本程序对students数组执行动态初始化,动态初始化由系统为数组元素分配默认的初始值:null,即每个数组元素的值都是null。执行动态初始化后的存储示意图如图所示:
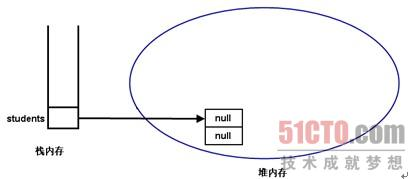
从图中可以看出,students数组的两个数组元素都是引用,而且这个引用并未指向任何有效的内存,因此每个数组元素的值都是null。这意味着依然不能直接使用students数组元素,因为每个数组元素都是null,这相当于定义了两个连续的Person变量,但这个变量还未指向任何有效的内存区,所以这两个连续的Person变量(students数组的数组元素)还不能使用。
接着的代码定义了zhang和lee两个Person实例,定义这两个实例实际上分配了4块内存,在栈内存中存储了zhang和lee两个引用变量,还在堆内存中存储了两个Person实例。此时的内存存储示意图如图所示:
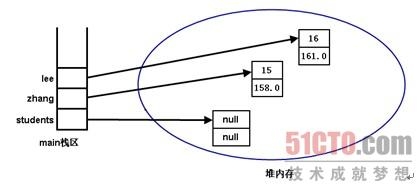
此时students数组的两个数组元素依然是null,直到程序依次将zhang赋给students数组的第一个元素,把lee赋给students数组的第二个元素,students数组的两个数组元素将会指向有效的内存区。此时的内存存储示意图如图所示:
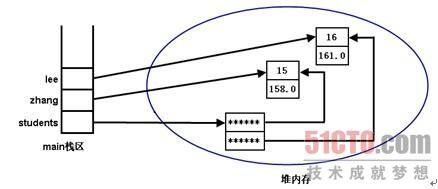
从图中可以看出,此时zhang和students[0]指向同一个内存区,而且它们都是引用类型变量,因此通过zhang和students[0]来访问Person实例的Field和方法的效果完全一样,不论修改students[0]所指向的Person实例的Field,还是修改zhang变量所指向的Person实例的Field,所修改的其实是同一个内存区,所以必然互相影响。同理,lee和students[1]也是引用同一个Person对象,也具有相同的效果。
--4.6.4 没有多维数组
Java语言里提供了支持多维数组的语法。但笔者还是想说,没有多维数组--如果从数组底层的运行机制上来看。
Java语言里的数组类型是引用类型,因此,数组变量其实是一个引用,这个引用指向真实的数组内存。数组元素的类型也可以是引用,如果数组元素的引用再次指向真实的数组内存,这种情形看上去很像多维数组。
回到前面定义数组类型的语法:type[] arrName;,这是典型的一维数组的定义语法,其中type是数组元素的类型。如果希望数组元素也是一个引用,而且是指向int数组的引用,则可以把type具体成int[](前面已经指出,int[]就是一种类型,int[]类型的用法与普通类型并无任何区别),那么上面定义数组的语法就是int[][] arrName。
如果把int这个类型扩大到Java的所有类型(不包括数组类型),则出现了定义二维数组的语法:
type[][] arrName;
Java语言采用上面的语法格式来定义二维数组,但它的实质还是一维数组,只是其数组元素也是引用,数组元素里保存的引用指向一维数组。
接着对这个"二维数组"执行初始化,同样可以把这个数组当成一维数组来初始化,把这个"二维数组"当成一个一维数组,其元素的类型是type[]类型,则可以采用如下语法进行初始化:
arrName = new type[length][]
上面的初始化语法相当于初始化了一个一维数组,这个一维数组的长度是length。同样,因为这个一维数组的数组元素是引用类型(数组类型)的,所以系统为每个数组元素都分配初始值:null。
这个二维数组实际上完全可以当成一维数组使用:使用new type[length]初始化一维数组后,相当于定义了length个type类型的变量;类似的,使用new type[length][]初始化这个数组后,相当于定义了length个type[]类型的变量,当然,这些type[]类型的变量都是数组类型,因此必须再次初始化这些数组。
下面程序示范了如何把二维数组当成一维数组处理。
public class TwoDimensionTest
{
public static void main(String[] args)
{
//定义一个二维数组
int[][] a;
//把a当成一维数组进行初始化,初始化a是一个长度为4的数组
//a数组的数组元素又是引用类型
a = new int[4][];
//把a数组当成一维数组,遍历a数组的每个数组元素
for (int i = 0 , len = a.length; i < len ; i++ )
{
System.out.println(a[i]);
}
//初始化a数组的第一个元素
a[0] = new int[2];
//访问a数组的第一个元素所指数组的第二个元素
a[0][1] = 6;
//a数组的第一个元素是一个一维数组,遍历这个一维数组
for (int i = 0 , len = a[0].length ; i < len ; i ++ )
{
System.out.println(a[0][i]);
}
}
}
上面程序中粗体字标识部分把a这个二维数组当成一维数组处理,只是每个数组元素都是null,所以我们看到输出结果都是null。下面结合示意图来说明这个程序的执行过程。
程序的第一行int[][] a;,将在栈内存中定义一个引用变量,这个变量并未指向任何有效的内存空间,此时的堆内存中还未为这行代码分配任何存储区。
程序对a数组执行初始化:a = new int[4][];,这行代码让a变量指向一块长度为4的数组内存,这个长度为4的数组里每个数组元素都是引用类型(数组类型),系统为这些数组元素分配默认的初始值:null。此时a数组在内存中的存储示意图如图所示:
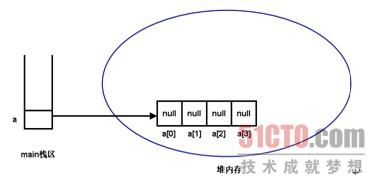 从图中看,虽然声明a是一个二维数组,但这里丝毫看不出它是一个二维数组的样子,完全是一维数组的样子。这个一维数组的长度是4,只是这4个数组元素都是引用类型,它们的默认值是null。所以程序中可以把a数组当成一维数组处理,依次遍历a数组的每个元素,将看到每个数组元素的值都是null。
从图中看,虽然声明a是一个二维数组,但这里丝毫看不出它是一个二维数组的样子,完全是一维数组的样子。这个一维数组的长度是4,只是这4个数组元素都是引用类型,它们的默认值是null。所以程序中可以把a数组当成一维数组处理,依次遍历a数组的每个元素,将看到每个数组元素的值都是null。
因为a数组的元素必须是int[]数组,所以接下来的程序对a[0]元素执行初始化,也就是让图4.12右边堆内存中的第一个数组元素指向一个有效的数组内存,指向一个长度为2的int数组。因为程序采用动态初始化a[0]数组,因此系统将为a[0]所引用数组的每个元素分配默认的初始值:0,然后程序显式为a[0]数组的第二个元素赋值为6。此时在内存中的存储示意图如图所示:
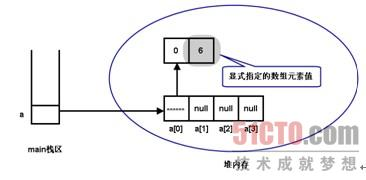
图中灰色覆盖的数组元素就是程序显式指定的数组元素值。TwoDimensionTest.java接着迭代输出a[0]数组的每个数组元素,将看到输出0和6。
 从上面程序中可以看出,初始化多维数组时,可以只指定最左边维的大小;当然,也可以一次指定每一维的大小。例如下面代码:
从上面程序中可以看出,初始化多维数组时,可以只指定最左边维的大小;当然,也可以一次指定每一维的大小。例如下面代码:
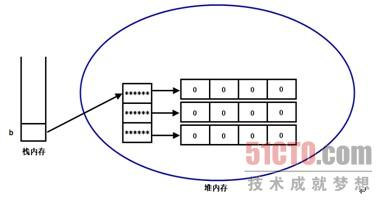
//同时初始化二维数组的两个维数 int[][] b = new int[3][4];
上面代码将定义一个b数组变量,这个数组变量指向一个长度为3的数组,这个数组的每个数组元素又是一个数组类型,它们各指向对应的长度为4的int[]数组,每个数组元素的值为0。这行代码执行后在内存中的存储示意图如图所示:
还可以使用静态初始化方式来初始化二维数组。使用静态初始化方式来初始化二维数组时,二维数组的每个数组元素都是一维数组,因此必须指定多个一维数组作为二维数组的初始化值。如下代码所示:
//使用静态初始化语法来初始化一个二维数组
String[][] str1 = new String[][]{new String[3]
, new String[]{"hello"}};
//使用简化的静态初始化语法来初始化二维数组
String[][] str2 = {new String[3]
, new String[]{"hello"}};
上面代码执行后内存中的存储示意图如图所示:
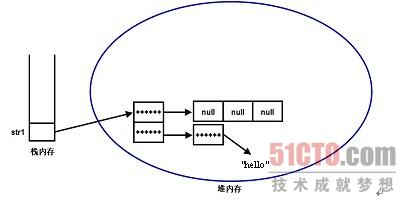
通过上面讲解,我们可以得到一个结论:二维数组是一维数组,其数组元素是一维数组;三维数组也是一维数组,其数组元素是二维数组;四维数组还是一维数组,其数组元素是三维数组……从这个角度来看,Java语言里没有多维数组。
--4.6.5 操作数组的工具类:Arrays
Java提供的Arrays类里包含的一些static修饰的方法可以直接操作数组,这个Arrays类里包含了如下几个static修饰的方法(static修饰的方法可以直接通过类名调用)。
- int binarySearch(type[] a, type key):使用二分法查询key元素值在a数组中出现的索引;如果a数组不包含key元素值,则返回负数。调用该方法时要求数组中元素已经按升序排列,这样才能得到正确结果。
- int binarySearch(type[] a, int fromIndex, int toIndex, type key):这个方法与前一个方法类似,但它只搜索a数组中fromIndex到toIndex索引的元素。调用该方法时要求数组中元素已经按升序排列,这样才能得到正确结果。
- type[] copyOf(type[] original, int newLength):这个方法将会把original数组复制成一个新数组,其中length是新数组的长度。如果length小于original数组的长度,则新数组就是原数组的前面length个元素;如果length大于original数组的长度,则新数组的前面元素就是原数组的所有元素,后面补充0(数值类型)、false(布尔类型)或者null(引用类型)。
- type[] copyOfRange(type[] original, int from, int to):这个方法与前面方法相似,但这个方法只复制original数组的from索引到to索引的元素。
- boolean equals(type[] a, type[] a2):如果a数组和a2数组的长度相等,而且a数组和a2数组的数组元素也一一相同,该方法将返回true。
- void fill(type[] a, type val):该方法将会把a数组的所有元素都赋值为val。
- void fill(type[] a, int fromIndex, int toIndex, type val):该方法与前一个方法的作用相同,区别只是该方法仅仅将a数组的fromIndex到toIndex索引的数组元素赋值为val。
- void sort(type[] a):该方法对a数组的数组元素进行排序。
- void sort(type[] a, int fromIndex, int toIndex):该方法与前一个方法相似,区别是该方法仅仅对fromIndex到toIndex索引的元素进行排序。
- String toString(type[] a):该方法将一个数组转换成一个字符串。该方法按顺序把多个数组元素连缀在一起,多个数组元素使用英文逗号(,)和空格隔开。
public class ArraysTest
{
public static void main(String[] args)
{
//定义一个a数组
int[] a = new int[]{3, 4 , 5, 6};
//定义一个a2数组
int[] a2 = new int[]{3, 4 , 5, 6};
//a数组和a2数组的长度相等,每个元素依次相等,将输出true
System.out.println("a数组和a2数组是否相等:"
+ Arrays.equals(a , a2));
//通过复制a数组,生成一个新的b数组
int[] b = Arrays.copyOf(a, 6);
System.out.println("a数组和b数组是否相等:"
+ Arrays.equals(a , b));
//输出b数组的元素,将输出[3, 4, 5, 6, 0, 0]
System.out.println("b数组的元素为:"
+ Arrays.toString(b));
//将b数组的第3个元素(包括)到第5个元素(不包括)赋值为1
Arrays.fill(b , 2, 4 , 1);
//输出b数组的元素,将输出[3, 4, 1, 1, 0, 0]
System.out.println("b数组的元素为:"
+ Arrays.toString(b));
//对b数组进行排序
Arrays.sort(b);
//输出b数组的元素,将输出[0, 0, 1, 1, 3, 4]
System.out.println("b数组的元素为:"
+ Arrays.toString(b));
}
}
Arrays类处于java.util包下,为了在程序中使用Arrays类,必须在程序中导入java.util.Arrays类。关于如何导入指定包下的类,请参考本书第5章。为了篇幅考虑,本书中的程序代码都没有包含import语句,读者可参考光盘里对应程序来阅读书中代码。
除此之外,在System类里也包含了一个static void arraycopy(Object src, int srcPos, Object dest, int destPos, int length)方法,该方法可以将src数组里的元素值赋给dest数组的元素,其中srcPos指定从src数组的第几个元素开始赋值,length参数指定将src数组的多少个元素值赋给dest数组的元素。
- void parallelPrefix(xxx[] array,XxxBinaryOperator op): 该方法使用op参数指定的计算公式计算得到的结果作为新的数组元素。op计算公式包括left、right两个形参,其中left代表新数组中前一个所引出的元素,right代表array数组中当前索引处的元素。新数组的第一个元素无须计算,直接等于array数组的第一个元素。
- void parallelPrefix(xxx[] array,int fromIndex,int toIndex,XxxBinaryOperator op):该方法与上一个方法相似,区别是该方法紧重新计算fromIndex到toIndex索引的元素。
- void setAll(xxx[] array,IntToXxxFunction generator):该方法使用指定的生成器(generator)为所有数组元素设置值,该生成器控制数组元素的值生成算法。
- void parallelSetAll(xxx[] array,IntToXxxFunction generator):该方法功能与上一个方法相同,只是该方法增加了并行能力,可以利用CPU并行来提升行能。
- void parallelSort(xxx[] a):该方法的功能与Array类以前有的sort()方法相似,只是该方法增加了并行能力,可以利用多CPU并行来提升行能。
- void parallel(xxx[] a,int fromIndex,int toIndex):该方法与上一个方法相似,区别是该方法仅对fromIndex到toIndex索引的元素进行排序。
- Spliterator.OfXxx spliterator(xxx[] array):将该数组的所有元素转换成对应的Spliterator对象。
- Spliterator.OfXxx spliterator(xxx[] array,int startInclusive,int endExclusive):该方法与上一个方法相似,区别是该方法仅转换startInclusive到endExclusive索引的元素。
public class Test
{
public static void main(String[] args) {
int[] arr1 = new int[] {3,-4,25,16,30,18};
//对数组arr1进行并发排序
Arrays.parallelSort(arr1);
System.out.println(Arrays.toString(arr1));
int[] arr2 = new int[] {3,-4,25,16,30,18};
Arrays.parallelPrefix(arr2, new IntBinaryOperator() {
//left代表新数组中前一个索引处的元素,right代表原数组中当前索引处的元素
//新数组的第一个元素总等于原数组的第一个元素
//两两相乘
@Override
public int applyAsInt(int left, int right) {
return left*right;
}
});
System.out.println(Arrays.toString(arr2));
int[] arr3 = new int[5];
Arrays.parallelSetAll(arr3, new IntUnaryOperator() {
//operand代表正在计算的元素索引
@Override
public int applyAsInt(int operand) {
return operand * 5;
}
});
System.out.println(Arrays.toString(arr3));
}
}
上述程序运行结果:
[-4, 3, 16, 18, 25, 30] [3, -12, -300, -4800, -144000, -2592000] [0, 5, 10, 15, 20]

