
正则表达式之旅_sed_awk
谈谈正则表达式这个东西:
我想作为一个程序员,正则表达式大家绝对不陌生。
正则表达式好像一个有限则动机。主要作用是匹配,但是同时因为这个功能,我们可以扩展很多其他用法
像很多语言都引人了正则表达式:java,C#等面向对象语言,更多的是脚本语言。
另外我们常用的一些工具都引入了这个正则表达式:sed,awk,gawk,grep
包括我们的C语言,它这种引入了一部分基础的正则表达式,我们一会会见到:
正则表达式是用正则表达式引擎实现的。正则表达式引擎是解释正则表达式模式并使用这些模式进行文字或者命令匹配的底层软件
学过编译原理的都知道DFA,和NFA的概念,这是我们编译过程中语法匹配的两大模式。他们的原理和正则表达式一样。
正则表达式就是根据这样分类:我们之关注Linux
在Linux,有两种流行的正则表达式引擎:
POSIX基本正则表达式引擎(BRE)
POSIX扩展正则表达式引擎(ERE)
大多数Linux工具都至少符合BRE
下面先看一下BRE基本成分,然后看看它在不同方面的不同应用
BRE主要有一些特殊字符组成:这些特殊字符有: .*[]^${}\+?|(),下面我们一一学习:但是有一点特殊:不能直接使用单斜线(/)要用反义字符表示包括除法符号(/)
1,锚字符
行首锁定:^ 定义从数据流中文本行的行首开始的模式。只能是行首
行尾锁定:$定义了行尾锚点
两种可以匹配 使用 达到特殊的用处
2,点字符
. 用来匹配除了换行符以外的任意单字符
3,字符数组
[] 可以在此数组中定义你想匹配的任意字符也可以前后配合使用用于交叉匹配
4,排除字符组
[^] 就是字符数组的反义词,匹配的时候不匹配数组中的字符
5,区间:
[]可以用次符号表示区间 [0-9] [a-z]等等进行匹配
6,特殊字符数组:这些定义好的可以使用
[[:alpha:]] 匹配任意字母字符,不区分大小写(都包括)
[[:alnum:]] 匹配任意字母数字字符0-9,A-Z , a-z
[[:blank:]] 匹配空格或者制表符
[[:digit:]] 匹配0-9数字
[[:lower:]] 匹配小写字母
[[:print:]] 匹配可打印字符
[[:punct:]] 匹配标点符号
[[:space:]] 匹配任意空白:空格,制表符,NL,NF,VT,和CR
[[:upper:]] 匹配任意大写字母
7,星号:
在匹配文本后面表示出现0次或多次:
ERE包括一些特殊的扩展用法,awk工具能识别但是sed工具不能
1,问号
文本后面加上?,表示匹配0次或者1次
2,加号
匹配文本后加上+,表示至少匹配一次
3,化括号
(m,n)至少出现m此,最多出现n次
4,管道符号
类似or符号,任意匹配就可以
5,聚合表达式
(),用该符号表示,相当于一个准字符
下面我们来做实验,介绍正则表达式常用的地方及场景
1,sed工具
sed的全程为stream editor,俗称流编辑器。和传说中的交互式文本编辑器正好相反
语法:
sed options script file
-e script 在处理输入时,将script中指定的命令添加到运行的命令中
-f file 在处理输入时,将file中指定的命令添加到运行的命令中
-n 不要为每个命令生成输出,等待print命令来输出,起到过滤的意思
下面一一道来:
e1:

我们从这三个例子中可以看出,sed -n选项的过滤作用,可以看到sed的流处理是怎么实现的。其中s是sed流处理过程中替换的标识,后面还有很多eg:d删除,p打印等等见到再说
///一共是三个,前面两个中间是被替换的文本,后面两个中间是要替换的文本
要在sed命令行上执行多条指令,则加上-e选项就可以了,相当于前面的插入命令,中间加上“;”号,其他不正确的写法看下图
e2:
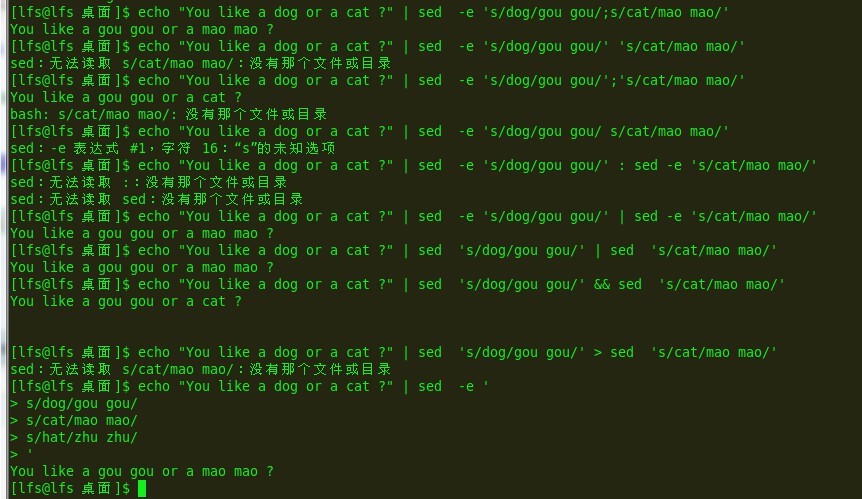
上面介绍了几种常见的正确和错误写法,其中最后一种主要是根据’号的作用,很类似python语言中的长句子(... ...)
而且还有一种现象,我们的匹配是完全的,只要有匹配的就替换,下面的从文本中读取编辑命令可以看出:
e3:
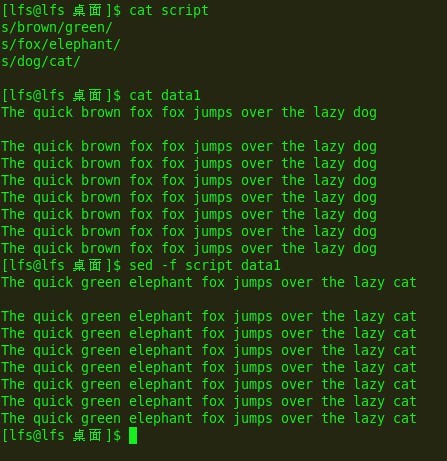
结果出来了,仔细看的就会发现。所谓完全匹配还是有一定的差别。有一个限制条件是:每行之替换一个!!!
如果我们想让它们都替换怎么办,简单,加上全集控制符就可以了/g,看它是怎么只手回天的
e4:

怎么样,控制性很高吧
sed的匹配模式语法:
s/pattern/replacement/flags
有四种可以替换标记:
>数字,标识将替换第几处匹配的地方
>g , 标识全局替换,只要出现就替换
>p ,标识原来行的内容打印出来
>w file ,将替换的结果写的文件file中
数字:
e5:
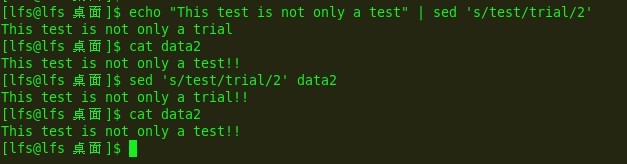
g和p:
e6:
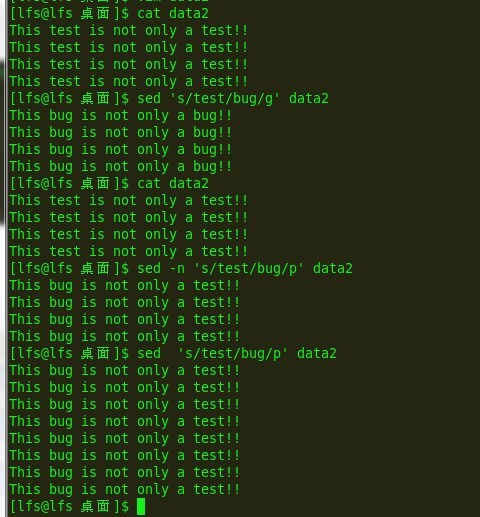
我们从例子中可以清晰的看出区别
下面看看我们的另类一点的 写文件:
e7:
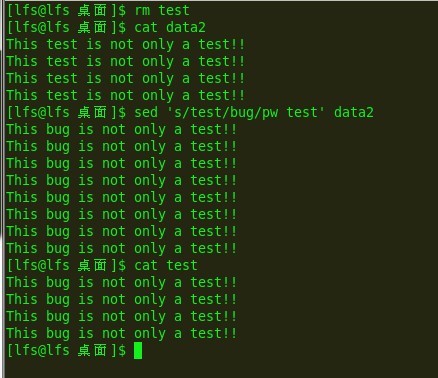
自己看,不解释,标志在感情可以接受的范围内可以用多个
另外我们发现,如果我们替换的是字符串并且字符串里面是一个路径(里面含有/)怎么办?
Look me:
e8:
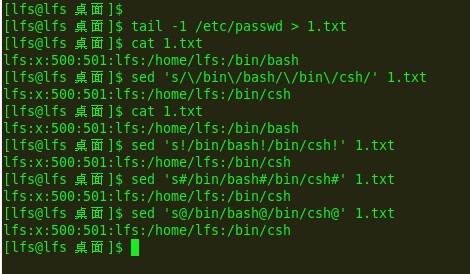
我们看出了什么? 很明显,有路径必须用\符合转义。当然也可以换作其他分割符"!"
而且目前只有"!"可以胜任,其他的(如例子#,@)虽然没有语法错误,但是不识别
sed使用地址:
sed中有两种行寻址:
1,行的数字范围
2,用文本模式来过滤出某行
都可以用相似方式实现:
[address] command
address {
command1
command2
command3
}
数字行寻址:
e9:
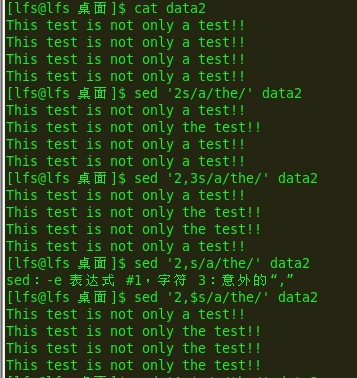
结果很明显,不做太多解释。$前面也介绍过
文本过滤模式过滤:
/pattern/command
e10:
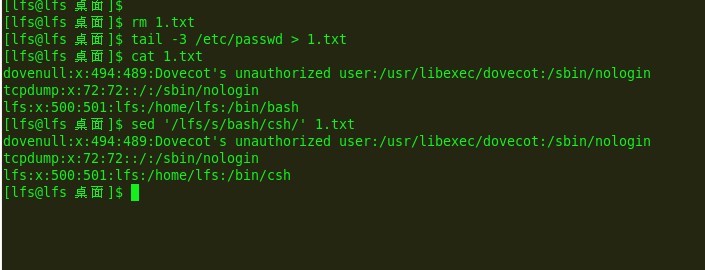
当然组合命令也是可以的,比较繁
一个新的sed标识:d(elete)
看例子:
e11:
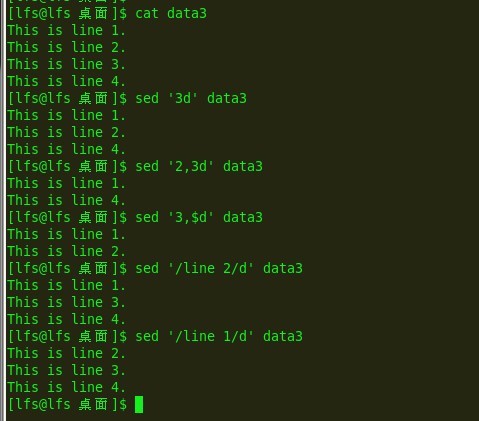
删除可以根据上面提到过的两种匹配模式
还有你甚至可以这样删除:
e12:
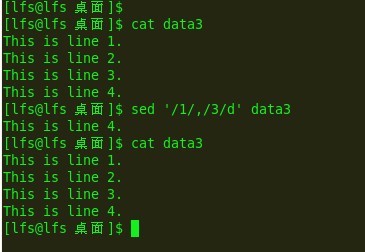
但是这么做有可能造成意外.第一次指定模式会"打开"行删除功能,第二个模式会"关闭"行删除功能.意思是会删除它们之间的元素
另外,只要匹配了打开功能,就开始删除.结果可能让你发疯:
e13:
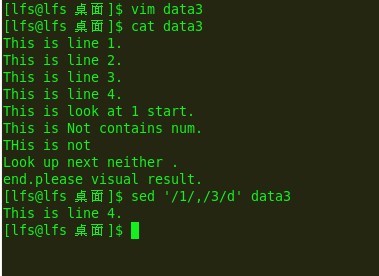
sed的插入和追加:
插入命令i会在指定行之前增加一行
追加命令a会在指定行之后加入一个新行
令人纳闷的它们格式:
sed '[address]command\
new line'
例子:
e14:
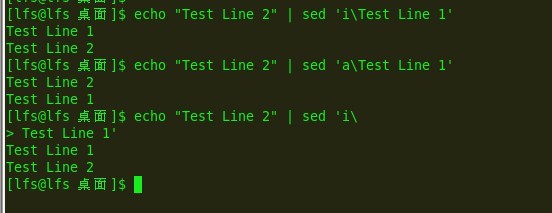
$指最后一行:
e15:
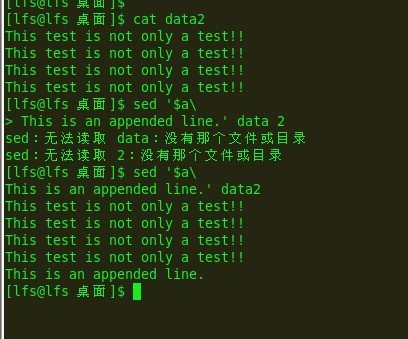
同理可以在文本第一行插入.
sed 的修改:
同理修改要指定行地址
e16:
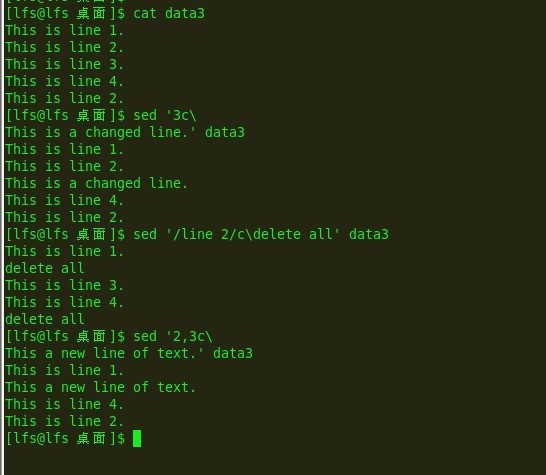
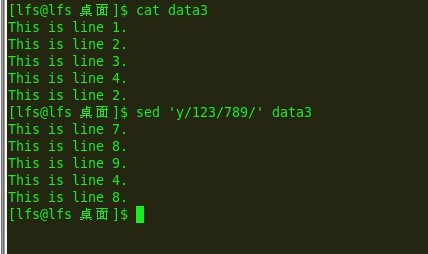
sed 转换命令
[address]y/inchars/outchars/ 等长转换
转换是一个全局命令,可以转化匹配的一切:
e17:
sed的打印
>p 打印文本行
>= 打印行号
>l 列出行
打印行:
e18:
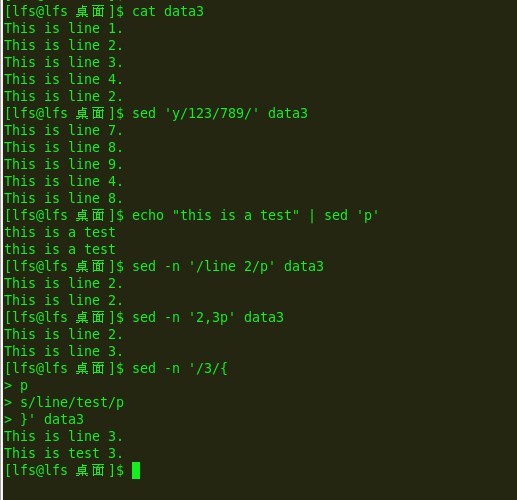
打印行号:
e19:
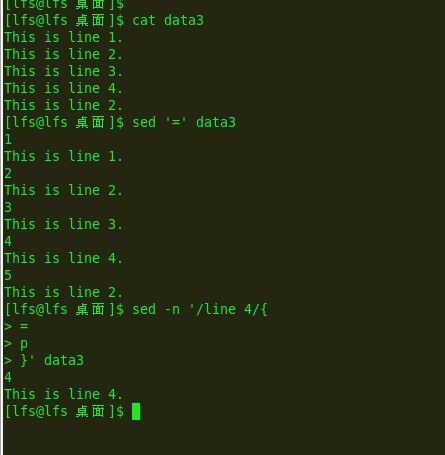
列出行: 列出数据流中所有字符,包括可打印和不可打印的字符
e20:

sed的文本保存
[address]w filename
sed '1,2w test' file 把file文件的1,2行读到test中.
可以用-n选项禁止显示在屏幕上
sed的读文件
[address]r filename
sed '3r test' file 读出test内容插入到file文件的第3行后面
sed '/number/r test' file 读出test内容,插入到file中含number行后面
sed '$r test' file 把test内容插到file文件最后

 浙公网安备 33010602011771号
浙公网安备 33010602011771号