

面试必问之JVM篇
前言
只有光头才能变强
JVM在准备面试的时候就有看了,一直没时间写笔记。现在到了一家公司实习,闲的时候就写写,刷刷JVM博客,刷刷电子书。
学习JVM的目的也很简单:
- 能够知道JVM是什么,为我们干了什么,具体是怎么干的。能够理解到一些初学时不懂的东西
- 在面试的时候有谈资
- 能装逼
声明:全文默认指的是HotSpot VM
一、简单聊聊JVM
1.1先来看看简单的Java程序
现在我有一个JavaBean:
-
-
public class Java3y {
-
-
// 姓名
-
private String name;
-
-
// 年龄
-
private int age;
-
-
//.....各种get/set方法/toString
-
}
一个测试类:
-
-
public class Java3yTest {
-
-
public static void main(String[] args) {
-
-
Java3y java3y = new Java3y();
-
java3y.setName("Java3y");
-
System.out.println(java3y);
-
-
}
-
}
我们在初学的时候肯定用过javac来编译.java文件代码,用过java命令来执行编译后生成的.class文件。

Java源文件:

在使用IDE点击运行的时候其实就是将这两个命令结合起来了(编译并运行),方便我们开发。

生成class文件

解析class文件得到结果

1.2编译过程
.java文件是由Java源码编译器(上述所说的java.exe)来完成,流程图如下所示:
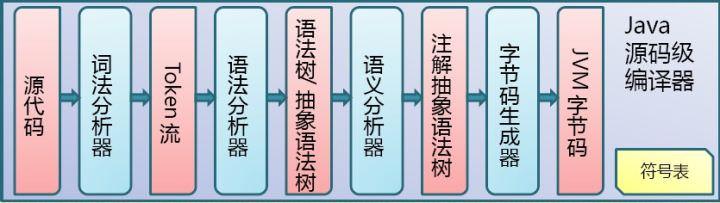
Java源码编译由以下三个过程组成:
- 分析和输入到符号表
- 注解处理
- 语义分析和生成class文件

1.2.1编译时期-语法糖
语法糖可以看做是编译器实现的一些“小把戏”,这些“小把戏”可能会使得效率“大提升”。
最值得说明的就是泛型了,这个语法糖可以说我们是经常会使用到的!
- 泛型只会在Java源码中存在,编译过后会被替换为原来的原生类型(Raw Type,也称为裸类型)了。这个过程也被称为:泛型擦除。
有了泛型这颗语法糖以后:
- 代码更加简洁【不用强制转换】
- 程序更加健壮【只要编译时期没有警告,那么运行时期就不会出现ClassCastException异常】
- 可读性和稳定性【在编写集合的时候,就限定了类型】
了解泛型更多的知识:
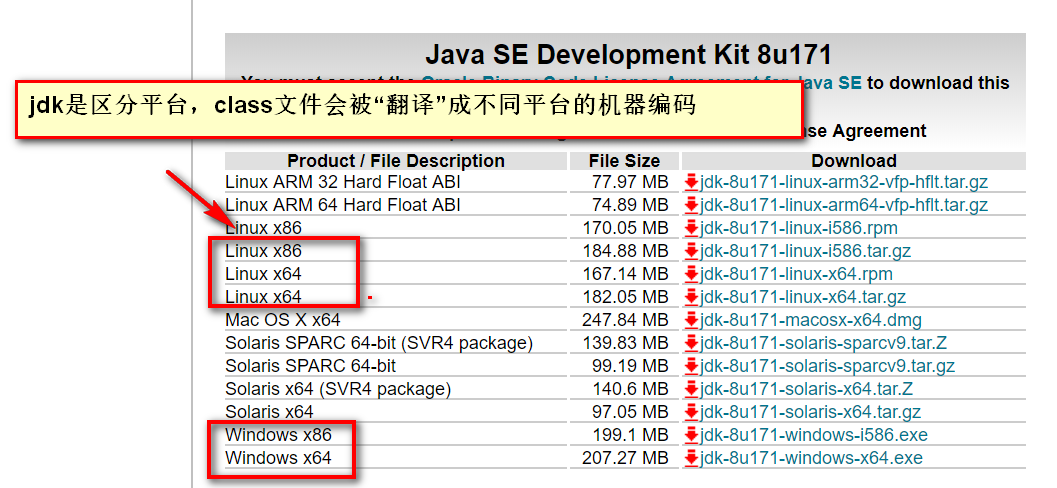
1.3JVM实现跨平台
至此,我们通过java.exe编译器编译我们的.java源代码文件生成出.class文件了!

这些.class文件很明显是不能直接运行的,它不像C语言(编译cpp后生成exe文件直接运行)
这些.class文件是交由JVM来解析运行!
- JVM是运行在操作系统之上的,每个操作系统的指令是不同的,而JDK是区分操作系统的,只要你的本地系统装了JDK,这个JDK就是能够和当前系统兼容的。
- 而class字节码运行在JVM之上,所以不用关心class字节码是在哪个操作系统编译的,只要符合JVM规范,那么,这个字节码文件就是可运行的。
- 所以Java就做到了跨平台--->一次编译,到处运行!
1.4class文件和JVM的恩怨情仇
1.4.1类的加载时机
现在我们例子中生成的两个.class文件都会直接被加载到JVM中吗??
虚拟机规范则是严格规定了有且只有5种情况必须立即对类进行“初始化”(class文件加载到JVM中):
- 创建类的实例(new 的方式)。访问某个类或接口的静态变量,或者对该静态变量赋值,调用类的静态方法
- 反射的方式
- 初始化某个类的子类,则其父类也会被初始化
- Java虚拟机启动时被标明为启动类的类,直接使用java.exe命令来运行某个主类(包含main方法的那个类)
- 当使用JDK1.7的动态语言支持时(....)
所以说:
- Java类的加载是动态的,它并不会一次性将所有类全部加载后再运行,而是保证程序运行的基础类(像是基类)完全加载到jvm中,至于其他类,则在需要的时候才加载。这当然就是为了节省内存开销。
1.4.2如何将类加载到jvm
class文件是通过类的加载器装载到jvm中的!
Java默认有三种类加载器:
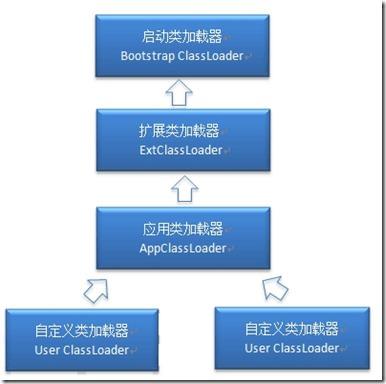
各个加载器的工作责任:
- 1)Bootstrap ClassLoader:负责加载$JAVA_HOME中jre/lib/rt.jar里所有的class,由C++实现,不是ClassLoader子类
- 2)Extension ClassLoader:负责加载java平台中扩展功能的一些jar包,包括$JAVA_HOME中jre/lib/*.jar或-Djava.ext.dirs指定目录下的jar包
- 3)App ClassLoader:负责记载classpath中指定的jar包及目录中class
工作过程:
- 1、当AppClassLoader加载一个class时,它首先不会自己去尝试加载这个类,而是把类加载请求委派给父类加载器ExtClassLoader去完成。
- 2、当ExtClassLoader加载一个class时,它首先也不会自己去尝试加载这个类,而是把类加载请求委派给BootStrapClassLoader去完成。
- 3、如果BootStrapClassLoader加载失败(例如在$JAVA_HOME/jre/lib里未查找到该class),会使用ExtClassLoader来尝试加载;
- 4、若ExtClassLoader也加载失败,则会使用AppClassLoader来加载
- 5、如果AppClassLoader也加载失败,则会报出异常ClassNotFoundException
其实这就是所谓的双亲委派模型。简单来说:如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把请求委托给父加载器去完成,依次向上。
好处:
- 防止内存中出现多份同样的字节码(安全性角度)
特别说明:
- 类加载器在成功加载某个类之后,会把得到的
java.lang.Class类的实例缓存起来。下次再请求加载该类的时候,类加载器会直接使用缓存的类的实例,而不会尝试再次加载。
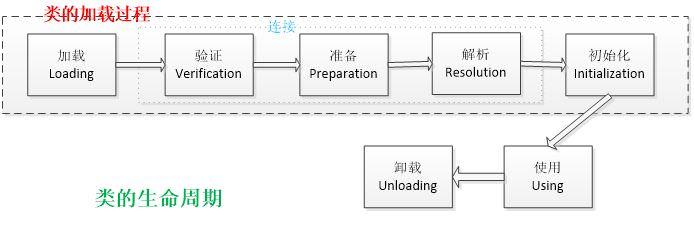
1.4.2类加载详细过程
加载器加载到jvm中,接下来其实又分了好几个步骤:
- 加载,查找并加载类的二进制数据,在Java堆中也创建一个java.lang.Class类的对象。
- 连接,连接又包含三块内容:验证、准备、初始化。
- 1)验证,文件格式、元数据、字节码、符号引用验证;
- 2)准备,为类的静态变量分配内存,并将其初始化为默认值;
- 3)解析,把类中的符号引用转换为直接引用
- 初始化,为类的静态变量赋予正确的初始值。
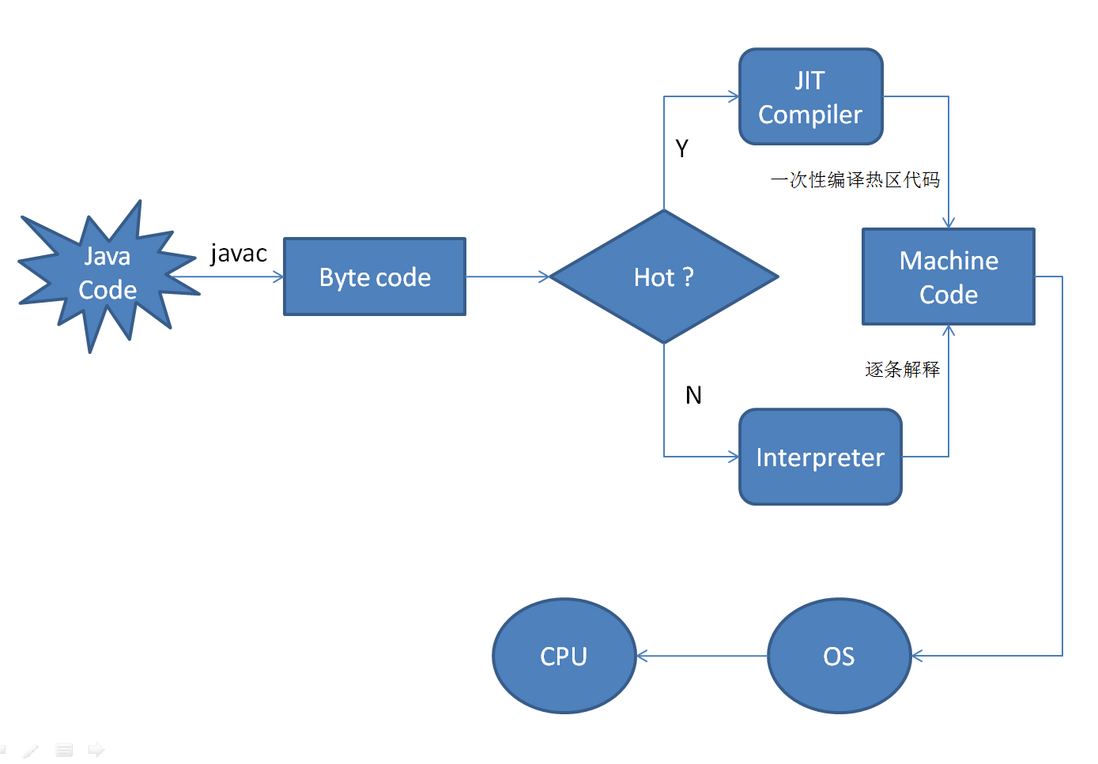
1.4.3JIT即时编辑器
一般我们可能会想:JVM在加载了这些class文件以后,针对这些字节码,逐条取出,逐条执行-->解析器解析。
但如果是这样的话,那就太慢了!
我们的JVM是这样实现的:
- 就是把这些Java字节码重新编译优化,生成机器码,让CPU直接执行。这样编出来的代码效率会更高。
- 编译也是要花费时间的,我们一般对热点代码做编译,非热点代码直接解析就好了。
热点代码解释:一、多次调用的方法。二、多次执行的循环体
使用热点探测来检测是否为热点代码,热点探测有两种方式:
- 采样
- 计数器
目前HotSpot使用的是计数器的方式,它为每个方法准备了两类计数器:
- 方法调用计数器(Invocation Counter)
- 回边计数器(Back EdgeCounter)。
- 在确定虚拟机运行参数的前提下,这两个计数器都有一个确定的阈值,当计数器超过阈值溢出了,就会触发JIT编译。
1.4.4回到例子中
按我们程序来走,我们的Java3yTest.class文件会被AppClassLoader加载器(因为ExtClassLoader和BootStrap加载器都不会加载它[双亲委派模型])加载到JVM中。
随后发现了要使用Java3y这个类,我们的Java3y.class文件会被AppClassLoader加载器(因为ExtClassLoader和BootStrap加载器都不会加载它[双亲委派模型])加载到JVM中

详情参考:
- https://www.mrsssswan.club/2018/06/30/jvm-start1/---浅解JVM加载class文件
- https://zhuanlan.zhihu.com/p/28476709---JVM杂谈之JIT
扩展阅读:
- https://www.ibm.com/developerworks/cn/java/j-lo-classloader/---深入探讨 Java 类加载器
- https://www.ibm.com/developerworks/cn/java/j-lo-just-in-time/---深入浅出 JIT 编译器
- https://www.zhihu.com/question/46719811---Java 类加载器(ClassLoader)的实际使用场景有哪些?
1.5类加载完以后JVM干了什么?
在类加载检查通过后,接下来虚拟机将为新生对象分配内存。
1.5.1JVM的内存模型
首先我们来了解一下JVM的内存模型的怎么样的:
- 基于jdk1.8画的JVM的内存模型--->我画得比较细。
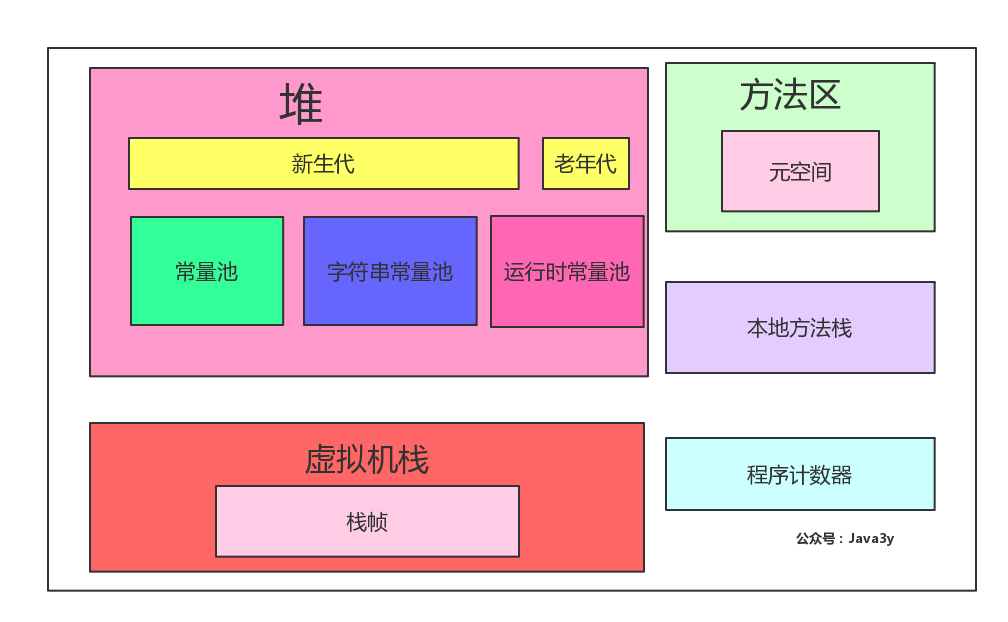
简单看了一下内存模型,简单看看每个区域究竟存储的是什么(干的是什么):
- 堆:存放对象实例,几乎所有的对象实例都在这里分配内存
- 虚拟机栈:虚拟机栈描述的是Java方法执行的内存模型:每个方法被执行的时候都会同时创建一个栈帧(Stack Frame)用于存储局部变量表、操作栈、动态链接、方法出口等信息
- 本地方法栈:本地方法栈则是为虚拟机使用到的Native方法服务。
- 方法区:存储已被虚拟机加载的类元数据信息(元空间)
- 程序计数器:当前线程所执行的字节码的行号指示器
1.5.2例子中的流程
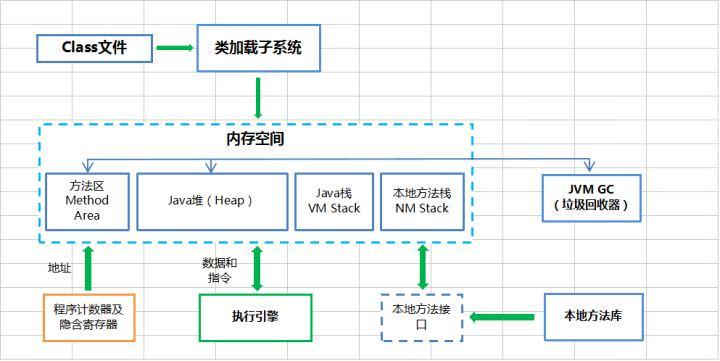
我来宏观简述一下我们的例子中的工作流程:
- 1、通过
java.exe运行Java3yTest.class,随后被加载到JVM中,元空间存储着类的信息(包括类的名称、方法信息、字段信息..)。 - 2、然后JVM找到Java3yTest的主函数入口(main),为main函数创建栈帧,开始执行main函数
- 3、main函数的第一条命令是
Java3y java3y = new Java3y();就是让JVM创建一个Java3y对象,但是这时候方法区中没有Java3y类的信息,所以JVM马上加载Java3y类,把Java3y类的类型信息放到方法区中(元空间) - 4、加载完Java3y类之后,Java虚拟机做的第一件事情就是在堆区中为一个新的Java3y实例分配内存, 然后调用构造函数初始化Java3y实例,这个Java3y实例持有着指向方法区的Java3y类的类型信息(其中包含有方法表,java动态绑定的底层实现)的引用
- 5、当使用
java3y.setName("Java3y");的时候,JVM根据java3y引用找到Java3y对象,然后根据Java3y对象持有的引用定位到方法区中Java3y类的类型信息的方法表,获得setName()函数的字节码的地址 - 6、为
setName()函数创建栈帧,开始运行setName()函数
从微观上其实还做了很多东西,正如上面所说的类加载过程(加载-->连接(验证,准备,解析)-->初始化),在类加载完之后jvm为其分配内存(分配内存中也做了非常多的事)。由于这些步骤并不是一步一步往下走,会有很多的“混沌bootstrap”的过程,所以很难描述清楚。
- 扩展阅读(先有Class对象还是先有Object):https://www.zhihu.com/question/30301819
参考资料:
- http://www.cnblogs.com/qiumingcheng/p/5398610.html---Java程序编译和运行的过程
- https://zhuanlan.zhihu.com/p/25713880---Java JVM 运行机制及基本原理
1.6简单聊聊各种常量池
在写这篇文章的时候,原本以为我对String s = "aaa";类似这些题目已经是不成问题了,直到我遇到了String.intern()这样的方法与诸如String s1 = new String("1") + new String("2"); 混合一起用的时候
- 我发现,我还是太年轻了。
首先我是先阅读了美团技术团队的这篇文章:https://tech.meituan.com/in_depth_understanding_string_intern.html---深入解析String#intern
嗯,然后就懵逼了。我摘抄一下他的例子:
-
-
public static void main(String[] args) {
-
String s = new String("1");
-
s.intern();
-
String s2 = "1";
-
System.out.println(s == s2);
-
-
String s3 = new String("1") + new String("1");
-
s3.intern();
-
String s4 = "11";
-
System.out.println(s3 == s4);
-
}
打印结果是
- jdk7,8下false true
调换一下位置后:
-
-
public static void main(String[] args) {
-
-
String s = new String("1");
-
String s2 = "1";
-
s.intern();
-
System.out.println(s == s2);
-
-
String s3 = new String("1") + new String("1");
-
String s4 = "11";
-
s3.intern();
-
System.out.println(s3 == s4);
-
}
打印结果为:
- jdk7,8下false false
文章中有很详细的解析,但我简单阅读了几次以后还是很懵逼。所以我知道了自己的知识点还存在漏洞,后面阅读了一下R大之前写过的文章:
- http://rednaxelafx.iteye.com/blog/774673#comments---请别再拿“String s = new String("xyz");创建了多少个String实例”来面试了吧
看完了之后,就更加懵逼了。
后来,在zhihu上看到了这个回答:
- https://www.zhihu.com/question/55994121---Java 中new String("字面量") 中 "字面量" 是何时进入字符串常量池的?
结合网上资料和自己的思考,下面整理一下对常量池的理解~~
1.6.1各个常量池的情况
针对于jdk1.7之后:
- 常量池位于堆中
- 运行时常量池位于堆中
- 字符串常量池位于堆中
常量池存储的是:
- 字面量(Literal):文本字符串等---->用双引号引起来的字符串字面量都会进这里面
- 符号引用(Symbolic References)
- 类和接口的全限定名(Full Qualified Name)
- 字段的名称和描述符(Descriptor)
- 方法的名称和描述符
常量池(Constant Pool Table),用于存放编译期生成的各种字面量和符号引用,这部分内容将在类加载后进入方法区的运行时常量池中存放--->来源:深入理解Java虚拟机 JVM高级特性与最佳实践(第二版)
现在我们的运行时常量池只是换了一个位置(原本来方法区,现在在堆中),但可以明确的是:类加载后,常量池中的数据会在运行时常量池中存放!
HotSpot VM里,记录interned string的一个全局表叫做StringTable,它本质上就是个HashSet<String>。注意它只存储对java.lang.String实例的引用,而不存储String对象的内容
字符串常量池只存储引用,不存储内容!
再来看一下我们的intern方法:
-
-
* When the intern method is invoked, if the pool already contains a
-
* string equal to this {
-
* the {
-
* returned. Otherwise, this {
-
* pool and a reference to this {
-
- 如果常量池中存在当前字符串,那么直接返回常量池中它的引用。
- 如果常量池中没有此字符串, 会将此字符串引用保存到常量池中后, 再直接返回该字符串的引用!
1.6.2解析题目
本来打算写注释的方式来解释的,但好像挺难说清楚的。我还是画图吧...
-
-
public static void main(String[] args) {
-
-
// 1.1在堆中创建"1"字符串对象
-
// 1.2字符串常量池引用"1"字符串对象
-
// 1.3s引用指向堆中"1"字符串对象
-
String s = new String("1");
-
-
// 2. 发现字符串常量池中已经存在"1"字符串对象,直接返回字符串常量池中对堆的引用(但没有接收)-->s引用还是指向着堆中的对象
-
s.intern();
-
-
// 3. 发现字符串常量池已经保存了该对象的引用了,直接返回字符串常量池对堆中字符串的引用
-
String s2 = "1";
-
-
// 4. s指向的是堆中对象的引用,s2指向的是在字符串常量池对堆中对象的引用
-
System.out.println(s == s2);// false
-
System.out.println("-----------关注公众号:Java3y-------------");
-
}
第一句:String s = new String("1");
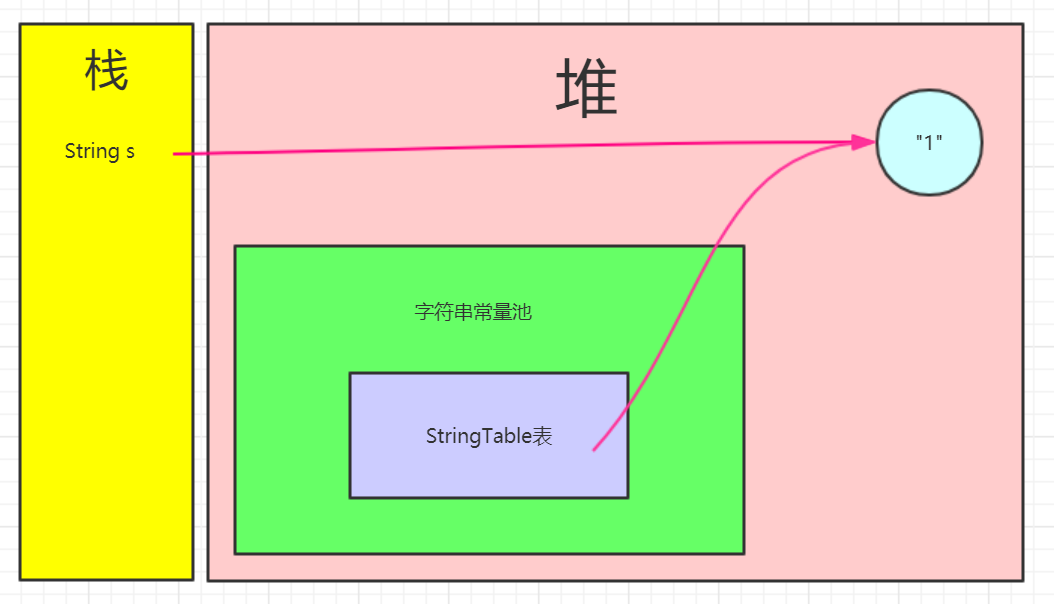
第二句:s.intern();发现字符串常量池中已经存在"1"字符串对象,直接返回字符串常量池中对堆的引用(但没有接收)-->此时s引用还是指向着堆中的对象
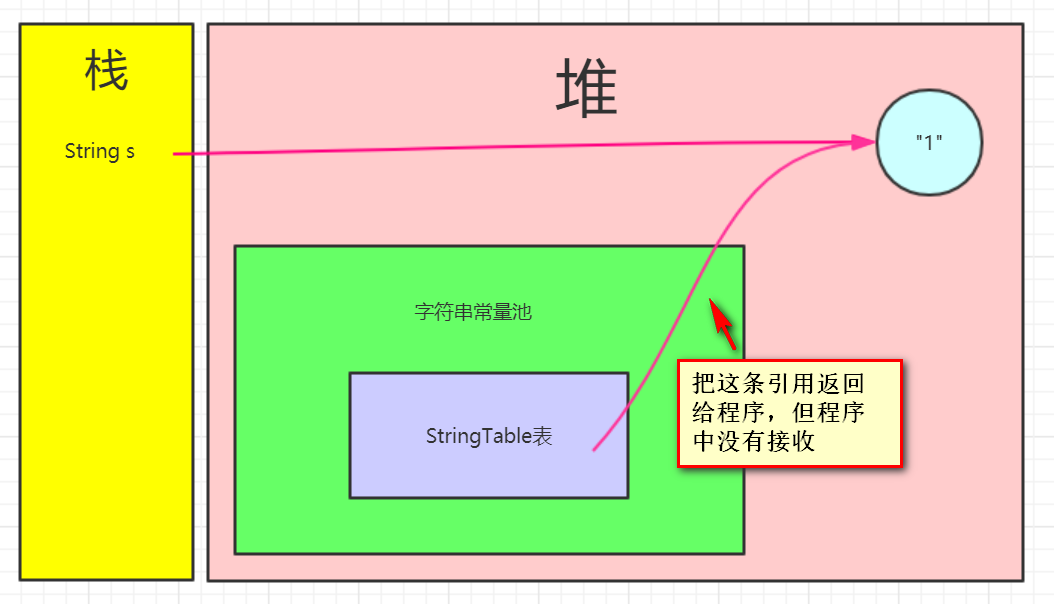
第三句:String s2 = "1";发现字符串常量池已经保存了该对象的引用了,直接返回字符串常量池对堆中字符串的引用

很容易看到,两条引用是不一样的!所以返回false。
-
-
public static void main(String[] args) {
-
-
System.out.println("-----------关注公众号:Java3y-------------");
-
-
// 1. 在堆中首先创建了两个“1”对象
-
// 1.1 +号运算符解析成stringBuilder,最后toString(),最终在堆中创建出"11"对象
-
// 1.2 注意:此时"11"对象并没有在字符串常量池中保存引用
-
String s3 = new String("1") + new String("1");
-
-
// 2. 发现"11"对象并没有在字符串常量池中存在,于是将"11"对象在字符串常量池中保存当前字符串的引用,并返回当前字符串的引用
-
s3.intern();
-
-
// 3. 发现字符串常量池已经存在引用了,直接返回(拿到的也是与s3相同指向的引用)
-
String s4 = "11";
-
System.out.println(s3 == s4); // true
-
}
第一句:String s3 = new String("1") + new String("1");在堆中首先创建了两个“1”对象。+号运算符解析成stringBuilder,最后toString(),最终在堆中创建出"11"对象。注意:此时"11"对象并没有在字符串常量池中保存引用。
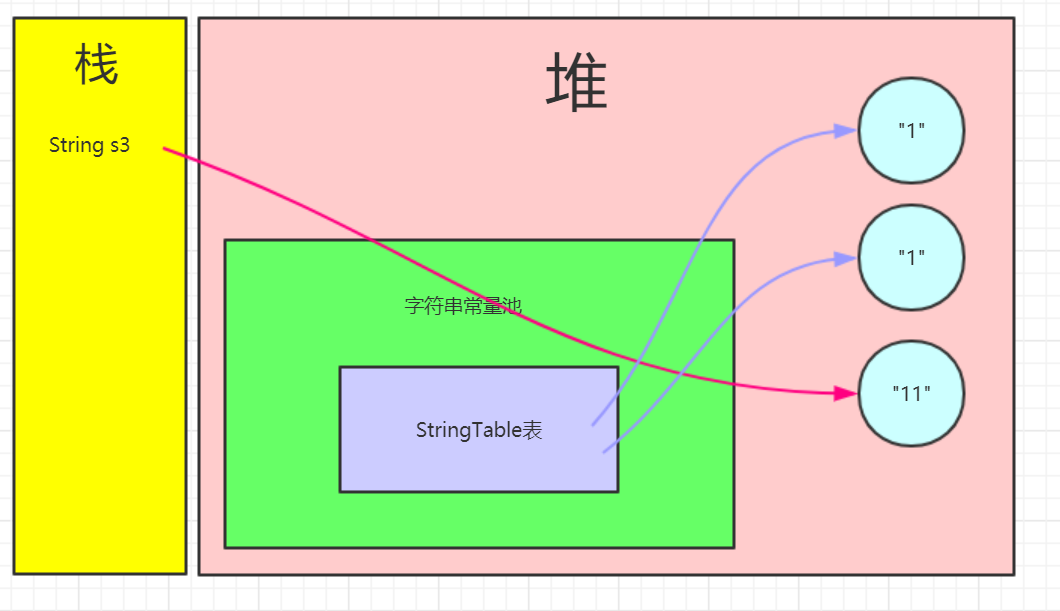
第二句:s3.intern();发现"11"对象并没有在字符串常量池中,于是将"11"对象在字符串常量池中保存当前字符串的引用,并返回当前字符串的引用(但没有接收)
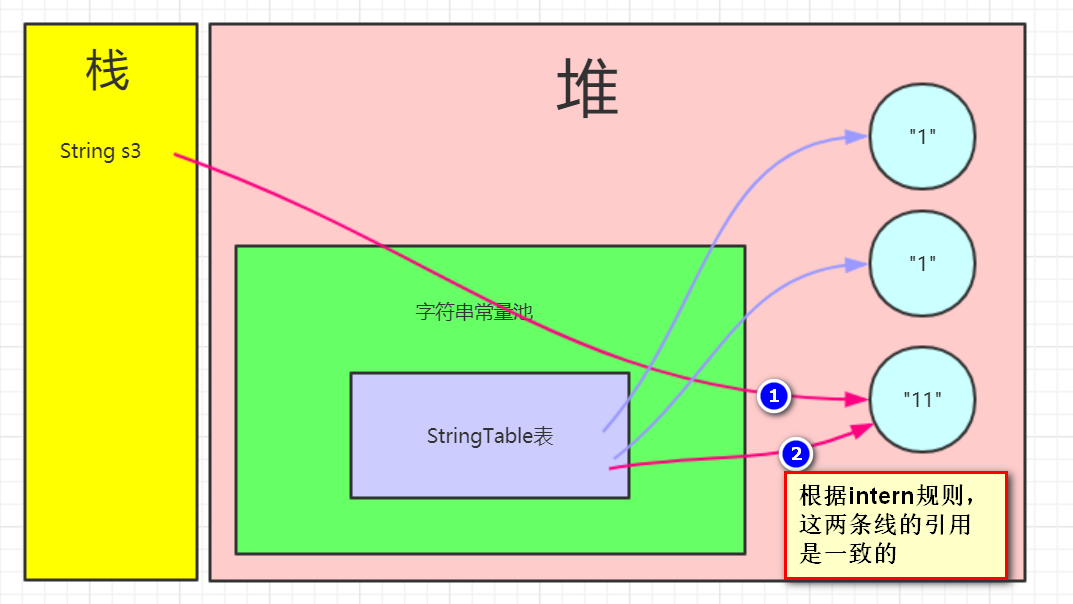
第三句:String s4 = "11";发现字符串常量池已经存在引用了,直接返回(拿到的也是与s3相同指向的引用)
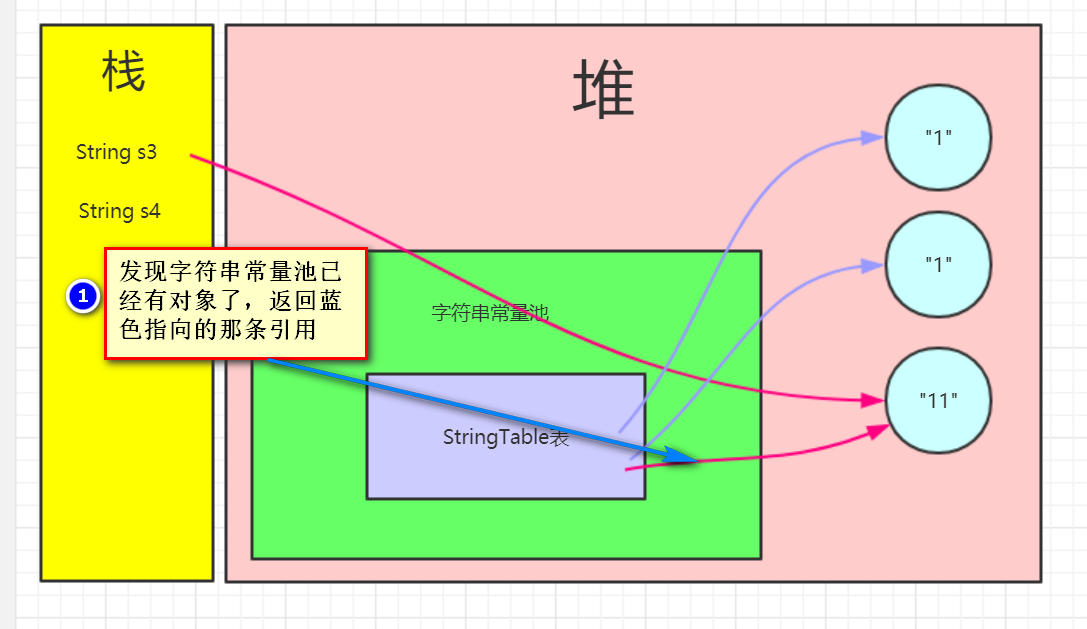
根据上述所说的:最后会返回true~~~
如果还是不太清楚的同学,可以试着接收一下intern()方法的返回值,再看看上述的图,应该就可以理解了。
下面的就由各位来做做,看是不是掌握了:
-
-
public static void main(String[] args) {
-
-
String s = new String("1");
-
String s2 = "1";
-
s.intern();
-
System.out.println(s == s2);//false
-
-
String s3 = new String("1") + new String("1");
-
String s4 = "11";
-
s3.intern();
-
System.out.println(s3 == s4);//false
-
}
还有:
-
-
public static void main(String[] args) {
-
String s1 = new String("he") + new String("llo");
-
String s2 = new String("h") + new String("ello");
-
String s3 = s1.intern();
-
String s4 = s2.intern();
-
System.out.println(s1 == s3);// true
-
System.out.println(s1 == s4);// true
-
}
1.7GC垃圾回收
可以说GC垃圾回收是JVM中一个非常重要的知识点,应该非常详细去讲解的。但在我学习的途中,我已经发现了有很好的文章去讲解垃圾回收的了。
所以,这里我只简单介绍一下垃圾回收的东西,详细的可以到下面的面试题中查阅和最后给出相关的资料阅
读吧~
1.7.1JVM垃圾回收简单介绍
在C++中,我们知道创建出的对象是需要手动去delete掉的。我们Java程序运行在JVM中,JVM可以帮我们“自动”回收不需要的对象,对我们来说是十分方便的。
虽然说“自动”回收了我们不需要的对象,但如果我们想变强,就要变秃..不对,就要去了解一下它究竟是怎么干的,理论的知识有哪些。
首先,JVM回收的是垃圾,垃圾就是我们程序中已经是不需要的了。垃圾收集器在对堆进行回收前,第一件事情就是要确定这些对象之中哪些还“存活”着,哪些已经“死去”。判断哪些对象“死去”常用有两种方式:
- 引用计数法-->这种难以解决对象之间的循环引用的问题
- 可达性分析算法-->主流的JVM采用的是这种方式
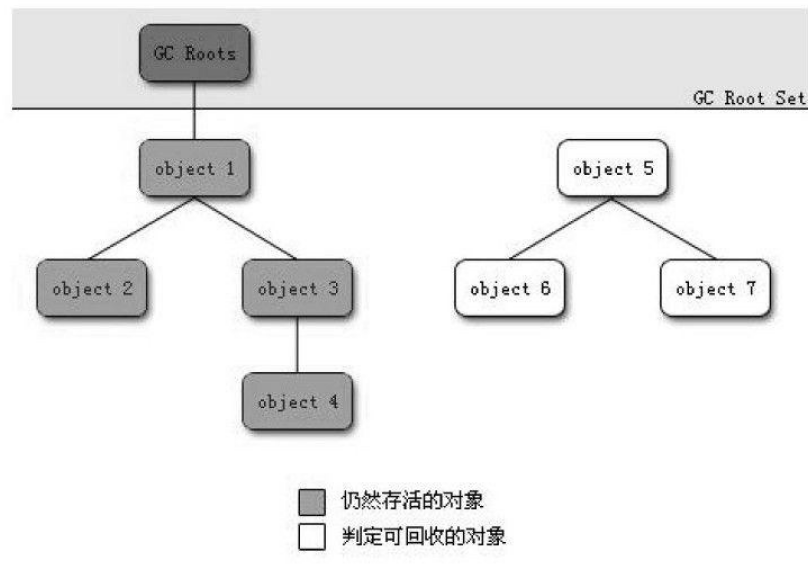
现在已经可以判断哪些对象已经“死去”了,我们现在要对这些“死去”的对象进行回收,回收也有好几种算法:
- 标记-清除算法
- 复制算法
- 标记-整理算法
- 分代收集算法
(这些算法详情可看下面的面试题内容)~
无论是可达性分析算法,还是垃圾回收算法,JVM使用的都是准确式GC。JVM是使用一组称为OopMap的数据结构,来存储所有的对象引用(这样就不用遍历整个内存去查找了,时间换空间)。
并且不会将所有的指令都生成OopMap,只会在安全点上生成OopMap,在安全区域上开始GC。
- 在OopMap的协助下,HotSpot可以快速且准确地完成GC Roots枚举(可达性分析)。
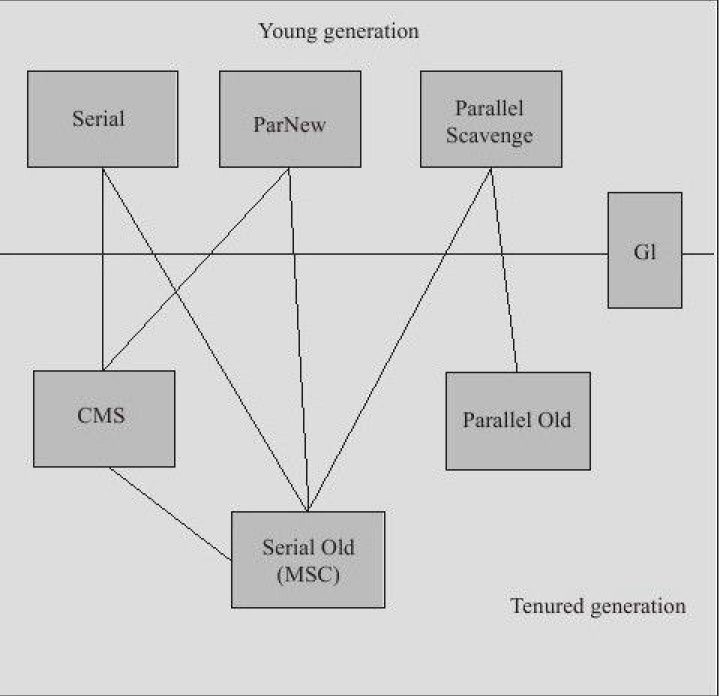
上面所讲的垃圾收集算法只能算是方法论,落地实现的是垃圾收集器:
- Serial收集器
- ParNew收集器
- Parallel Scavenge收集器
- Serial Old收集器
- Parallel Old收集器
- CMS收集器
- G1收集器
上面这些收集器大部分是可以互相组合使用的
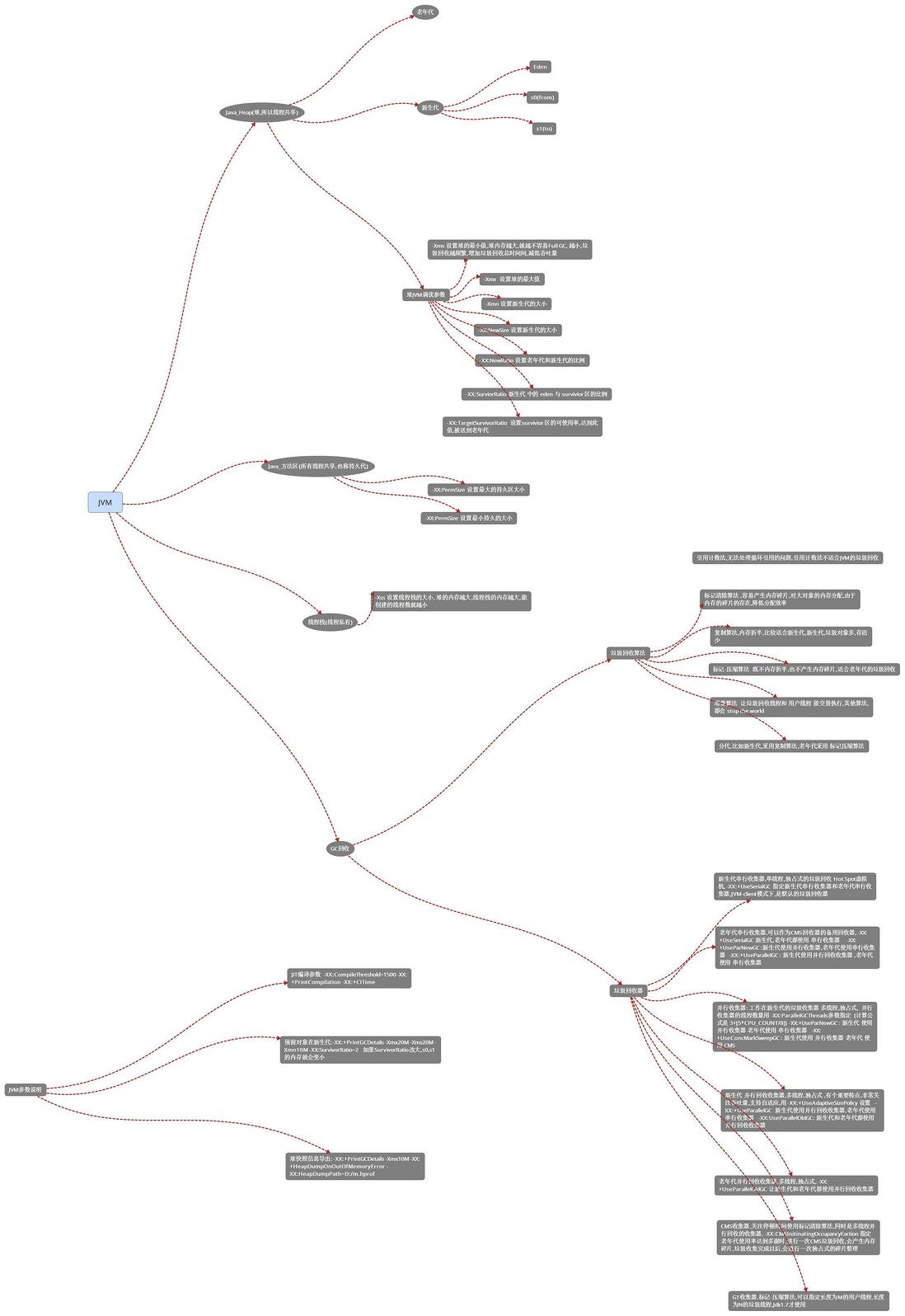
1.8JVM参数与调优
很多做过JavaWeb项目(ssh/ssm)这样的同学可能都会遇到过OutOfMemory这样的错误。一般解决起来也很方便,在启动的时候加个参数就行了。
上面也说了很多关于JVM的东西--->JVM对内存的划分啊,JVM各种的垃圾收集器啊。
内存的分配的大小啊,使用哪个收集器啊,这些都可以由我们根据需求,现实情况来指定的,这里就不详细说了,等真正用到的时候才回来填坑吧~~~~
参考资料:
- http://www.cnblogs.com/redcreen/archive/2011/05/04/2037057.html---JVM系列三:JVM参数设置、分析
二、JVM面试题
拿些常见的JVM面试题来做做,加深一下理解和查缺补漏:
- 1、详细jvm内存模型
- 2、讲讲什么情况下回出现内存溢出,内存泄漏?
- 3、说说Java线程栈
- 4、JVM 年轻代到年老代的晋升过程的判断条件是什么呢?
- 5、JVM 出现 fullGC 很频繁,怎么去线上排查问题?
- 6、类加载为什么要使用双亲委派模式,有没有什么场景是打破了这个模式?
- 7、类的实例化顺序
- 8、JVM垃圾回收机制,何时触发MinorGC等操作
- 9、JVM 中一次完整的 GC 流程(从 ygc 到 fgc)是怎样的
- 10、各种回收器,各自优缺点,重点CMS、G1
- 11、各种回收算法
- 12、OOM错误,stackoverflow错误,permgen space错误
题目来源:
2.1详细jvm内存模型
根据 JVM 规范,JVM 内存共分为虚拟机栈、堆、方法区、程序计数器、本地方法栈五个部分。
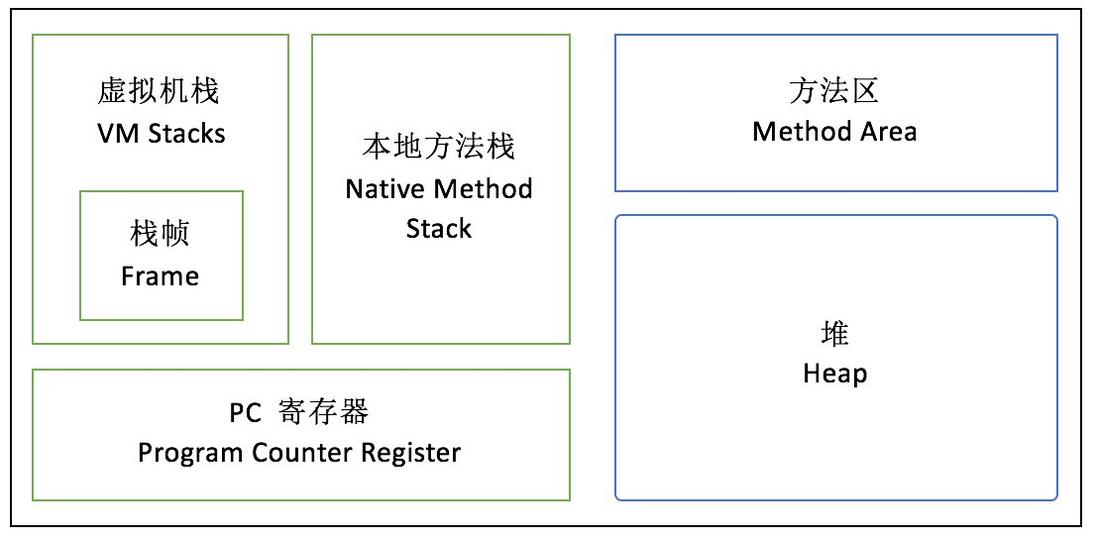
具体可能会聊聊jdk1.7以前的PermGen(永久代),替换成Metaspace(元空间)
- 原本永久代存储的数据:符号引用(Symbols)转移到了native heap;字面量(interned strings)转移到了java heap;类的静态变量(class statics)转移到了java heap
- Metaspace(元空间)存储的是类的元数据信息(metadata)
- 元空间的本质和永久代类似,都是对JVM规范中方法区的实现。不过元空间与永久代之间最大的区别在于:元空间并不在虚拟机中,而是使用本地内存。
- 替换的好处:一、字符串存在永久代中,容易出现性能问题和内存溢出。二、永久代会为 GC 带来不必要的复杂度,并且回收效率偏低
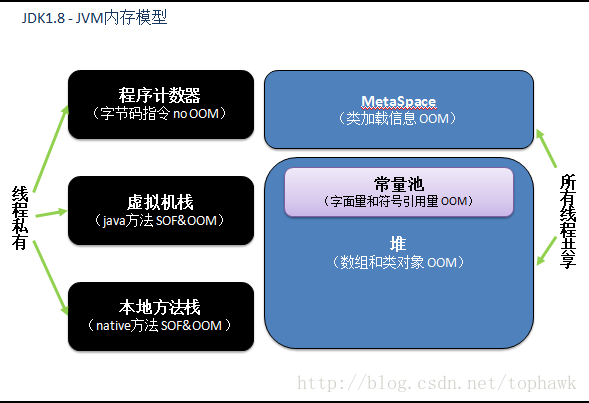
图片来源:https://blog.csdn.net/tophawk/article/details/78704074
参考资料:
2.2讲讲什么情况下回出现内存溢出,内存泄漏?
内存泄漏的原因很简单:
- 对象是可达的(一直被引用)
- 但是对象不会被使用
常见的内存泄漏例子:
-
-
public static void main(String[] args) {
-
-
Set set = new HashSet();
-
-
for (int i = 0; i < 10; i++) {
-
Object object = new Object();
-
set.add(object);
-
-
// 设置为空,这对象我不再用了
-
object = null;
-
}
-
-
// 但是set集合中还维护这obj的引用,gc不会回收object对象
-
System.out.println(set);
-
}
解决这个内存泄漏问题也很简单,将set设置为null,那就可以避免上诉内存泄漏问题了。其他内存泄漏得一步一步分析了。
内存泄漏参考资料:
内存溢出的原因:
- 内存泄露导致堆栈内存不断增大,从而引发内存溢出。
- 大量的jar,class文件加载,装载类的空间不够,溢出
- 操作大量的对象导致堆内存空间已经用满了,溢出
- nio直接操作内存,内存过大导致溢出
解决:
- 查看程序是否存在内存泄漏的问题
- 设置参数加大空间
- 代码中是否存在死循环或循环产生过多重复的对象实体、
- 查看是否使用了nio直接操作内存。
参考资料:
2.3说说线程栈
这里的线程栈应该指的是虚拟机栈吧...
JVM规范让每个Java线程拥有自己的独立的JVM栈,也就是Java方法的调用栈。
当方法调用的时候,会生成一个栈帧。栈帧是保存在虚拟机栈中的,栈帧存储了方法的局部变量表、操作数栈、动态连接和方法返回地址等信息
线程运行过程中,只有一个栈帧是处于活跃状态,称为“当前活跃栈帧”,当前活动栈帧始终是虚拟机栈的栈顶元素。
通过jstack工具查看线程状态
参考资料:
- http://wangwengcn.iteye.com/blog/1622195
- https://www.cnblogs.com/Codenewbie/p/6184898.html
- https://blog.csdn.net/u011734144/article/details/60965155
2.4JVM 年轻代到年老代的晋升过程的判断条件是什么呢?
- 部分对象会在From和To区域中复制来复制去,如此交换15次(由JVM参数MaxTenuringThreshold决定,这个参数默认是15),最终如果还是存活,就存入到老年代。
- 如果对象的大小大于Eden的二分之一会直接分配在old,如果old也分配不下,会做一次majorGC,如果小于eden的一半但是没有足够的空间,就进行minorgc也就是新生代GC。
- minor gc后,survivor仍然放不下,则放到老年代
- 动态年龄判断 ,大于等于某个年龄的对象超过了survivor空间一半 ,大于等于某个年龄的对象直接进入老年代
2.5JVM 出现 fullGC 很频繁,怎么去线上排查问题
这题就依据full GC的触发条件来做:
- 如果有perm gen的话(jdk1.8就没了),要给perm gen分配空间,但没有足够的空间时,会触发full gc。
- 所以看看是不是perm gen区的值设置得太小了。
System.gc()方法的调用
- 这个一般没人去调用吧~~~
- 当统计得到的Minor GC晋升到旧生代的平均大小大于老年代的剩余空间,则会触发full gc(这就可以从多个角度上看了)
- 是不是频繁创建了大对象(也有可能eden区设置过小)(大对象直接分配在老年代中,导致老年代空间不足--->从而频繁gc)
- 是不是老年代的空间设置过小了(Minor GC几个对象就大于老年代的剩余空间了)

2.6类加载为什么要使用双亲委派模式,有没有什么场景是打破了这个模式?
双亲委托模型的重要用途是为了解决类载入过程中的安全性问题。
- 假设有一个开发者自己编写了一个名为
java.lang.Object的类,想借此欺骗JVM。现在他要使用自定义ClassLoader来加载自己编写的java.lang.Object类。 - 然而幸运的是,双亲委托模型不会让他成功。因为JVM会优先在
Bootstrap ClassLoader的路径下找到java.lang.Object类,并载入它
Java的类加载是否一定遵循双亲委托模型?
- 在实际开发中,我们可以通过自定义ClassLoader,并重写父类的loadClass方法,来打破这一机制。
- SPI就是打破了双亲委托机制的(SPI:服务提供发现)。SPI资料:
- https://zhuanlan.zhihu.com/p/28909673
- https://www.cnblogs.com/huzi007/p/6679215.html
- https://blog.csdn.net/sigangjun/article/details/79071850
参考资料:
2.7类的实例化顺序
- 1. 父类静态成员和静态初始化块 ,按在代码中出现的顺序依次执行
- 2. 子类静态成员和静态初始化块 ,按在代码中出现的顺序依次执行
- 3. 父类实例成员和实例初始化块 ,按在代码中出现的顺序依次执行
- 4. 父类构造方法
- 5. 子类实例成员和实例初始化块 ,按在代码中出现的顺序依次执行
- 6. 子类构造方法
检验一下是不是真懂了:
-
-
class Dervied extends Base {
-
-
-
private String name = "Java3y";
-
-
public Dervied() {
-
tellName();
-
printName();
-
}
-
-
public void tellName() {
-
System.out.println("Dervied tell name: " + name);
-
}
-
-
public void printName() {
-
System.out.println("Dervied print name: " + name);
-
}
-
-
public static void main(String[] args) {
-
-
new Dervied();
-
}
-
}
-
-
class Base {
-
-
private String name = "公众号";
-
-
public Base() {
-
tellName();
-
printName();
-
}
-
-
public void tellName() {
-
System.out.println("Base tell name: " + name);
-
}
-
-
public void printName() {
-
System.out.println("Base print name: " + name);
-
}
-
}
输出数据:
-
-
Dervied tell name: null
-
Dervied print name: null
-
Dervied tell name: Java3y
-
Dervied print name: Java3y
第一次做错的同学点个赞,加个关注不过分吧(hahaha
2.8JVM垃圾回收机制,何时触发MinorGC等操作
当young gen中的eden区分配满的时候触发MinorGC(新生代的空间不够放的时候).
2.9JVM 中一次完整的 GC 流程(从 ygc 到 fgc)是怎样的
这题不是很明白意思(水平有限...如果知道这题的意思可在评论区留言呀~~)
- 因为按我的理解:执行fgc是不会执行ygc的呀~~
YGC和FGC是什么
- YGC :对新生代堆进行gc。频率比较高,因为大部分对象的存活寿命较短,在新生代里被回收。性能耗费较小。
- FGC :全堆范围的gc。默认堆空间使用到达80%(可调整)的时候会触发fgc。以我们生产环境为例,一般比较少会触发fgc,有时10天或一周左右会有一次。
什么时候执行YGC和FGC
- a.eden空间不足,执行 young gc
- b.old空间不足,perm空间不足,调用方法
System.gc(),ygc时的悲观策略, dump live的内存信息时(jmap –dump:live),都会执行full gc
2.10各种回收算法
GC最基础的算法有三种:
- 标记 -清除算法
- 复制算法
- 标记-压缩算法
- 我们常用的垃圾回收器一般都采用分代收集算法(其实就是组合上面的算法,不同的区域使用不同的算法)。
具体:
- 标记-清除算法,“标记-清除”(Mark-Sweep)算法,如它的名字一样,算法分为“标记”和“清除”两个阶段:首先标记出所有需要回收的对象,在标记完成后统一回收掉所有被标记的对象。
- 复制算法,“复制”(Copying)的收集算法,它将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。
- 标记-压缩算法,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存
- 分代收集算法,“分代收集”(Generational Collection)算法,把Java堆分为新生代和老年代,这样就可以根据各个年代的特点采用最适当的收集算法。
2.11各种回收器,各自优缺点,重点CMS、G1
图来源于《深入理解Java虚拟机:JVM高级特效与最佳实现》,图中两个收集器之间有连线,说明它们可以配合使用.
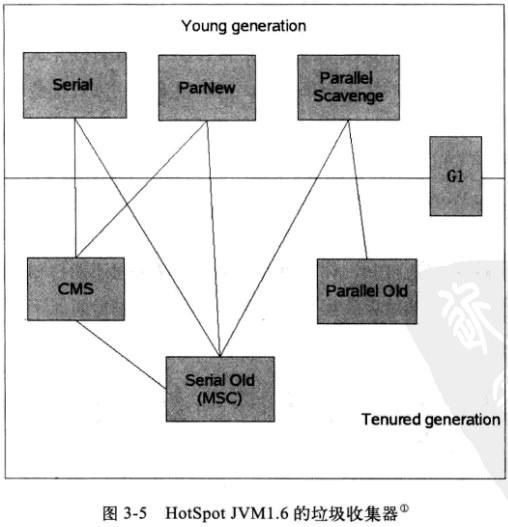
- Serial收集器,串行收集器是最古老,最稳定以及效率高的收集器,但可能会产生较长的停顿,只使用一个线程去回收。
- ParNew收集器,ParNew收集器其实就是Serial收集器的多线程版本。
- Parallel收集器,Parallel Scavenge收集器类似ParNew收集器,Parallel收集器更关注系统的吞吐量。
- Parallel Old收集器,Parallel Old是Parallel Scavenge收集器的老年代版本,使用多线程“标记-整理”算法
- CMS收集器,CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。它需要消耗额外的CPU和内存资源,在CPU和内存资源紧张,CPU较少时,会加重系统负担。CMS无法处理浮动垃圾。CMS的“标记-清除”算法,会导致大量空间碎片的产生。
- G1收集器,G1 (Garbage-First)是一款面向服务器的垃圾收集器,主要针对配备多颗处理器及大容量内存的机器. 以极高概率满足GC停顿时间要求的同时,还具备高吞吐量性能特征。
2.12stackoverflow错误,permgen space错误
stackoverflow错误主要出现:
- 在虚拟机栈中(线程请求的栈深度大于虚拟机栈锁允许的最大深度)
permgen space错误(针对jdk之前1.7版本):
- 大量加载class文件
- 常量池内存溢出
三、总结
总的来说,JVM在初级的层面上还是偏理论多,可能要做具体的东西才会有更深的体会。这篇主要是入个门吧~
这篇文章懒懒散散也算把JVM比较重要的知识点理了一遍了,后面打算学学,写写SpringCloud的东西。
如果文章有错的地方欢迎指正,大家互相交流。习惯在微信看技术文章,想要获取更多的Java资源的同学,可以关注微信公众号:Java技术zhai。为了大家方便,建了一下qq群:650385180,大家也可以去交流交流。谢谢支持了!希望能多介绍给其他有需要的朋友
