跳表的原理及实例
SkipList的基本原理
为什么选择跳表?
目前经常使用的平衡数据结构有:B树,红黑树,AVL树,Splay Tree, Treep等。想象一下,给你一张草稿纸,一只笔,一个编辑器,你能立即实现一颗红黑树,或者AVL树出来吗?
很难吧,这需要时间,要考虑很多细节,要参考一堆算法与数据结构之类的树,还要参考网上的代码,相当麻烦。
用跳表吧,跳表是一种随机化的数据结构,目前开源软件 Redis 和 LevelDB 都有用到它,它的效率和红黑树以及 AVL 树不相上下,但跳表的原理相当简单,只要你能熟练操作链表,就能轻松实现一个 SkipList。
定义
如果你要在一个有序的序列中查找元素 k ,相信大多数人第一反应都是二分查找。
如果你需要维护一个支持插入操作的有序表,大家又会想到链表。
简单的说,要达到以logn的速度查找链表中的元素
我们先来看看这张图:

如果要在这里面找 21 ,过程为 3→ 6 → 7 → 9 → 12 → 17 → 19 → 21 。
我们考虑从中抽出一些节点,建立一层索引作用的链表:

跳表的主要思想就是这样逐渐建立索引,加速查找与插入。
一般来说,如果要做到严格 O(logn) ,上层结点个数应是下层结点个数的 1/2 。但是这样实现会把代码变得十分复杂,就失去了它在 OI 中使用的意义。
此外,我们在实现时,一般在插入时就确定数值的层数,而且层数不能简单的用随机数,而是以1/2的概率增加层数。
用实验中丢硬币的次数 K 作为元素占有的层数。显然随机变量 K 满足参数为 p = 1/2 的几何分布,K 的期望值 E[K] = 1/p = 2. 就是说,各个元素的层数,期望值是 2 层。
同时,为了防止出现极端情况,设计一个最大层数MAX_LEVEL。如果使用非指针版,定义这样一个常量会方便许多,更能节省空间。如果是指针版,可以不加限制地任由它增长。
1 inline int rand_level()
2 {
3 int ret = 1;
4 while (rand() % 2 && ret <= MAX_LEVEL)
5 ++ret;
6 return ret;
7 }
我们来看看存储结点的结构体:
1 struct node
2 {
3 int key;
4 int next[MAX_LEVEL + 1];
5 } sl[maxn + 10];
next[i] 表示这个结点在第 i 层的下一个结点编号。
分配新结点
为了充分地利用空间,就是用一个栈或是队列保存已经被删除的节点,模拟一个内存池,记录可以使用的内存单元。
可以节省很多空间,使空间在 O(n · MAX_LEVEL) 级
1 inline void new_node(int &p, int key)
2 {
3 if (top)
4 p = st[top--];
5 else
6 p = ++node_tot;
7 sl[p].key = key;
8 }
回收结点
其实就是维护内存池,讲腾出的空间记录下来,给下一个插入的节点使用
1 inline void free_node(int p)
2 {
3 st[++top] = p;
4 }
初始化
按照定义,链表头尾应分别为负与正无穷。但是有时候是不需要的,不过为避免某些锅还是打上的好
1 inline void init()
2 {
3 new_node(head, -INF), new_node(tail, INF);
4 for (register int i = 1; i <= MAX_LEVEL; ++i)
5 sl[head].next[i] = tail;
6 }
查找
从最上层开始,如果key小于或等于当层后继节点的key,则平移一位;如果key更大,则层数减1,继续比较。最终一定会到第一层(想想为什么)
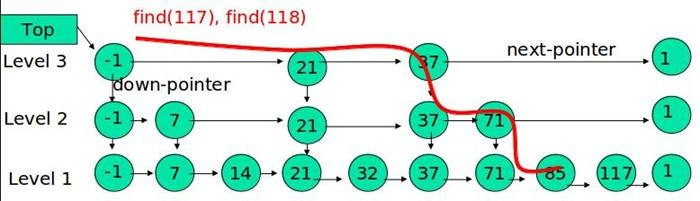
插入
先确定该元素要占据的层数 K(采用丢硬币的方式,这完全是随机的)。
然后在 Level 1 ... Level K 各个层的链表都插入元素。
用Update数组记录插入位置,同样从顶层开始,逐层找到每层需要插入的位置,再生成层数并插入。
例子:插入 119, K = 2

1 void insert(int key)
2 {
3 int p = head;
4 int update[MAX_LEVEL + 5];
5 int k = rand_level();
6 for (register int i = MAX_LEVEL; i; --i)
7 {
8 while (sl[p].next[i] ^ tail && sl[sl[p].next[i]].key < key)
9 p = sl[p].next[i];
10 update[i] = p;
11 }
12 int temp;
13 new_node(temp, key);
14 for (register int i = k; i; --i)
15 {
16 sl[temp].next[i] = sl[update[i]].next[i];
17 sl[update[i]].next[i] = temp;
18 }
19 }
删除
与插入类似
1 void erase(int key)
2 {
3 int p = head;
4 int update[MAX_LEVEL + 5];
5 for (register int i = MAX_LEVEL; i; --i)
6 {
7 while (sl[p].next[i] ^ tail && sl[sl[p].next[i]].key < key)
8 p = sl[p].next[i];
9 update[i] = p;
10 }
11 free_node(sl[p].next[1]);
12 for (register int i = MAX_LEVEL; i; --i)
13 {
14 if (sl[sl[update[i]].next[i]].key == key)
15 sl[update[i]].next[i] = sl[sl[update[i]].next[i]].next[i];
16 }
17 }
实战
先来看道水题:CodeVS 1230
题目:给出 n 个正整数,然后有 m 个询问,每个询问一个整数,询问该整数是否在 n 个正整数中出现过。
思路:用set就能实现,这里尝试用跳表(set本部就是平衡树,所有用SkipList能解决的,set也能解决一些)
//由于这题没有删除节点操作,省去了维护内存池部分
1 #include<cstdio>
2 #include<cstdlib>
3 using namespace std;
4
5 const int maxn = 100000 + 10;
6 const int max_level = 25; //层数上限
7
8 //定义节点
9 struct Node
10 {
11 int key;
12 int next[max_level + 1]; //next[i]表示这个节点在第i层的下一个编号
13 }node[maxn + 2];
14 int node_tot, head, tail;
15
16 //生成层数
17 inline int rand_level()
18 {
19 int ret = 1;
20 while (rand() % 2 && ret <= max_level)
21 ret++;
22 return ret;
23 }
24
25 //分配新节点 //key默认为0,表示head、tail的值为0
26 inline void new_node(int& p, int key = 0)
27 {
28 p = ++node_tot;
29 node[p].key = key;
30 }
31
32
33 //初始化
34 inline void init()
35 {
36 new_node(head); new_node(tail);
37 for (register int i = 1; i <= max_level; i++)
38 node[head].next[i] = tail;
39 }
40
41 //插入操作
42 void insert(int key)
43 {
44 int p = head;
45 int update[max_level + 1];
46 int K = rand_level();
47 for (register int i = max_level; i; i--)
48 {
49 while (node[p].next[i] ^ tail && node[node[p].next[i]].key < key) p = node[p].next[i];
50 update[i] = p;
51 }
52 int tmp;
53 new_node(tmp, key);
54 for (register int i = K; i; i--)
55 {
56 node[tmp].next[i] = node[update[i]].next[i];
57 node[update[i]].next[i] = tmp;
58 }
59 }
60
61 //查找元素
62 int find(int key)
63 {
64 int p = head;
65 for(register int i = max_level; i; i--)
66 {
67 while (node[p].next[i] ^ tail && node[node[p].next[i]].key < key)
68 p = node[p].next[i];
69 }
70 if (node[node[p].next[1]].key == key) return node[p].next[1] - 2;
71 else return -1;
72 }
73
74 int n, m;
75
76 int main()
77 {
78 srand(19260817);
79 scanf("%d%d", &n, &m);
80 init();
81 int tmp;
82 while (n--)
83 {
84 scanf("%d", &tmp);
85 insert(tmp);
86 }
87 while (m--)
88 {
89 scanf("%d", &tmp);
90 int res = find(tmp);
91 if (res > 0) printf("YES\n");
92 else printf("NO\n");
93 }
94 return 0;
95 }
现在来看道蓝题:P2286
题目:太长了,自己看
思路:
如果收养者按照到来顺序收养宠物的话,只要把宠物的特点值建立平衡树,每次求收养者特点值前驱后继与之绝对值相差较小的一个。
这就是一个set的简单应用啦
对于100%的数据,人和宠物互相选择,可以用两个平衡树,实现起来有些麻烦
但我们可以想到,人和宠物在此题本质等价,人和宠物都可能待在店里等待
那其实只要一个平衡树,再加一个变量记录一下当前树中存的是人还是宠物即可,具体见代码。
set版
1 #include<cstdio>
2 #include<cstring>
3 #include<queue>
4 #include<set>
5 #include<algorithm>
6 using namespace std;
7
8 const int INF = 0x7fffffff;
9 const int mod = 1000000;
10 set<int>st;
11 queue<int>que;
12 int n;
13 int ans;
14
15 void query(int x)
16 {
17 set<int>::iterator l = --st.lower_bound(x), r = st.lower_bound(x);
18 if (*r == INF) { ans += abs(*l - x); st.erase(l); }
19 else if (*l == -INF) { ans += abs(*r - x); st.erase(r); }
20 else
21 {
22 if (x - *l <= *r - x)
23 {
24 ans += x - *l;
25 st.erase(l);
26 }
27 else
28 {
29 ans += *r - x;
30 st.erase(r);
31 }
32 }
33 ans %= mod;
34 }
35
36 int main()
37 {
38 st.insert(-INF);
39 st.insert(INF);
40 int flag; //记录是宠物树,还是主人树
41 scanf("%d", &n);
42 while (n--)
43 {
44 int a, b;
45 scanf("%d %d", &a, &b);
46 if (st.size() == 2) { flag = a; st.insert(b); }
47 else if (a == flag) st.insert(b);
48 else query(b);
49 }
50 printf("%d\n", ans);
51 return 0;
52 }
SkipList版
1 #include<cstdio>
2 #include<cstdlib>
3 #include<cstring>
4 using namespace std;
5
6 const int INF = 0x7fffffff;
7 const int mod = 1000000;
8 const int MAX_LEVEL = 30;
9 const int maxn = 10000 + 10;
10 int top,node_tot,st[maxn];
11 int head, tail;
12 int size; //实时跳表元素个数
13
14 struct node
15 {
16 int key;
17 int next[MAX_LEVEL + 1];
18 } sl[maxn + 10];
19
20 inline int rand_level()
21 {
22 int ret = 1;
23 while (rand() % 2 && ret <= MAX_LEVEL)
24 ++ret;
25 return ret;
26 }
27
28 inline void new_node(int &p, int key)
29 {
30 if (top)
31 p = st[top--];
32 else
33 p = ++node_tot;
34 sl[p].key = key;
35 size++;
36 }
37
38 inline void free_node(int p)
39 {
40 st[++top] = p;
41 size--;
42 }
43
44 inline void init()
45 {
46 new_node(head, -INF), new_node(tail, INF);
47 for (register int i = 1; i <= MAX_LEVEL; ++i)
48 sl[head].next[i] = tail;
49 }
50
51 void insert(int key)
52 {
53 int p = head;
54 int update[MAX_LEVEL + 5];
55 int k = rand_level();
56 for (register int i = MAX_LEVEL; i; --i)
57 {
58 while (sl[p].next[i] ^ tail && sl[sl[p].next[i]].key < key)
59 p = sl[p].next[i];
60 update[i] = p;
61 }
62 int temp;
63 new_node(temp, key);
64 for (register int i = k; i; --i)
65 {
66 sl[temp].next[i] = sl[update[i]].next[i];
67 sl[update[i]].next[i] = temp;
68 }
69 }
70
71 void erase(int key)
72 {
73 int p = head;
74 int update[MAX_LEVEL + 5];
75 for (register int i = MAX_LEVEL; i; --i)
76 {
77 while (sl[p].next[i] ^ tail && sl[sl[p].next[i]].key < key)
78 p = sl[p].next[i];
79 update[i] = p;
80 }
81 free_node(sl[p].next[1]);
82 for (register int i = MAX_LEVEL; i; --i)
83 {
84 if (sl[sl[update[i]].next[i]].key == key)
85 sl[update[i]].next[i] = sl[sl[update[i]].next[i]].next[i];
86 }
87 }
88
89 int find(int key)
90 {
91 int p = head;
92 for (register int i = MAX_LEVEL; i; --i)
93 while (sl[p].next[i] ^ tail && sl[sl[p].next[i]].key < key)
94 p = sl[p].next[i];
95 return p; //相当于lower_bound的结果减1
96 }
97
98 int ans = 0;
99 void query(int x)
100 {
101 int p = find(x);
102 int l = p, r = sl[p].next[1];
103 if (sl[l].key ^ -INF && x - sl[l].key <= sl[r].key - x)
104 {
105 ans += x - sl[l].key;
106 erase(sl[l].key);
107 }
108 else
109 {
110 ans += sl[r].key - x;
111 erase(sl[r].key);
112 }
113 ans %= mod;
114 }
115
116 int main()
117 {
118 init();
119 int n;
120 scanf("%d", &n);
121 int a, b, type;
122 while (n--)
123 {
124 scanf("%d%d", &a, &b);
125 if (size == 2) { type = a; insert(b); }
126 else if (a == type) insert(b);
127 else query(b);
128 }
129 printf("%d\n", ans);
130 }
参考链接:
1、https://www.luogu.org/blog/Ilovehimforever/SkipList
2、https://www.cnblogs.com/a8457013/p/8251967.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号