SRGAN的原理及Pytorch实现
follow this repo: https://github.com/aladdinpersson/Machine-Learning-Collection/tree/master/ML/Pytorch/GANs/SRGAN
paper: https://arxiv.org/pdf/1609.04802.pdf
介绍
号称是第一个将GAN应用于图像超分辨率的论文
Super-Resolution, SR
Single Image Super Resolution, SISR
low-resolution, LR
high-resolution, HR
mean square error, MSR
peak signal-to-noise ratio, PSNR
mean-opinion-score, MOS
结构
全部在图里面了

有一点出入的地方是,论文文字中residual block是16块,图中只画了5块(可能是画不下吧
喔 zz了,B=16
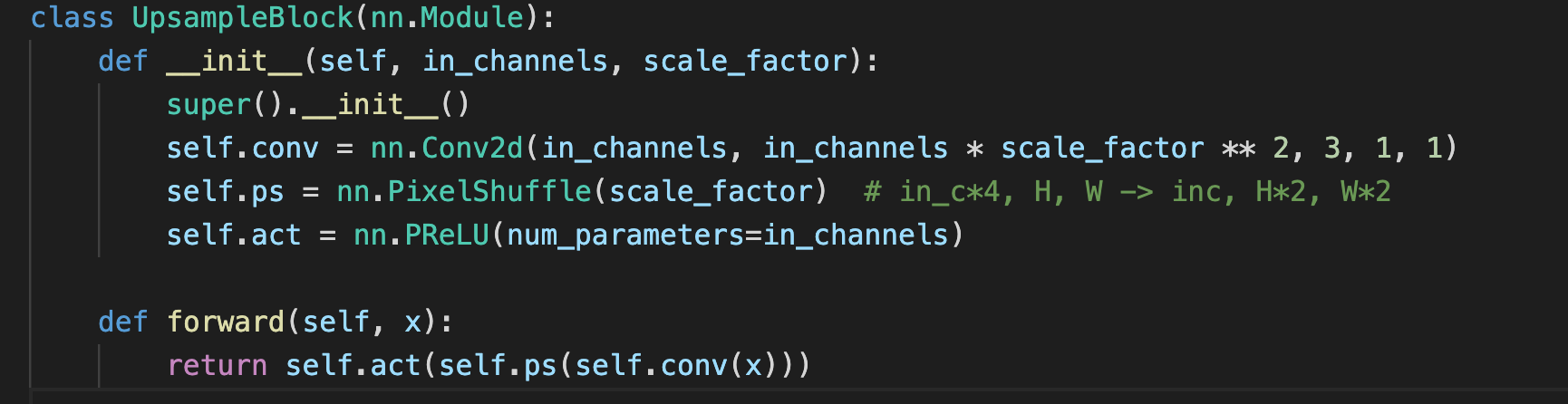
Subpixel模块
PixelShuffler操作,这里是用于Upsampling,扩大图片尺寸2倍
Subpixel模块是一种在超分辨率中经常使用的upscale方法,又叫做pixel shuffle。我们知道,对CNN的feature map进行放大的方法有转置卷积,但是如果直接用转置卷积的话,在超分辨率中通常会带入过多人工因素。而Subpixel模块会大大降低这个风险。

就是,如果我们想把图片放大2倍的话,那么我们需要生成2^2=4个一样大小的feature map,最后将这4个特征图拼成一个大图
loss改进
MSE/PSNR 不行
VGG feature map mse 行
作者认为PSNR高不一定好,PSNR低一点的可能更加符合人的视觉效果
为此作者设计了mean-opinion test(平均意见得分检验),请26个评分员对图片按5个梯度打分

比如第3幅的PSNR比第2幅低,但是看起来更逼真(比如帽子部分
一些思考
(1) vgg loss真的好吗?
高PSNR值并不符合人眼直观感受的缺点很早已经被注意到,但从未有有效的算法替代MSE类算法来进行相关工作,问题的根源在于MSE的高效性难以被超越;
SRGAN 似乎恢复了一些细节,但也有人认为这些其实时高频噪声,噪声在图像处理中的作用十分值得关注,但该领域已经进入半死不活的状态,期待有理论上的突破。
from https://zhuanlan.zhihu.com/p/27859358
qs 感觉就是加了复杂的vgg loss,变得既不优雅又低效
效果提升也不明显,而是是个主观打分
论文作者说vgg越深越好,vgg loss就是符合人类视觉效果的终点吗
vgg随便选吗,需要是同类数据集训练出来的吗?
(2) residual block的深度怎么确定
论文中用的16层,作者后来又说>16层会更好,一直residual会学到多的知识吗
其他
SRResNet可以单独用来做SR,这里是用作SRGAN的Generator
这么看GAN更像是一种训练方法,或者说是一种训练技巧,只是在训练过程中会用到Discirminator,而在推断阶段,仅仅用到的Generator
因为是全卷积网络,可以适应任何尺寸的图片
参考链接:https://blog.csdn.net/Rocky6688/article/details/104369905

 浙公网安备 33010602011771号
浙公网安备 33010602011771号