Baidu EasyDL入门介绍
其实目前在 GitHub 上有很多优秀的机器学习开源项目,例如各种预训练深度卷积网络、高度封装的算法以及大量开放数据集,不过要想复现以及根据实际情况调整这些项目,开发者还是需要一些 ML 领域知识。此外,很多项目的文档说明与技术支持都有待提高,它们需要开发者一点点调试与试错才能正确搭建。更重要的是,将训练后的模型部署到移动端等平台会遇到非常多的困难,这主要还是当前流行的深度学习框架并不能完美支持模型部署。
所以对于不太了解 ML 的开发者而言,最好将上述这些过程都自动化。例如我们只需要收集少量和任务相关的数据,并直接在平台上完成标注,然后让系统帮我们选择合适模型与超参数进行训练,最后已训练模型还可以直接部署到云 API 或打包成安装包。其实现在也已经有一些平台能完成这一些过程,例如谷歌的 AutoML 和百度的 EasyDL 等。
EasyDL 主页:http://ai.baidu.com/easydl/
EasyDL经典版
功能:
- 零算法训练模型:无需机器学习专业知识,只需上传并标注需要识别的示例数据即可一键训练模型
- 校验模型效果:查看详细的效果评估报告,并在可视化界面校验模型效果,进而有针对性地补充训练数据
- 部署应用模型:对模型效果满意后,将模型部署在云端、设备端、私有服务器,或直接购买软硬一体方案
例如用于图像分类:
定制识别一张图中是否是某类物体/状态/场景,适合图片中主体或者状态单一的场景
应用场景:
- 图片内容检索:定制训练需要识别的各种物体,并结合业务信息展现更丰富识别结果
- 制造业分拣或质检:定制生产线上各种产品识别,进而实现自动分拣或者质检
- 医疗诊断:定制识别医疗图像,辅助医生肉眼诊断
主要技术手段:
- AI Workflow 统一大数据工程系统与分布式训练系统,为 EasyDL 提供稳定的系统和流程支持
- 采用 PaddlePaddle 作为基本框架,为模型的搭建提供基础;
- 采用 Auto Model Search 自动搜索模型超参数,支持获得更好的训练效果
- 采用迁移学习训练较小的用户数据集,从而大大加强训练效率与效果等。
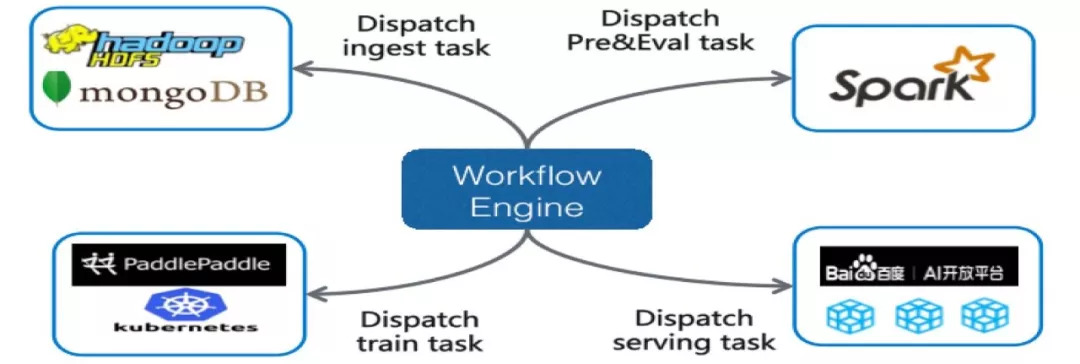
AI Workflow 与 PaddlePaddle
AI Workflow 是百度对机器学习从训练到上线构建的工作流引擎,
总体而言,AI Workflow 的主要流程可以分为四个阶段:
- 首先第一阶段是对数据进行预处理,例如对图像实现归一化、大小裁剪与数据增强等。
- 随后第二阶段是模型的训练,或者说是学习过程,这一阶段会基于百度研发的深度学习框架 PaddlePaddle 进行分布式训练。
- 训练完模型后,第三阶段就需要验证模型的效果,也就是说用户可以上传小规模的测试数据,并对模型的召回率与精度等指标进行验证。
- 最后第四阶段为服务的上线或模型的部署,在这个过程中我们可以将已训练模型加载到云端并对外提供服务,也可以打包为一组移动端开发套件,为进一步集成到其它任务中提供接口。
自动模型搜索与迁移学习
目前 EasyDL 采用了 Auto Model Search 的算法,即系统会同时发起多个模型结构和超参数不同的训练,并采用对应算法进行最终模型的筛选,从而确保更优的模型效果。Auto Model Search 与后文介绍的 AutoDL 在功能上是相近的,但百度的 AutoDL 是一种神经架构搜索方法,它关注于利用强化学习从头构建神经网络。
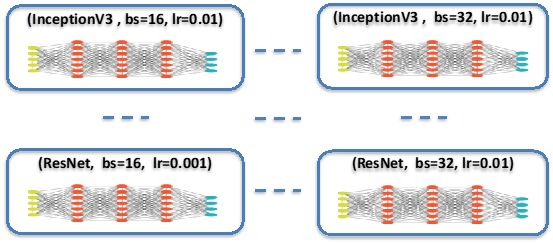
其中系统可调的超参数包含神经网络类型的选择,例如对于图像分类可以选择 Inception、ResNet 或者其他。而对于每一个模型,可选的超参数包含批量大小、迭代数量和卷积核大小等。
其实 Auto Model Search 是针对特定用户数据的,在用户上传与他们任务相关的数据后,EasyDL 会抽取多个已训练深度网络,并采用迁移学习和不同的超参配置精调这些深度网络。如下所示在用户确定好小型数据集后,EasyDL 可能会选择 Inception v3/v4 和 ResNet 等,在固定这几个网络前面层级的权重后,系统会根据用户数据以及不同的批量大小和学习率训练网络。
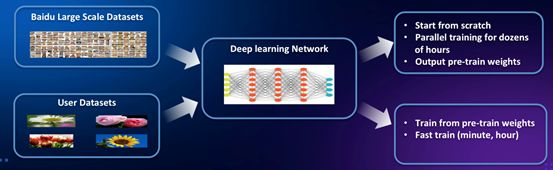
EasyDL 大量采用了迁移学习技术,各种基础模型会在百度大规模数据集上进行预训练,并将从中学习到的知识(Knowledge)运用到用户提交的小规模训练数据集上,从而实现出色的模型效果和快速的模型训练。迁移学习的主干是非常大的网络,而一般我们每一类只需要使用 20 到 100 多张图像就能完成对后面层级的训练,且 EasyDL 也会采用 Early Stopping 等正则化手段降低模型过拟合的风险。
神经架构搜索
EasyDL 即将引入百度领先的 AutoDL 技术,这是一种 AutoML 的技术,它实现了深度学习网络结构的自动搜索和设计。
在架构搜索策略上,目前比较流行的有进化策略、强化学习和基于梯度的连续空间搜索方法。而百度的 AutoDL 主要是基于强化学习,其核心思路是希望能搜索到尽可能广的空间。为了将神经架构搜索构造为强化学习问题,神经架构的生成可以视为智能体对动作的选择,动作空间也就相当于搜索空间。智能体获得的奖励会根据已训练架构在验证数据上的性能评估而定义。
模型部署
目前 EasyDL 有两种发布服务的方式,即生成在线 API 和离线 SDK。在线 API 能让开发者更方便地与业务系统整合,而离线 SDK 有更低的调用延迟,对互联网的依赖性也没有那么强,它可以利用本地计算资源实现更安全与稳定的计算。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号