进程切换和线程切换的区别?
我们都知道线程切换的开销比进程切换的开销小,那么小在什么地方?切换的过程是怎样的?
无论是在多核还是单核系统中,一个CPU看上去都像是在并发的执行多个进程,这是通过处理器在进程间切换来实现的。在任何一个时刻,单处理器系统都只能执行一个进程的代码。
- 操作系统实现这种交错执行的机制称为上下文切换。
- 操作系统保持跟踪进程运行所需的所有状态信息,这种状态,也就是上下文,它包括许多信息,例如PC和寄存器文件的当前值,以及主存的内容。
进程切换
系统中的每个程序都是运行在某个进程的上下文中的。
上下文是由程序正确运行所需的状态组成的,这个状态主要是存放在存储器中的程序的代码和数据、用户栈,通用目的寄存器的内容,程序计数器,环境变量以及打开文件描述符的集合、内核栈。
所以进程切换就是上下文切换。
- 通用目的寄存器
- 浮点寄存器
- 程序计数器
- 用户栈
- 状态寄存器
- 内核栈
- 各种内核数据结构:比如描绘地址空间的页表,包含有关当前进程信息的进程表,以及包含进程已打开文件的信息的文件表。
其实就是整个虚拟地址空间里的东西,包括用户空间和内核空间
线程切换
当然这里的线程指的是同一个进程中的线程。要想正确回答这个问题,需要理解虚拟内存。
虚拟内存
虚拟内存是操作系统为每个进程提供的一种抽象,每个进程都有属于自己的、私有的、地址连续的虚拟内存,当然我们知道最终进程的数据及代码必然要放到物理内存上,那么必须有某种机制能记住虚拟地址空间中的某个数据被放到了哪个物理内存地址上,这就是所谓的地址空间映射,那么操作系统是如何记住这种映射关系的呢,答案就是页表。
为了加速页表,还引入了高速缓存TLB
还需要的明确的是,页表是放在内存中,每个进程有自己的页表;TLB放再CPU MMU中,是进程间共享的(不是很准确的描述,后面会细讲)
每个进程有自己独立的虚拟地址空间,进程内的所有线程共享进程的虚拟地址空间
那回到最开始的问题,进程切换和线程切换有什么区别?
进程切换和线程切换的区别
最主要的一个区别在于进程切换涉及虚拟地址空间的切换而线程不会。因为每个进程都有自己的虚拟地址空间,而线程是共享所在进程的虚拟地址空间的,因此同一个进程中的线程进行线程切换时不涉及虚拟地址空间的转换。
为什么虚拟地址空间切换会比较耗时呢?因为cache和TLB会失效
Flushing the TLB
cache和TLB会失效的前提是它们的entry不会记录pid
一些处理器,每次上下文切换时都会刷新整个TLB,这可能会非常昂贵,因为这意味着新进程不得不经历缺页、查找页表和插入条目整个过程
有些处理器,会给每个TLB项添加一个额外的唯一字段ASID(address space ID),这意味这每个地址空间都有自己的ID,且标记在TLB上。因此上下文切换的时候TLB不需要被刷新,新来的进程讲会有不同的地址空间ID,甚至可以请求相同的虚拟地址,因为地址空间ID不同,翻译之后的物理地址也会不同。这种方式能减少清空、增加系统性能,但是需要更多的TLB硬件来存储ASIB位
进程和线程的区别
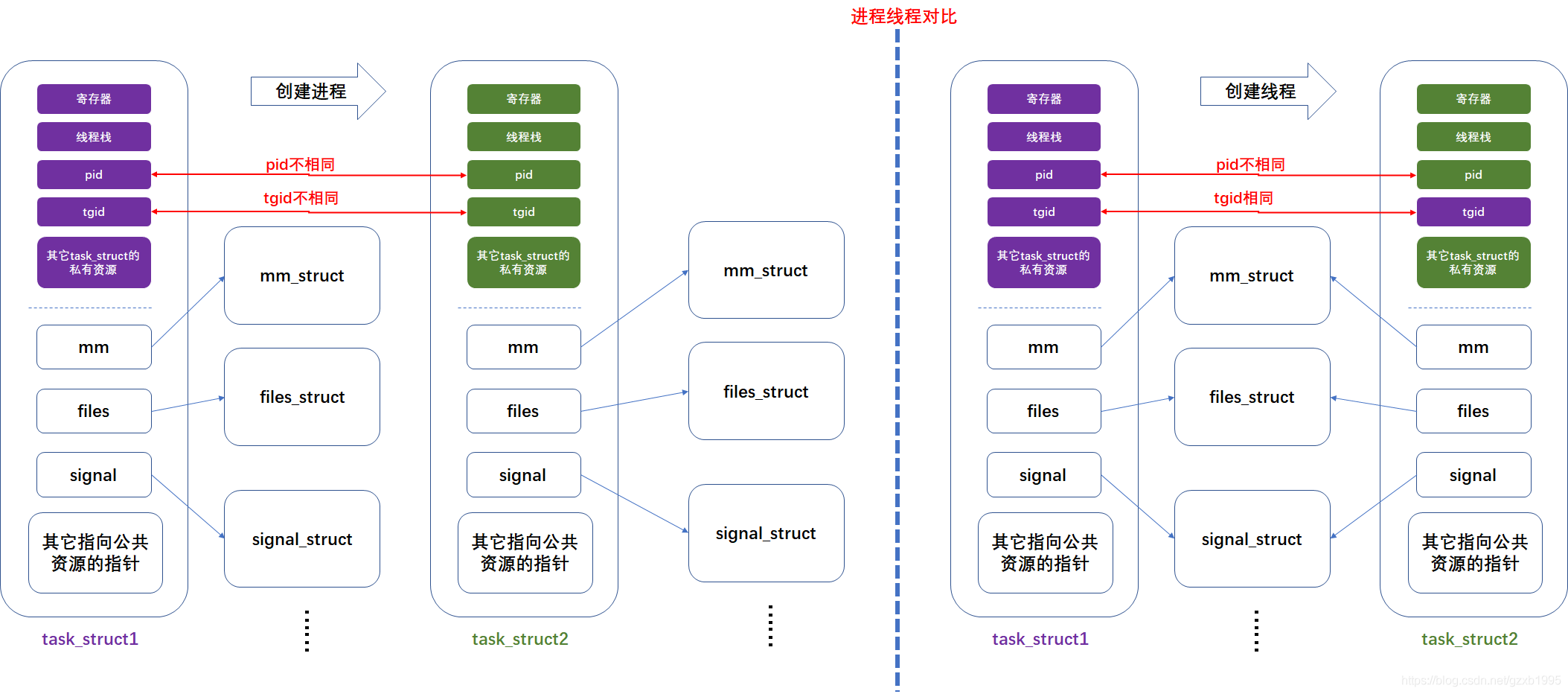
各种操作系统教材上往往会对进程、线程做出泾渭分明的定义或说明,也确实有操作系统实现了清晰的进程、线程抽象,但linux没有。linux没有为进程(process)和线程(thread)分别做抽象,而是使用一个名为task_struct的结构来描述调度的一个单元。对于那些进程拥有的公共资源,比如地址空间、打开的文件、信号等,linux分别使用相应的对象(结构体)来描述它们,例如描述进程地址空间的mm_struct。在task_struct中,不会完整的保存描述公共资源的对象,仅维护一个指向这些对象的指针。这样一来,假如两个task_struct中相应指针指向了同一个描述公共资源的对象实例,那么就说明这两个task_struct共享该公共资源,比如共享地址空间,共享打开的文件等。
体共享哪些东西是可以控制的,当我们使用clone系统调用去创建一个task_struct时,可以通过传参告诉内核新创建的任务与当前任务共享哪些资源。那么如何用task_struct去体现进程和线程呢?不难想到,假如两个task_struct不共享任何公共资源,它们就被视为两个进程;相反,如果两个task_struct共享所有公共资源,它们就被视为一个进程下的两个线程。事实上,linux中,用fork创建进程、用pthread_create创建线程,其内部都是通过调用clone,并为clone传递不共享/共享公共资源的参数来实现的,如下图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号