
DRF开发
DRF开发
web应用模式
我们之前学习到的Django框架,就是典型的web框架,专门用来开发web应用
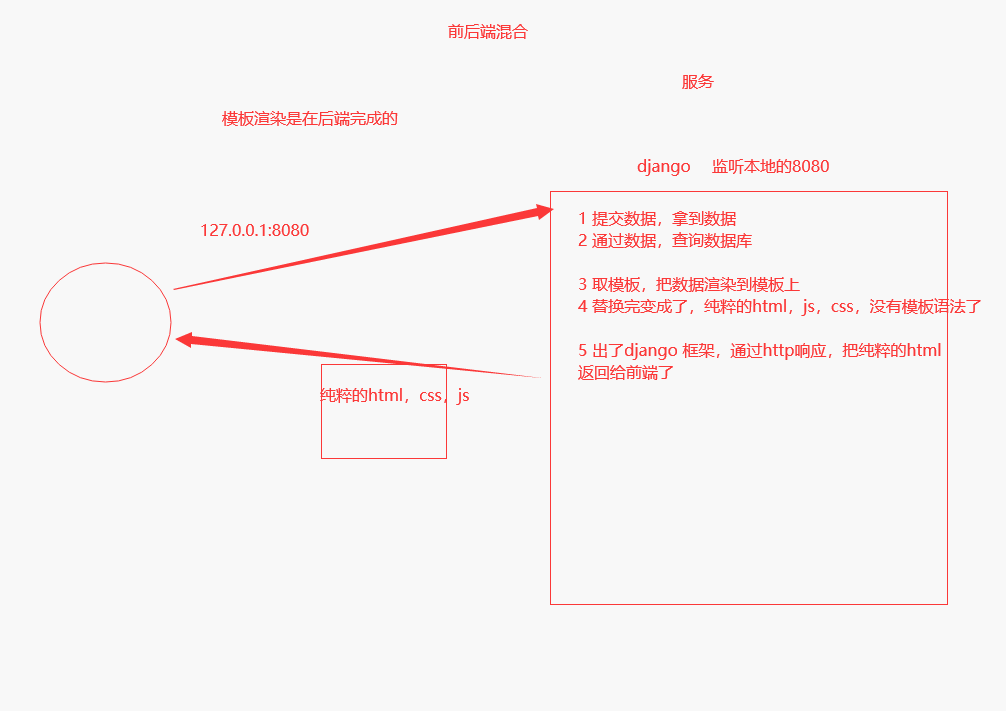
而在学习过程中,我们所编写的BBS及图书管理系统就属于web应用,采用的为前后端混合开发的模式
在前后端混合开发过程中,后端人员既要编写后端逻辑,也需要编写前端页面进行展示,而在前端展示时,需要使用模板语法将后端的数据渲染到前端页面进行展示
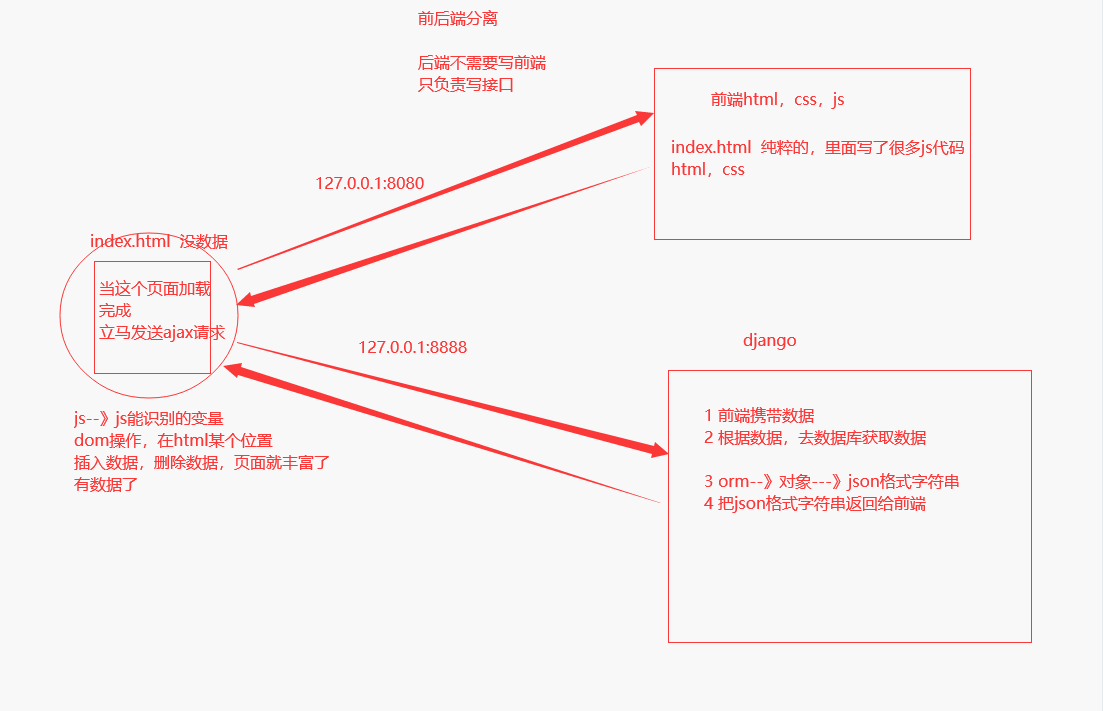
而另一种开发模式则为前后端完全分离,后端人员只需要编写后端逻辑并将数据返回供前端调用,而作为全栈开发,前端的编写由框架来完成,常用的框架有Vue与react两种
API接口
在前后端分离开发模式下,数据的携带与传输是需要按照固定的规范进行的,而这种方式就是我们接下来要学习的API接口,按照规范完成的API接口可以让前后端传递的数据的用途一目了然
而API最大的作用在于规定了前后端交互规则的URL,以此作为信息交互的媒介
http://127.0.0.1/books/
-url地址:
https://api.map.baidu.com/place/v2/search
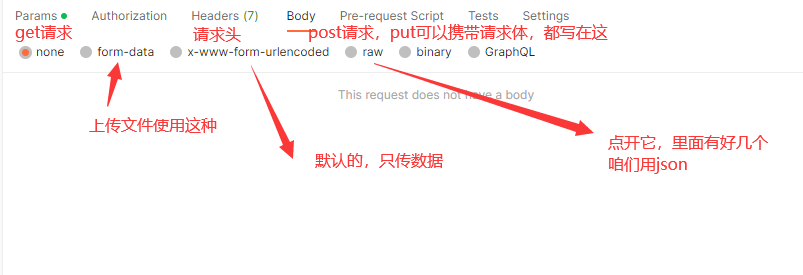
-请求方式:get,post,delete,put。。。。
-请求参数:json格式的key-value类型数据
-早些年:前后端交互使用xml格式----》ajax:异步JavaScript和XML
-后来,随着json格式的出现,成了主流,直到现在
-以后:一定会出现,比json更高效的交互格式,更安全
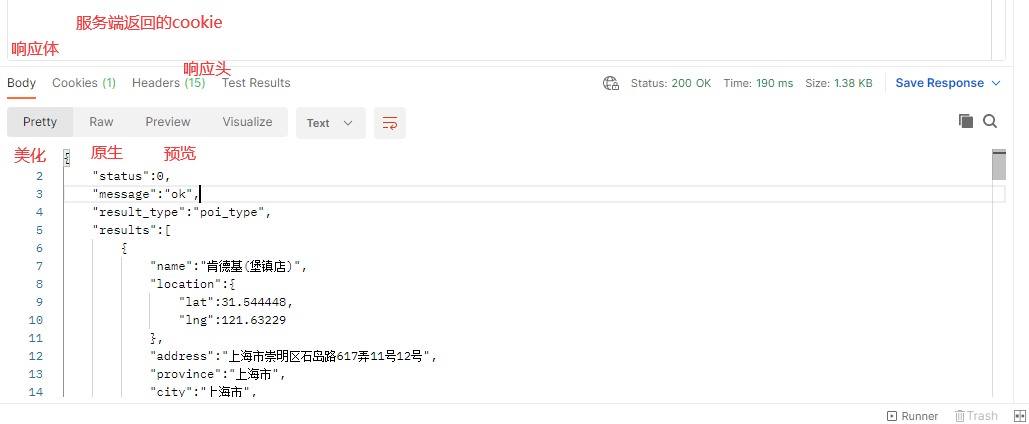
-响应结果:json格式的数据
接口实例
-https://api.map.baidu.com/place/v2/search?ak=6E823f587c95f0148c19993539b99295®ion=上海&query=肯德基&output=xml
-https://api.map.baidu.com/place/v2/search?ak=6E823f587c95f0148c19993539b99295®ion=上海&query=肯德基&output=json
6E823f587c95f0148c19993539b99295相当于固定的访问账号,而其中的汉字一般为百分号与字母的组合,而在这里使用汉字是因为在正常的字母符号经过解析后得到的依旧是对应的汉字
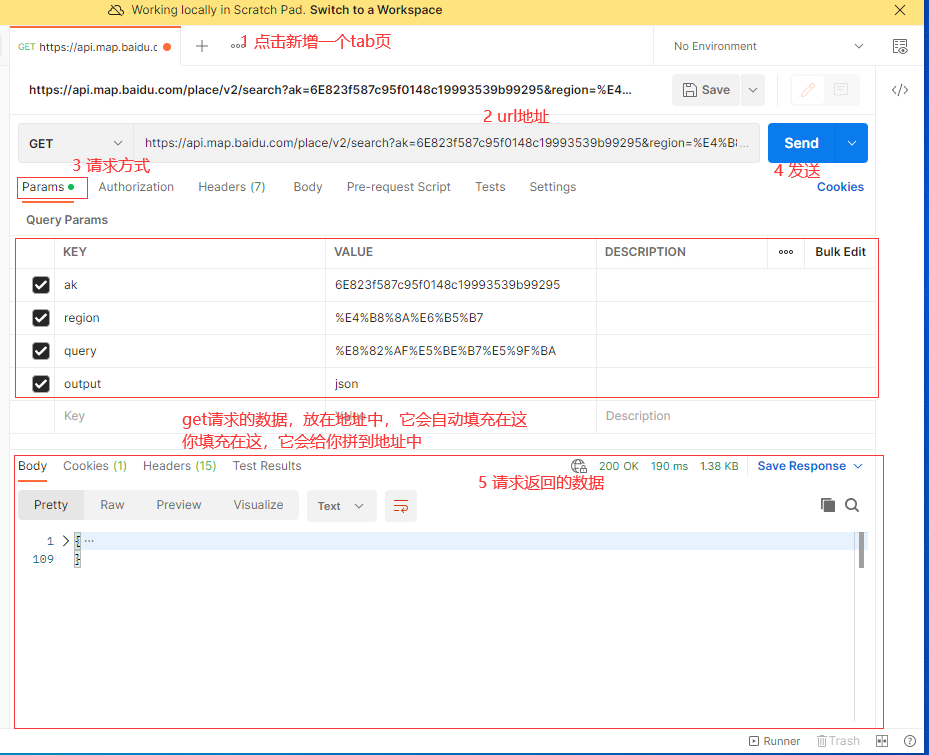
接口测试工具postman
在接口的编写完成后,首先需要我们自行进行测试,除了浏览器外,我们还可以使用专门有测试端口的测试工具
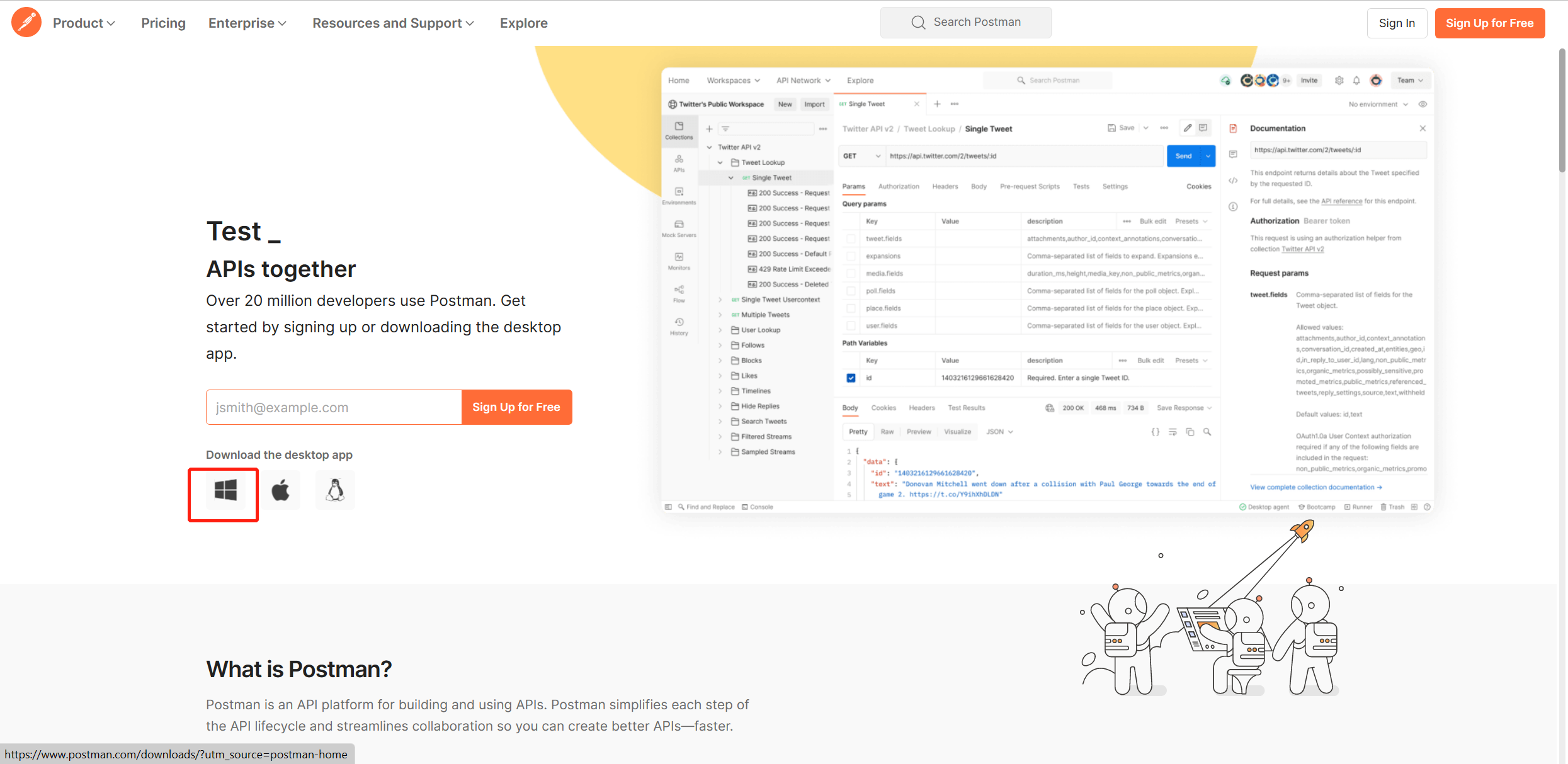
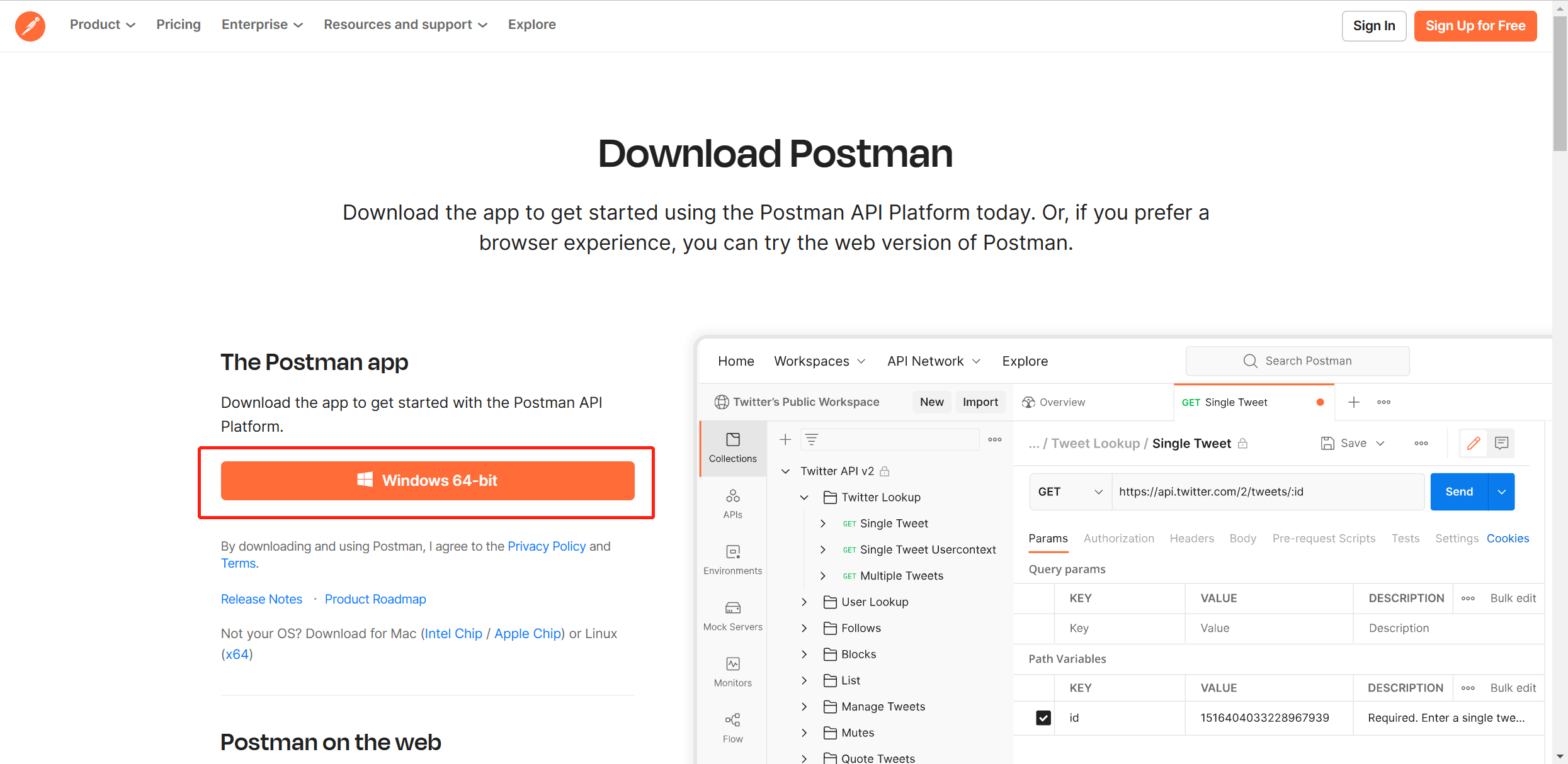
按照以上提示下载安装包后,安装即可
postman操作界面
restful规范
restful中rest的全称为Representational State Transfer,中文为表征性状态转移,首次出现于2000年Roy Fielding的博士论文中,RESTful是一种用来定义web API接口设计风格的规范,尤其是用于前后端分离的开发模式,可以使数据的传输及其用途简洁明了
- 数据安全保障---通常采用HTTPS协议完成
HTTPS即http+ssl/tsl,我们在接口中使用的url一般都是采用该协议进行传输,这样可以显著的提升数据在交互过程中的安全性
- 接口中需要带有api标识
常用的两种方式如下
https://api.lqz.com/books
https://www.lqz.com/api/books
不论是哪种方式都带有明确的api标识,而第二种方式是我们在学习过程中使用最多的
- 多版本共存,url中带有版本信息
https://api.lqz.com/v1/login
https://www.lqz.com/api/v2/login
在接口使用过程中,根据业务的拓展,会不断的更新迭代,这样接口也会有不同的版本,当多版本共存时,接口的url中需要带有明确的版本信息,以上实例中v1与v2就表明不同的版本号
- ⭐数据即资源,均用名词,尽量不出现动词
在前后端数据交互过程中,所使用到的数据都被称为资源
https://api.baidu.com/users
https://api.baidu.com/books
在以上实例最后出现的users与books就都是以名词的方式展现的,但是当前后端交互过程中,如果当一些特殊的接口没有明确的对应资源,我们就可以用动词来标识,而这时使用的动词应当可以明确地表达出接口的核心含义或业务逻辑
https://api.baidu.com/login
- 资源操作方式由传输方式(
method)决定
在之前的编写过程中,我们所写的业务逻辑一般都需要专门开设对应的路由,才可以完成对应的请求,但是在前后端分离的开发过程中,资源的增删改查都可以通过不同的请求方式来表示,以此完成增删改查动作
https://api.baidu.com/books - get请求:获取所有书
https://api.baidu.com/books/1 - get请求:获取主键为1的书
https://api.baidu.com/books - post请求:新增一本书书
https://api.baidu.com/books/1 - put请求:修改主键为1的书
https://api.baidu.com/books/1 - delete请求:删除主键为1的书
- 在请求发送使用的url中携带过滤条件
https://api.baidu.com/books?name=红&price=99
在发送请求的过程中,?之后携带的数据本身是不影响路由匹配的,那么当前后端分离后,我们可以借助于这种方式来携带一些数据作为过滤的条件
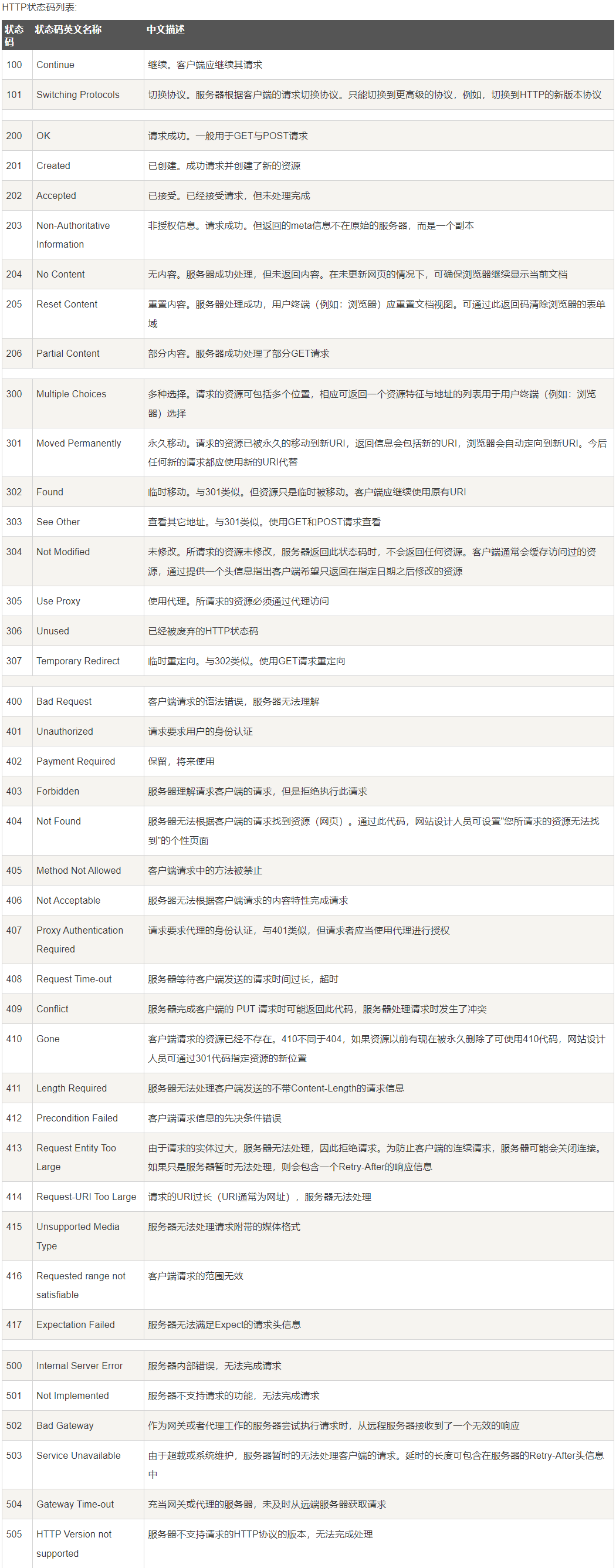
- 响应状态码
响应状态码一般会使用两套,一套是由http协议规定的,另一套是由公司内部规定并在开发过程中时用到的
http响应状态码
而公司内部使用的响应状态码,正常情况下都存放在响应体中,一般以10000为起始
{code:10000}
{status:10000}
以上两种都是常用的响应状态码表现形式
- 返回数据中携带错误信息
当我们从后端向前端返回数据时,字典往往是最优先考虑的数据类型,那么这时候除了相应的响应状态码之外,我们还应返回与状态码对应的错误信息
back_dict = {'code':10000
'msg':'ok/成功'}
- 返回结果应当符合一定规范
GET 获取所有数据:返回资源对象的列表(数组)[{name:红楼梦,price:99},{name:红楼梦,price:99},{name:红楼梦,price:99}]
GET 单个对象:返回单个资源对象:{name:红楼梦,price:99}
POST 新增对象:返回新生成的资源对象:{name:西游记,price:99}
PUT 修改对象:返回完整的资源对象 :{name:西游记,price:100}
DELETE 删除:返回一个空文档
- 响应数据中携带链接
{
"code": 1,
"info": {
"uin": 774740085,
"nickname": "ゆ、 音色 Cutey。",
"logo": "http:\/\/thirdqq.qlogo.cn\/g?b=sdk&k=E6OgxqD3YO5KL06CB9q1Dg&s=100&t=1566808348",
"vip": "1",
"svip": "1",
"vip-level": "9",
"vip-year": "1",
"level": "121",
"level-num": "15296",
"today-num": "7.6",
"today-speed": "3.2",
"nex-level-day": "76",
"one-crown-day": -10944,
"two-crown-day": 1600,
"three-crown-day": 22336,
"four-crown-day": 51264,
"dg": {
"phone": true,
"pc": "1",
"qzone": "1",
"eye": "1",
"medal": "1",
"weishi": "0",
"safe": "1",
"game": "1",
"walk": "1"
}
}
}
"logo": "http:\/\/thirdqq.qlogo.cn\/g?b=sdk&k=E6OgxqD3YO5KL06CB9q1Dg&s=100&t=1566808348"就是携带在返回数据中的链接
序列化与反序列化
接口的使用,最先要考虑到的就是数据的通用性,前后端分离开发,如何保障数据在交互过程中无论是在前端还是在后端都能够正常使用,最适合的就是数据转换
而数据的转换就需要使用到序列化与反序列化
序列化可以理解为将我们现有的数据转换为通用格式供前端使用,在python中我们可以使用JSON模块,将数据转换为JSON格式字符串,例如我们在django中获取到的数据默认是模型对象,但是模型对象数据无法直接提供给前端或别的平台使用,所以我们需要把数据进行序列化,变成字符串或者json数据,提供给前端使用,这个过程称之为read
反序列化则是恰巧相反,反序列化是使用JSON模块将通用的JSON格式字符串转换为我们可以使用的数据类型,然后将数据进行保存,例如前端js提供过来的json数据,对于python而言就是字符串,我们需要进行反序列化换成模型类对象,这样我们才能把数据保存到数据库中,这个过程称之为write
基于Django原生环境编写接口
基于Django原生环境编写接口,我们就需要使用CBV进行编写,然后按照对应的请求方式编写代码
class BooksView(View):
def get(self, request):
pass
def post(self, request):
pass
具体业务根据不同需求进行编写即可
# 以后写的接口,基本上都是5个接口及其变形
-查询所有
-查询单个
-新增一个
-修改一个
-删除一个
# 基于books单表为例,写5个接口
-创建book表
-表迁移
-录入假数据:直接录,后台管理录
-写查询所有接口---》遵循restful规范,使用cbv
-新增一个数据---》
-查询一个
-修改一个:put提交的数据,不能从requets.POST中取,需要从request.body提取
-删除一个
drf简介与快速使用
drf全称django rest framework,可以drf 帮助我们快速的实现符合restful规范的接口编写
需要注意的一点是当我们安装最新的drf时,python会自动将我们的Django版本更新为最新版,但是如果项目采用的是老版本Django,我们可以在安装完drf之后手动安装老版本的Django,这样不会出现项目的不兼容,也不会出现项目与框架的不兼容,因为虽然drf官方宣称只提供支持到Django的3.X版本,但是这并不影响使用
使用方法
# 使用drf编写5个接口
# views中
from .serializer import BookSerializer
from rest_framework.viewsets import ModelViewSet
class BookView(ModelViewSet):
queryset = Book.objects.all()
serializer_class = BookSerializer # serializer需要自己建py文件编写
# serializer
from rest_framework import serializers
from .models import Book
class BookSerializer(serializers.ModelSerializer):
class Meta:
model = Book
fields = '__all__'
# urls中
from rest_framework.routers import SimpleRouter
router = SimpleRouter()
router.register('books', views.BookView, 'books')
urlpatterns = [
path('admin/', admin.site.urls),
]
# 两个列表相加 [1,2,4] + [6,7,8]=
urlpatterns += router.urls
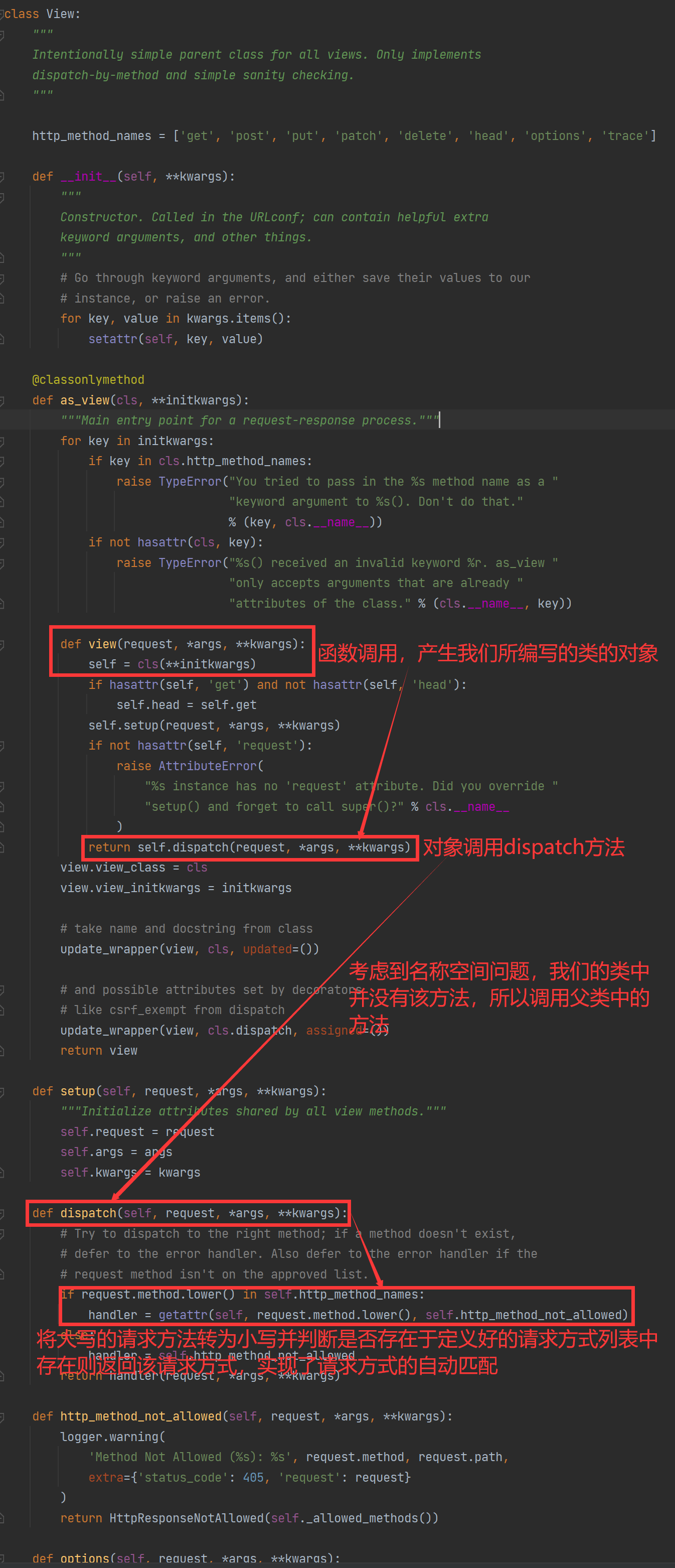
CBV源码分析
# 1 路由中写的:path('api/v1/books/', views.BookView.as_view()),第二个参数无论是fbv还是cbv放的都是函数内存地址
-当请求来了,匹配成功会执行,views.BookView.as_view()(request)
-views.BookView.as_view()执行结果是View的类方法as_view返回的结果是内层函数view,是个函数内层地址
-本身请求来了,匹配成功,会执行view(request)
def view(request, *args, **kwargs):
return self.dispatch(request, *args, **kwargs)
-self.dispatch View类的方法
def dispatch(self, request, *args, **kwargs):
# request.method请求方式转成小写,必须在列表中才能往下走
if request.method.lower() in self.http_method_names:
# 反射,去self【视图类的对象:BookView】,去通过get字符串,反射出属性或方法
# BookView的get方法
handler = getattr(self, request.method.lower(), self.http_method_not_allowed)
else:
handler = self.http_method_not_allowed
# BookView的get方法,加括号,传入request
return handler(request, *args, **kwargs)
基于类的识图(Class Based View),利用创建类的方式来进行视图函数的操作
from django import views
class MyLoginView(views.View):
def get(self, request):
return HttpResponse('from CBV get function')
def post(self, request):
return HttpResponse('from CBV post function')
如果使用CBV视图的话,路由与视图的绑定关系编写方法如下
path('login/', views.MyLoginView.as_view())
这样就可以实现自动根据不同的数据请求匹配对应的方法,我们也可以在对应的函数下添加操作,根据不同的路由返回不同的页面
那么views.MyLoginView.as_view()中的as_view()来自于哪里呢,根据名称空间的查找顺序,首先排除我们自己定义的类,那么我们通过查看源码的方式查找
这样看来,本质上绑定关系的的代码本质为
path('login/', views.view)
那么CBV的本质也还是FBV,那么它是怎么运行的呢
首先,当我们访问指定路由时,view加括号产生会产生我们自己编写的类的对象
利用反射获取到请求方式后就相当于完成了请求方式的自动匹配,这也就是CBV的实现原理
关键代码如下:
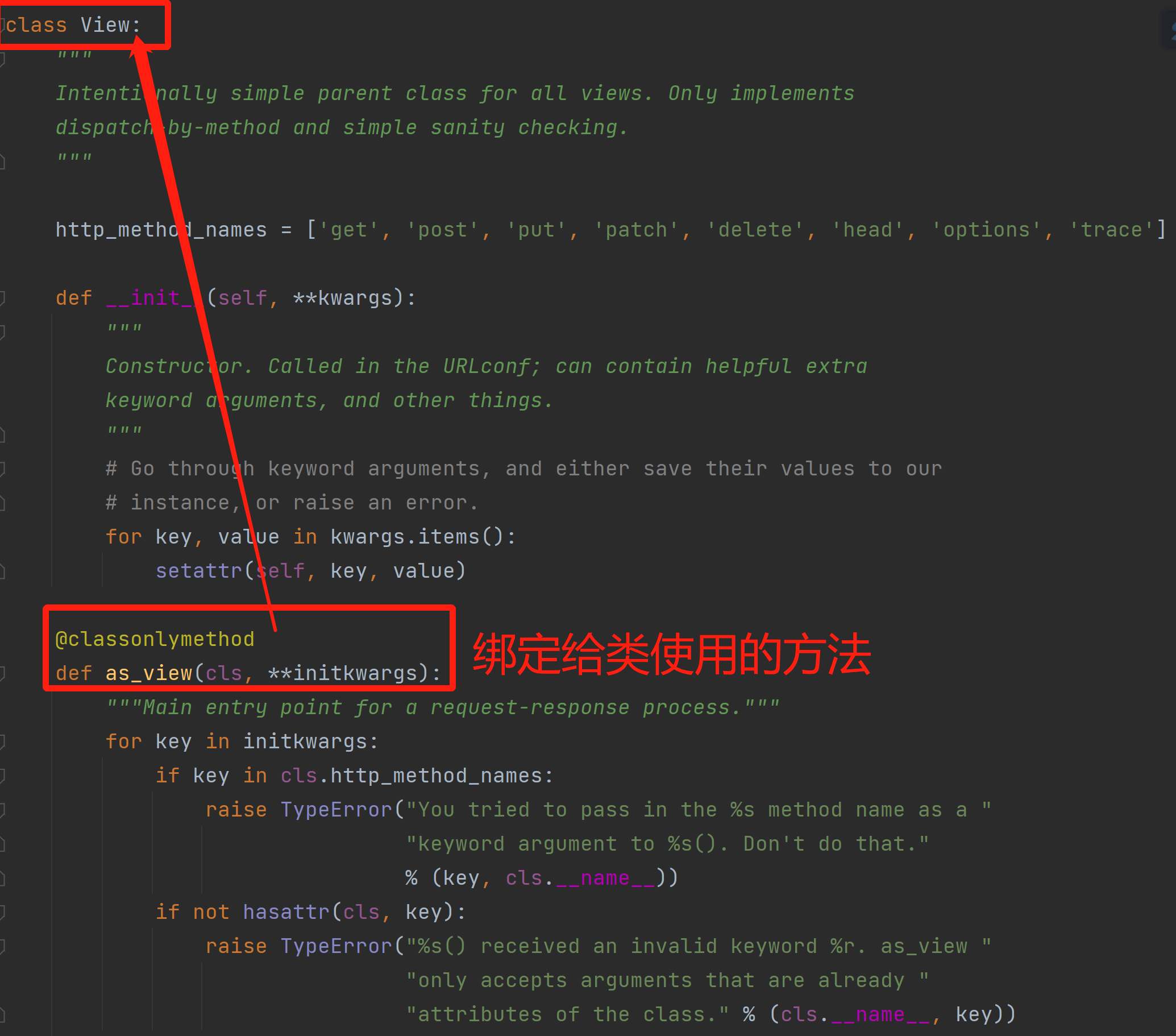
class View:
@classmethod
def as_view(cls, **initkwargs):
def view(request, *args, **kwargs):
self = cls(**initkwargs)
return self.dispatch(request, *args,**kwargs)
def dispatch(self, request, *args, **kwargs):
handler = getattr(self, request.method.lower())
return handler(request, *args, **kwargs)
APIView执行流程
- 基于
APIView+JsonResponse编写接口
基于原生的Django环境编写接口,需要自己编写view,并在此基础上编写接口,而drf继承并改写了原本的view,所以当我们使用APIView编写接口时,只需要继承APIView编写视图类即可
class BookView(APIView):
def get(self, request):
books = Book.objects.all()
book_list = []
for book in books:
book_list.append({'name': book.name, 'price': book.price, 'publish': book.publish})
return JsonResponse(book_list, safe=False)
# JSONresponse在使用时,由于数据是没有校验过的,所以需要添加safe参数
- 基于APIView+Response编写接口
在使用response返回数据时,就不需要再添加safe参数了
class BookView(APIView):
def get(self, request):
books = Book.objects.all()
book_list = []
for book in books:
book_list.append({'name': book.name, 'price': book.price, 'publish': book.publish})
return Response(book_list)
# 无论是列表还是字典都可以序列化
- APIView执行流程
首先我们先回顾一下之前as_view的执行
--path的第二个参数是:View类的as_view内部有个view闭包函数内存地址
一旦有请求来了,匹配test路径成功
--执行第二个参数view函数内存地址(requset)
--本质执行了self.dispatch(request)
--通过反射去获得方法 (假设是get方法) 的内存地址赋值给handler
--最后执行handler方法, 传入参数, 也就是触发了(get)方法的执行
那么我们按照该思路分析一下APIView执行流程
与CBV的源码分析过成一样, 我们也是从路由中的as_view()方法入手
1.首先创建一个DRF类来逐步分析
- views.py
from rest_framework.views import APIView
from rest_framework.response import Response
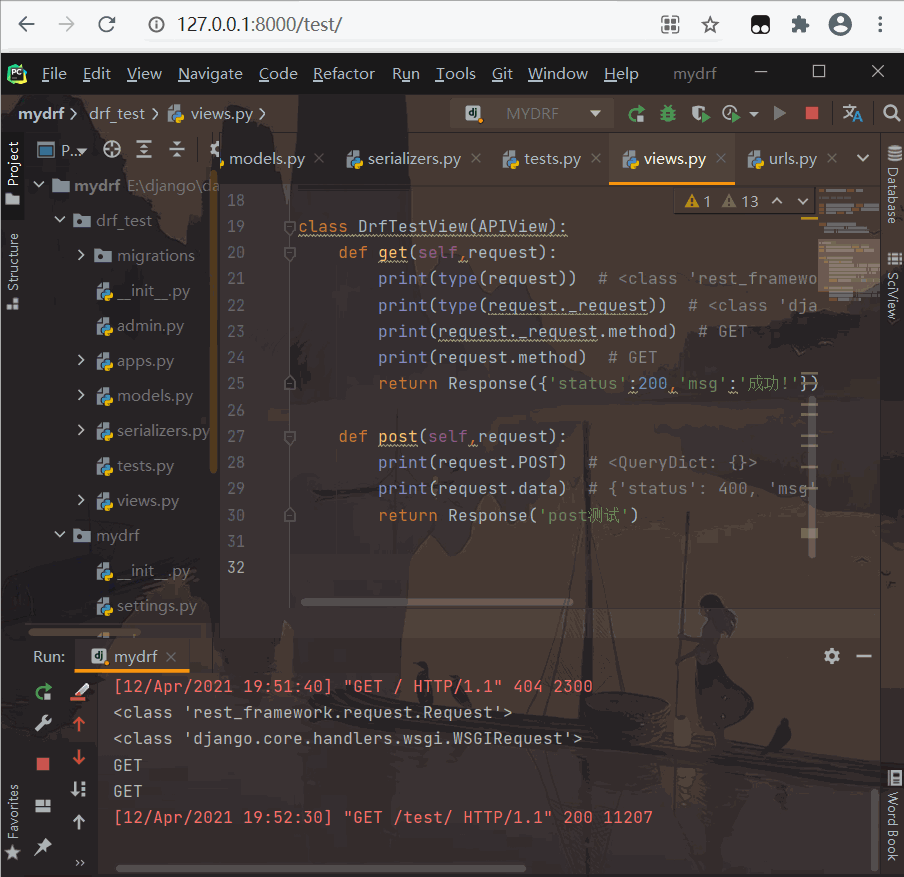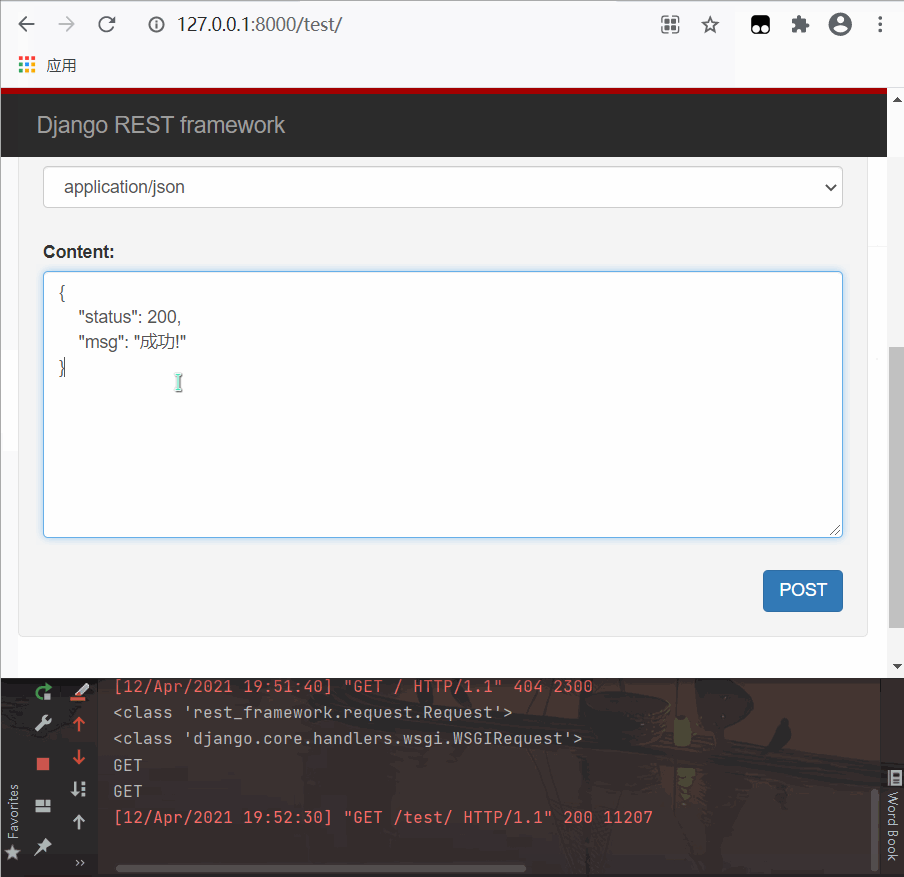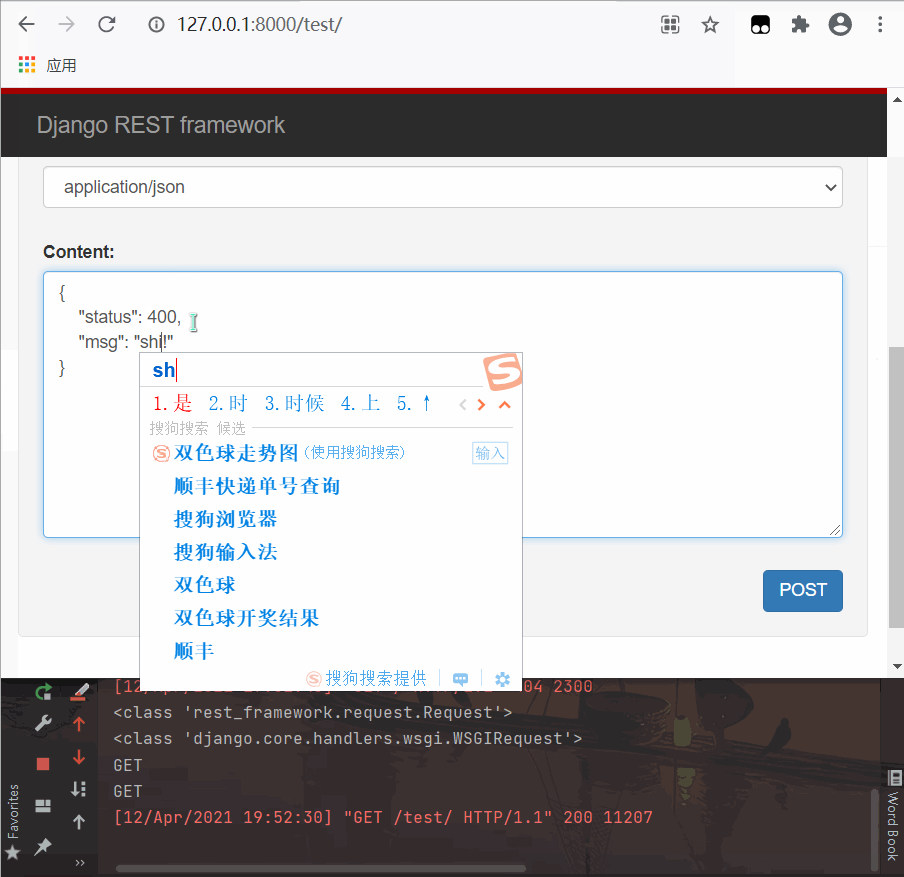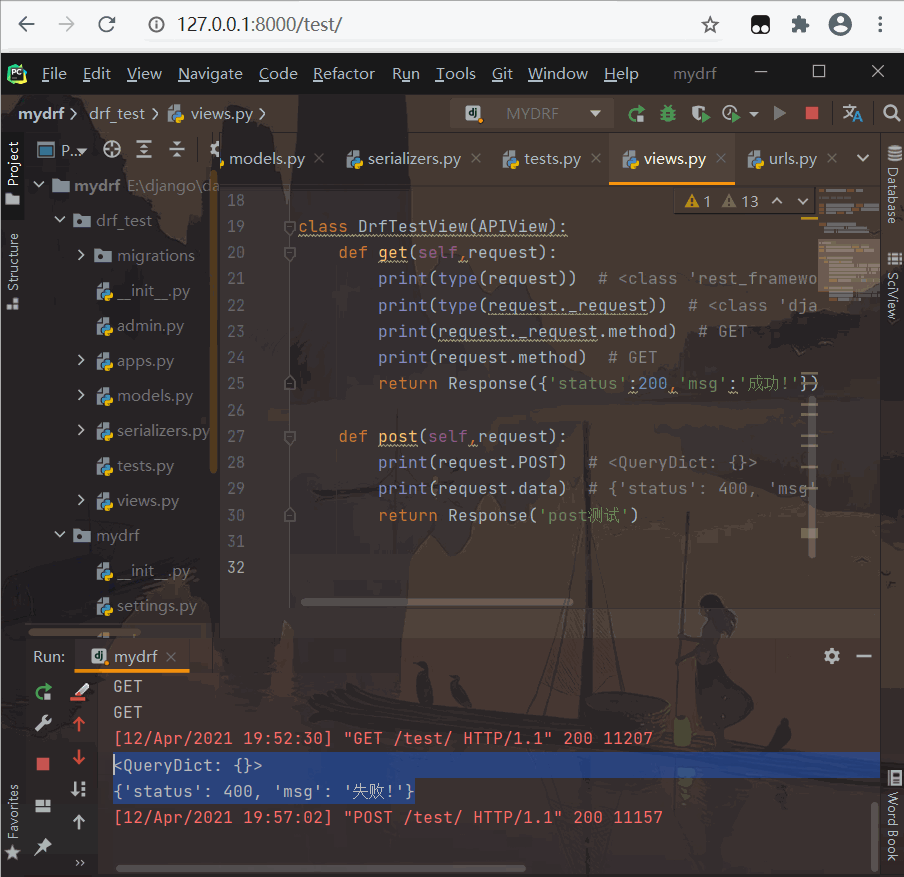
class DrfTestView(APIView):
def get(self,request):
print(type(request))
print(type(request._request))
print(request._request.method)
print(request.method)
return Response({'status':200,'msg':'成功!'})
def post(self,request):
print(request.POST)
print(request.data)
return Response('post测试')
123456789101112131415
- urls.py
path('test/', views.DrfTestView.as_view()),
1
2.分别使用 get, post 方式测试输出结果
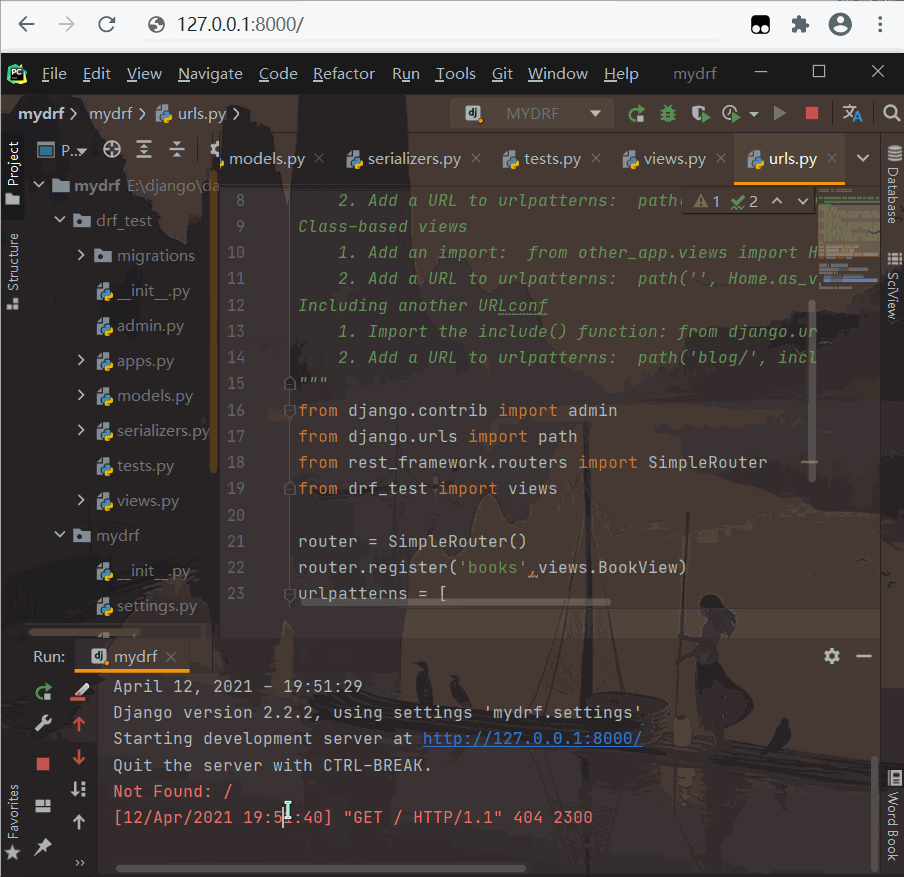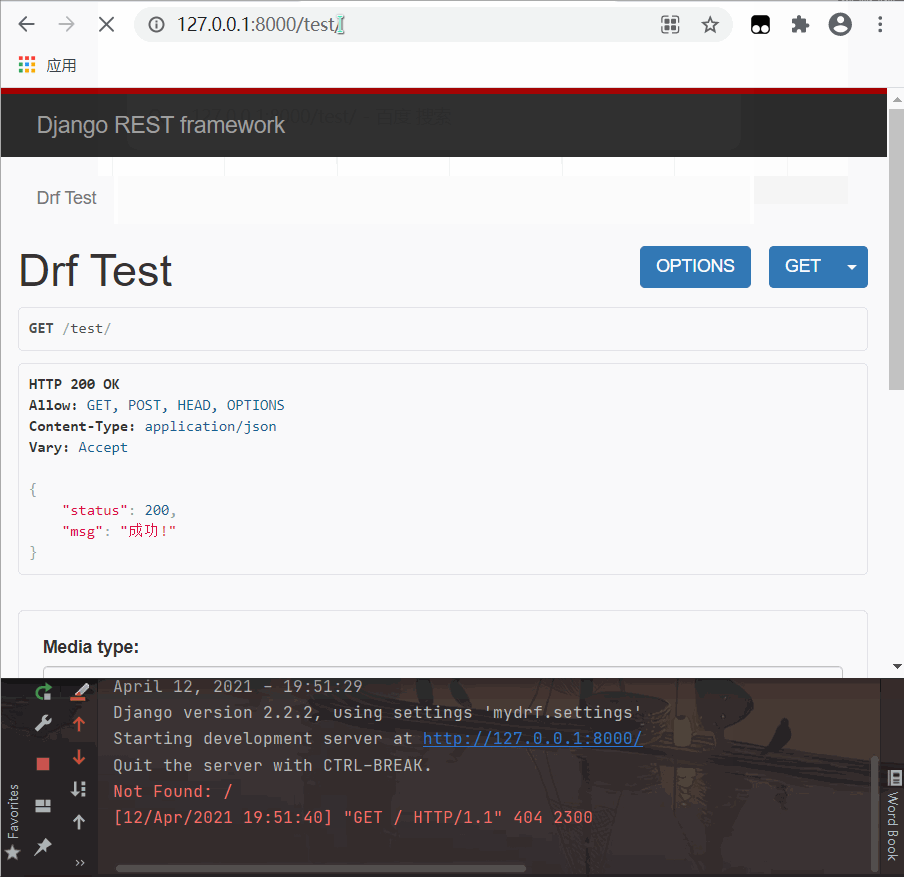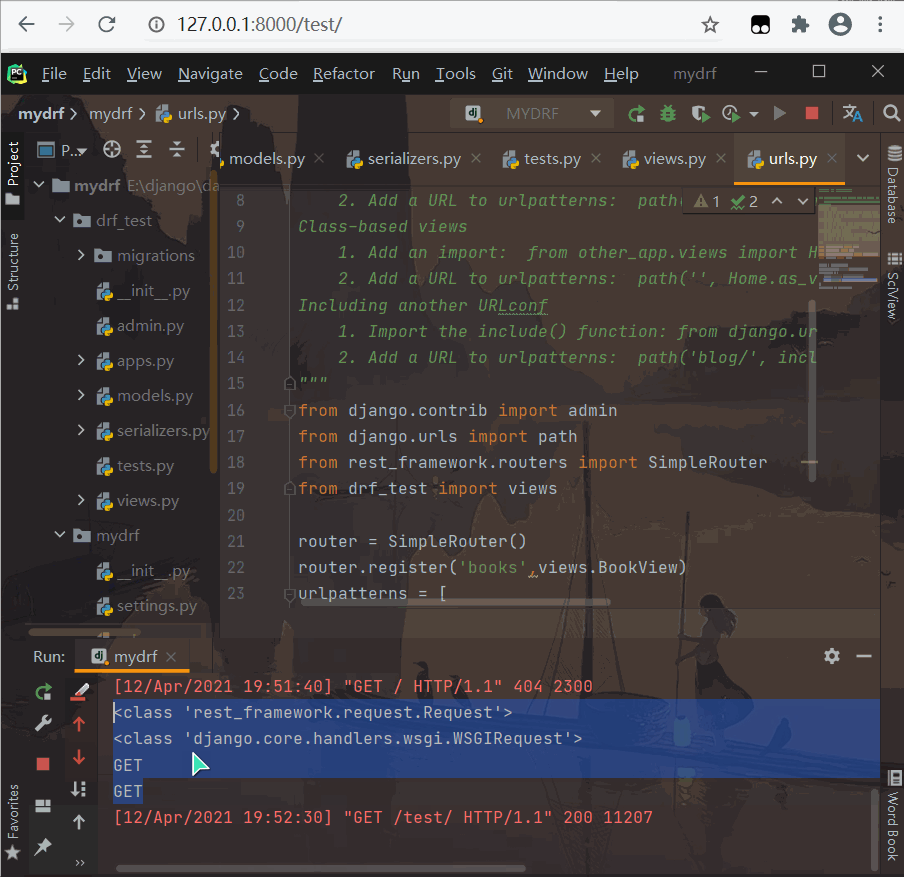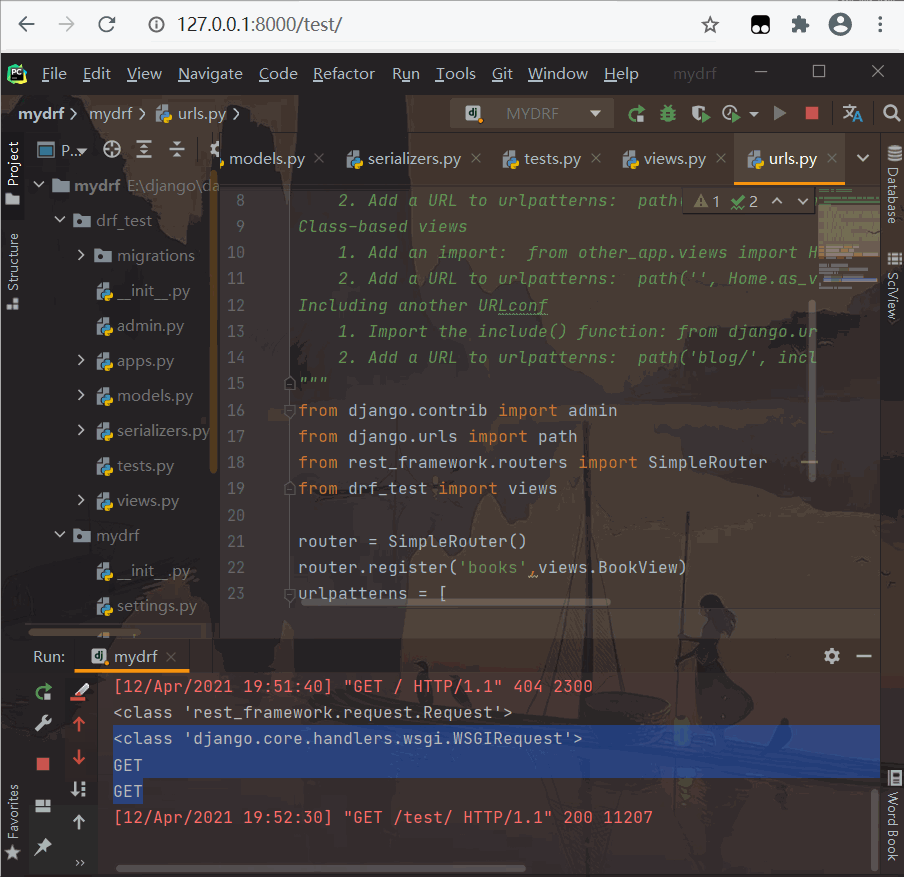
- get 请求测试
print(type(request))
# <class 'rest_framework.request.Request'>
print(type(request._request))
# <class 'django.core.handlers.wsgi.WSGIRequest'>
print(request._request.method) # GET
print(request.method) # GET
12345678
- post 请求测试
print(request.POST) # <QueryDict: {}>
print(request.data) # {'status': 400, 'msg': '失败!'}
12
3.疑问
- 为什么 Django的
request对象会变成 DRF的request对象 - 为什么 DRF 的
request也能取出 Django中request对象的属性 - 原生的
request对象去哪里了
4.分析流程
- 点击路由层中配置的
as_view()方法
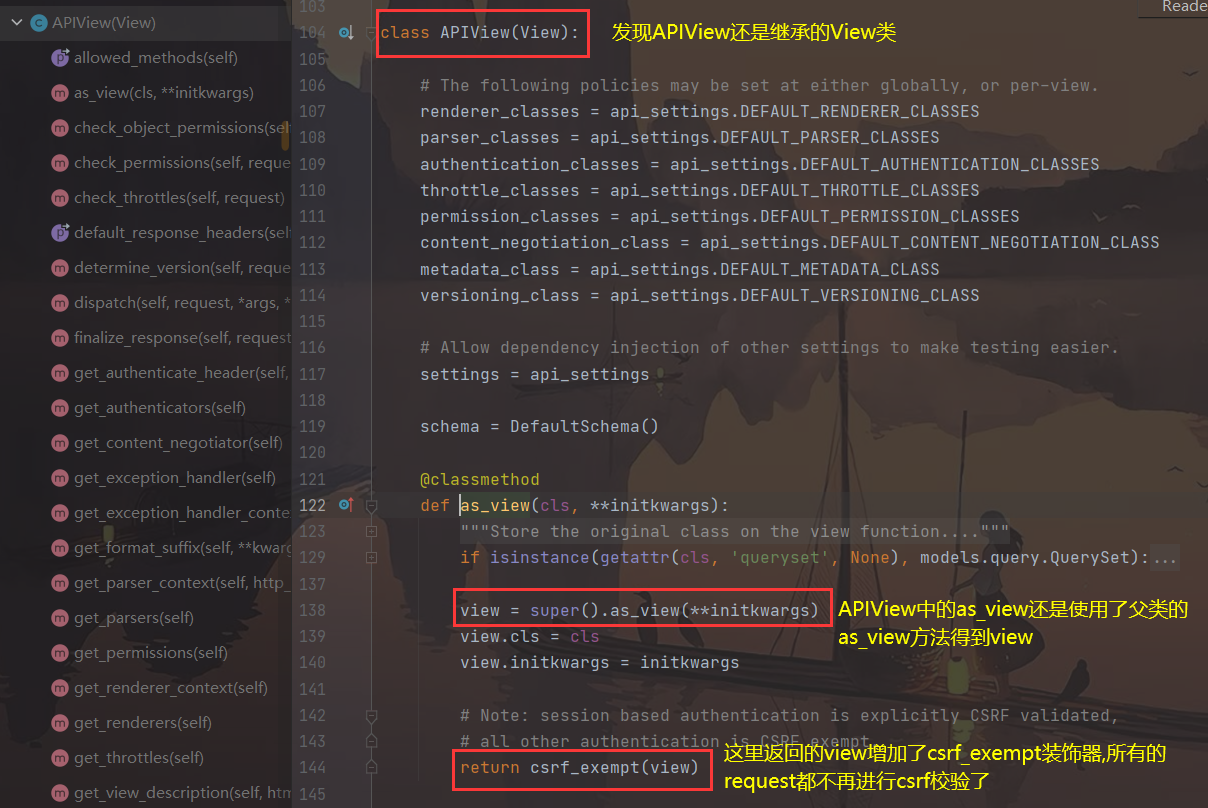
ps : 装饰器函数的原理 csrf_exempt
@csrf_exempt def test(): pass # 本质上就是将装饰器下方的函数当做参数传入 test=csrf_exempt(test) 123456
- 再去到父类 View 中看其源码
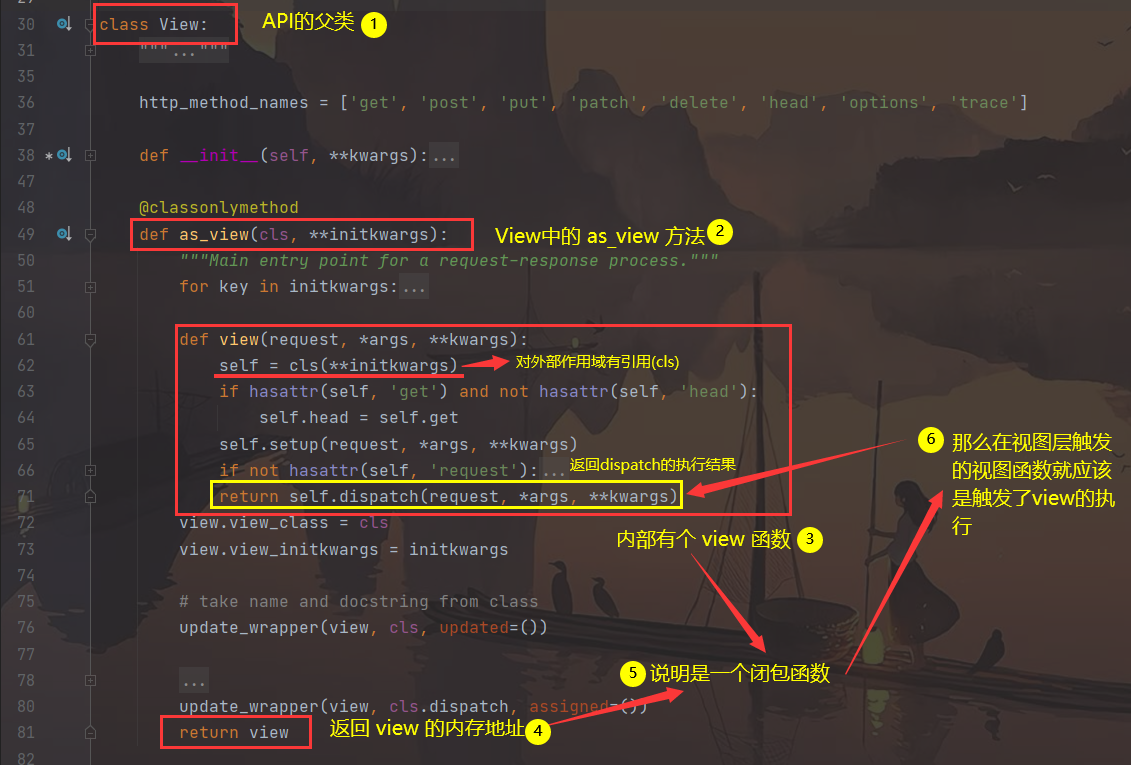
在
view方法中最后返回了dispatch方法, 属性的查找顺序, 先找自己, 再找父类, 所以先找到了自己(APIView)里面的dispatch方法
- 查看
dispatch方法里面的逻辑代码
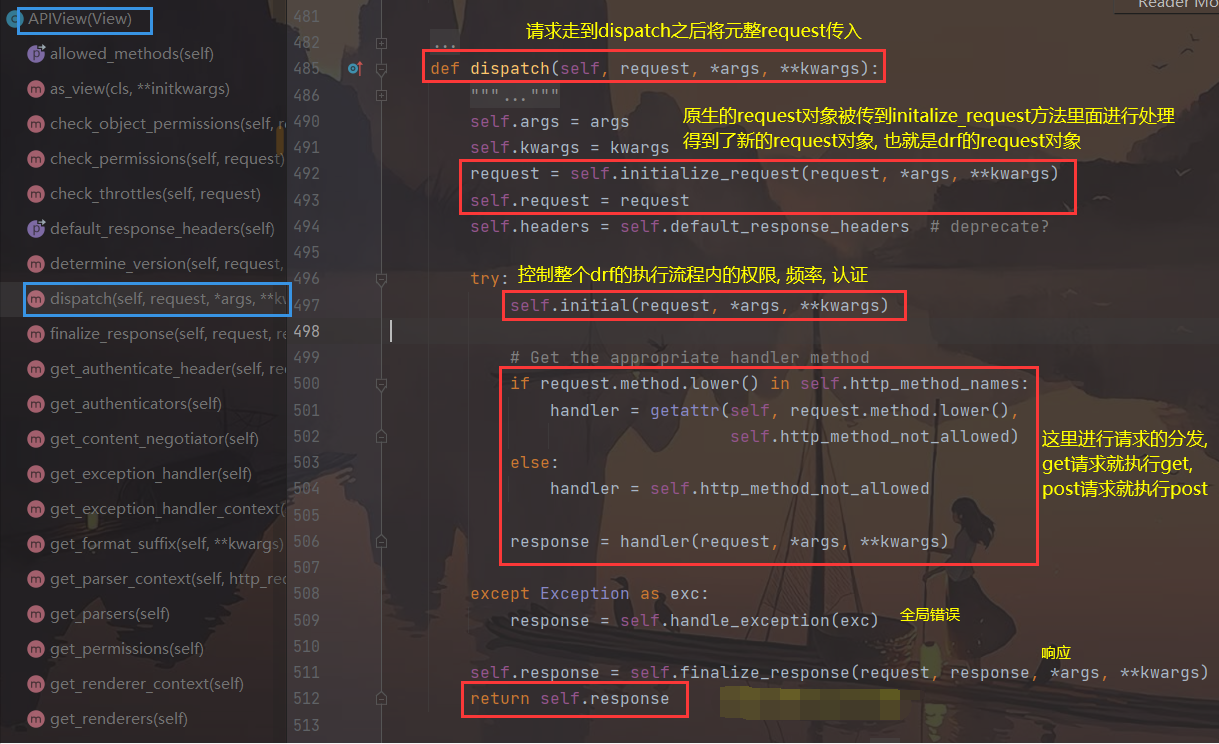
我们可以发现 APIView 对
dispatch方法进行了重写, 并且重写了不少内容
- 使用
initialize_request方法对原生request对象的封装- 认证、权限、频率控制
- 处理全局异常
- 处理全局响应
- 我们在查看
initialize_request方法如何进行封装
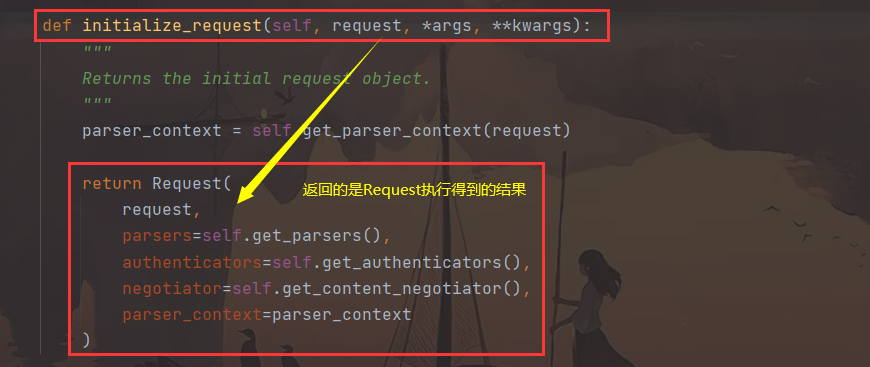
- 继续点进
Request查看
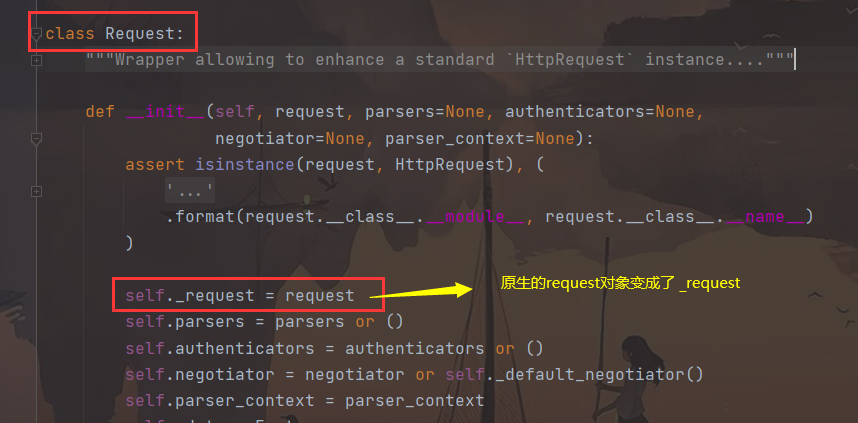
我们发现原生的
request对象在 DRF的request中变成了_request
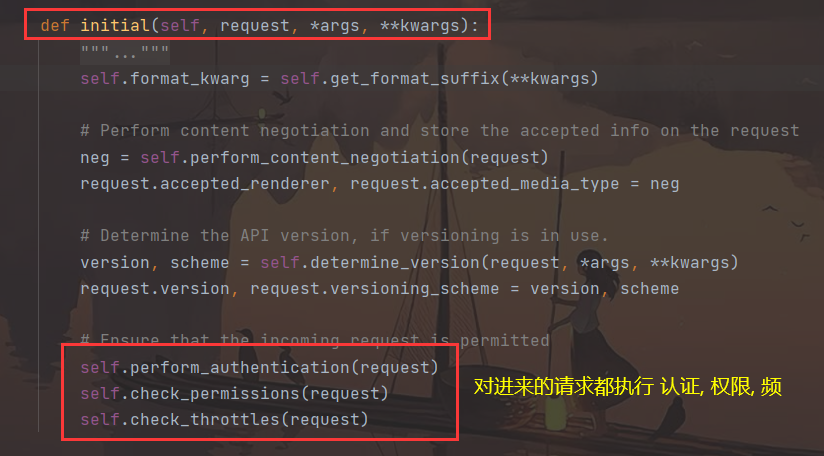
- 顺便看一下执行的 认证、权限、频率 (后边进行详细源码分析)
5.流程总结
- 请求来了, 匹配路由成功执行了APIView类的 as_view( ) 方法其内部是用了父类View的as_view( ) 方法, 执行了 view 闭包函数
- 但是加了个csrf_exempt装饰器,所以,继承了APIView的所有接口,都没有csrf的校验了
- 按顺序查找
dispatch方法, 想找自己, 再找父类, 结果自己里面重写了dispatch方法 - 在APIView中的dispatch方法中先把原来request封装进去,变成新的 DRF的request对象
- 接下来又执行了三个组件,分别是认证,权限和频率
- 处理了全局异常
- 再走分发方法,最后返回response
6.总结
- 所有的csrf都不校验了
- request对象变成了新的request对象,drf的request对象
- 执行了权限,频率,认证
- 捕获了全局异常(统一处理异常)
- 处理了response对象,如果浏览器访问是一个样,postman访问又一个样
- 以后,在视图类中使用的request对象已经不是原来的request对象了,现在都是drf的request对象了
Request 对象分析
1.通过以上对 APIView 的分析:
- Django原生request对象 :
django.core.handlers.wsgi.WSGIRequest - DRF 的 request 对象 :
rest_framework.request.Request - drf 的 request 对象中有原生的 request 对象 :
self._request

2.疑问
- 在视图类中使用
request对象, 从中取出想要的数据
# 正常取值应该是使用 "_request"
request._request.method
# 但我们使用的却是
request.method
12345
3.分析
- 我们猜想一定是其中重写了点拦截方法
__getattr__
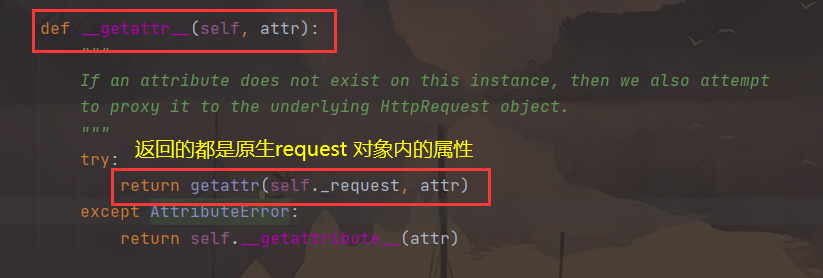
在 Response 类中找到
__getattr__, 当属性在 drf 中的 request 中找不到时, 就会通过反射的方式从原生的 request 对象中取值所以虽然视图类中request对象变成了drf的request,但是用起来,跟原来的一样,只不过它多了一些属性
-方法 __getattr__ -在视图类的方法中,执行request.method ,新的request是没有method的,就触发了新的Request的__getattr__方法的执行 def __getattr__(self, attr): try: # 从老的request中反射出 要取得属性 return getattr(self._request, attr) except AttributeError: return self.__getattribute__(attr) -request.data--->这是个方法,包装成了数据属性 -以后无论post,put。。放在body中提交的数据,都从request.data中取,取出来就是字典 -无论是那种编码格式 -request.query_params--->这是个方法,包装成了数据属性 -get请求携带的参数,以后从这里面取 -query_params:查询参数--->restful规范请求地址中带查询参数 -request.FILES--->这是个方法,包装成了数据属性 -前端提交过来的文件,从这里取
4.总结
- drf 的 request 对象用起来跟原来一样 (重写了
__getattr__) request.data: post请求提交的数据,不论什么格式,都在它中requst.query_params: get请求提交的数据 (查询参数), 也可以直接使用request.GET
序列化器介绍及使用
在写接口时,需要序列化与反序列化数据,而且反序列化的过程中要做数据校验(认证,频率,权限),drf直接提供了固定的写法,只要按照固定写法使用,就能完成上面的三个需求
drf提供了两个类Serializer、ModelSerializer
只需要写自己的类,继承drf提供的序列化类,使用其中的某些方法,就能完成上面的操作
- 序列化类基本使用,序列化多条
from rest_framework import serializers
class BookSerializer(serializers.Serializer):
# 序列化某些字段,这里写要序列化的字典
name = serializers.CharField()
# serializers下大致跟models下的类是对应的
price = serializers.CharField()
publish = serializers.CharField()
class BookView(APIView):
def get(self, request):
# 只是为了验证之前讲过的
print(request.method)
print(request._request)
print(type(self.request))
books = Book.objects.all()
# 使用序列化类来完成---》得有个序列化类
# instance要序列化的数据books、queryset对象
# many=True 只要是queryset对象要传many=True,如果是单个对象就不用传
ser = BookSerializer(instance=books, many=True)
return Response(ser.data) # 无论是列表还是字典都可以序列化
- 序列化单条
序列化类不需要改动
from rest_framework import serializers
class BookSerializer(serializers.Serializer):
name = serializers.CharField()
price = serializers.CharField()
publish = serializers.CharField()
视图类调整
class BookDetailView(APIView):
# def get(self, request,pk):
def get(self, request, *args, **kwargs):
book = Book.objects.filter(pk=kwargs.get('pk')).first()
# 序列化
ser = BookSerializer(instance=book)
return Response(ser.data)
路由层需要添加路由
urlpatterns = [
path('books/<int:pk>/', views.BookDetailView.as_view()),
]
反序列化
- 反序列化新增
序列化类
class BookSerializer(serializers.Serializer):
# 序列化某些字段,这里写要序列化的字典
name = serializers.CharField() # serializers下大致跟models下的类是对应的
price = serializers.CharField()
publish = serializers.CharField()
def create(self, validated_data):
# 保存的逻辑
# validated_data 校验过后的数据 {name,price,publish}
# 保存到数据库
book = Book.objects.create(**validated_data)
# 一定不要返回新增的对象
return book
视图层调整
class BookView(APIView):
def post(self, request):
# requset.data # 前端提交的要保存的数据----》校验数据---》存
ser = BookSerializer(data=request.data) # 把前端传入的要保存的数据,给data参数
# 校验数据
if ser.is_valid():
# 保存---->需要自己写,要在序列化类BookSerializer中写----》create方法
ser.save() # 调用ser.save,自动触发咱们写的create,保存起来
return Response({'code': 100, 'msg': '新增成功', 'result': ser.data})
else:
return Response({'code': 101, 'msg': ser.errors})
- 反序列化需要做的修改
序列化类
class BookSerializer(serializers.Serializer):
# 序列化某些字段,这里写要序列化的字典
name = serializers.CharField() # serializers下大致跟models下的类是对应的
price = serializers.CharField()
publish = serializers.CharField()
def create(self, validated_data):
# 保存的逻辑
# validated_data 校验过后的数据 {name,price,publish}
# 保存到数据库
book = Book.objects.create(**validated_data)
# 一定不要返回新增的对象
return book
def update(self, instance, validated_data):
# instance 要修改的对象
# validated_data 校验过后的数据
instance.name = validated_data.get('name')
instance.price = validated_data.get('price')
instance.publish = validated_data.get('publish')
instance.save() # orm的单个对象,修改了单个对象的属性,只要调用对象.save,就能把修改保存到数据库
return instance # 返回修改后的对象
视图层调整
class BookDetailView(APIView):
def put(self, request, pk):
book = Book.objects.filter(pk=pk).first()
# 借助于序列化类实现反序列化保存
ser = BookSerializer(data=request.data, instance=book)
if ser.is_valid():
ser.save() # 由于没有重写update,所以这报错
return Response({'code': 100, 'msg': '修改成功', 'result': ser.data})
else:
return Response({'code': 101, 'msg': ser.errors})
- 删除单条
在以上的基础上,只需要修改视图层中的视图类
class BookDetailView(APIView):
def delete(self, requset, pk):
Book.objects.filter(pk=pk).delete()
return Response({'code': 100, 'msg': '删除成功'})
这样,我们就已经完成了基于序列化器的五类接口的编写,这也将是我们在之后的开发过程中,用到最多的编写方法
反序列化校验
反序列化的数据校验类似于我们之前学习的钩子函数,对全局与局部的函数分别进行校验
class BookSerializer(serializers.Serializer):
# 序列化某些字段,这里写要序列化的字典
name = serializers.CharField() # serializers下大致跟models下的类是对应的
price = serializers.CharField()
publish = serializers.CharField()
def create(self, validated_data):
# 保存的逻辑
# validated_data 校验过后的数据 {name,price,publish}
# 保存到数据库
book = Book.objects.create(**validated_data)
# 一定不要返回新增的对象
return book
def update(self, instance, validated_data):
# instance 要修改的对象
# validated_data 校验过后的数据
instance.name = validated_data.get('name')
instance.price = validated_data.get('price')
instance.publish = validated_data.get('publish')
instance.save() # orm的单个对象,修改了单个对象的属性,只要调用对象.save,就能把修改保存到数据库
return instance # 不要忘了吧修改后的对象,返回
# 反序列化校验的局部钩子 ,名字不能以lf开头
def validate_name(self, name):
# 校验name是否合法
if name.startswith('lf'):
# 校验不通过,抛异常
raise ValidationError('不能以lf开头')
else:
return name
# 全局钩子
def validate(self, attrs):
# 校验过后的数据,书名跟出版社名字不能一致
if attrs.get('name') == attrs.get('publish'):
raise ValidationError('书名跟出版社名字不能一致')
else:
return attrs

