

dfs序详解!!看一篇就够了!(并不)
dfs序是一种非常好用的东西
毕竟谁不想要抛弃图论,怀抱数据结构呢
大体思想:
根据dfs遍历的顺序来为节点赋予权值,根据权值来为节点排序。
wzh:你这题解有病吧。明明是序号非得说成权值
LEWISAK:(苦笑)没办法,叫惯了
第一个遍历的(根节点)权值为1,第二个遍历的权值为二……以此类推
举个栗子吧!
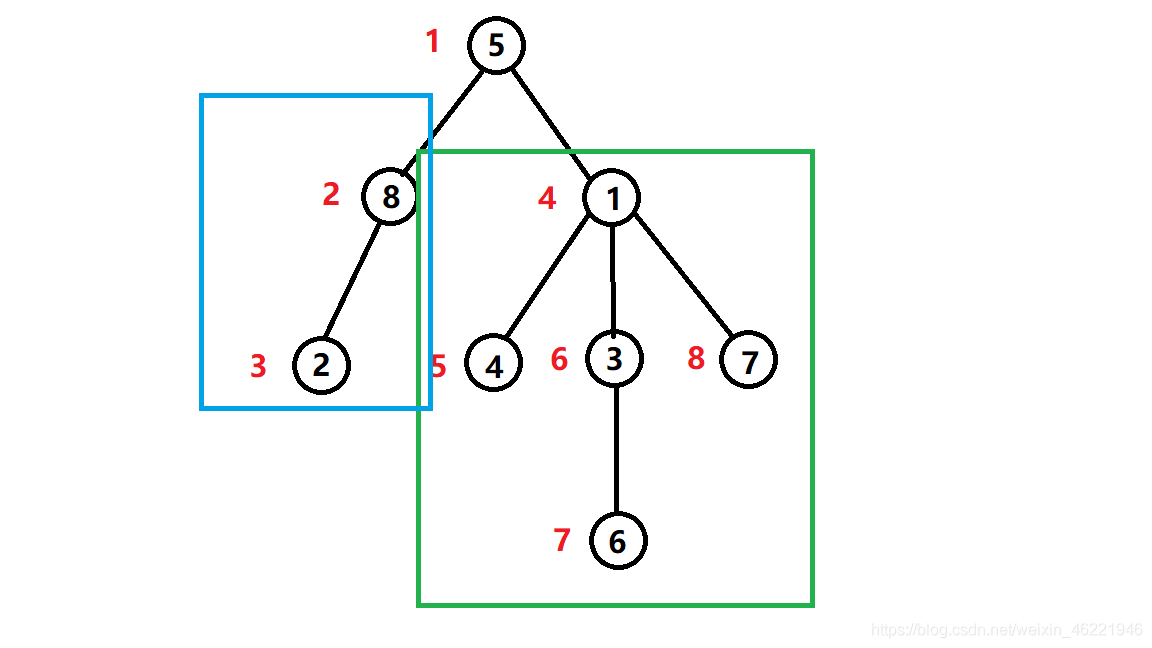
让我们人脑模拟一下dfs!
- 从5号节点开始遍历
- 先遍历左子树,8节点权值为2,2节点权值为3
- 再遍历右子树,1节点权值为4,4节点权值为5
- 作者要看原神PV,没时间写了,自己想吧。。
那么,可以注意到,被蓝框圈中的(根节点的左子树)的权值是连续的。
那么这就是dfs序的特点……
好吧,那我们再看一下绿色的框,(根节点的右子树)的编号也是连续的!
那么,这是怎么一回事呢?
显然,因为是同一个子树,就会被挨个访问,访问完后才会回溯。
那么,dfs序有什么用呢?
因为我们将子树的权值都赋为了相邻的,所以如果想要计算子树节点上的……
wzh:叫你把序号说成权值,现在好了,修改的要叫什么呢?
LEWISAK:诶,你好问题
读者你好,请把上面的“权值”遗忘掉,改为新的定义
计算子树上的权值之和时其实就是对数组区间修改。
正确的,dfs序的作用就是让图上操作可以用数据结构来维护!
好了,那这道题你肯定是手拿把掐!
不贴代码了吧
AC code
#include<bits/stdc++.h>
#define int long long
#define I using
#define am namespace
#define zxc std;
I am zxc
#define M 2000005
int tree[M],n,ans[M],in[M],out[M],cnt,a[M],m,r,head[M],num;
struct naosf{
int nxt;
int to;
}e[M];
void add(int u,int v){
e[++num].to=v;
e[num].nxt=head[u];
head[u]=num;
return;
}
int lowbit(int x){
return x&(-x);
}
int sum_(int x){
int ans=0;
for(int i=x;i;i-=lowbit(i)){
ans+=tree[i];
}
return ans;
}
void Add(int x,int y){
for(int i=x;i<=n;i+=lowbit(i)){
tree[i]+=y;
}
return;
}
void dfs(int x,int fa){
in[x]=++cnt;
Add(cnt,a[x]);
for(int i=head[x];i;i=e[i].nxt){
int v=e[i].to;
if(v!=fa){
dfs(v,x);
}
}
out[x]=cnt;
return;
}
signed main(){
cin>>n>>m>>r;
for(int i=1;i<=n;i++){
cin>>a[i];
}
for(int i=1;i<n;i++){
int u,v;
cin>>u>>v;
add(u,v);
add(v,u);
}
dfs(r,-1);
for(int i=1;i<=m;i++){
int t;
cin>>t;
if(t==1){
int tt,ttt;
cin>>tt>>ttt;
Add(in[tt],ttt);
}
else{
int tt;
cin>>tt;
cout<<sum_(out[tt])-sum_(in[tt]-1)<<endl;
}
}
}
本文作者:LEWISAK
本文链接:https://www.cnblogs.com/lewisak/p/18146975
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步