高性能队列disruptor为什么这么快?
背景
 Disruptor是LMAX开发的一个高性能队列,研发的初衷是解决内存队列的延迟问题(在性能测试中发现竟然与I/O操作处于同样的数量级)。基于Disruptor开发的系统单线程能支撑每秒600万订单,2010年在QCon演讲后,获得了业界关注。2011年,企业应用软件专家Martin Fowler专门撰写长文介绍。同年它还获得了Oracle官方的Duke大奖。
Disruptor是LMAX开发的一个高性能队列,研发的初衷是解决内存队列的延迟问题(在性能测试中发现竟然与I/O操作处于同样的数量级)。基于Disruptor开发的系统单线程能支撑每秒600万订单,2010年在QCon演讲后,获得了业界关注。2011年,企业应用软件专家Martin Fowler专门撰写长文介绍。同年它还获得了Oracle官方的Duke大奖。
目前,包括Apache Storm、Camel、Log4j2在内的很多知名项目都应用了Disruptor以获取高性能。
我们先知道disruptor是干什么的,然后笔者带你们源码搞一波,再来看看在log4j2中的运用。
一、Disruptor是什么?
可以这样总结,Disruptor是LMAX开源的、用于替代并发线程间数据交换的环形队列的、基本无锁的(只有部分等待策略存在)、高性能的线程间通讯框架。
Disruptor唯一可能遇到Java锁的时候,就是在消费者等待可用事件进行消费时。而Disruptor为这个等待过程,编写了包括使用锁和不使用锁的多种策略,可根据不同场景和需求进行选择。
开源:https://github.com/LMAX-Exchange/disruptor
二、Disruptor为什么这么快
1、环形队列RingBuffer
一个环形队列,意味着首尾相连,对列可以循环使用,使用数组来保存。环形队列在JVM生命周期中通常是永生的,GC的压力更小。
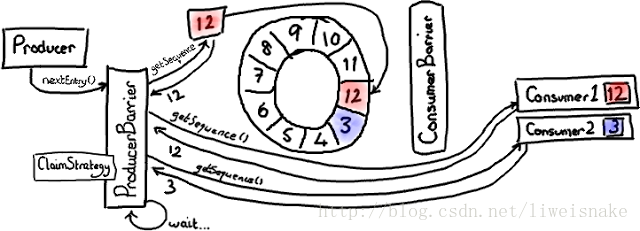
我们来解释一下这个图:当前有一个consumer,停留在位置12,这时producer假设在位置3,这时producer的下一步是如何处理的呢?producer会尝试读取4,发现下一个可以获取,所以可以安全获取,并且通知一个阻塞的consumer起来活动。如此一直到下一圈11都是安全的(这里我们假设生产者比较快),当producer尝试访问12时发现不能继续,于是自旋等待;当consumer消费时,会调用barrier的waitFor方法,waitFor看到前面最近的安全节点已经到了下一圈的11,于是consumer可以无锁的去消费当前12到下一圈11所有数据,可以想象,这种方式比起synchronized要快上很多倍。
2、弃用锁机制使用CAS
在高度竞争的情况下,锁的性能将超过原子变量的性能,但是更真实的竞争情况下,原子变量的性能将超过锁的性能。同时原子变量不会有死锁等活跃性问题。能不用锁,就不使用锁,如果使用,也要将锁的粒度最小化。
唯一使用锁的就是消费者的等待策略实现类中,下图。补充一句,生产者的等到策略就是LockSupport.parkNanos(1),再自旋判断。
| 名称 | 措施 | 适用场景 |
|---|---|---|
| BlockingWaitStrategy | 加锁 | CPU资源紧缺,吞吐量和延迟并不重要的场景 |
| BusySpinWaitStrategy | 自旋 | 通过不断重试,减少切换线程导致的系统调用,而降低延迟。推荐在线程绑定到固定的CPU的场景下使用 |
| PhasedBackoffWaitStrategy | 自旋 + yield + 自定义策略 | CPU资源紧缺,吞吐量和延迟并不重要的场景 |
| SleepingWaitStrategy | 自旋 + yield + sleep | 性能和CPU资源之间有很好的折中。延迟不均匀 |
| TimeoutBlockingWaitStrategy | 加锁,有超时限制 | CPU资源紧缺,吞吐量和延迟并不重要的场景 |
| YieldingWaitStrategy | 自旋 + yield + 自旋 | 性能和CPU资源之间有很好的折中。延迟比较均匀 |
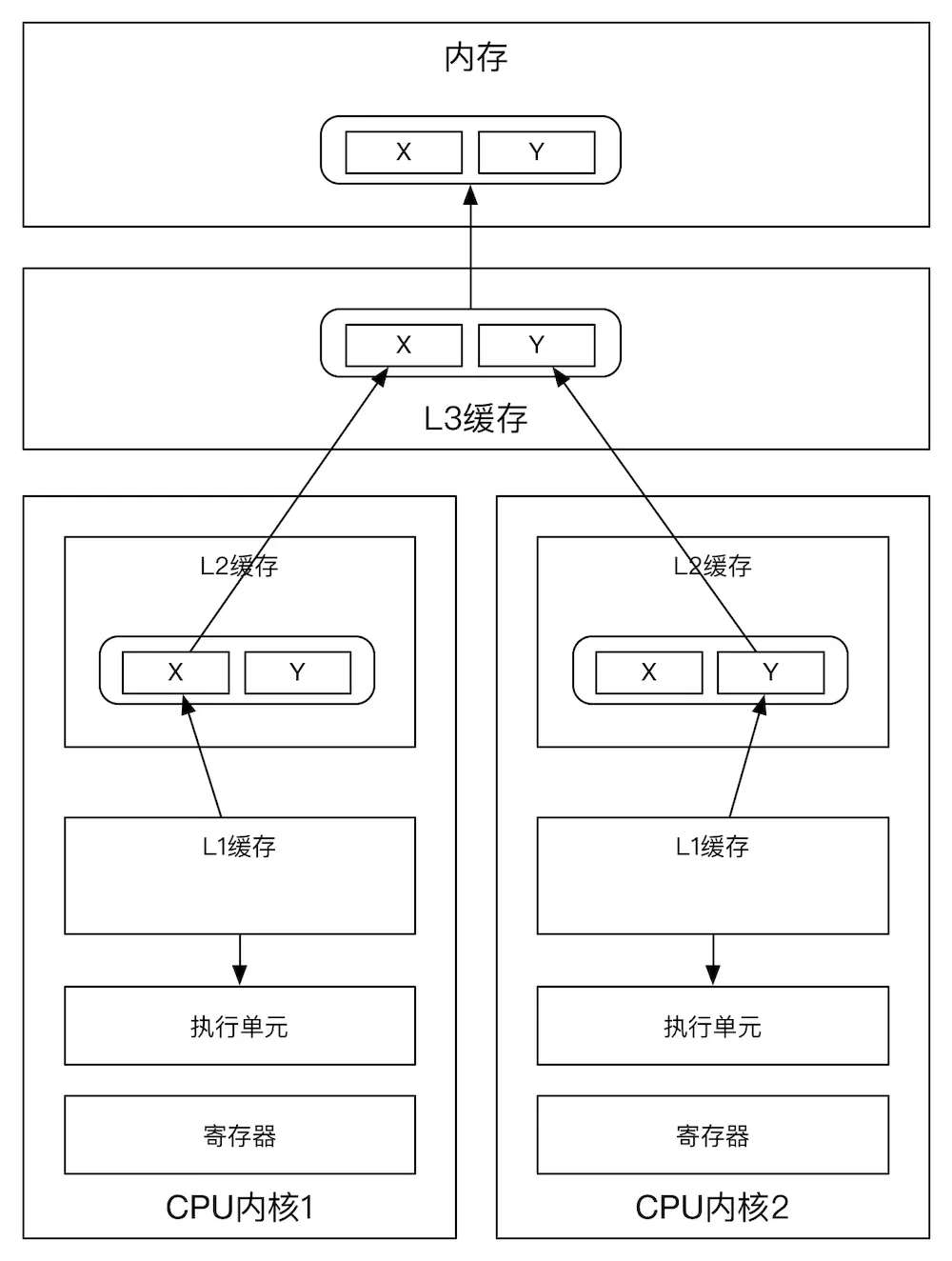
3、解决伪共享,采用缓存行填充
abstract class SingleProducerSequencerPad extends AbstractSequencer { protected long p1, p2, p3, p4, p5, p6, p7; SingleProducerSequencerPad(int bufferSize, WaitStrategy waitStrategy) { super(bufferSize, waitStrategy); } } public final class SingleProducerSequencer extends SingleProducerSequencerFields { protected long p1, p2, p3, p4, p5, p6, p7; //..省略 }
Java中通过填充缓存行,来解决伪共享问题的思路,现在可能已经是老生常谈,连Java8中都新增了sun.misc.Contended注解来避免伪共享问题。但在Disruptor刚出道那会儿,用缓存行来优化Java数据结构,这恐怕还很新潮。
4、还有一些细节性的
1)通过sequence & (bufferSize - 1)定位元素的index比普通的求余取模(%)要快得多。sequence >>> indexShift 快速计算出sequence/bufferSize的商flag(其实相当于当前sequence在环形跑道上跑了几圈,在数据生产时要设置好flag。
2)合理使用Unsafe,CPU级别指令。实现更加高效地内存管理和原子访问。
至于一些更细节的,下面源码搞起来,还是很简单的。
源码分析:Disruptor源码解读
参考:
https://tech.meituan.com/disruptor.html
https://www.jianshu.com/p/c3c108c3dcfd

 浙公网安备 33010602011771号
浙公网安备 33010602011771号