MQ初窥门径【面试必看的Kafka和RocketMQ存储区别】

MQ初窥门径
全称(message queue)消息队列,一个用于接收消息、存储消息并转发消息的中间件
应用场景
用于解决的场景,总之是能接收消息并转发消息
- 用于异步处理,比如A服务做了什么事情,异步发送一个消息给其他B服务。
- 用于削峰,有些服务(秒杀),请求量很高,服务处理不过来,那么请求先放到消息队列里面,后面按照能力处理,相当于蓄水池。
- 应用解耦、消息通讯等等
总之MQ是可以存放消息并转发消息的中间件,场景取决于拿这个能力去解决什么问题
MQ概念模型
MQ向别人承诺的场景是接收消息,存储,并可以转发消息
接收消息
接收消息,那么接收谁的消息,为了说明这个问题,那么mq需要引入一个概念,叫做生产者,也就是发送消息的服务,否则没有办法来区分是谁发的消息,生产者通过网络发送消息就可以,中间的细节我们先不探讨。
那么还有一个问题就是消息发送给谁?
- 我在发送消息的时候,指明我要发送给谁,就像发送短信一样,你需要指明你要发送给谁?
这种方案在使用中是有问题的,因为在现在业务很多场景中, 发送方其实根本不知道对方是谁,他只是将自己的状态发送出来,那么谁需要这个消息,谁就接收,第二个如果指明了接收方,那么以后增加一个接收方就要改一下配置或者代码,将发送消息的人跟接收消息的人绑定在一起了
那么有没有方案,解耦的最好办法就是中间人,也叫中间层,我只发送给第三方,谁要消息,问第三方要,那么相当于我把发送的目标改为发送给第三方,这里的第三方就是mq,为了说明说明发送的地方,mq引入了topic的概念,发送方把消息发送到mq指定的一个通道中,以后谁想要这个消息,就跟mq说我想要这个通道的消息,也就是发送方发送的消息。
消费消息
消费消息,那么同理的一个问题,谁消费消息,为了说明那么mq需要引入一个概念,叫做消费者,也就是消费消息的服务,否则没有办法来区分是谁在接收消息,消费者通过网络接收消息就可以了,中间的细节我们先不探讨。
那么问题来了,消费者怎么说明消费谁的消息,上文已经说了,通过指明mq的topic,来决定我要哪一类消息。
至此我们总结一下最后的模型
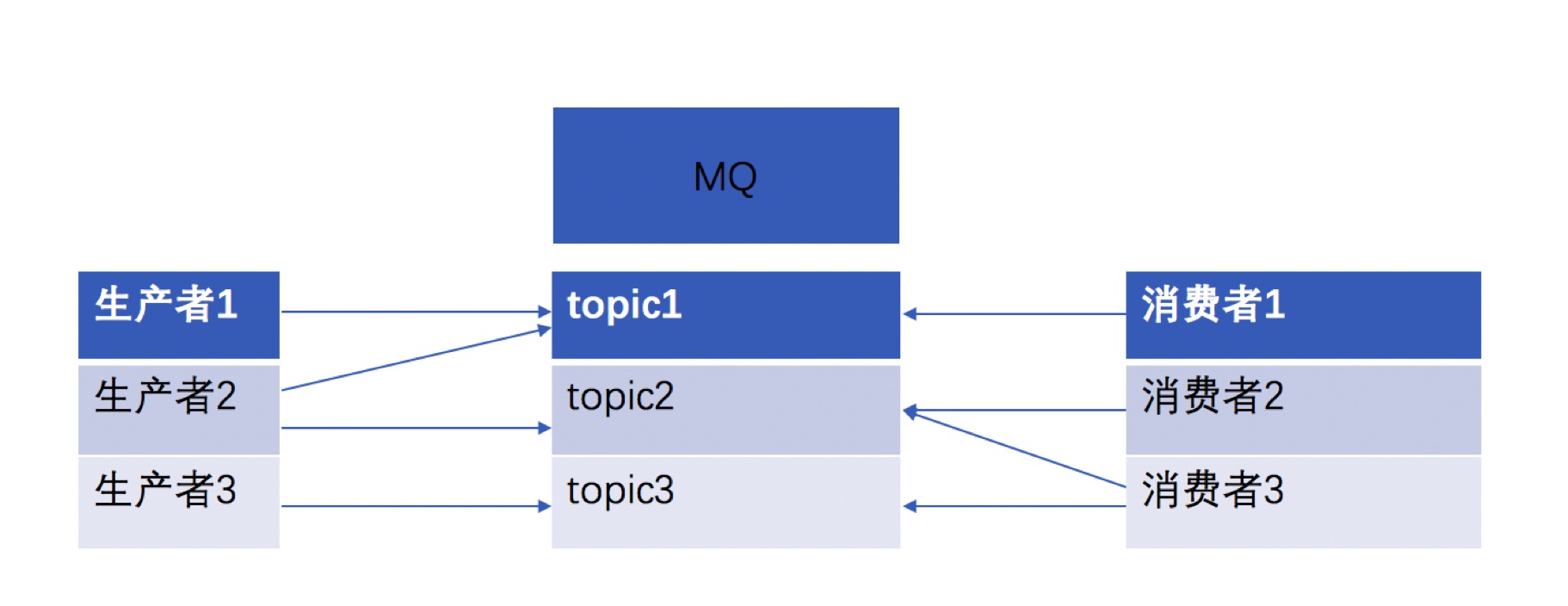
也就是最后生产者和消费者通过MQ的topic概念来实现解耦。
存储
说到存储,其实效率才是最主要的,容量不是我们关心的,但是说到存储,不只是mq,所有需要高效率的存储其实最后利用的核心都是一样的。
- 随机写转换成顺序写
- 集中刷盘
为什么随机写要转换为顺序写?
第一 现在主流的硬盘是机械硬盘
第二 机械硬盘的机械结构一次读写时间 = 寻道时间 + 旋转延迟 + 读取数据时间
那么寻道时间比较长,如果是顺序写,只需要一次寻道时间,关于机械硬盘整个过程,读者可自行google。
为什么集中刷盘?
因为每次刷盘都会进行系统调用,第二还是跟硬盘的本身属性有关,无论是机械硬盘还是ssd按照一定块刷盘会比小数据刷盘效率更好
kafka
为什么先说kafka的存储,因为kafka是第一个高性能的消息中间件,其中rocketmq也是借鉴于它,所以我们先说。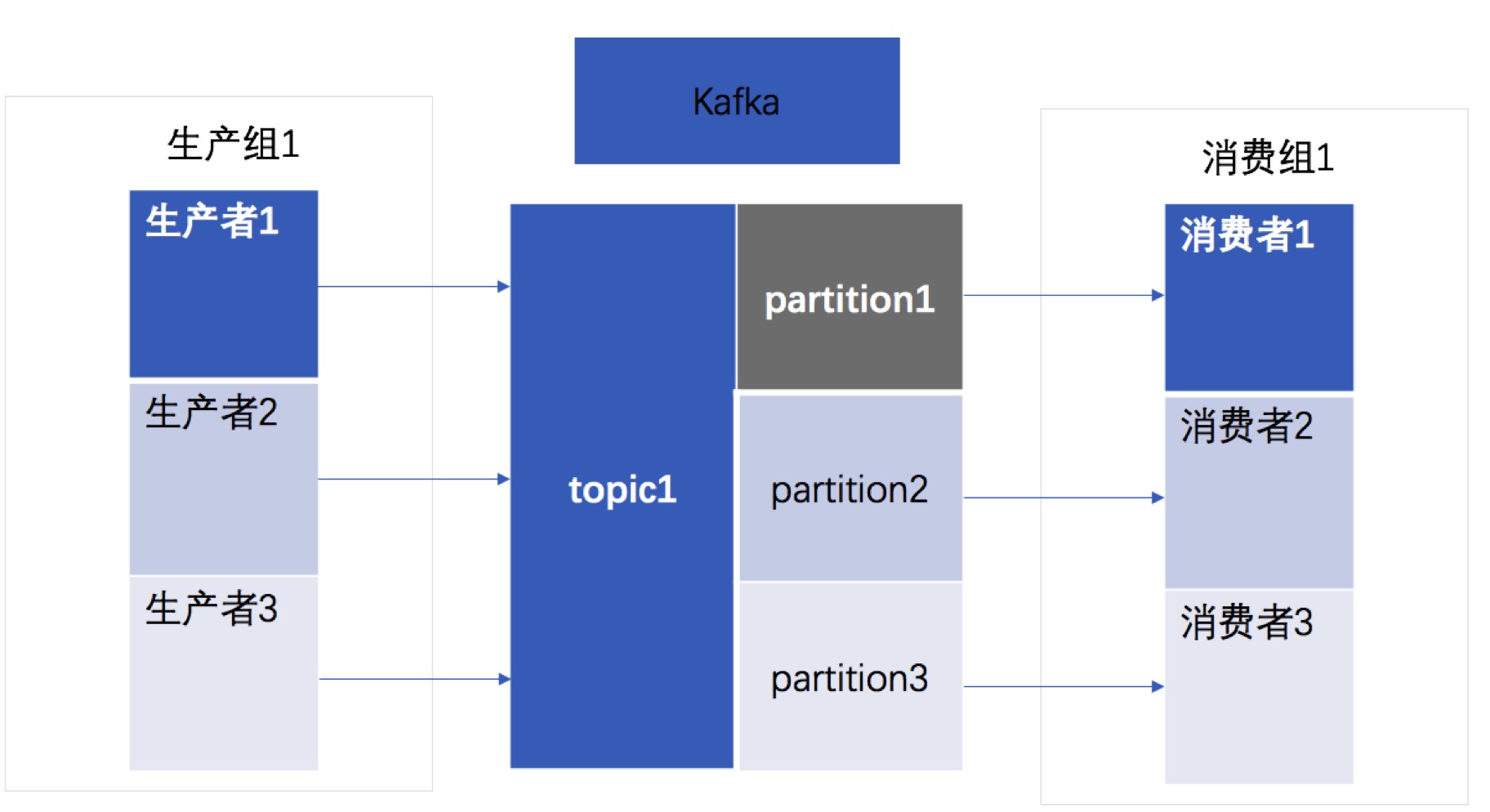
先给出最终模型变化图。
- 为什么引入消费组概念?
上一次模型图我们还没有消费组,那么引入消费组,是因为现在一个服务都有很多实例在运行,消费组是对这群一群机器的一个划分,他还是一个概念而已。 - mq内部也发生了变化,一个topic后面又对应了很多partition,partition也是一个概念,他只不过是把一个topic分成了很多份,每一份叫一个partition,你高兴也可以叫他xxx,那么我们来说说为什么要分成很多份,一份不行吗?
因为现在一个服务有很多实例在运行,如果topic只有一份的话,那么所有的实例都会来消费消息,并且都是抢占我们一个topic,这不可避免引入了多实例竞争,以及他们之间怎么协调,一堆问题需要关注解决,现在我把topic分成了很多份,每一份只给一个实例,那么就不会引入各实例之间的竞争问题了,简化了mq的问题。 - 生产组的引入也是一样的,只不过是一组机器的一个概念,一个逻辑的划分,生产者发送消息原先是发往topic,那么现在topic分成了很多份,生产者发送消息,需要说明发往哪个partition或者随意分配都可以,只不过最终发送的消息,会到一个topic下的一份里面。无论使用哪种映射方式都可以。
那么模型出来了,我们说说存储的问题。
对于kafka,一个partition对应一个文件,每次消息来都是顺序写这个文件。并且是定时刷盘,而不是每次写都刷盘,所以kafka的写非常高效。
rocketmq

上文我们说了rocketmq借鉴于kafka,所以存储借鉴了kafka,但是rocketmq不是仅仅把partition改成了ConsumeQueue,在这里做了变化,原先kafka,里面partition存储的是整个消息,但是现在ConsumeQueue里面是存储消息的存储地址,但是不存储消息了。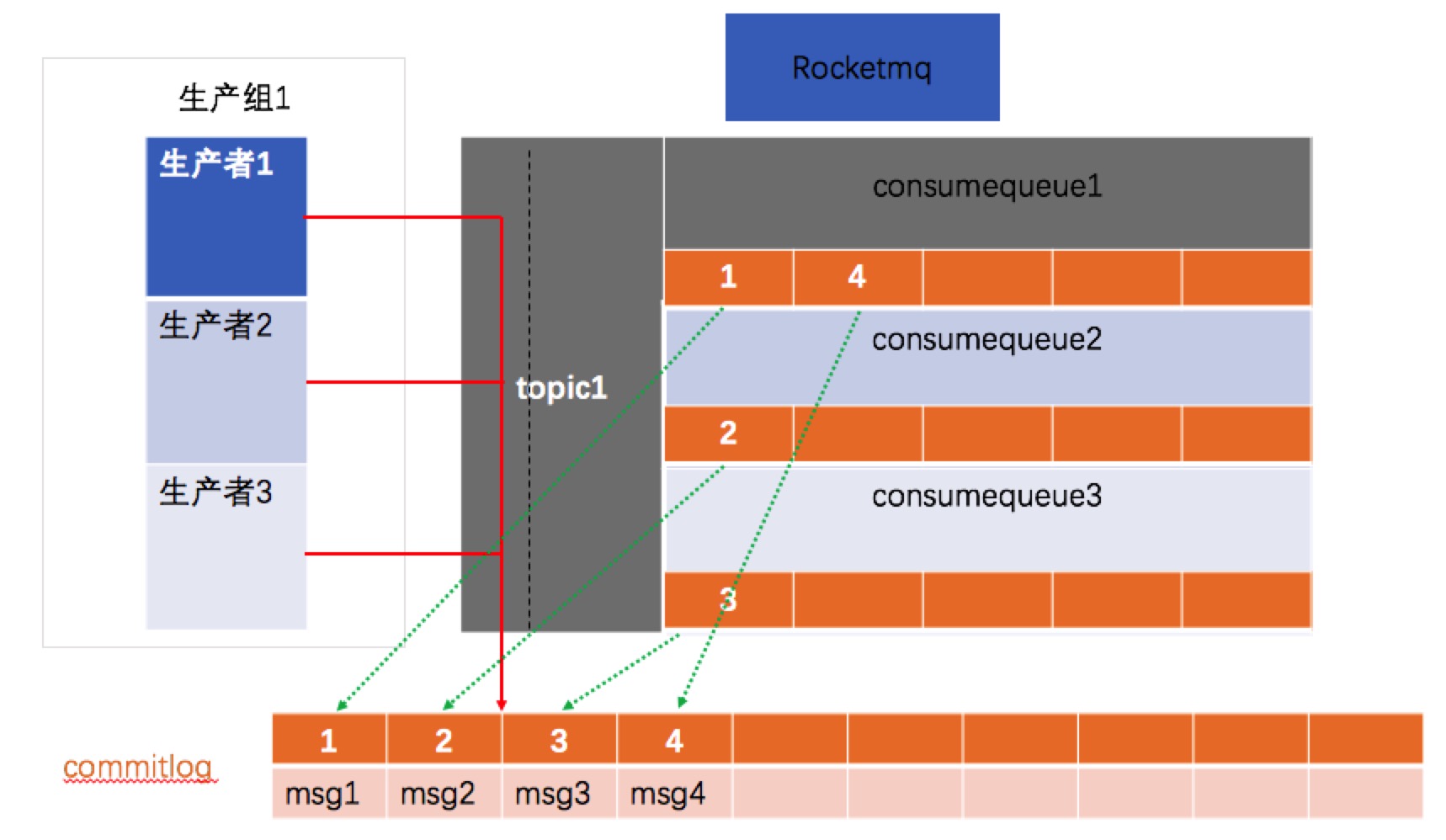
现在每个ConsumeQueue存储的是每个消息在commitlog这个文件的地址,但是消息存在于commitlog中。
也就是所有的消息体都写在了一个文件里面,每个ConsumeQueue只是存储这个消息在commitlog中地址。
存储对比
-
消息体存储的变化
那么我们先来看看kafka,假设partition有1000个,一个partition是顺序写一个文件,总体上就是1000个文件的顺序写,是不是就变成了随机写,所以当partition增加到一定数目后,kafka性能就会下降。而rocketmq是把消息都写到一个CommitLog文件中,所以相当于一个文件的顺序写。 -
为什么索引文件(ConsumeQueue)的增加对性能影响没有那么partition大?
(kafka也有索引文件,在这里只是想说明索引文件的增加跟partition增加的区别)
虽然rocketmq是把消息都写到一个CommitLog文件中,但是按照上面的实例会有1000个ConsumeQueue,也就是一千个文件,那么为什么就没有把顺序写变成随机写,带来性能的下降呢?首先就要介绍linux的pagecache
我们平常调用write或者fwrite的时候,数据还没有写到磁盘上,只是写到一个内核的缓存(pagecache),只有当我们主动调用flush的时候才会写到硬盘中。或者需要回写的pagecache占总内存一定比例的时候或者一个应该回写的page超过一定时间还没有写磁盘的时候,内核会将这些数据通过后台进程写到磁盘中(总结就是达到一定比例,或者多长时间还没有回写,会被内核自动回写)。
然后我们现在来看看为什么大量索引文件的顺序写没有像partition一样导致性能明显下降。ConsumeQueue只存储了(CommitLog Offet + Size + Message Tag Hashcode),一共20个字节,那么当commitlog定时任务刷盘之后,应该回写的pagecache的比例就会下降很多,那么ConsumeQueue的部分可以不用刷盘,就相当于ConsumeQueue的内容会等待比较长的时间聚合批量写入,而kafka每个partition都是存储的消息体,因为消息体都相对较大,基本在kb之上。
当一个partition刷盘的时候,应该回写的pagecache的比例降低的并不多,不能阻止其他partition的刷盘,所以会大量存在多个partition同时刷盘的场景,变成随机写。但是rocketmq消息都会写入一个commitLog,也就是顺序写。
所以我们总结下这个点:
1、consumerQueue消息格式大小固定(20字节),写入pagecache之后被触发刷盘频率相对较低。就是因为每次写入的消息小,造成他占用的pagecache少,主要占用方一旦被清理,那么他就可以不用清理了。
2、kafka中多partition会存在随机写的可能性,partition之间刷盘的冲撞率会高,但是rocketmq中commitLog都是顺序写。
欢迎关注博主公众号,后面会持续更新mq系列知识点,一起讨论。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号