LeetCode刷题2
[040201]455. 分发饼干【简单】贪心算法
假设你是一位很棒的家长,想要给你的孩子们一些小饼干。但是,每个孩子最多只能给一块饼干。对每个孩子\(i\) ,都有一个胃口值 \(g_i\) ,这是能让孩子们满足胃口的饼干的最小尺寸;并且每块饼干\(j\) ,都有一个尺寸 \(s_j\) 。如果 \(s_j\) >= \(g_i\) ,我们可以将这个饼干 \(j\) 分配给孩子 \(i\),这个孩子会得到满足。你的目标是尽可能满足越多数量的孩子,并输出这个最大数值。
注意:
你可以假设胃口值为正。
一个小朋友最多只能拥有一块饼干。
示例 1:
输入: [1,2,3], [1,1]
输出: 1
解释:
你有三个孩子和两块小饼干,3个孩子的胃口值分别是:1,2,3。
虽然你有两块小饼干,由于他们的尺寸都是1,你只能让胃口值是1的孩子满足。
所以你应该输出1。
示例 2:
输入: [1,2], [1,2,3]
输出: 2
解释:
你有两个孩子和三块小饼干,2个孩子的胃口值分别是1,2。
你拥有的饼干数量和尺寸都足以让所有孩子满足。
所以你应该输出2.
class Solution(object):
def findContentChildren(self, g, s):
"""
:type g: List[int]
:type s: List[int]
:rtype: int
"""
if g == None or s == None:
return 0
else:
g = sorted(g)
s = sorted(s)
i = 0
j = 0
ret = 0
# 在这个饼干分发的过程中,每个孩子寻找让大于等于自己的胃口饼干
while i < len(g) and j < len(s):
if s[j] >= g[i]:
ret += 1
i += 1
j += 1
return ret
执行用时 :208 ms, 在所有 Python3 提交中击败了53.35%的用户
内存消耗 :15.5 MB, 在所有 Python3 提交中击败了6.36%的用户
[040202]134. 加油站【中等】
在一条环路上有 N 个加油站,其中第 i 个加油站有汽油 gas[i] 升。
你有一辆油箱容量无限的的汽车,从第 i 个加油站开往第 i+1 个加油站需要消耗汽油 cost[i] 升。你从其中的一个加油站出发,开始时油箱为空。
如果你可以绕环路行驶一周,则返回出发时加油站的编号,否则返回 -1。
说明:
- 如果题目有解,该答案即为唯一答案。
- 输入数组均为非空数组,且长度相同。
- 输入数组中的元素均为非负数。
示例 1:
输入:
gas = [1,2,3,4,5]
cost = [3,4,5,1,2]
输出: 3
解释:
从 3 号加油站(索引为 3 处)出发,可获得 4 升汽油。此时油箱有 = 0 + 4 = 4 升汽油
开往 4 号加油站,此时油箱有 4 - 1 + 5 = 8 升汽油
开往 0 号加油站,此时油箱有 8 - 2 + 1 = 7 升汽油
开往 1 号加油站,此时油箱有 7 - 3 + 2 = 6 升汽油
开往 2 号加油站,此时油箱有 6 - 4 + 3 = 5 升汽油
开往 3 号加油站,你需要消耗 5 升汽油,正好足够你返回到 3 号加油站。
因此,3 可为起始索引。
示例 2:
输入:
gas = [2,3,4]
cost = [3,4,3]
输出: -1
解释:
你不能从 0 号或 1 号加油站出发,因为没有足够的汽油可以让你行驶到下一个加油站。
我们从 2 号加油站出发,可以获得 4 升汽油。 此时油箱有 = 0 + 4 = 4 升汽油
开往 0 号加油站,此时油箱有 4 - 3 + 2 = 3 升汽油
开往 1 号加油站,此时油箱有 3 - 3 + 3 = 3 升汽油
你无法返回 2 号加油站,因为返程需要消耗 4 升汽油,但是你的油箱只有 3 升汽油。
因此,无论怎样,你都不可能绕环路行驶一周。
【笔记】一次遍历法,车能开完全程需要满足两个条件:
- 车从
i站能开到i+1。 - 所有站里的油总量要
>=车子的总耗油量。
那么,假设从编号为0站开始,一直到k站都正常,在开往k+1站时车子没油了。这时,应该将起点设置为k+1站。
class Solution:
def canCompleteCircuit(self, gas: List[int], cost: List[int]) -> int:
rest = 0
run = 0
start = 0
i = 0
while i < len(gas):
run += gas[i]-cost[i]
# rest 表示总的油量够不够
rest += gas[i]-cost[i]
if run < 0:
start = i + 1
run = 0
i += 1
return -1 if rest < 0 else start
补充两个问题(2019/5/26):
问题1: 为什么应该将起始站点设为k+1?
- 因为
k->k+1站耗油太大,0->k站剩余油量都是不为负的,每减少一站,就少了一些剩余油量。所以如果从k前面的站点作为起始站,剩余油量不可能冲过k+1站。
问题2: 为什么如果k+1->end全部可以正常通行,且rest>=0就可以说明车子从k+1站点出发可以开完全程?
- 因为,起始点将当前路径分为
A、B两部分。其中,必然有(1)A部分剩余油量<0。(2)B部分剩余油量>0。 - 所以,无论多少个站,都可以抽象为两个站点(A、B)。(1)从B站加满油出发,(2)开往A站,车加油,(3)再开回B站的过程。
重点:B剩余的油>=A缺少的总油。必然可以推出,B剩余的油>=A站点的每个子站点缺少的油。
执行用时 :48 ms, 在所有 Python3 提交中击败了74.59%的用户
内存消耗 :14.2 MB, 在所有 Python3 提交中击败了5.04%的用户
[040301]763. 划分字母区间【中等】贪心算法
字符串 S 由小写字母组成。我们要把这个字符串划分为尽可能多的片段,同一个字母只会出现在其中的一个片段。返回一个表示每个字符串片段的长度的列表。
示例 1:
输入: S = "ababcbacadefegdehijhklij"
输出: [9,7,8]
解释:
划分结果为 "ababcbaca", "defegde", "hijhklij"。
每个字母最多出现在一个片段中。
像 "ababcbacadefegde", "hijhklij" 的划分是错误的,因为划分的片段数较少。
注意:
S的长度在[1, 500]之间。S只包含小写字母'a'到'z'。
class Solution:
def partitionLabels(self, S: str) -> List[int]:
# 建立两个字典,用于存放字符的第一个索引和最后一个索引
f_dict = {}
l_dict = {}
for i,s in enumerate(S):
if s not in f_dict:
f_dict[s] = i
if s in f_dict:
l_dict[s] = i
lst = []
for j in f_dict.keys():
lst.append([f_dict[j],l_dict[j]])
left = lst[0][0]
right = lst[0][1]
res = []
for inter in lst:
# 此时,right>inter[1] or right <= inter[1]
if right >= inter[0]:
right = max(right, inter[1])
else:
res.append([left,right])
left = inter[0]
right = inter[1]
# 只有在后面还有的情况下,才会加入res中
res.append([left,right])
return [interval[1] - interval[0] + 1 for interval in res]
执行用时 :44 ms, 在所有 Python3 提交中击败了77.78%的用户
内存消耗 :13.8 MB, 在所有 Python3 提交中击败了8.70%的用户
[040302]435. 无重叠区间【中等】
给定一个区间的集合,找到需要移除区间的最小数量,使剩余区间互不重叠。
注意:
- 可以认为区间的终点总是大于它的起点。
- 区间 [1,2] 和 [2,3] 的边界相互“接触”,但没有相互重叠。
示例 1:
输入: [ [1,2], [2,3], [3,4], [1,3] ]
输出: 1
解释: 移除 [1,3] 后,剩下的区间没有重叠。
示例 2:
输入: [ [1,2], [1,2], [1,2] ]
输出: 2
解释: 你需要移除两个 [1,2] 来使剩下的区间没有重叠。
示例 3:
输入: [ [1,2], [2,3] ]
输出: 0
解释: 你不需要移除任何区间,因为它们已经是无重叠的了。
class Solution:
def eraseOverlapIntervals(self, intervals: List[List[int]]) -> int:
##换一个思路:先找出能够一直排序的,然后用数组的长度-能排序的长度就是需要删除的长度
lens = len(intervals)
##特殊情况
if lens==0:
return 0
##贪心算法:先对每个数组值进行排序,按照末尾数字排序很重要
intervals.sort(key=lambda x:x[1])
print(intervals)
pre = 0 ##记录前面一个可以连接的数组的下标位置
nums = 1
## 记录有多少个可以连续连接在一起的数组,注意这里初始化为1,
## 因为当有一个可以连续组合成为的时候,此时应该是2个,而不是1个数组,
## 所以初始化应该是1,并且,单独的一个数组也能算作连续的
for i in range(1,lens):
if intervals[i][0]>=intervals[pre][1]:
pre = i
nums+=1
else:
pass
return lens-nums
##剩下的就是不能连续组合的数组的个数
[040401]784. 字母大小写全排列【简单】回溯算法
给定一个字符串S,通过将字符串S中的每个字母转变大小写,我们可以获得一个新的字符串。返回所有可能得到的字符串集合。
示例:
输入: S = "a1b2"
输出: ["a1b2", "a1B2", "A1b2", "A1B2"]
输入: S = "3z4"
输出: ["3z4", "3Z4"]
输入: S = "12345"
输出: ["12345"]
注意:
S的长度不超过12。S仅由数字和字母组成。
class Solution(object):
def letterCasePermutation(self, S):
"""
:type S: str
:rtype: List[str]
从上自下的遍历
"""
res = list()
l = len(S)
if l == 0:
return [""]
def dfs(start, temp):
if start >= l or len(temp) == l: #已经找到了一个答案
res.append(temp)
return
# print start, temp
if S[start].isdigit(): #数字就直接加
dfs(start + 1, temp + S[start])
elif S[start].islower(): #字母就加本身和对立面
dfs(start + 1, temp + S[start])
dfs(start + 1, temp + S[start].upper())
elif S[start].isupper():
dfs(start + 1, temp + S[start])
dfs(start + 1, temp + S[start].lower())
dfs(0, "")
return res
执行用时 :60 ms, 在所有 Python3 提交中击败了83.87%的用户
内存消耗 :15.2 MB, 在所有 Python3 提交中击败了6.35%的用户
[040402]17. 电话号码的字母组合【中等】
给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。
给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。
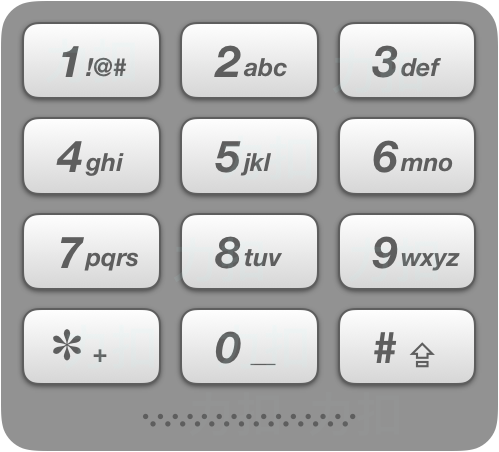
示例:
输入:"23"
输出:["ad", "ae", "af", "bd", "be", "bf", "cd", "ce", "cf"].
说明:
尽管上面的答案是按字典序排列的,但是你可以任意选择答案输出的顺序。
class Solution:
def letterCombinations(self, digits: str) -> List[str]:
# 构建字典
num_dict = {"2":["a","b","c"],
"3":["d","e","f"],
"4":["g","h","i"],
"5":["j","k","l"],
"6":["m","n","o"],
"7":["p","q","r","s"],
"8":["t","u","v"],
"9":["w","x","y","z"]}
if digits == "":
return []
res = [""]
for num in digits:
res = [pre+suf for pre in res for suf in num_dict[num]]
return res
[040501]面试题 08.07. 无重复字符串的排列组合【中等】回溯算法
无重复字符串的排列组合。编写一种方法,计算某字符串的所有排列组合,字符串每个字符均不相同。
示例1:
输入:S = "qwe"
输出:["qwe", "qew", "wqe", "weq", "ewq", "eqw"]
示例2:
输入:S = "ab"
输出:["ab", "ba"]
提示:
- 字符都是英文字母。
- 字符串长度在[1, 9]之间。
class Solution:
def permutation(self, S: str) -> List[str]:
res = []
n = len(S)
temp = []
def helper(temp,S):
if len(temp) == n:
res.append("".join(temp))
return
for s in S:
if s in temp:
continue
temp.append(s)
helper(temp,S)
temp.pop()
helper(temp,S)
return res
执行用时 :320 ms, 在所有 Python3 提交中击败了9.12%的用户
内存消耗 :21.2 MB, 在所有 Python3 提交中击败了100.00%的用户
[040502]面试题 08.09. 括号【中等】回溯
括号。设计一种算法,打印n对括号的所有合法的(例如,开闭一一对应)组合。
说明:解集不能包含重复的子集。
例如,给出 n = 3,生成结果为:
[
"((()))",
"(()())",
"(())()",
"()(())",
"()()()"
]
class Solution:
def generateParenthesis(self, n: int) -> List[str]:
res = []
temp = []
def helper(temp,left,right,n):
if left < right: return # 左括号的数量始终大于右括号,就可以排除不正常的情况
if left == n and right == n:
res.append(temp)
return
if left < n :
helper(temp+"(",left+1,right,n)
if right < n:
helper(temp+")",left,right+1,n)
helper("",0,0,n)
return res
执行用时 :40 ms, 在所有 Python3 提交中击败了77.87%的用户
内存消耗 :13.9 MB, 在所有 Python3 提交中击败了100.00%的用户
[040601]53. 最大子序和[简单]动态规划
给定一个整数数组 nums ,找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
示例:
输入: [-2,1,-3,4,-1,2,1,-5,4],
输出: 6
解释: 连续子数组 [4,-1,2,1] 的和最大,为 6。
1. 暴力解法(超时)可能有问题
class Solution:
def maxSubArray(self, nums: List[int]) -> int:
n = len(nums)
if n < 2:
return sum(nums)
dp_i = float("-inf")
for i in range(n):
for j in range(i+1,n+1):
dp_i = max(dp_i,sum(nums[i:j]))
return dp_i
2.
class Solution:
def maxSubArray(self, nums: List[int]) -> int:
dp_i = 0 # dp_i用于保存各个子序列的和
res = nums[0] # res 保存所用序列和的最大值
for i in nums:
if dp_i > 0:
dp_i += i
else:
dp_i = i
res = max(dp_i,res)
return res
# 该题的思想类似于加油站,从各个子序列的和,当他大于0时一直往下计算
# 直到小于0
# 对于整体最大来说,各个值的贡献
# 首先,在我们尽可能以一个正值开始一个子序列,在序列长度增加的同时,记录下来增加过程中和的值,并取最大保存下来
3. 动态规划
class Solution:
def maxSubArray(self, nums: List[int]) -> int:
res = []
dp_i = 0
for num in nums:
dp_i = max(dp_i + num , num)
# 根据递归计算,代表的是要么接着前面的往下算,要么新开始一个头算
res.append(dp_i)
return sorted(res)[-1]
执行用时 :52 ms, 在所有 Python3 提交中击败了72.98%的用户
内存消耗 :14.5 MB, 在所有 Python3 提交中击败了5.12%的用户
3.1 动态规划(升级版)
class Solution:
def maxSubArray(self, nums: List[int]) -> int:
res = float("-inf")
dp_i = 0
for num in nums:
dp_i = max(dp_i + num , num)
# 根据递归计算,代表的是要么接着前面的往下算,要么新开始一个头算
# 但是,他只能保证相邻元素子序列求较大值
# 但是,这儿存在一个问题,就是存在上一轮的dp_i的值为正
# 本轮中,dp_i+num < 0 且 dp_i+num > num,
# 那么dp_i的值就会减小,不再是之前的峰值,因此需要引入res来处理这个问题
# 与2中的算法形成对比,2中存在dp_i>0的判断条件
res = max(res,dp_i)
return res
执行用时 :44 ms, 在所有 Python3 提交中击败了90.50%的用户
内存消耗 :14.1 MB, 在所有 Python3 提交中击败了5.12%的用户

 浙公网安备 33010602011771号
浙公网安备 33010602011771号