
angr_ctf——从0学习angr(三):Hook与路径爆炸
路径爆炸#
之前说过,angr在处理分支时,采取统统收集的策略,因此每当遇见一个分支,angr的路径数量就会乘2,这是一种指数增长,也就是所说的路径爆炸。
以下是路径爆炸的一个例子:
char buffer[17];
for(int i=0;i<16;i++){ if(buffer[i]!='B'){ return 0; } } return 1;
buffer的字符长度为16,当它等于16个连续的'B'时,程序返回1,然而angr在探索这样的路径时,会遇上16次if语句,也就相应地产生2的16次方个路径,但正确的答案只有一条路径能够达到(if全为false的那一条),这一条路径就被淹没在大量错误路径中,产生了路径爆炸。
因此当遇见大量分支(尤其是循环中嵌套的if语句)时,必须想办法缓解这种路径爆炸。
angr常用的缓解路径爆炸的方式有四种:
- 重写可能导致路径爆炸的函数或代码片段,可以采用angr提供的hook
- veritesting:结合动态符号执行和静态符号执行
- Lazy Solve:跳过不必要的函数
- Symbion:结合具体执行和符号执行
在angr_ctf中只涉及到了前两种方式,因此本篇着重说说第一种方式,以及简略介绍下第二种方式。angr缓解路径爆炸的策略,后续新开一篇详细谈谈。
重写代码片段#
仍然以上一节路径爆炸中用的代码片段为例,字符串buffer要按位比较16次从而产生2的16次方条路径,它的路径大致如下图:
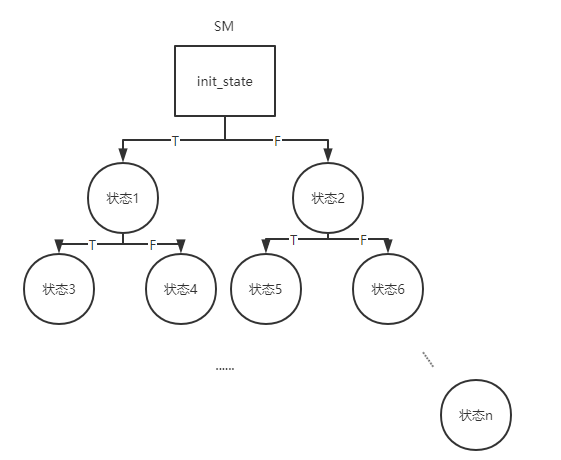
angr必须选择16次F才能达到目标状态。
然而根据逆向分析得出的结果来看,只要让buffer='B'*16就可以通过这段代码了,因此如果我们之间跳过这段代码,然后在跳过了这段代码的state中添加一个约束:buffer='B'*16,这样就不会产生路径了。
你可能会问,既然我们都通过逆向的手段看出来buffer等于16个B了,那为什么还要使用angr呢。
然而如果真正的目标状态在该代码片段的后面,这段会产生路径爆炸的代码如果不绕开的话,你很可能无法达到真正的目标状态。
Hook#
Hook可以译为挂钩或者钩子,是逆向工程中改变程序运行流程的技术,可以让自己的代码运行在其他程序当中。通常说Hook函数,则是接收被Hook函数的参数,然后使用这些参数执行自己的代码,并将返回值返回(也可以没有返回值),至于被Hook的函数,可以选择让它继续执行,或者不执行。
听上去Hook技术很麻烦,让其他程序运行自己写的代码似乎挺不可思议的。Hook技术值得深入研究,但angr提供了简便的Hook接口,能够用于Hook被angr模拟执行的程序,它通常有两种方式:
- 装饰器@project.hook
- 函数project.hook_symbol
装饰器@project.hook#
@project.hook(hook_addr, length=ins_length) def hook_ins(state): #your code
请注意,这里的project.hook来自于你使用angr.Project方法创建的顶层模块(即project=angr.Project('filename'))。
该方法相当于在hook_addr处删去长度为length的指令,然后用hook_ins中的指令替代。
该装饰器需要传入待hook的地址,以及要跳过的指令的长度,然后在hook_ins中实现你的代码即可。
使用装饰器的方法,如果是对函数进行hook而不是对某一代码片段进行hook的话,无法接收函数的参数,需要根据情况来使用。
hook_symbol#
假设程序中有一个这样的原始函数:
int my_add(int a, int b){ return a+b; }
那么这样的函数可以被下面的方式hook掉:
class Replace_my_add(angr.SimProcedure): def run(self, a, b): return a - b hooked_func_name = 'my_add' project.hook_symbol(hooked_func_name, Replace_my_add())
该方法相当于替换了原函数,为此你需要创建一个类,继承自angr.SimProcedure,类名随意。
然后在类中重写run方法,run的self后的参数与待hook的函数相同。
最后在主函数中,调用project.hook_symbol,并传入待hook的函数名以及新建的继承自SimProcedure的类的对象即可。
设立返回值#
- 对于装饰器
该方法相当于代码片段的替换,因此如果你选择跳过了某条函数调用语句(例如 call my_add这条汇编指令),那么就需要去查看该函数的返回值,或者说代码片段的最终计算结果,被保存在了什么地方。找到这个地方,然后使用内存或者寄存器操作,将返回值填入即可。
一般来说,32位程序函数的返回值会放在eax寄存器中
- 对于hook_symbol
该方式相当于替换了函数的内容,因此直接在重写的run方法中使用return返回即可
返回值的时候,如果需要根据某个符号变量来决定返回的内容(例如判断一个符号变量等于某个字符串时返回1,否则返回0),此时不能用python的if语句来判断,然后分别返回1和0,这有两个问题:
- 符号变量与其他内容进行比较(无论是符号变量、位向量、常数、变量),它的真值永远是false
- 如果返回值后续参与了其他的路径选择,此时若只返回了值而不是带约束的符号变量,可能会造成约束丢失
这种情况下,需要使用claripy.If来返回值:
state.regs.eax = claripy.If(buffer == target, claripy.BVV(1, 32),claripy.BVV(0, 32))
上面代码的意思是,当buffer==target时,将位向量<BVV32 1>传递给eax,否则将位向量<BVV32 0>传递给eax
而如果不这么做,你可能会写出这样的代码:
if buffer==target: state.regs.eax = claripy.BVV(1,32) else: state.regs.eax = claripy.BVV(0,32)
这两种做法的区别在于,如果buffer或target中至少存在一个符号变量,下面的方式将永远判断为false。
此外,两种方式传递给eax的内容也不同,下面一种方式传递的是一个位向量,而上面的方式传递的是带约束的符号变量(之后实战中你会看到更多)。
Veritesting#
veritesting意为路径归并,它在动态符号执行(DSE)和静态符号执行(SSE)之间切换,结合两种方式减少了路径爆炸的影响。
- DSE:为路径生成公式,生成公式时负载很高,但公式易解
- SSE:为语句生成公式,公式生成容易,也能覆盖更多路径,但更难解
详细可参见这篇论文:Enhancing symbolic execution with veritesting (acm.org)
在angr中,要启动veritesting,有以下两种方式:

p = angr.Project('/bin/true') state = p.factory.entry_state() #初始化SM时启动 simgr = p.factory.simgr(state, veritesting=True) #或者在SM初始化后启动 simgr = p.factory.simgr(state) simgr.use_technique(angr.exploration_techniques.Veritesting())
state插件#
之前提到的angr的求解器solver,以及操作内存、寄存器、文件系统的方法:memory、regs、fs等,实际上都是state的插件,下面说明两个其他常用的插件。
全局插件global#
state.global实现了标准python dict接口,使用它你能够在模拟执行的state中存储任意数据,并且很方便的就能访问到。可以使用如下的语句访问全局变量:
state.globals['x'] = a_symbol
全局变量名x不需要提前声明,但当你需要使用这个全局变量之前,需要对它赋值。
history插件#
history记录了一个状态的执行路径,它是一个链表,每个节点代表一次执行的状态。你可以不断使用.parent来回溯这个链表,history的使用方式如下:
- state.history.bbl_addrs:返回当前state执行的基本块的地址列表
- state.history.parent.bbl_addrs:返回上一个state执行的基本块的地址列表
- state.history.descriptions:描述state上每轮执行的状态的字符串列表
- state.histroy.guards:到达当前state所走路径需要满足的条件的列表(也就是每次分支判断时为True还是False)
- state.history.events:执行过程中发生的事件列表,比如符号跳转条件、弹出消息框等
此外,在每种方法前加上recent_,就可以获取列表中最近的那个地址,例如state.history.recent_bbl_addrs会返回当前state最近执行的基本块的地址。
实战:08_angr_constraints#
先逆向查看逻辑
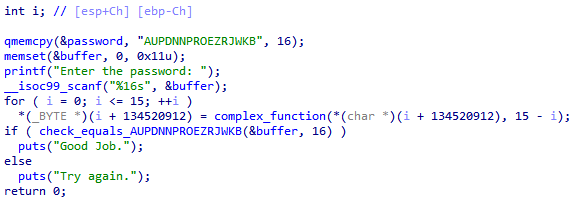
和之前一样,先对输入进行混淆,然后再判断。
但这里的问题在于,首先字符串的长度为16,此外,在check_equals函数中,采用的是按位比较的方式:

而字符串长度为16,那么就会进行16次比较,从而产生2的16次方条路径,这样angr就会陷入路径爆炸。
但能够注意到,check函数中实际上是在让buffer与password进行比较(0x0804a040就是password的地址),而password在main的开头被初始化为一串已知的字符串。
因此可以考虑让模拟运行在调用check函数之前停下来,然后添加一个符号约束(buffer==已知的字符串),之后再用求解器求解buffer即可。
angr脚本如下:
import angr import claripy import time def good(state): tag = b'Good' in state.posix.dumps(1) return True if tag else False def bad(state): tag = b'Try' in state.posix.dumps(1) return True if tag else False time_start = time.perf_counter() path_to_binary = './dist/08_angr_constraints' p = angr.Project(path_to_binary, auto_load_libs=False) start_addr = 0x08048625 init_state = p.factory.blank_state(addr=start_addr) buffer = claripy.BVS('buffer', 16*8) # buffer的地址 buffer_addr = 0x0804a050 init_state.memory.store(buffer_addr, buffer) simgr = p.factory.simgr(init_state) # call check指令的地址 check_addr = 0x08048565 # 让程序模拟运行到call check时就标记为目标状态 simgr.explore(find=check_addr) if simgr.found: solution_state = simgr.found[0] # 由于buffer经过混淆函数混淆发生了变化 # 因此需要从buffer的内存地址中取出buffer目前的值 buffer_current = solution_state.memory.load(buffer_addr, 16) key = 'AUPDNNPROEZRJWKB' # 为当前状态添加约束 solution_state.solver.add(buffer_current == key) # 求解buffer solution = solution_state.solver.eval(buffer, cast_to=bytes) print('[+]Success:', solution.decode()) else: raise Exception("Could not find solution") print('program last: ', time.perf_counter() - time_start)
你大概有两个问题:
- 为何要重新从buffer_addr中取出符号变量,不能直接使用buffer吗?
- 在实战05中输入字符串的长度为32,然后使用了strncmp进行比较,strncmp的底层实现也是按位比较的,为何之前不用考虑路径爆炸的问题呢?
首先第一个问题,我们可以先将buffer打印出来,应该能得到一个位向量<BV128 buffer_0_128>。该位向量之后被我们保存在了buffer的地址当中。
然后打印一下buffer_current:
_128[7:7] .. buffer_0_128[7:7] .. buffer_0_128[7:7] .. buffer_0_128[7:7] .. buffer_0_128[7:7] .. buffer_0_128[7:7] .. buffer_0_128[7:7] .. buffer_0_128[7:7] .. buffer_0_128[7:7] .. buffer_0_128[7:7] .. buffer_0_128[7:7] .. buffer_0_128[7:7] .. buffer_0_128[7:7] .. buffer_0_128[7:7] .. buffer_0_128[7:7] .. buffer_0_128[7:0]))[63:32] >> 0x3[7:0] + 26 * 0xffffffbf + (buffer_0_128[7:7] .. buffer_0_128[7:7] .. buffer_0_128[7:7] .. buffer_0_128[7:7] .. buffer_0_128[7:7] .. buffer_0_128[7:7] .. buffer_0_128[7:7] .. buffer_0_128[7:7] .. buffer_0_128[7:7] .. buffer_0_128[7:7] .. buffer_0_128[7:7] .. buffer_0_128[7:7] .. buffer_0_128[7:7] .. buffer_0_128[7:7] .. buffer_0_128[7:7] .. buffer_0_128[7:7] .. buffer_0_128[7:7] .. buffer_0_128[7:7] .. buffer_0_128[7:7] .. buffer_0_128[7:7] .. buffer_0_128[7:7] .. buffer_0_128[7:7] .. buffer_0_128[7:7] .. buffer_0_128[7:7] .. buffer_0_128[7:0]) >> 0x1f[7:0]>
会得到一个极为庞大的符号变量,或者说一个表达式,这是位向量<BV128 buffer_0_128>经过混淆函数混淆后的结果,因此要求解的应该是这个表达式。
我们创建的符号buffer被保存在了buffer的地址当中,然后模拟程序运行时,从地址中取出符号进行混淆,混淆的过程也被保存在buffer的地址中,因此在最后需要从这个地址里面取出混淆后的符号进行求解。
第二个问题,先说结论:angr在路径选择时只进入库函数一次,而不关心库函数内部的实现采用了多少次if。
编写以下两个c程序并编译(我这里使用gcc编译成64位了,与题目的32位不符,但原理相同):
#include<stdio.h> char buffer[9]; char passwd[9] = "abcdefgh"; int main(){ scanf("%8s", buffer); if (strncmp(buffer, passwd ,8)==0){ printf("good"); } else{ printf("bad"); } }
#include<stdio.h> char buffer[9]; char passwd[9] = "abcdefgh"; int check(int size){ int i = 0; for(i;i<size;i++){ if(buffer[i]!=passwd[i]){ return 0; } } return 1; } int main(){ scanf("%8s", buffer); printf("%s\n",buffer); if (check(8)){ printf("good"); } else{ printf("bad"); } }
两个程序都接收8个字符,然后与abcdefgh进行比较,区别在于第一个程序使用库函数strncmp进行比较,而后一个程序则自己定义了一个check进行比较,两者比较的内部原理都是按位循环比较(strncmp还进行了一些额外处理,但基本原理仍然是按位循环比较,具体可参见strncmp源码)
然后,我们使用符号变量填充到buffer对应的地址中,让模拟执行从scanf后的语句开始执行,并以打印good为目标状态。
获取目标状态后,使用history插件打印出当前state执行的基本块,这些步骤的angr代码如下:
import angr import claripy import time def good(state): tag = b'good' in state.posix.dumps(1) return True if tag else False def bad(state): tag = b'bad' in state.posix.dumps(1) return True if tag else False start_time = time.perf_counter() p = angr.Project('./a', auto_load_libs=False) init_state = p.factory.blank_state(addr=0x40118b) buffer_addr = 0x404060 x = claripy.BVS('x', 8 * 9) init_state.memory.store(buffer_addr, x) simgr = p.factory.simgr(init_state) simgr.explore(find=good, avoid=bad) if simgr.found: solution_state = simgr.found[0] x_current = solution_state.memory.load(buffer_addr, 8)
# 打印路径 for address in solution_state.history.bbl_addrs: print(hex(address)) result = solution_state.solver.eval(x_current, cast_to=bytes) print(result) else: raise Exception("Could not find solution") print(time.perf_counter() - start_time)
两个程序的angr脚本相同,修改一下地址和文件名即可,此外还需要注意,如果编译时没加任何参数,装载的地址可能会跟你在IDA中看到的不一样,例如我使用angr时提示如下:
WARNING | 2022-11-29 02:41:46,685 | cle.loader | The main binary is a position-independent executable. It is being loaded with a base address of 0x400000.
它提示我们,程序被装载到基地址0x400000中了,而我们在IDA中看到的程序的地址main函数以0x1169开头,这是一个相对地址,因此在编写angr脚本时,要将这些相对地址加上0x400000.
此时打印出来两种判断方式的路径如下:
#程序1 0x40118b 0x401040 0x500010 0x40119a 0x401030 0x500008 0x4011b8 0x401050 0x500018 0x4011ce 0x401030 0x500008 0x4011ec 0x4011f0 0x401050 0x500018 #程序2 0x4011c9 0x401030 0x500008 0x4011d8 0x401159 0x401198 0x401169 0x401194 0x401169 0x401194 0x401169 0x401194 0x401169 0x401194 0x401169 0x401194 0x401169 0x401194 0x401169 0x401194 0x401169 0x401194 0x4011a0 0x4011e2 0x4011e6 0x401040 0x500010
程序1中0x40119a所在的基本块就是调用strncmp的基本块,它只被执行了一次,因此在if语句中只会产生2个路径。
而程序2中check函数内部的循环语句所在的基本块0x401169和0x401194被执行了8次,从而产生了2的8次方个路径。
因此可以得到开头的结论,库函数内部如何实现,与angr无关,并不会产生额外的路径。
实战:09_angr_hooks#
仍然先逆向查看逻辑
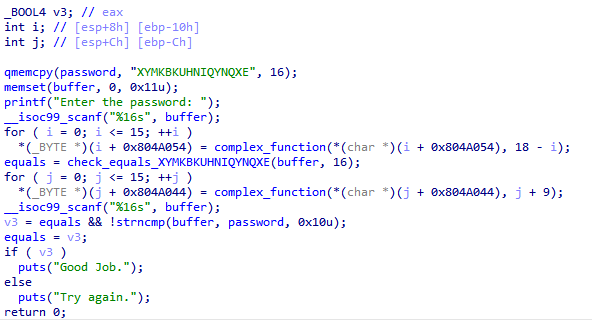
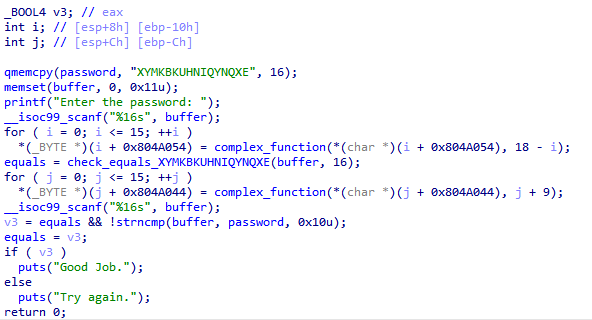
程序先接收一个输入,输入被混淆后与password进行比较,password被初始化为一个已知的字符串。
然后程序混淆password,再接收一个输入,将输入与混淆后的password进行比较。(两个for循环中的地址分别是buffer和password的地址)
第一次比较在check函数中按位比较,后一次比较则是使用了strncmp函数,因此路径爆炸发生在check函数中,对于strncmp则无须处理。
这次使用装饰器的方法来解决这个问题:
- 使用装饰器跳过调用check函数的指令,也就是call cehck_equals
- 在装饰器内部实现符号==AUPDNNPROEZRJWKB的约束
- 将符号约束作为返回值返回,查看汇编代码可以知道,check函数的返回值保存在了eax寄存器中
angr脚本如下:
import angr import time import claripy time_strat = time.perf_counter() def good(state): tag = b'Good' in state.posix.dumps(1) return True if tag else False def bad(state): tag = b'Try' in state.posix.dumps(1) return True if tag else False path_to_binary = './dist/09_angr_hooks' p = angr.Project(path_to_binary, auto_load_libs=False) init_state = p.factory.entry_state() # call check_equal的地址 check_addr = 0x080486b3 # call check_equal的指令長度 ins_size = 5 @p.hook(check_addr, length=ins_size) def skip_check(state): buffer_addr = 0x0804a054 buffer = state.memory.load(buffer_addr, 16) target = 'XYMKBKUHNIQYNQXE' # 使用claripy.If返回一个符号约束 tmp = claripy.If(buffer == target, claripy.BVV(1, 32), claripy.BVV(0, 32)) print(type(tmp)) print(tmp) state.regs.eax = tmp simgr = p.factory.simgr(init_state) simgr.explore(find=good, avoid=bad) if simgr.found: solution_state = simgr.found[0] flag = solution_state.posix.dumps(0) print(flag) else: raise Exception("Could not find solution")
打印出tmp的内容,其中最后的片段如下:
packet_0_stdin_4_128[7:7] .. packet_0_stdin_4_128[7:7] .. packet_0_stdin_4_128[7:7] .. packet_0_stdin_4_128[7:7] .. packet_0_stdin_4_128[7:7] .. packet_0_stdin_4_128[7:7] .. packet_0_stdin_4_128[7:7] .. packet_0_stdin_4_128[7:7] .. packet_0_stdin_4_128[7:7] .. packet_0_stdin_4_128[7:7] .. packet_0_stdin_4_128[7:0]) >> 0x1f[7:0]) == 0x58594d4b424b55484e4951594e515845 then 0x1 else 0x0>
tmp前面的内容即buffer的内容,是经过混淆计算后的符号,而在最后可以看到,claripy.If创建了一个判断,因此实际上返回了一个约束,这就是为什么不适用python中的if然后传递一个<BVV32 1>的原因。
实战:10_angr_simprocedures#
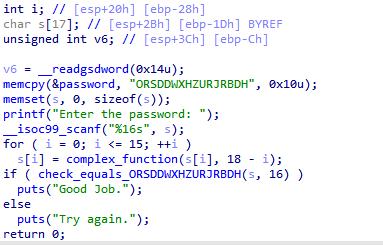
第十题的路径爆炸仍然发生在check_equals函数当中,与上一题的区别在于,此时输入的字符串被保存在局部变量当中,我们无法提前得知它的地址,因此如果要hook掉check函数,则必须获取check函数的参数。
因此需要使用hook_symbol的方式来hook掉check函数
使用方式之前说明了,只需要注意使用hook_symbol的方法本质上是创建了新的函数取代了原有函数,因此在返回值的时候使用return返回,而不用将值保存在eax当中(事实上重写的run方法中没有当前的state,你也保存不到eax里面)
angr脚本如下:
import angr import time import claripy time_strat = time.perf_counter() def good(state): tag = b'Good' in state.posix.dumps(1) return True if tag else False def bad(state): tag = b'Try' in state.posix.dumps(1) return True if tag else False path_to_binary = './dist/10_angr_simprocedures' p = angr.Project(path_to_binary, auto_load_libs=False) init_state = p.factory.entry_state() class Hook(angr.SimProcedure): def run(self, addr, size): # 后两个参数即为check_equals函数的参数 input_buffer = addr input_size = size # 从内存中读取输入 input_str = self.state.memory.load(input_buffer, input_size) right_str = 'ORSDDWXHZURJRBDH' # 比较返回符号约束 result = claripy.If(input_str == right_str, claripy.BVV(1, 32), claripy.BVV(0, 32)) return result # funcname一定要相同,可在IDA中查看 hooked_funcname = 'check_equals_ORSDDWXHZURJRBDH' p.hook_symbol(hooked_funcname, Hook()) simgr = p.factory.simgr(init_state) simgr.explore(find=good, avoid=bad) if simgr.found: solution_state = simgr.found[0] flag = solution_state.posix.dumps(0) print(flag)
实战:11_angr_sim_scanf#
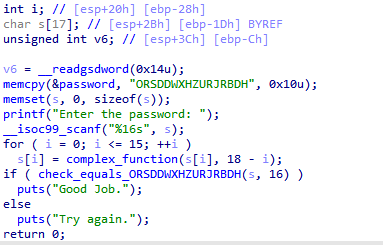
此题与实战2-7中的题类似,实际上使用万能脚本就可以成功。出于练习的目的,跟着angr_ctf作者的思路,我们使用hook_symbol方法来hook掉scanf函数。
angr脚本如下,使用到了state的全局变量插件,用法很简单,用于进行约束求解。如果不使用全局变量的话,从buffer的地址中取出符号进行求解也是一样的(就像在实战8中做的那样)
import angr import claripy def good(state): tag = b'Good' in state.posix.dumps(1) return True if tag else False def bad(state): tag = b'Try' in state.posix.dumps(1) return True if tag else False path_to_binary = './dist/11_angr_sim_scanf' project = angr.Project(path_to_binary, auto_load_libs=False) initial_state = project.factory.entry_state() class ReplacementScanf(angr.SimProcedure): # 第一个参数是scanf的格式化字符串,接着是两个buffer地址 def run(self, format_string, scanf0_address, scanf1_address): # 在run中完成scanf的功能,即向目标地址写入符号 # 定义两个符号变量,用于写入buffer scanf0 = claripy.BVS('scanf0', 32) scanf1 = claripy.BVS('scanf1', 32) # 写入内存,最后一个参数指定字节序 self.state.memory.store(scanf0_address, scanf0, endness=project.arch.memory_endness) self.state.memory.store(scanf1_address, scanf1, endness=project.arch.memory_endness) # 保存变量到全局,方便后续约束求解 self.state.globals['solution0'] = scanf0 self.state.globals['solution1'] = scanf1 # scanf的函数名称,可在ida中查看 scanf_symbol = '__isoc99_scanf' project.hook_symbol(scanf_symbol, ReplacementScanf()) simulation = project.factory.simgr(initial_state) simulation.explore(find=good, avoid=bad) if simulation.found: solution_state = simulation.found[0] # 对符号变量进行约束求解 stored_solutions0 = solution_state.globals['solution0'] stored_solutions1 = solution_state.globals['solution1'] scanf0_solution = solution_state.solver.eval(stored_solutions0) scanf1_solution = solution_state.solver.eval(stored_solutions1) print(scanf0_solution, scanf1_solution) else: raise Exception('Could not find the solution')
实战:12_angr_veritesting#
先逆向分析

可以看到,此题与之前的题目不同的地方在于,它不仅是按位进行比较的,而且是按位进行混淆后马上比较。之前的题目都是整体混淆后比较。因此路径爆炸同时出现在混淆和比较两个地方。
之前的做法是跳过循环比较,直接让混淆后的字符串与正确的字符串比较,但这里不能这样做,跳过循环比较就意味着跳过了混淆。
因此考虑使用路径归并的搜索策略veritesting,此题就是用来体验一把veritesting的强大功能的。
angr脚本如下,直接使用万能脚本,并且开启veritesting:
import angr import claripy import time start_time = time.perf_counter() p = angr.Project('./dist/12_angr_veritesting', auto_load_libs=False) init_state = p.factory.entry_state() def good(state): tag = b'Good' in state.posix.dumps(1) return True if tag else False def bad(state): tag = b'Try' in state.posix.dumps(1) return True if tag else False simgr = p.factory.simgr(init_state, veritesting=True) simgr.explore(find=good, avoid=bad) if simgr.found: solution_state = simgr.found[0] print(solution_state.posix.dumps(0).decode()) print(time.perf_counter() - start_time)
(不加veritesting直接能跑死机,大佬的智慧真是看不懂,但是真好用)



· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现