HBase——HMaster启动之二(HMaster线程的调用)
紧接着上一节HMaster的构建完成。接下来会调用HMaster调用master.start(),master.join()。
由HMaster的继承关系,很明显,他是Runnable的子类。也就是说,在调用其start方法时,run方法被调用。![]()
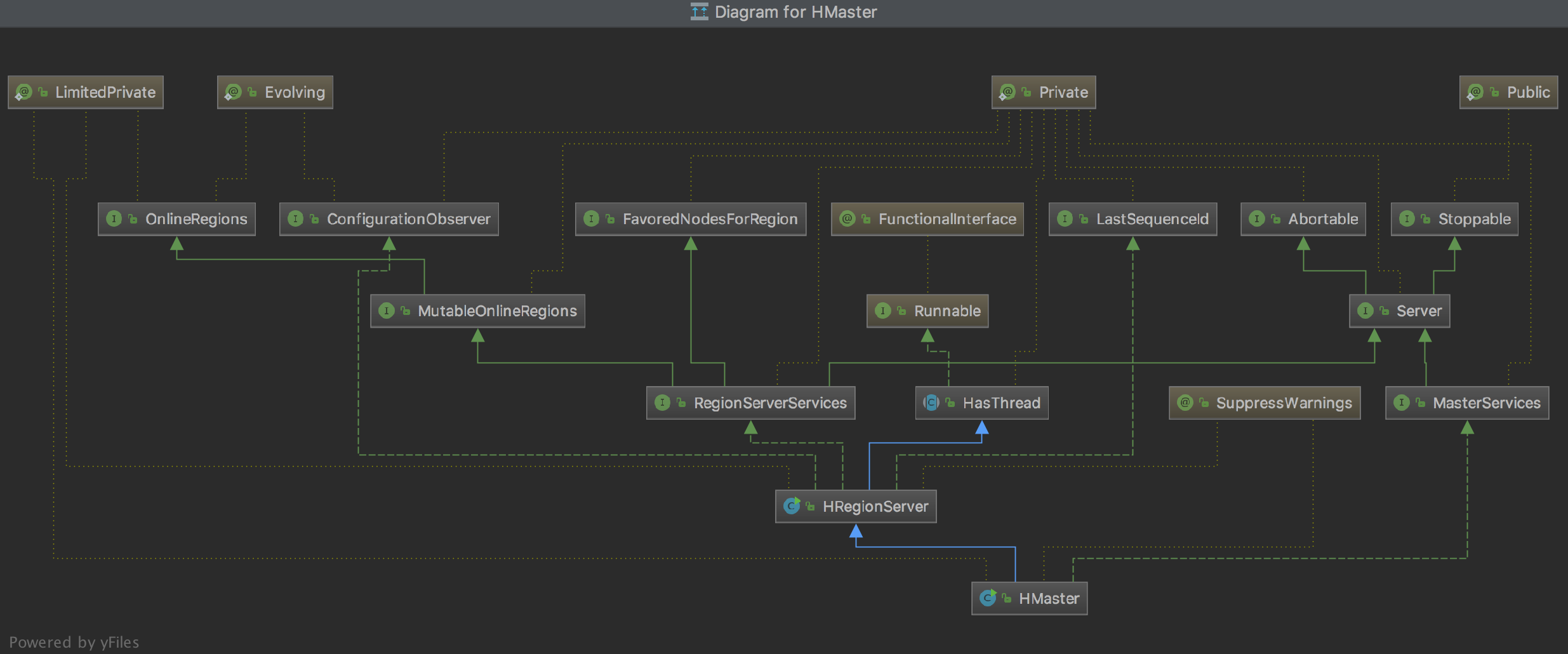

让我们来到super.run的调用。来到这里一看,内容很多,各位同学不需要慌,让我们再进入preRegistrationInitialization一探究竟。![]()
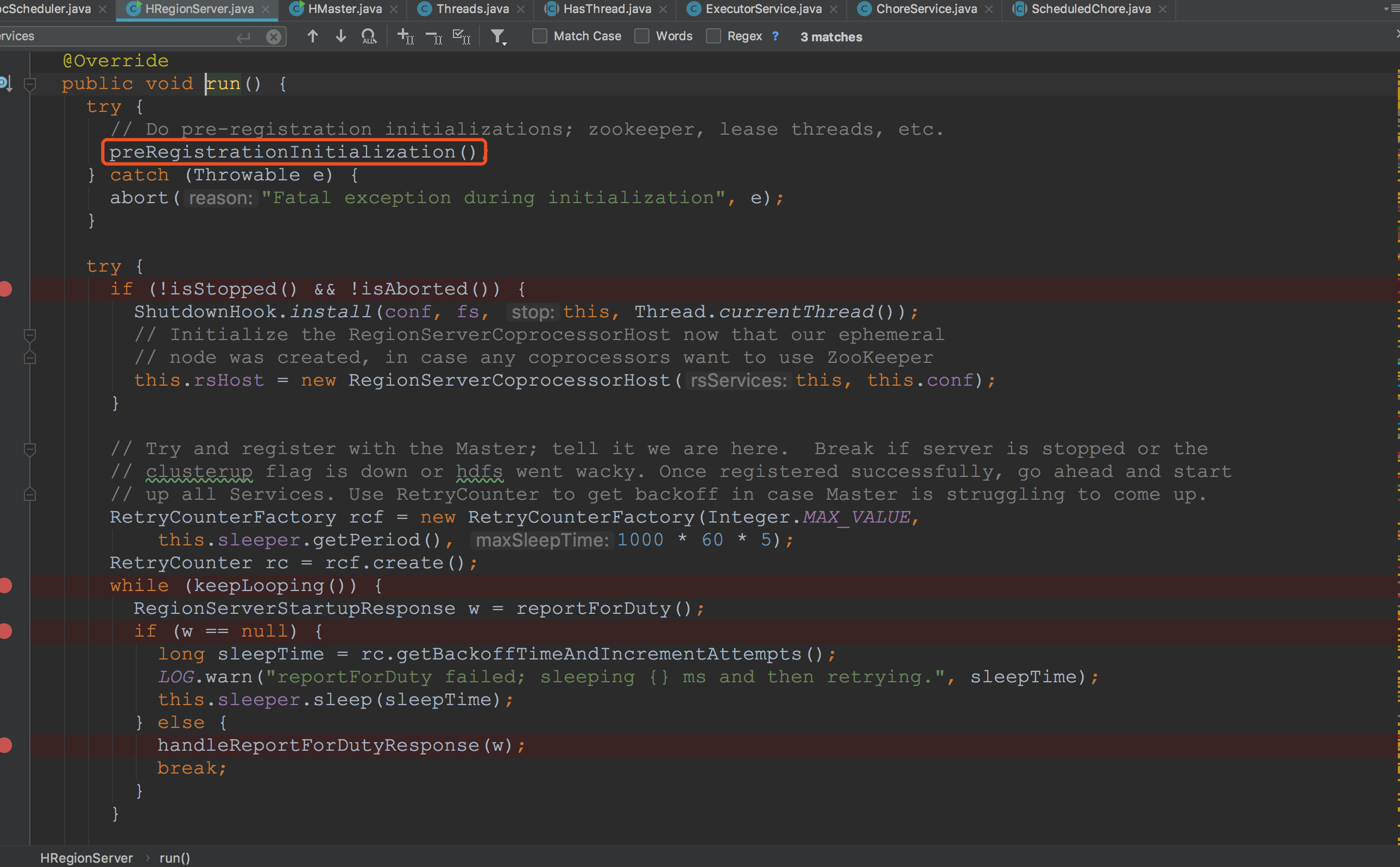
来到preRegistrationInitialization,各位同学可能有所迷惑,为什么比较关键的方法有三个,而我在这里之框选了一个呢。原因很简单,在HMaster启动期间,他还运行不到下面去。![]()
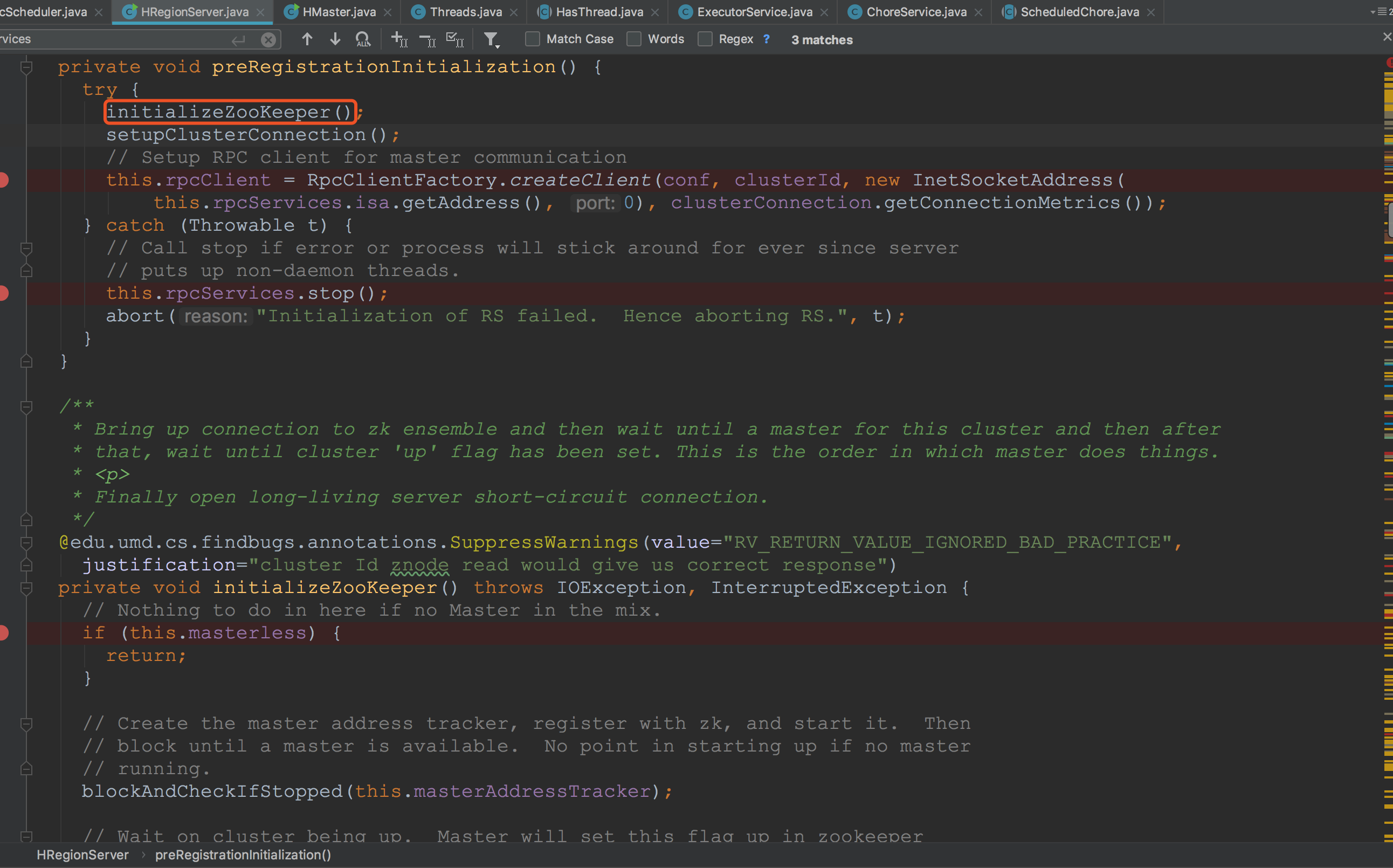
接着,让我们一探究竟。看了两个block方法,各位同学可能以为是在这里阻塞的,然而并不是,真正的等待是在下图框选的waitForMasterActive。![]()

来到waitForMasterActive(由于在这里我们研究的是HMaster,因此,这里的方法应该是HMaster.waitForMasterActive)。这个方法虽然比较短,确实困扰了我很久的一个地方。下图框选的地方获得的默认值为false,而isStopped与isAborted的获得的初始值都是false。因此,HMaster在启动时,包括启动后,都一直在这里轮询等待。因为启动后只是将activeMaster置位false。在tablesOnMaster默认值为false的情况下,并没有任何作用。也就是说只有后面的两个值发生变动后,这种等待才会被打破。分析到这里,各位同学应该可以安心的分析那个守护线程了。![]()

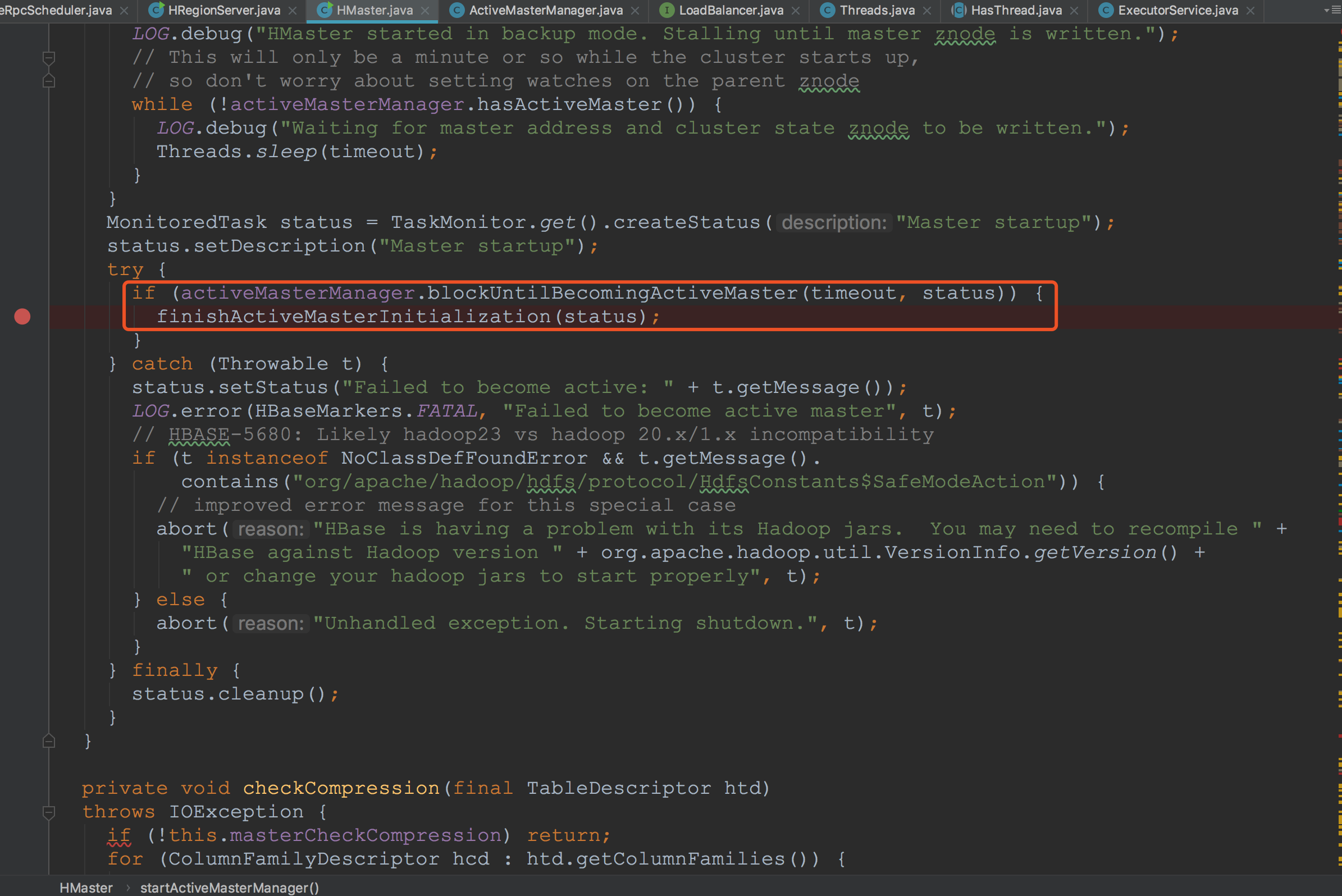
让我们来到HMaster.startActiveMasterManager方法中,首先通过调用activeMasterManager.blockUntilBecomingActiveMaster确定当前Master为ActiveMaster,然后再调用finishActiveMasterInitialization方法。这里我们只分析ActiveMaster的流程,并不介绍StandyMaster。在blockUntilBecomingActiveMaster方法中的调用并不是很难,感兴趣的同学可以简单。在activeMasterManager.blockUntilBecomingActiveMaster。这里我们把重点放在finishActiveMasterInitialization。![]()
接下来让我们来到finishActiveMasterInitialization方法。
这个方法是出奇的长,在这里,我们还是按照一张张的来介绍,以避免大家到后面会忘记前面的。![]() 首先我们分析第一个方法initializeMemStoreChunkCreator,其实这里只是初始化了
首先我们分析第一个方法initializeMemStoreChunkCreator,其实这里只是初始化了![]()
![]()
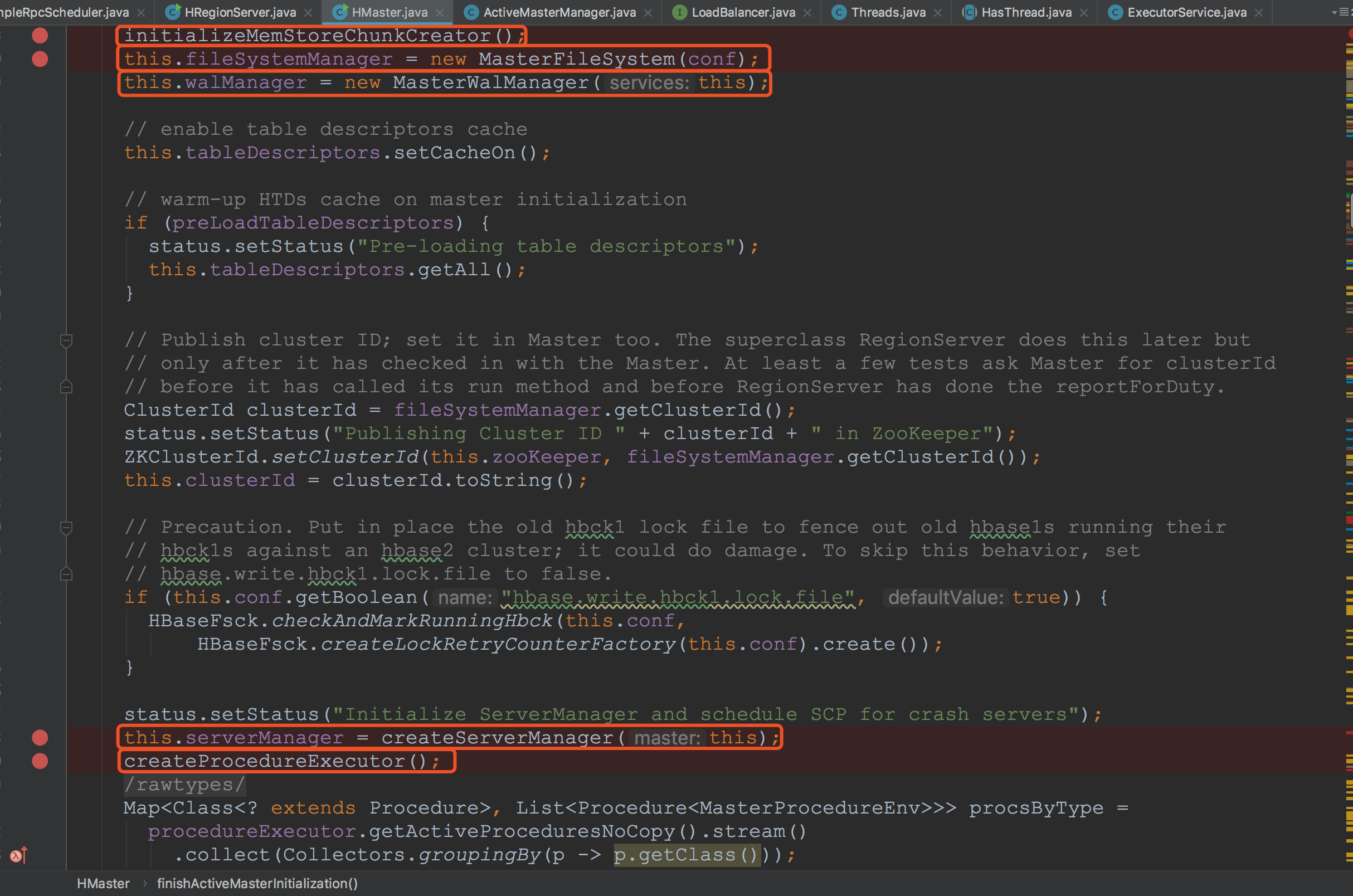 首先我们分析第一个方法initializeMemStoreChunkCreator,其实这里只是初始化了
首先我们分析第一个方法initializeMemStoreChunkCreator,其实这里只是初始化了

来到ChunkCreator的构造方法,我们可以看到其主要调用了initializePools方法![]()
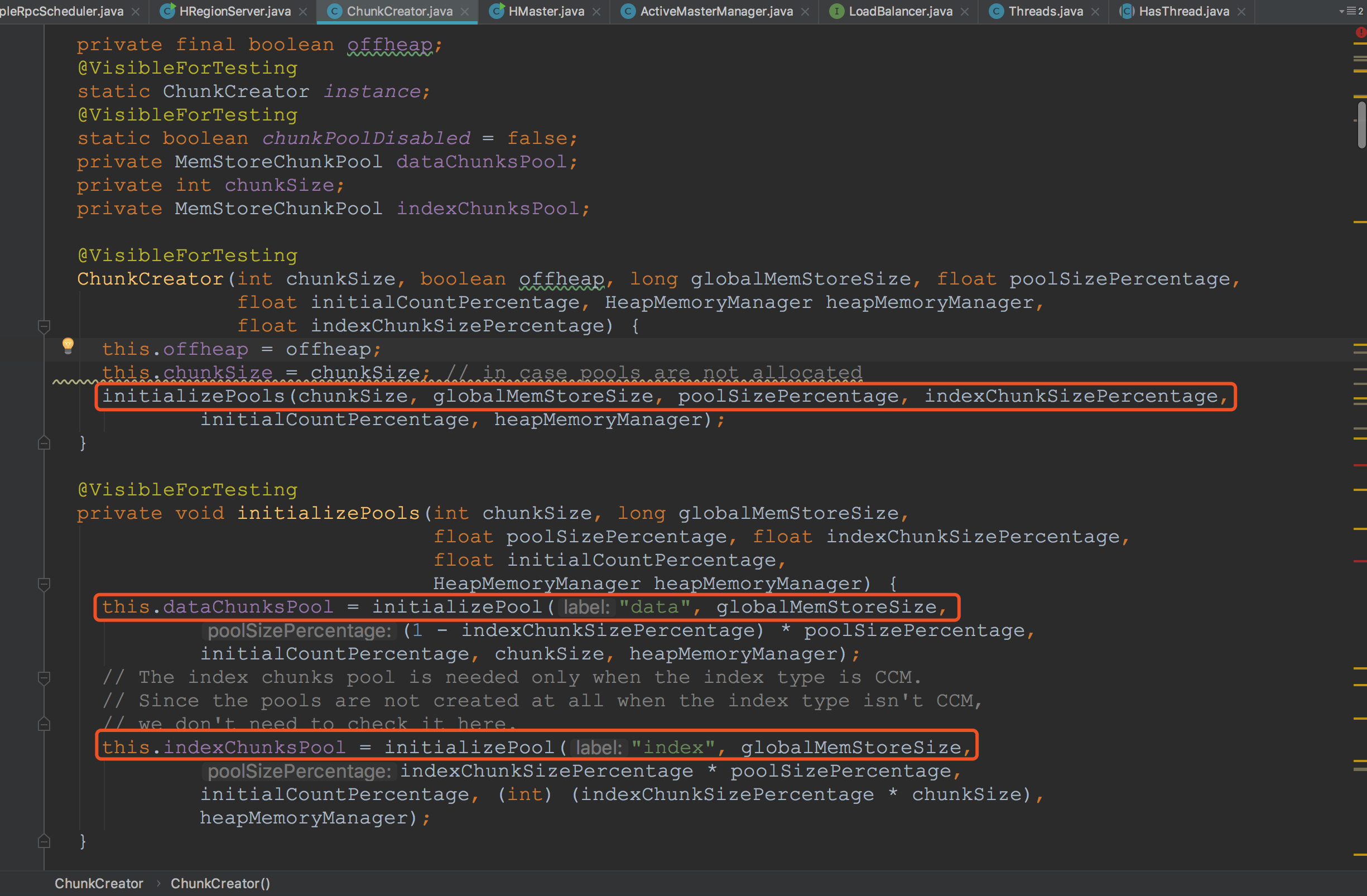
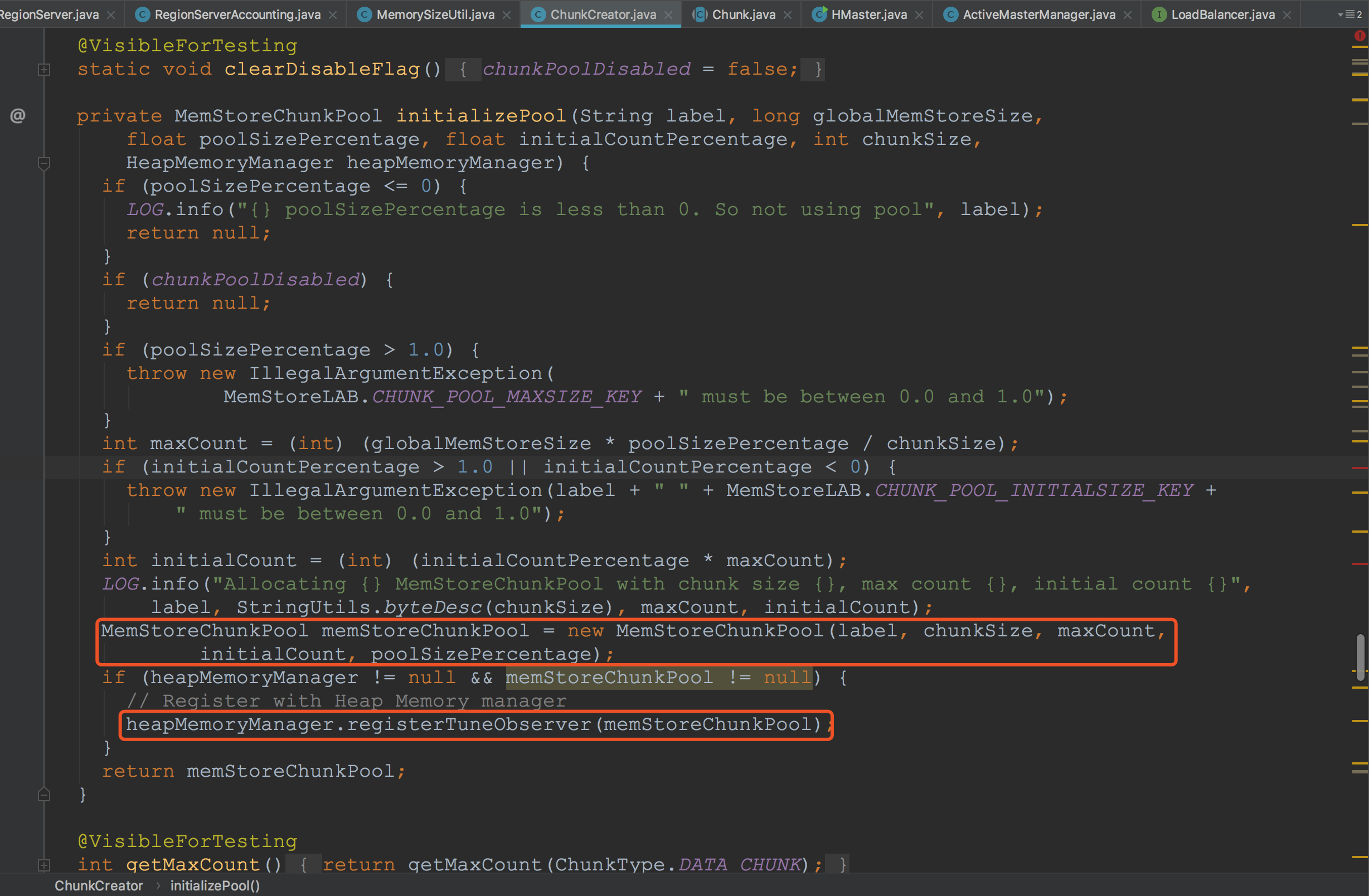
在initializePool方法中,主要构建了MemStoreChunkPool,并且将其加入heapMemoryManager的管理之中。而在构建MemStoreChunkPool的过程中,创建了Chunk,并将其放入reclaimedChunks中,初始化并开始周期调用统计线程StatisticsThread,将其内存数据打印出来。这里设计到HBase的内存管理,我将在后续的章节中专门拿出一讲来为大家讲解。这里就介绍到这。![]()
接着来到MasterFileSystem的构造方法中,这里主要获得了fs与walFs。![]()

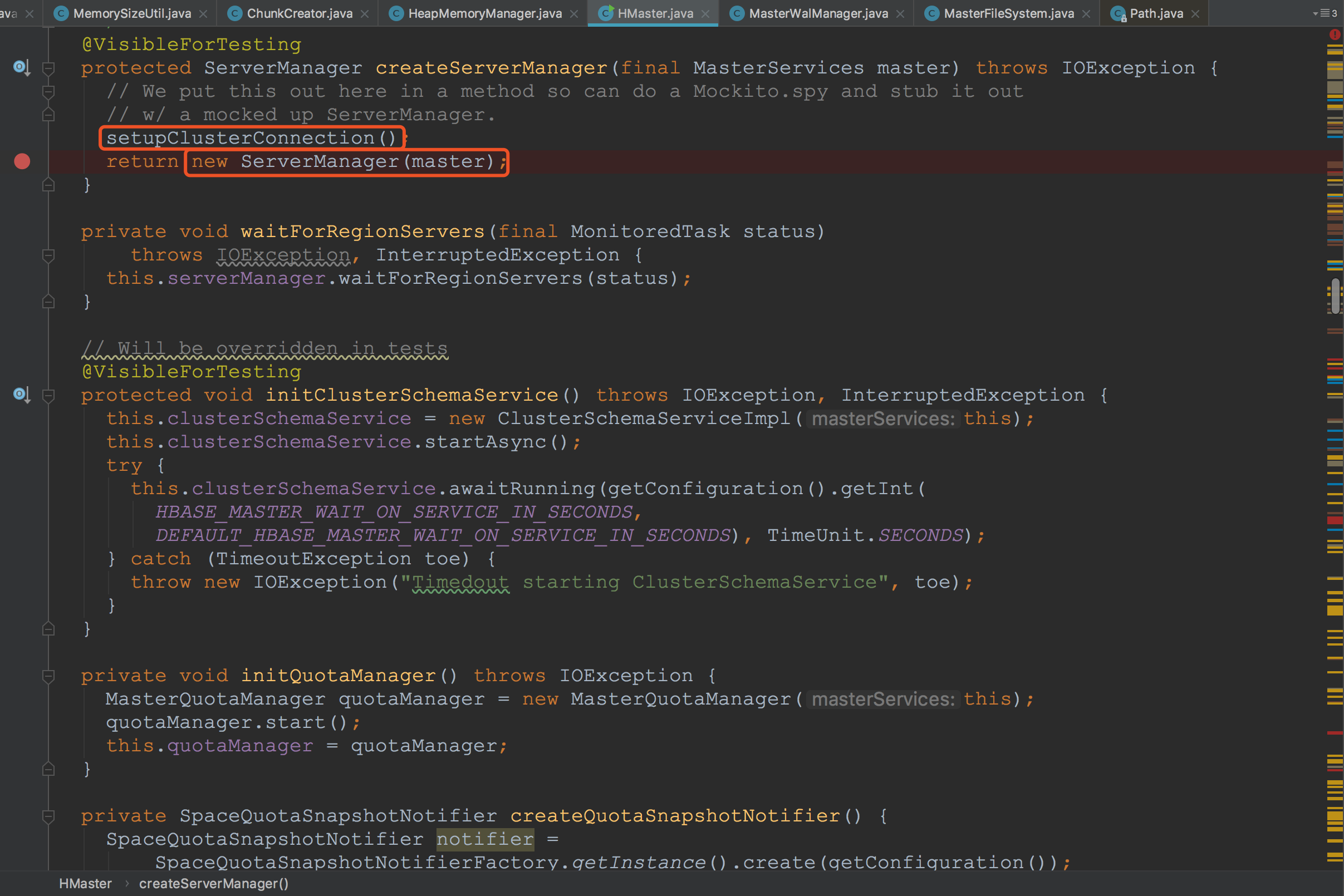
接下来,让我们来到createServerManager方法中,在这里首先构建了clusterConnection对象,其中主要构建了ShortCircuitingClusterConnection与MetaTableLocator。这里简单略过,详细内容请看我的另外一篇博文《HBase之setupClusterConnection流程》。然后构造了ServerManager,他就是HMaster用于管理region servers信息的类。![]()
再接下来,来到createProcedureExecutor,这是一个重量级的方法。![]()

让我们首先来到MasterProcedureEnv的构造方法,这个构造方法看似简单,却同时构造了两个重要的对象。RSProcedureDispatcher、MasterProcedureScheduler。其中的RSProcedureDispatcher负责HMaster向RegionServer的Procedure调用,而MasterProcedureScheduler负责的是Master自身的Procedure的调用。![]()

需要注意的是,在MasterProcedureScheduler中有几个队列的成员变量,他们的作用就是保存将要调用procedure,然后由具体线程调用。![]()

接下来是WALProcedureStore,这里主要传入了一个LeaseRecovery对象,而他的实际类型是MasterProcedureEnv.WALStoreLeaseRecovery,他的主要作用是对hdfs的文件恢复租约。![]()
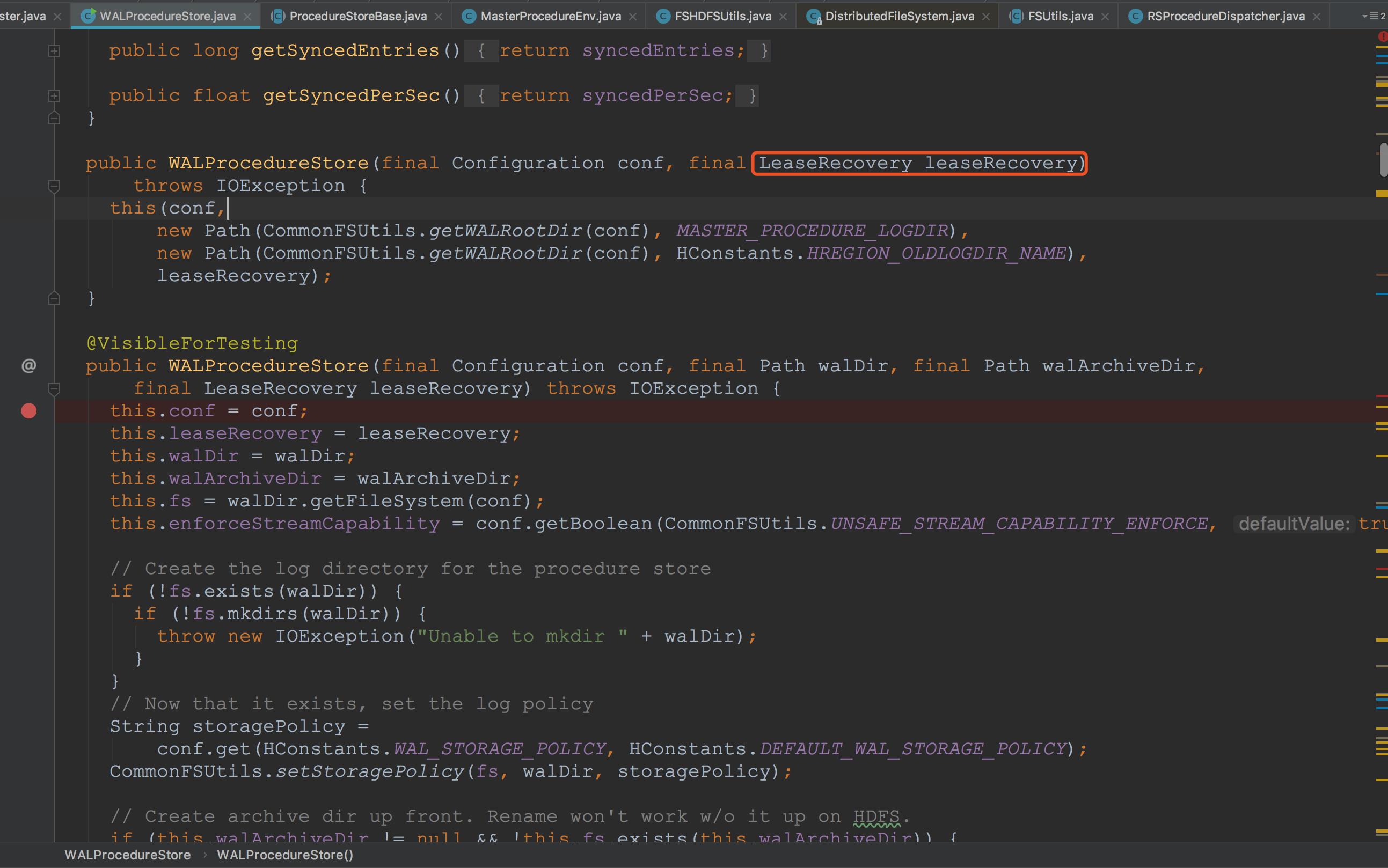
在ProcedureExecutor的构造方法中只是对其成员变量的赋值,并没有什么比较重要的方法。不过,在这里我们需要记住,在这里传入的store类型为WALProcedureStore,scheduler类型为MasterProcedureScheduler。![]()
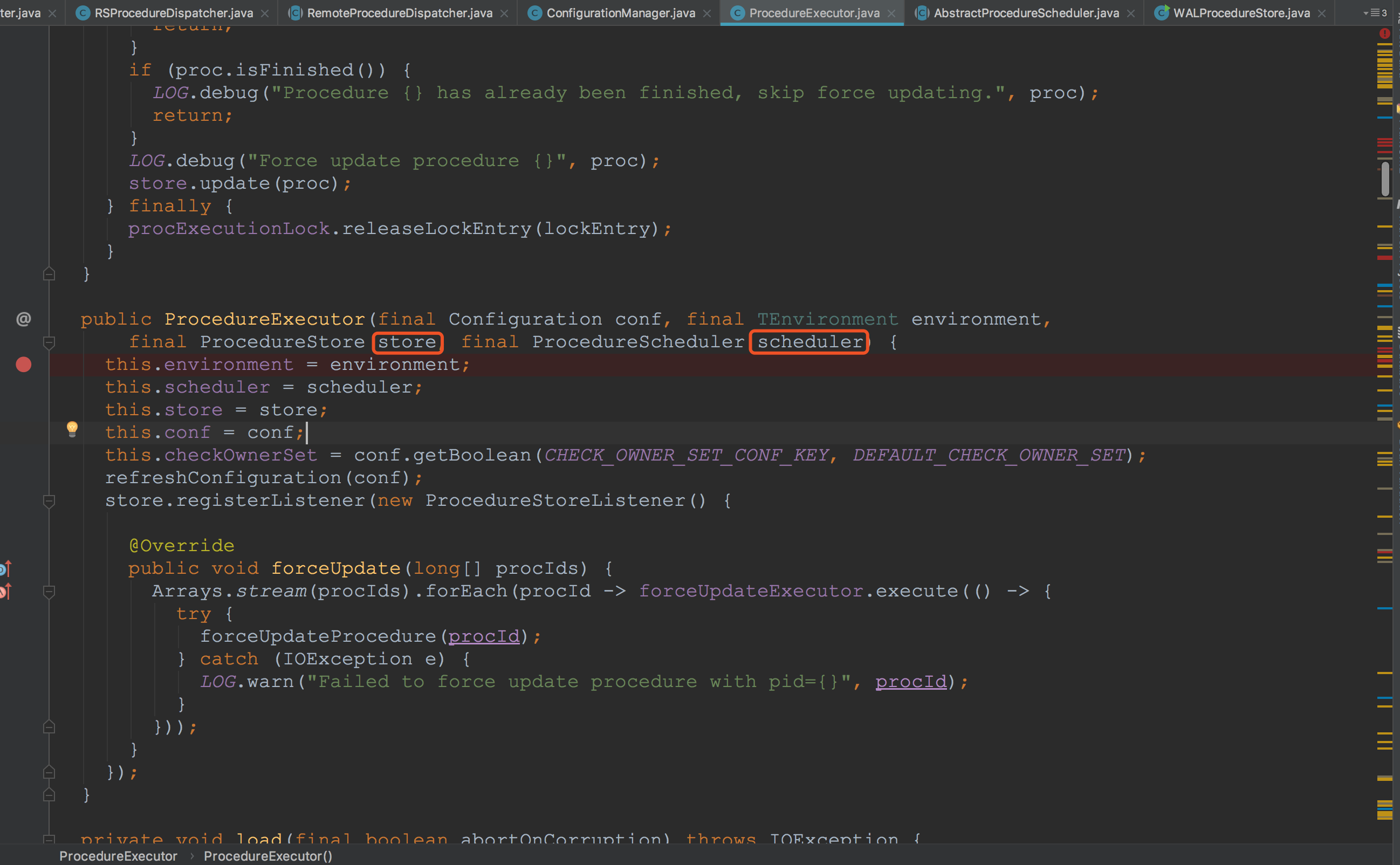
接下来来到WALProcedureStore.start方法。在这里,根据传入的线程数初始化了Slot数量,并且启动WALProcedureStoreSyncThread线程用于调用syncLoop方法。这里就简单略过,我们先继续后面的流程。![]()

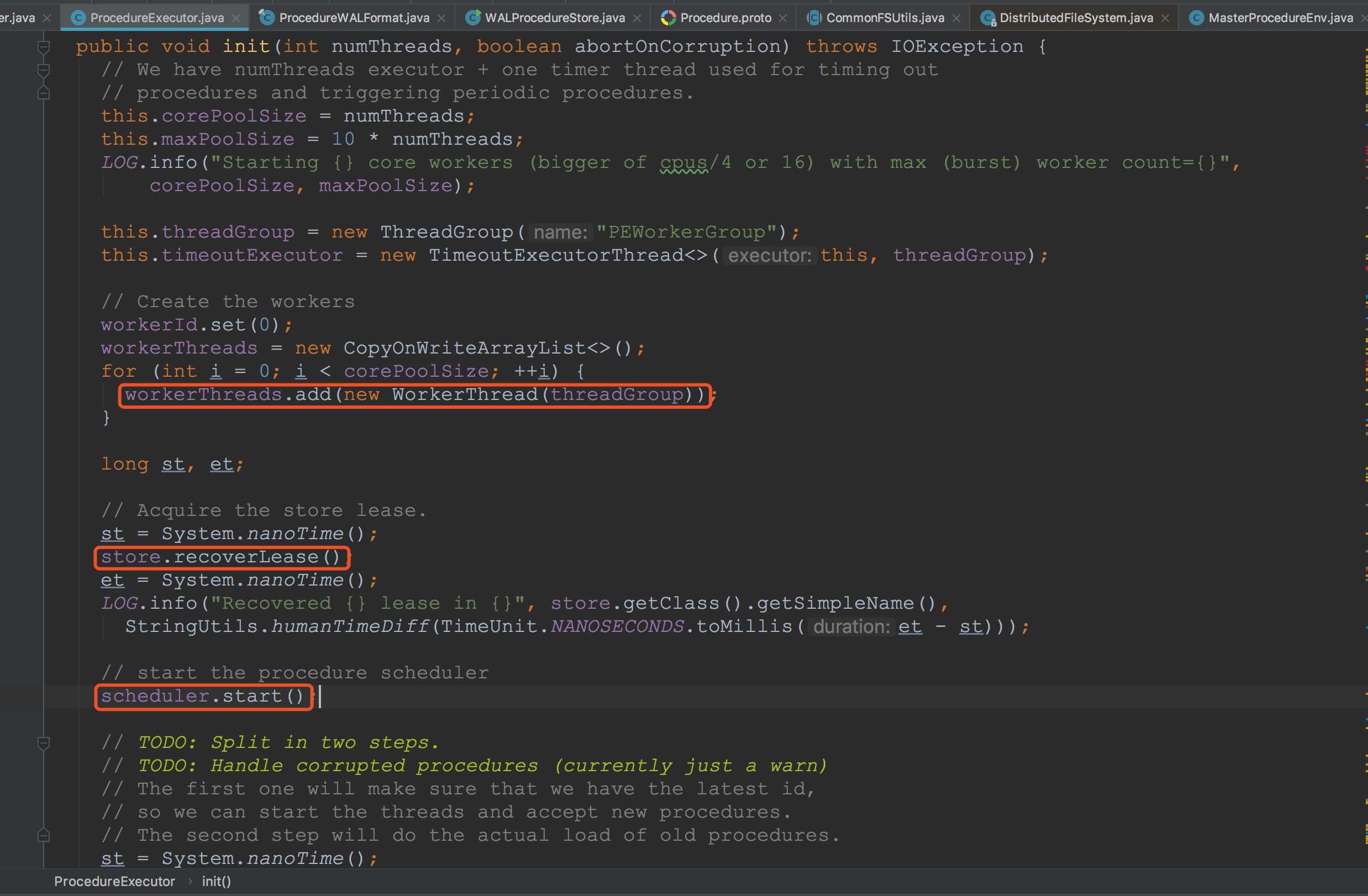
下面,来到ProcedureExecutor.init方法。这里将WorkerThread,添加到workerThread成员变量中。接着调用store.recoverLease,恢复相关文件的租约。然后调用scheduler.start,将scheduler中的running置位true。![]() 这里简单看一下WorkThread中的run方法。这里的流程在我的博文《hbase之InitMetaProcedure流程》中有相关介绍,感兴趣的大家可以去看一下。
这里简单看一下WorkThread中的run方法。这里的流程在我的博文《hbase之InitMetaProcedure流程》中有相关介绍,感兴趣的大家可以去看一下。![]()
 这里简单看一下WorkThread中的run方法。这里的流程在我的博文《hbase之InitMetaProcedure流程》中有相关介绍,感兴趣的大家可以去看一下。
这里简单看一下WorkThread中的run方法。这里的流程在我的博文《hbase之InitMetaProcedure流程》中有相关介绍,感兴趣的大家可以去看一下。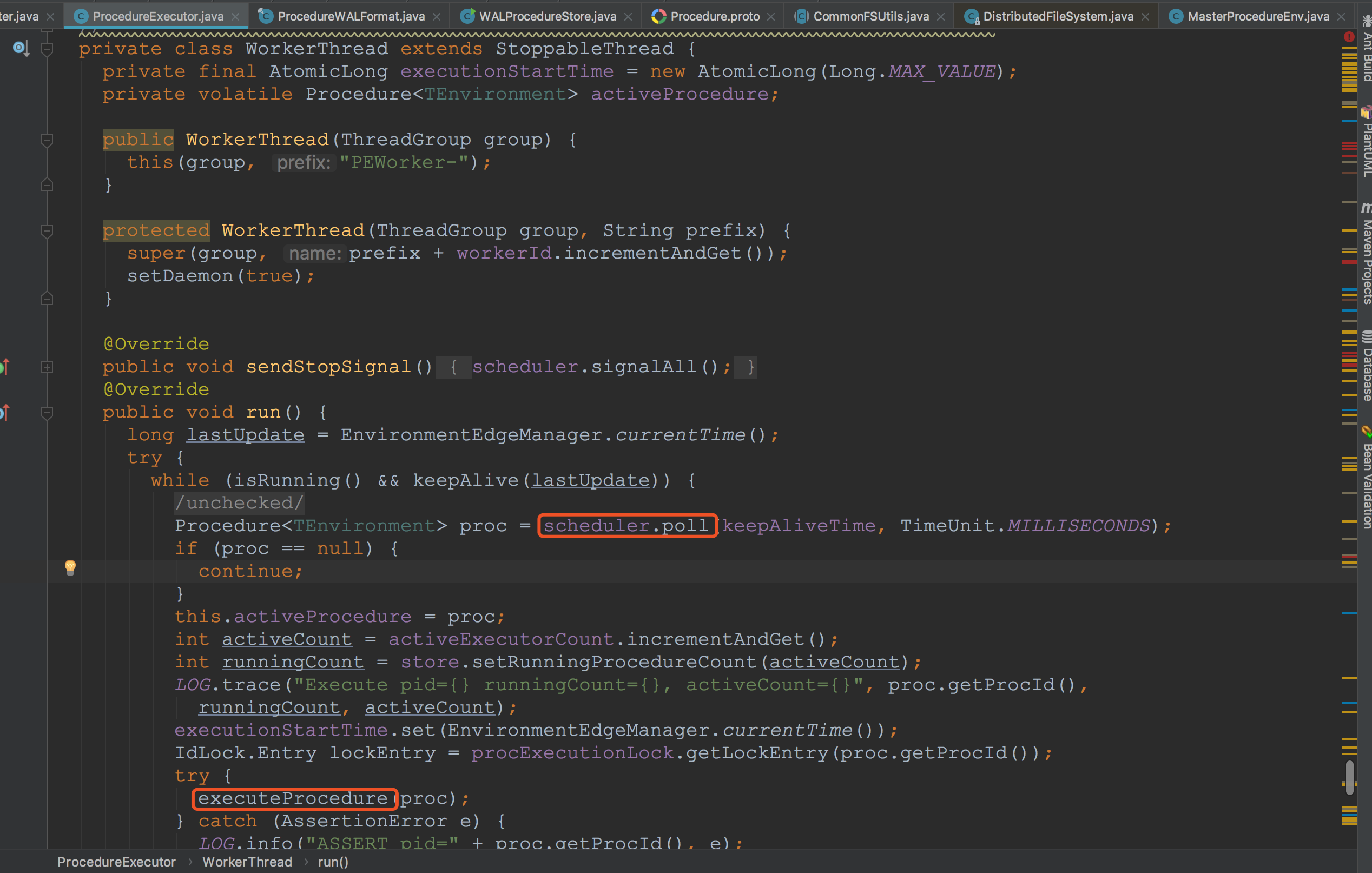
接下来来到finishActiveMasterInitialization的第二张图。
首先创建了AssignmentManager,AssignmentManager的作用就是用来操作assign/unassign。然后调用了AssignmentManager.start方法。关于AssignmentManager的相关调用我在博文《HBase之AssignmentManager相关调用》中有介绍,感兴趣的同学可以去看一下。接下来构造并调用了RegionServerTracker,用于通过ZK跟踪在线RegionServers。![]()

然后调用了initializeZKBasedSystemTrackers方法,在这里初始化了所有基于ZK的系统跟踪器。尽管如此,还是有些方法值得我们探究。首先介绍各种Tracker,这些都是直接或间接继承自ZKListener,或者将传入的ZK保存到自己的成员变量中用来实现对自己所在ZK目录中状态的监听。![]()
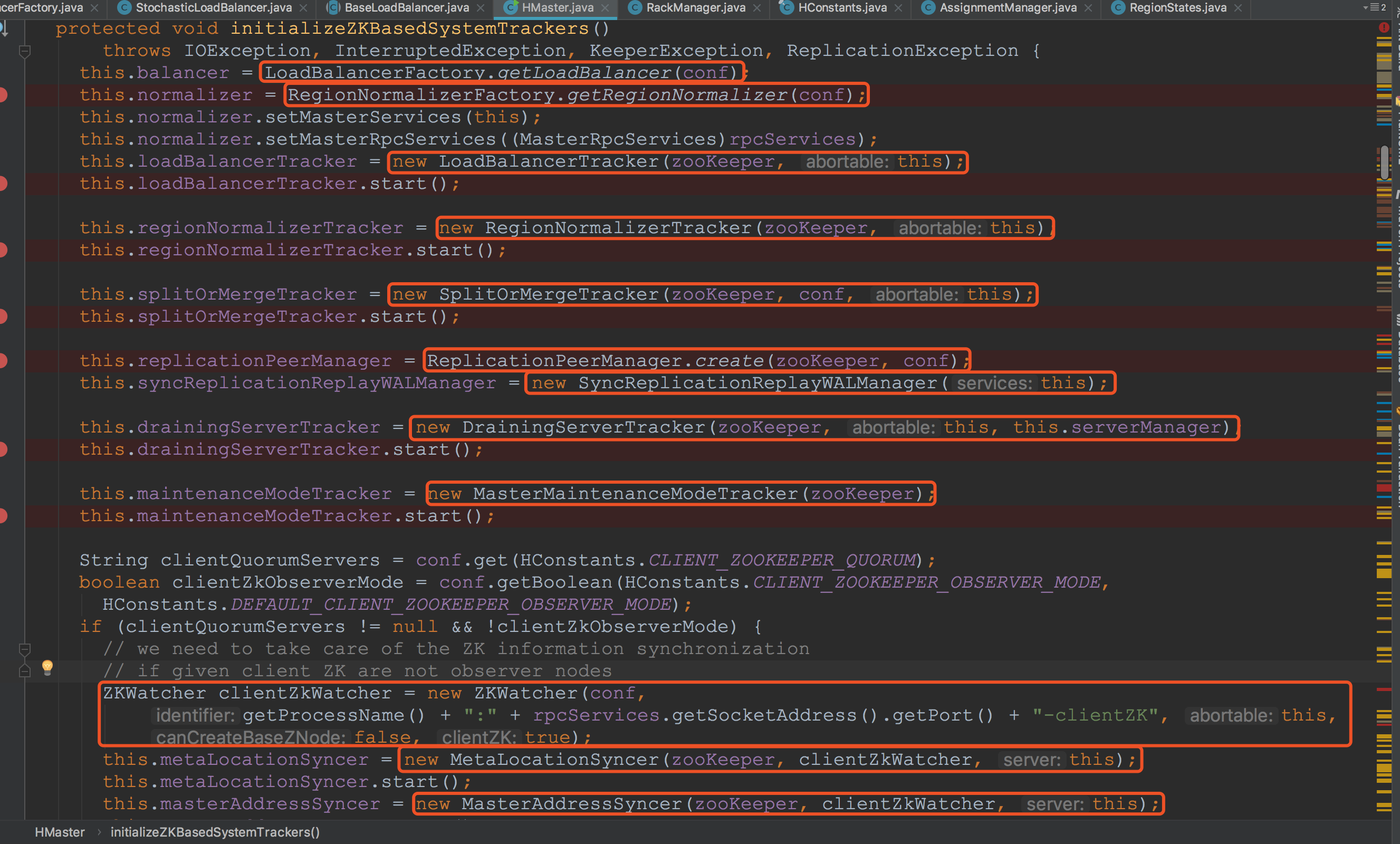
然后来到LoadBalancerFactory.getLoadBalancer方法,这里调用ReflectionUtils.newInstance通过反射创建了StochasticLoadBalancer,同时由于StochasticLoadBalancer实现了Configurable接口。因此在通过反射创建了StochasticLoadBalancer,紧接着变调用了setConf方法。在StochasticLoadBalancer.setConf中调用了构造了各种CostFunction。在这里我们简单略过![]() 。
。![]()

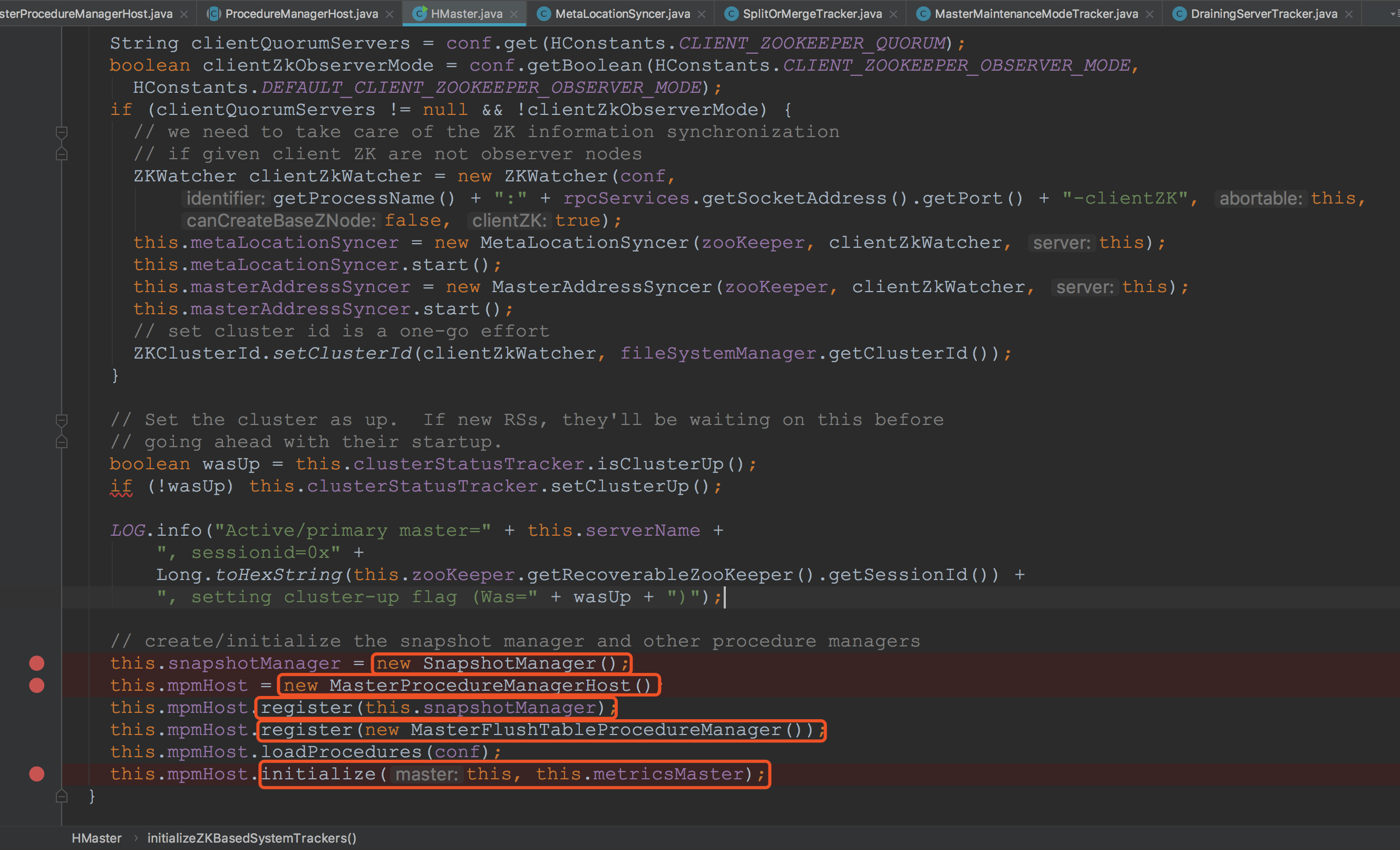
接下来来到方法的后面,这里构建了SnapshotManager、MasterFlushTableProcedureManager(二者都继承自抽象类ProcedureManagerHost)并且注册到创建的MasterProcedureManagerHost对象中。接着调用了MasterProcedureManagerHost.initialize,调用了刚刚注册进来的两个对象initialize方法。![]()
接下来来到finishActiveMasterInitialization的下一张图。如果已经不是第一次调用,那么就不会调用框二中所选的内容,不过,感兴趣的同学可以去看我的博客《hbase之InitMetaProcedure流程》。这里我们只介绍框一与框三中的内容。![]()

来到HMaster.startServiceThreads。这里的executorService大家可能已经忘记了,他是在HMaster构造时实例化的(具体是在HMaster的父类HRegionServer构造的最后)。通过调用executorService.startExecutorService,ExecutorType的类型与最大线程数量传入ExecutorService.startExecutorService,构造了相应名称的线程池,并且将其置于ExecutorService的成员变量executorMap的管理之下。接下来我们简单介绍一下getChoreService().scheduleChore。这是ScheduledChore调用的通用方式,通过getChoreService获取初始化的成员变量choreService(同样在HMaster的父类HRegionServer构造的最后实例化的),然后调用其scheduleChore方法,在上面我已经讲过了,这里就不再赘述了。![]()

接着调用waitForRegionServers等待RegionServer的注册。关于HMaster与HRegionServer的交互流程我在以后的章节中会介绍到。接下来调用waitUntilMetaOnline,等待hbase:meta上线并且可读。以为后面assignmentManager.joinCluster中loadMeta做准备。![]()
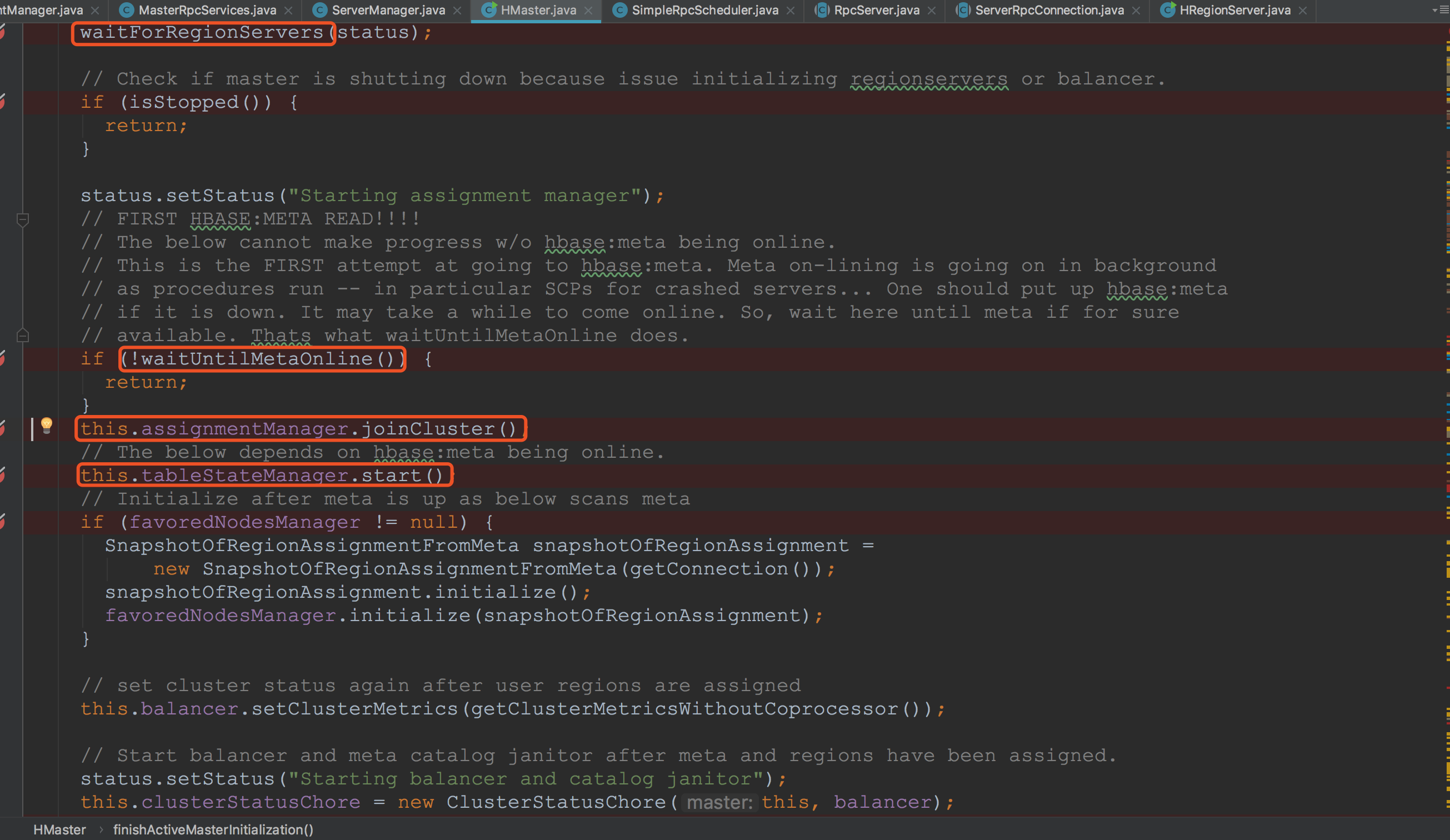
接下来,我们首先来到assignmentManager.joinCluster
在loadMeta中,主要用于载入hbase:meta的各个Region,并且将其加入到regionStates的管理中。接下来调用processOfflineRegions,当前保存在AssignmentManager.regionStates中,其状态OFFLINE的Regions。然后将成员变量ritChore加入到ProcedureExecutor的timeoutExecutor中。![]()
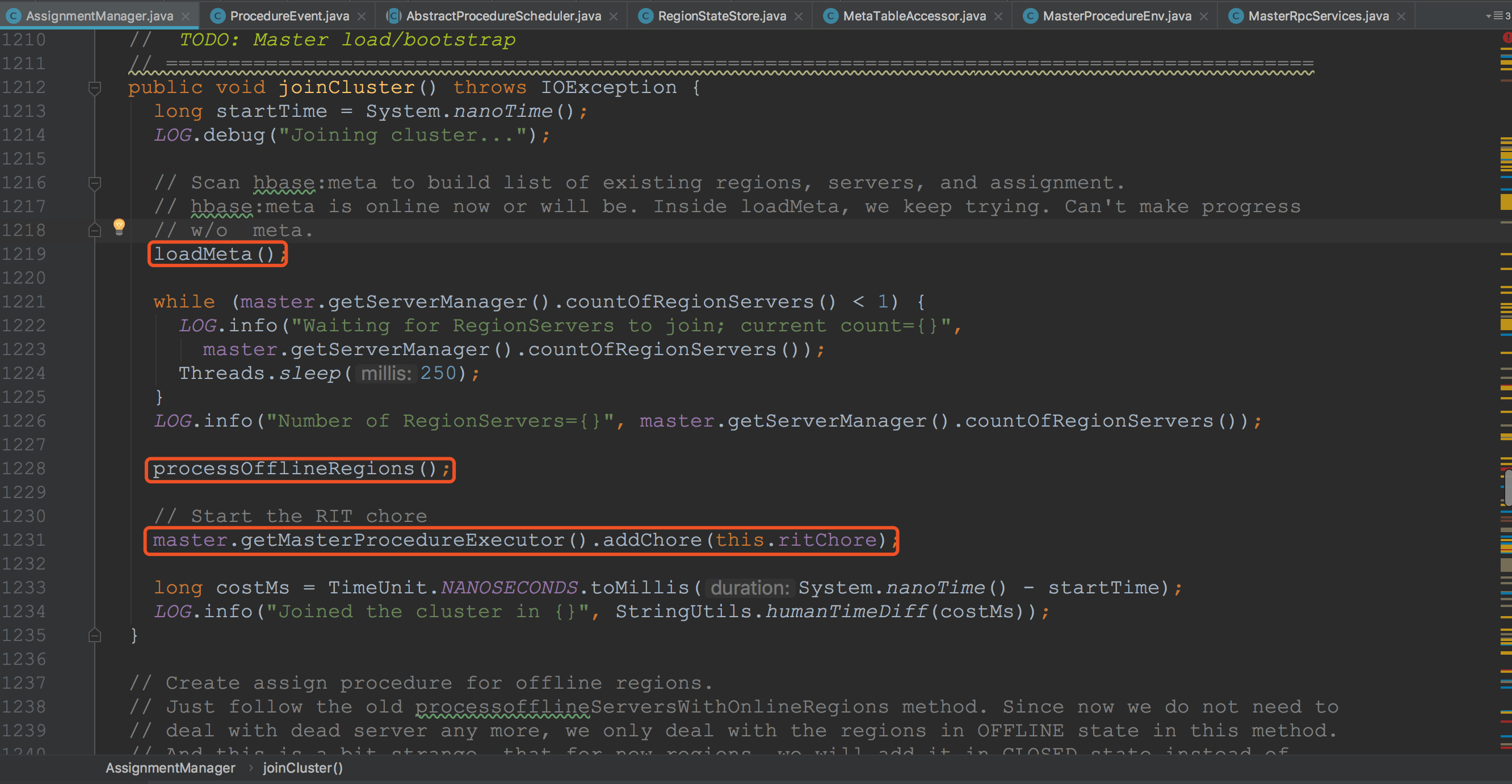
接下来调用了TableStateManager.start,将当前的表都置于TableStateManager的管理之中。![]()

下面框选中的内容虽然多,但是,我们只是简单介绍。因为这里已经不是很主要的流程了。首先是几个ScheduledChore的子类构建并调用。接着,调用ServerManager.startChore其主要讲FlushedSequenceIdFlusher这个ScheduledChore构建并开始调用。然后,调用了initClusterSchemaService、cpHost.preMasterInitialization。最后,将三个ConfigurationObserver注册到configurationManager中。![]()

来到FAMI中的最后一张图,这里我们只是引出,关于其中具体的流程,我们将在后面意义道来。在后面主要介绍initMobCleaner。![]()

下图首先构建了ExpiredMobFileCleanerChore(这个ScheduledChore用于定期删除过期的mob文件),然后将其加入到choreService中并启动。紧接着构建并启动了MobCompactionChore,这个ScheduledChore用于定期压缩以合并小的mob文件。然后构建了MasterMobCompactionThread。![]()

至此,HMaster的启动流程就完成了,感谢大家内心观看。说实话,不仅各位看的辛苦,小编我写的也很辛苦,所以,留下你的赞,小编更有动力发表更好的文章。
学完这一节,很多同学可能会对netty的原理想要有比较深入的了解。请各位同学不要着急,在介绍完HBase中比较重要的流程,小编就会为大家带来netty的深入应用以及源码剖析。请大家持续关注。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号