计算机组成与体系结构(COaA)复习知识点
前言
- 冯诺依曼体系结构及其五大部件
- 三种类型的计算机
- 计算机体系结构的概念
- 计算机的组成
- 计算机的实现
- 计算机的性能评价方法
冯诺依曼体系结构及其五大部件
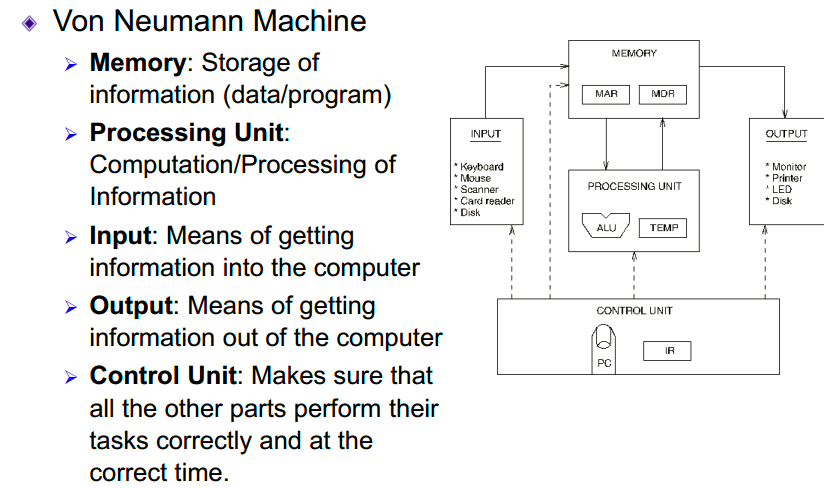
特征
最重要特征:存储程序、顺序访问(按地址访问)
“程序存储”:指令以代码的形式事先输入到计算机的主存储器中,然后按其在存储器中的首地址执行程序的第一条指令,以后就按该程序的规定顺序执行其他指令,直至程序执行结束。即按地址访问并顺序执行指令
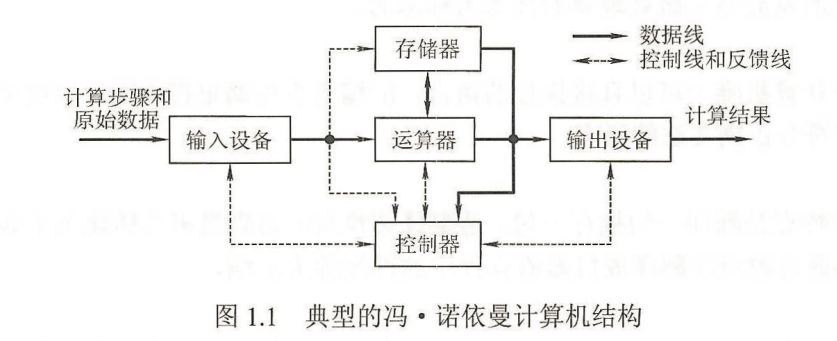
- 冯诺曼体系结构特点:
- 计算机硬件系统由五大部件组成(存储器、运算器、控制器、输出设备、输入设备)
- 指令和数据以同等地位存于存储器,可按地址寻访
- 指令和数据用二进制表示
- 指令由操作码和地址码组成
- 存储程序
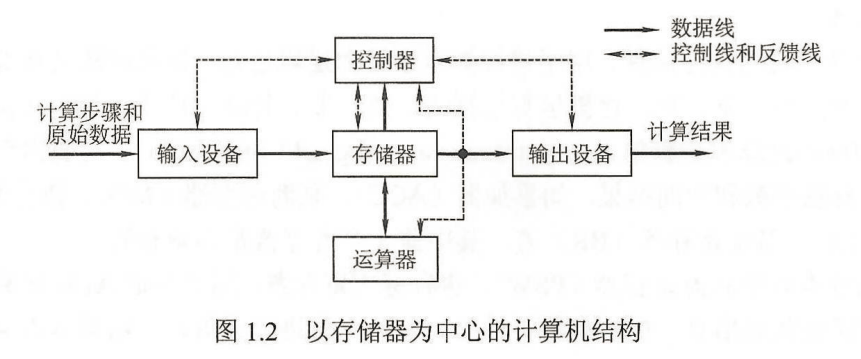
- 以运算器为中心
冯·诺依曼机器的五大部件
- 存储器(Memory+Storage):信息(数据/程序)的存储
- 运算器:信息的计算/处理
- 输入设备:将信息输入计算机的方法
- 输出设备:将信息从计算机中取出的方法
- 控制器:确保所有其他部分在正确的时间正确执行其任务
输入设备,是指将外部信息以计算机能读懂的方式输入进来,如键盘,鼠标等
输出设备,就是将计算机处理的信息以人所能接受的方式输出出来,比如显示屏,打印机。
存储器,存储器分为 主存储器(内存储器,CPU能直接访问)和 辅助存储器(外存储器,协助主存储器记忆更多的信息,辅助存储器的信息需要导入到主存储器中,才可以被CPU访问)。
主存储器的工作方式是按存储单元的地址进行存取,这种存取方式称为按地址存取方式(相联存储器既可以既可以按照地址寻址,又可以按照内容寻址,为了与传统存储器区别,又称为内容寻址的存储器!)
主存储器是由地址寄存器(MAR),数据寄存器(MDR),存储体,时序控制逻辑,地址寄存器存放访存地址,经过地址译码后找到所选的存储单元。数据寄存器,是存储器与其他部件的中介,用于暂存要从存储器读或写的信息。时序控制逻辑用于产生存储器操作所需的各种时序信号。在现代CPU,MAR和MDR是在CPU中的。
运算器,是计算机的运算单元,用于算术运算和逻辑运算
运算器的核心单元是算术逻辑单元(ALU)
控制器,控制器是计算机的指挥中心,有其指挥各部件自动协调第进行工作,现代计算机将运算器和控制器集成到一个芯片上,合成为中央处理器,简称CPU。有程序计数器(PC)、指令寄存器(IR)和控制单元(CU)。
三种类型的计算机
桌面计算机:桌面计算机的产品范围非常广泛,包括低端的上网本、台式计算机、笔记本计算机以及高配置的工作站。

服务器:服务器主要提供大规模和可靠的文件及计算服务,强调可用性、可扩展性和很高的吞吐率。

嵌入式计算机:嵌入式计算机是专用的,针对某个特定的应用的,对功能、可靠性、成本、体积、功耗有严格要求的计算机系统。

计算机体系结构/计算机组成的概念
计算机体系结构是指机器语言或汇编语言程序员所看得到的传统机器的属性,包括指令集、数据类型、存储器寻址技术等,大都属于抽象的属性。
计算机组成是指如何实现计算机体系结构所体现的属性,它包含对许多对程序员来说透明的硬件细节。
例如,指令系统属于结构的问题,但指令的实现即如何取指令、分析指令、取操作数如何运算等都属于组成的问题。因此,当两台机器指令系统相同时,只能认为它们具有相同的结构,至于这两台机器如何实现其指令,完全可以不同,即可以认为它们的组成方式是不同的。例如,一台机器是否具备乘法指令是一个结构的问题,但实现乘法指令采用什么方式则是一个组成的问题。(简言之,看有没有这个属性,就是结构问题;看怎么实现,就是组成问题)
计算机的性能评价方法
CPI及其计算
CPI(Clock cycle Per Instruction),每条指令执行所需的平均时钟周期数。
CPI的计算:
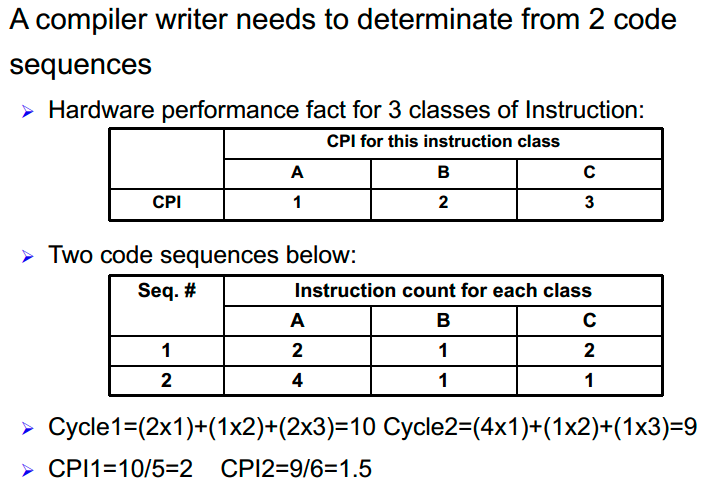
总体有效CPI:

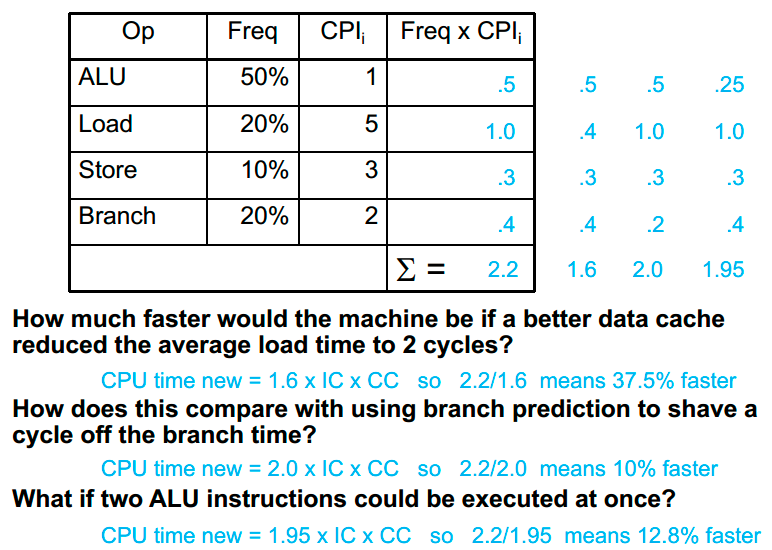
CPU执行时间 = (指令条数×CPI)/时钟频率
阿姆达尔(Amdahl)定律

例题:
\( 80=\frac{1}{(1-p)+ \frac{p}{100}} \),得出:\(p=99.75\%\)。
指令集
- 指令执行的流程
- 指令格式
- 计算机的基本操作指令
- 操作数的载体
- 寄存器/操作码数量对程序性能或大小的影响
指令执行的流程
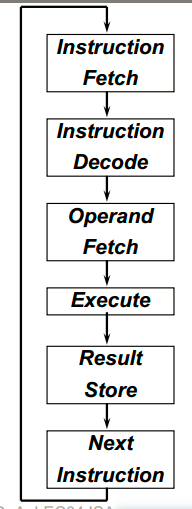
取址——译码——取数——运算——写结果——计算下一条指令地址,往复执行
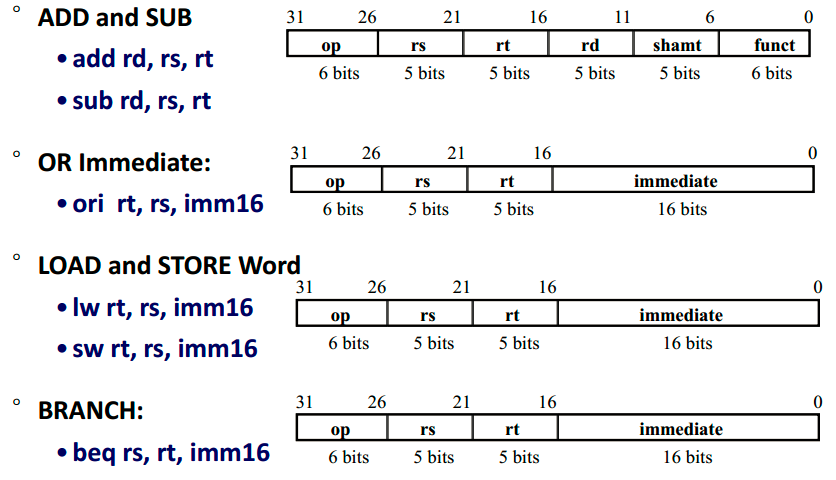
指令格式
OP字段+若干个操作数
(要做什么+操作的对象)
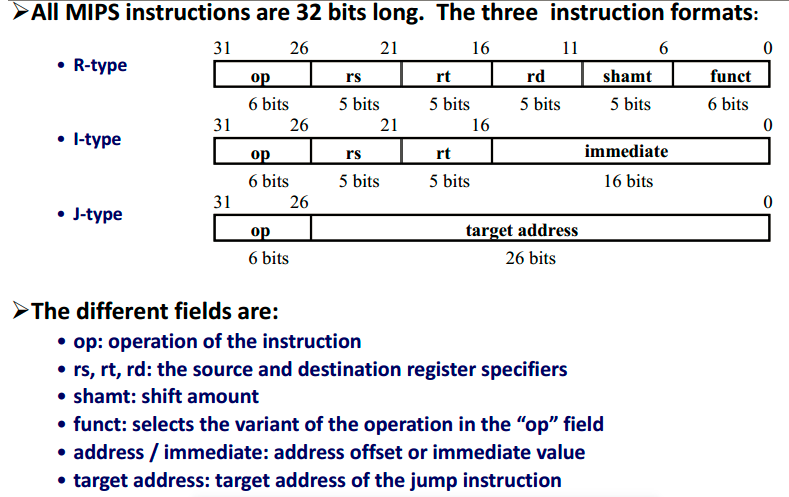
- R型:操作数都取自寄存器,其中,rs、rt分别表示源寄存器1和源寄存器2,rd表示目标寄存器,shamt字段用于移位操作,funct字段指定具体的操作类型。
- I型:有一个操作数是常量,其中,第一个操作数寄存器(rs)和目标寄存器(rt)表示指令中涉及的寄存器编号,立即数(imm)表示指令中涉及的立即数的值。
- J型:直接跳转指令
计算机的基本操作指令
算术逻辑操作、取数存数操作……
1.算术和逻辑指令
算术和逻辑指令是MIPS指令集中最基本的指令之一,用于执行加、减、乘、除、与、或、异或等基本算术和逻辑运算。其中一些常用的指令如下:
\(ADD\ \$rd, \$rs, \$rt\):
将寄存器rs和rt的值相加,结果存入寄存器 r d 。
\(SUB\ \$rd, \$rs, \$rt\):
将寄存器 r s 和 rs和 rs和rt的值相减,结果存入寄存器 r d 。
\(ADDI\ \$rt, \$rs, imm\):
将寄存器 r s 和立即数 i m m 相加,结果存入寄存器rt。
\(ADDIU\ \$rt, \$rs, imm\):
将寄存器 r s 和立即数 i m m 相加,结果存入寄存器rt。
与ADDI的区别在于,ADDIU对立即数的符号不做特殊处理,而是视为无符号整数相加。
\(OR\ \$rd, \$rs, \$rt\):
将寄存器 rs和rt的值进行按位或运算,并将结果存入寄存器 r d 。
\(XOR\ \$rd, \$rs, \$rt\):
将寄存器 rs和rt的值进行按位异或运算,并将结果存入寄存器 r d 。
\(SLT\ \$rd, \$rs, \$rt\):
将寄存器 rs和rt的值进行比较,如果 rs < r t ,则将寄存器rd的值设为1,否则设为0。
2.存储器指令
存储器指令是MIPS指令集中用于读取和写入存储器中的数据的指令。这些指令包括加载(load)和存储(store)指令,其中加载指令用于从存储器中读取数据并将其存储到寄存器中,而存储指令则用于将寄存器中的数据写入存储器中。以下是一些常用的存储器指令:
\(lw\ t , o f f s e t ( s)\):
加载字(Load Word)指令,从内存中读取一个32位字(word)的数据,存储到寄存器 t 中。其中,s指定了内存地址的基地址,offset是一个16位的有符号立即数,表示相对于基地址的偏移量
\(sw\ t , o f f s e t (s)\):
存储字(Store Word)指令,将寄存器 t 中的 32 位数据存储到内存中。其中,s指定了内存地址的基地址,offset是一个16位的有符号立即数,表示相对于基地址的偏移量。例如,sw t0 , 8 (s2)表示将 t 0 中的一个字的数据存储到内存地址s2+8处。
lb:从存储器中加载一个8位的字节(byte)并将其存储到寄存器中。
sb:将寄存器 t 中的 8 位数据存储到以寄存器s的值加上偏移量offset所表示的内存地址中的一个字节中。
3.分支和跳转指令
分支和跳转指令是MIPS指令集中用于控制程序流程的指令。其中分支指令根据特定的条件改变程序的执行路径,而跳转指令则直接将程序转移到一个新的地址。以下是一些常用的分支和跳转指令:
\(BEQ\ \$rs, \$rt, offset\):
如果寄存器 rs和rt的值相等,则跳转到当前指令地址+ 4 + 4 × o f f s e t 处执行。具体步骤为:将 4+4×offset处执行。具体步骤为:将 4+4×offset处执行。
\(BNE\ \$rs, \$rt, offset\):
如果寄存器 rs和rt的值不相等,则跳转到当前指令地址+ 4 + 4 × o f f s e t 处执行。
\(J\ target\):
无条件跳转到目标地址执行。具体步骤为:将PC的高4位设置为当前指令的地址的高4位,将PC的低28位设置为目标地址的高4位×4,跳转到该地址执行下一条指令。目标地址是一个32位的地址,但只有高28位有效,低4位会被忽略。
\(JALR\ \$rd, \$rs\):
将寄存器 r s 中的值作为目标地址跳转,并将下一条指令的地址存入寄存器rd。具体步骤为:将PC的值存入 r d ,将rs中的值设置为目标地址,跳转到该地址执行下一条指令。注意,$rs中的值必须是一个有效的地址,即它的低2位必须为0,因为跳转时会将最低的两位强制设置为0。
4.特权指令
特权指令是MIPS指令集中用于操作特权级别的指令。这些指令只能由特权级别较高的程序执行,并且可以用于访问系统资源或执行特定的操作。以下是一些常用的特权指令:
\(SYSCALL\):
用于在用户程序中发起系统调用(system call)。该指令没有任何操作数。执行SYSCALL指令时,CPU将会进入内核态,并跳转到一个特定的系统调用处理函数,通过该函数执行需要的操作。一般来说,系统调用是由操作系统提供的接口,用于实现进程管理、文件管理、网络通信等功能。
\(MFC0\ \$rt, \$rd\):
用于将协处理器0(CP0)的寄存器 r d 的值传送到通用寄存器rt中。CP0是MIPS体系结构中的一个特殊寄存器集合,用于实现对异常处理、中断控制、虚拟内存等方面的支持。
\(MTC0\ \$rt, \$rd\):
用于将通用寄存器 r t 的值传送到协处理器 0 ( C P 0 )的寄存器rd中。通常,使用MTC0指令来配置CP0寄存器的值,例如配置异常处理向量表的基地址等。
5.浮点指令
MIPS指令集还提供了一组用于执行浮点运算的指令,这些指令用于对单精度浮点数和双精度浮点数执行基本算术和逻辑运算。以下是一些常用的浮点指令:
\(ADD.S\ \$fd, \$fs, \$ft\):
将单精度浮点寄存器 fs和ft的值相加,将结果存储到单精度浮点寄存器 f d 中。
\(SUB.S\ \$fd, \$fs, \$ft\):
将单精度浮点寄存器 fs和ft的值相减,将结果存储到单精度浮点寄存器 f d 中。
\(MUL.S\ \$fd, \$fs, \$ft\):
将单精度浮点寄存器 fs和ft的值相乘,将结果存储到单精度浮点寄存器 f d 中。
\(DIV.S\ \$fd, \$fs, \$ft\):
将单精度浮点寄存器 f s 的值除以ft的值,将结果存储到单精度浮点寄存器 f d 中。
操作数的载体
寄存器、内存、IO设备
寄存器:直接采用索引
内存:各种寻址模式
- 立即数寻址:操作数为指令自身中的立即数
- 直接寻址:操作数的地址在指令中
- 间接寻址:操作数的地址的地址在指令中(指向的是存储操作数地址所在内存的地址,需要访存两次才能取到)
- 寄存器寻址:操作数为寄存器中的值
- 寄存器相对寻址:以基址寄存器中的值和立即数常数之和作为地址,该地址指向的内存的值作为操作数
- PC相对寻址:以PC程序计数器和指令中常数之和作为地址,即16位地址左移2位(即乘以4)与PC计数器相加
- 偏移寻址:将基址寄存器(BR)的值加上操作数中的地址,形成操作数的有效地址
- 变址寻址:将变址寄存器(IX)的值加上操作数中的地址,形成操作数的有效地址。变址寄存器的内容可由用户改变。
指令编码/寄存器数量/操作码的数量对程序大小和性能的影响
可能导致性能提升,也可能导致性能下降。
时间(性能):
- 寄存器、操作码数量增多时,导致指令长度变长,进而取址时间变长。
- 寄存器数量变多,寄存器溢出的概率降低,从内存取数的时间变少。
大小:
- 增加每个位字段的大小可能会使每个指令更长,从而可能增加整体代码大小。
- 然而,增加寄存器的数量可能会导致更少的寄存器溢出,这将减少指令的总数,可能会减少整体代码大小。
CPU
- 单周期CPU的特点、数据通路
- 多周期CPU的特点、数据通路
- 流水线
- 冒险与解决
- 循环展开
单周期CPU
单周期的CPI=1,性能是最高吗?
不是,因为时钟周期取决于执行时间最久的那条指令(一般就是取数指令),导致时间周期很长。
数据通路
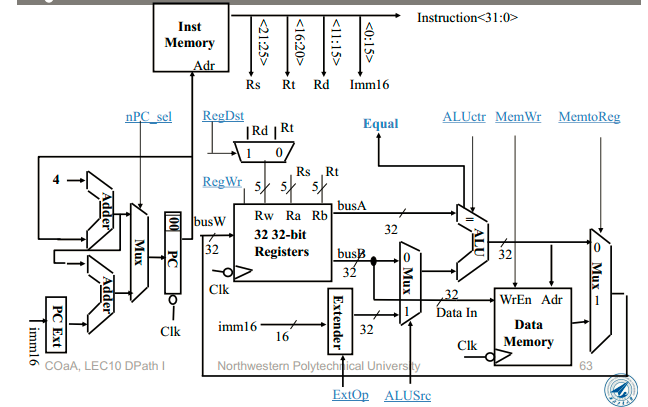
特点
- CPI = 1
- 以指令为单位,对于每条指令而言,都需要耗费 1 个时钟周期
- 在物理设计上,cycle time 必须统一标准,因此 cycle time 一般取决于耗时最长的指令 lw(lw需要干的事情最多),当指令中只有少数 lw 指令时,就会产生时间上的浪费
- 单位指令执行时间 = 1 * T(T 为耗时最长指令的 cycle time)
多周期CPU
在单周期CPU的基础上,在功能部件之间加入寄存器,将一个周期的任务,分成多个周期来做。
多周期CPU的频率提升,但CPI也增大了。
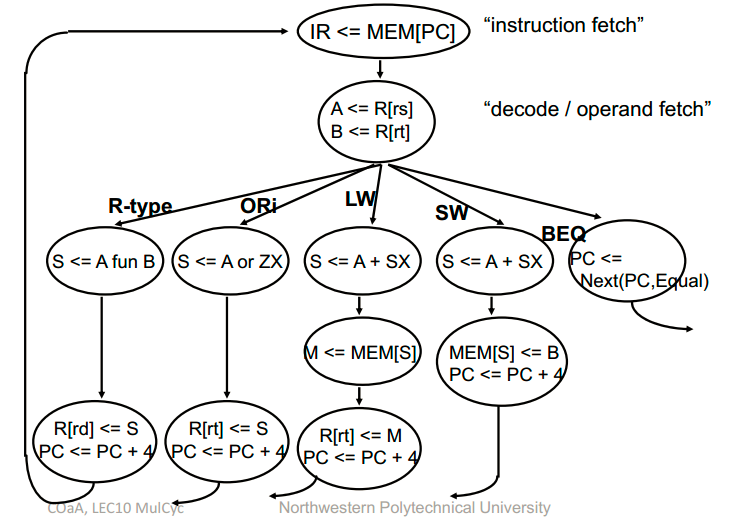

单周期处理器的缺点:除了加载指令外,所有指令的周期时间都太长
多周期处理器:将指令分成更小的步骤,在一个周期内执行每个步骤(而不是整个指令)
将数据路径划分为大小相等的块以最大限度地减少周期时间
遵循相同的5步方法来设计“真实的”处理器
- 提出划分阶段的思想,将每一条指令拆分为 5 个阶段:IF(Instruction Fetch,指令获取),ID(Instruction Decode,指令解码),EX(Execution,指令执行),MEM(Memory Access,内存读写)和 WB(Write Back to Register,写回寄存器)
- CPI 一般为 N( N 代表阶段数目,一般情况下 N = 5 )
- 依然以指令为单位,只不过一条指令被分为更细的几个阶段来执行,这样可以减少阶段数不同引起的单位指令执行时间的误差。例如 lw 指令需要经历全部的 5 个阶段,但是 sw 指令则只需要经历 4 个阶段(没有 WB),因此当一定数量的等量 lw 和 sw 指令连续出现的时候,平均阶段数会趋近于 4.5,而在单周期处理器中则是 5(为了考虑 lw),很明显后者的误差会更大一些
- cycle time 取决于耗时最长的阶段(一般是 MEM)
- 单位指令执行时间 = N * ( T / N )(取平均值,CPI * 平均 cycle time,平均 cycle time 近似为总时长的 1/N)
流水线CPU
单周期与多周期间的取长补短,主频趋近于多周期CPU,但CPI又趋近于1。
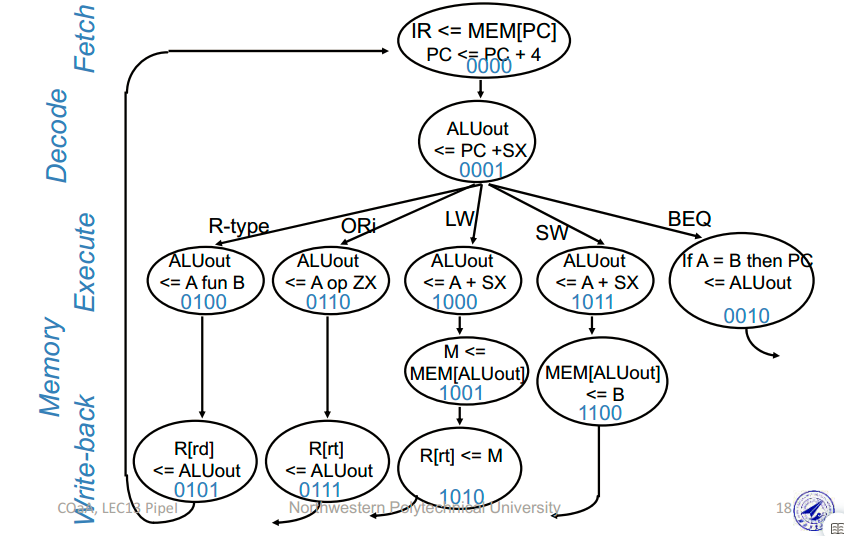

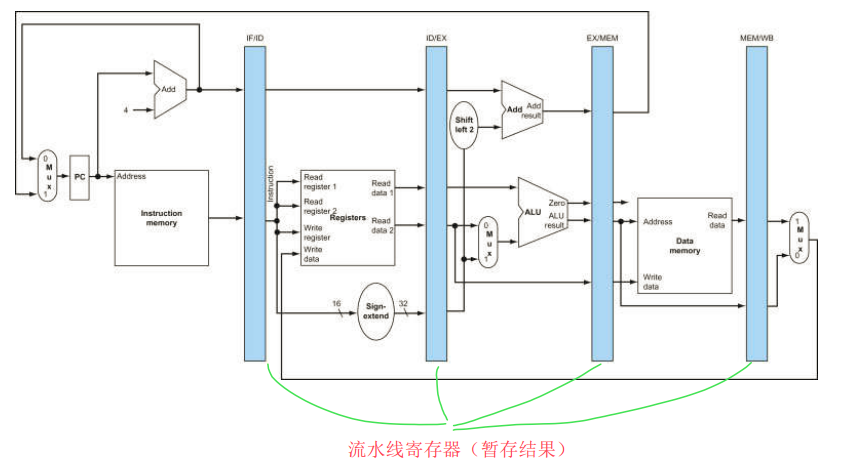

- 在多周期处理器的基础上进一步优化
- 平均 CPI 为 1(当指令数量很大 > 10000 时,最开始 4 个 cycle 的指令填充和 最后 4 个 cycle 的指令排空可以忽略不计,可以近似认为执行 m 条指令消耗 m( m >> 8 )个时钟周期,因此平均 CPI = 1)
- 不再以指令为单位。与多周期不同,流水线以每个阶段为单位,一个阶段内可能有多条指令在同时执行(并行)。例如当一条指令在 EX 阶段时,它的上一条指令可能在 MEM 阶段,而下一条指令可能在 ID 阶段,理论上它们是同时执行的
- cycle time 取决于耗时最长的阶段(一般是 MEM)
- 单位指令执行时间 = 1 * ( T / N )
- 可能存在三类冒险问题:结构冒险( Structural Hazard )、数据冒险( Data Hazard )以及控制冒险( Control Hazard )
冒险与解决
三种冒险产生的原因及如何解决。
结构冒险:试图同时以两种不同的方式使用同一资源
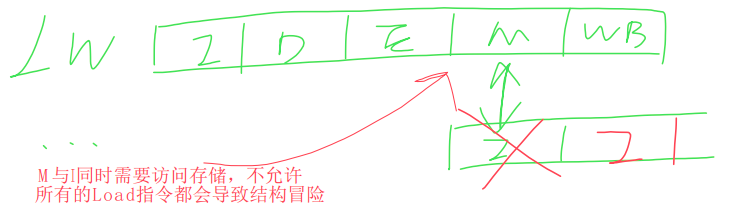
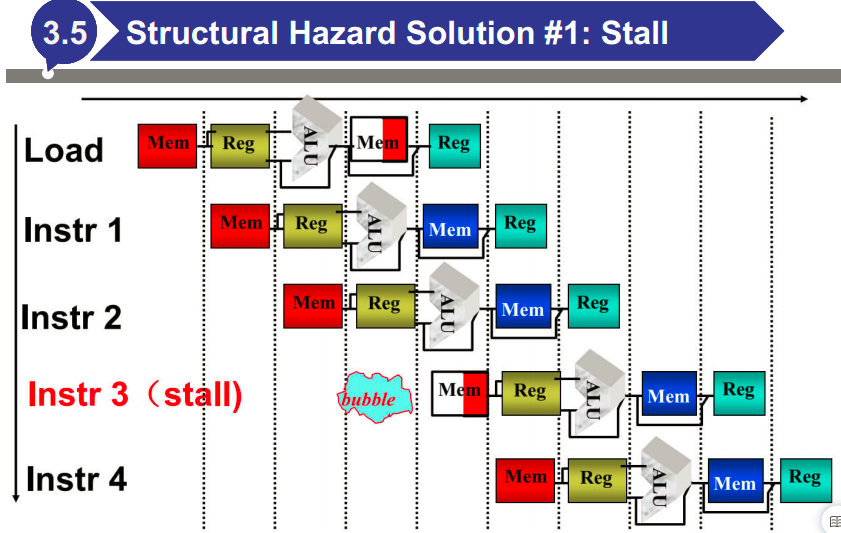
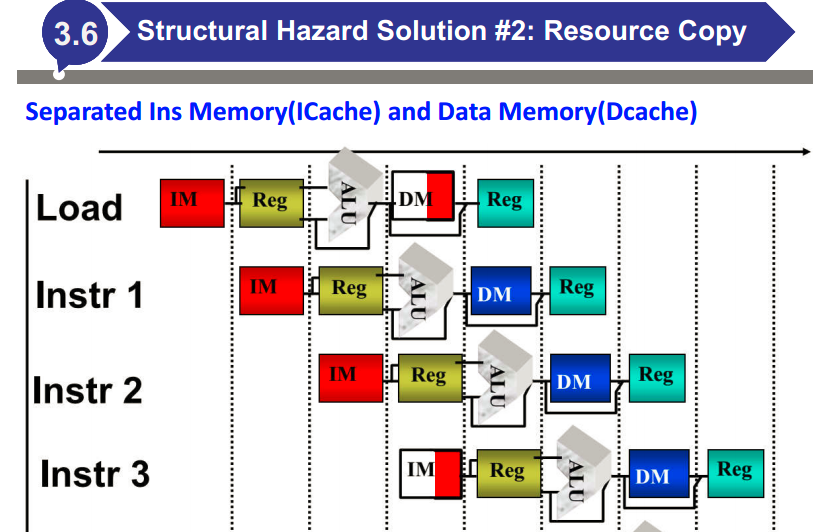
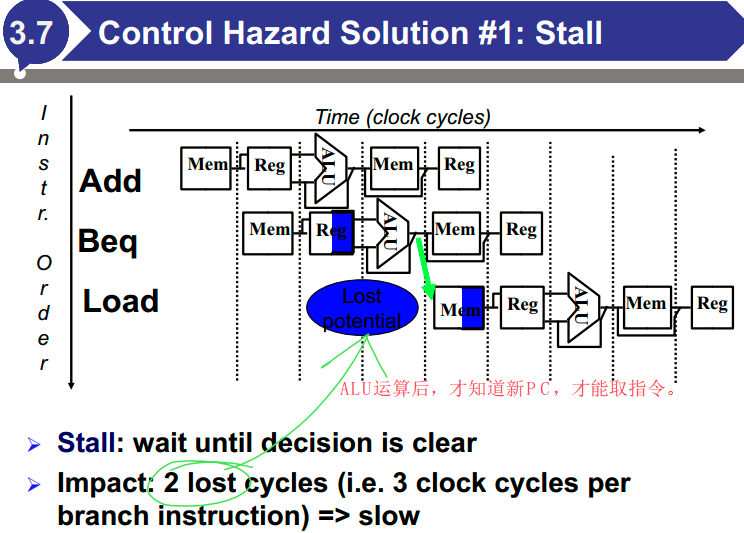
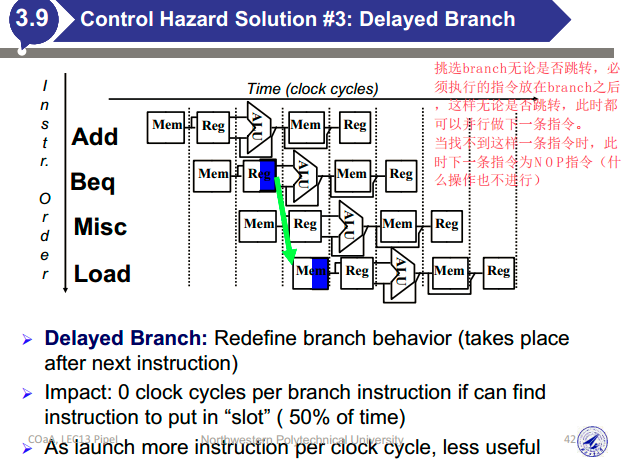
控制冒险:在评估条件之前尝试做出决定

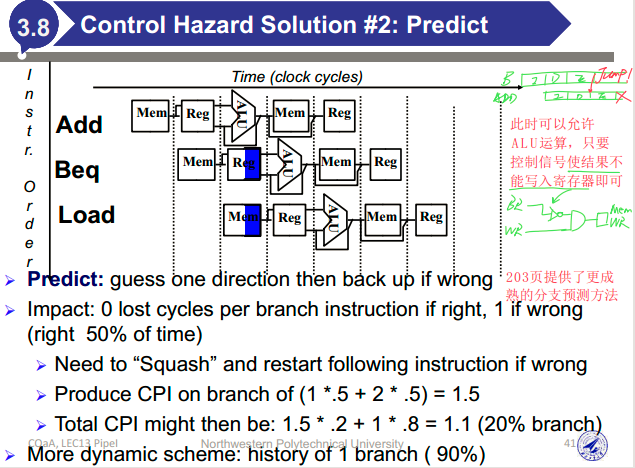
更成熟的分支预测方法:根据每个分支指令的行为进行预测,并在程序生命周期内可能改变分支预测的结果。例如,保存每个条件分支是否发生分支的历史记录,根据过去的行为来预测未来。
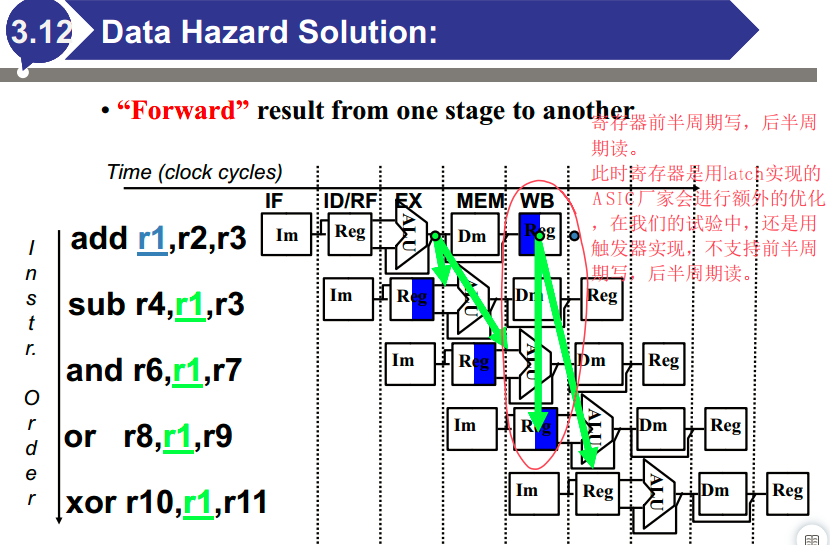
数据冒险:在项目准备就绪之前尝试使用项目

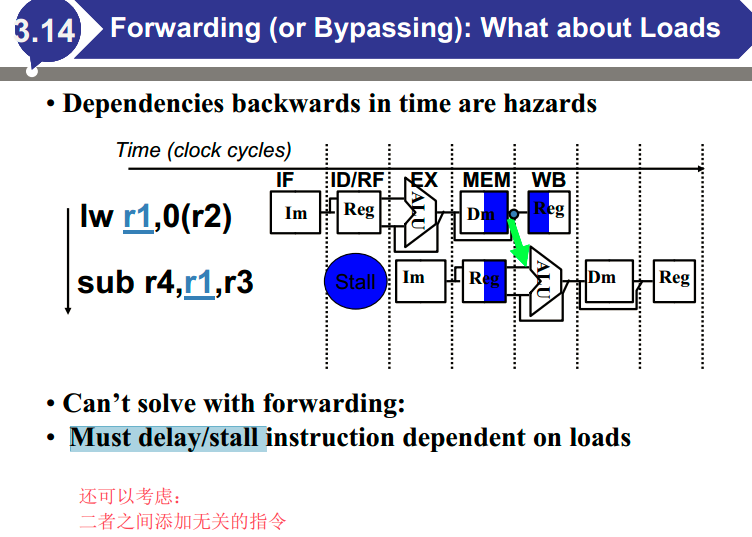
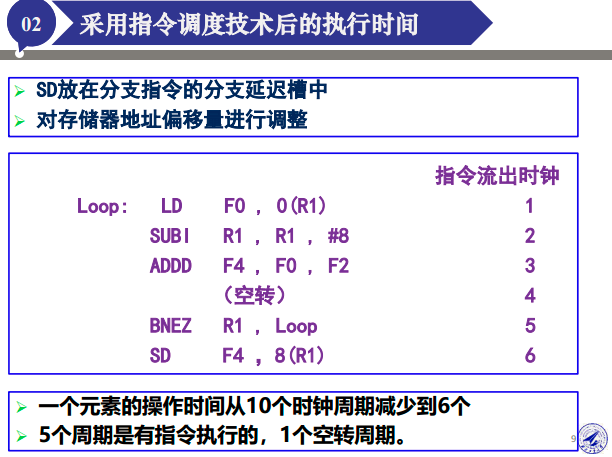
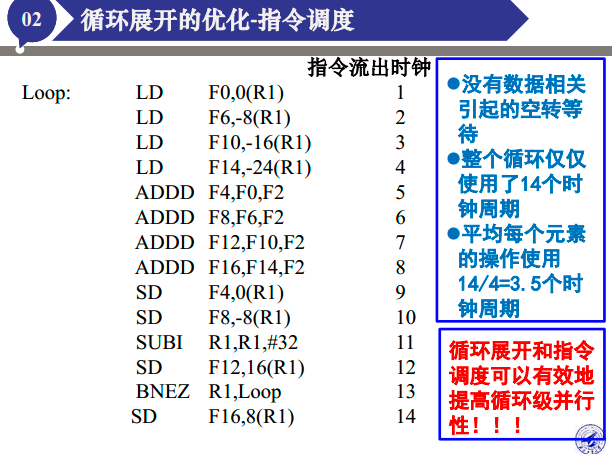
循环展开的例子
掌握思想。





内存
- 概念题
- SRAM的结构、工作原理
- DRAM的结构、工作原理
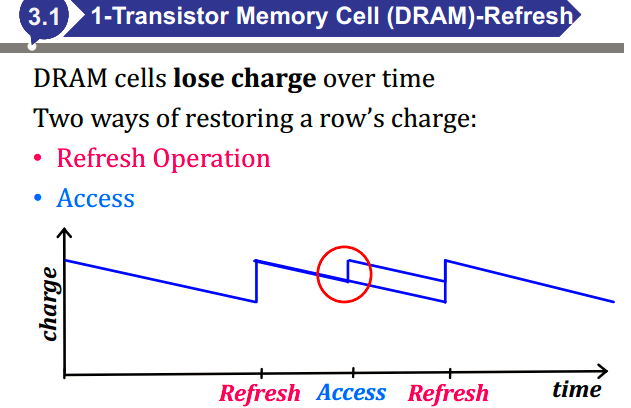
- DRAM为什么要刷新(晶体管很难关断,导致电荷会释放)
- DRAM怎么刷新(进行一次假读)
- DRAM刷新时间的计算
- cache
- 为什么用cache(内存与CPU间的速度差异越来越大)
- 为什么能引入cache(数据和指令在空间、时间上的局部性)
- 平均访存延迟(AMAT)的计算
- 计算公式:\(T=高一级访存延迟+miss\_rate\times下一级访存延迟\)
- 多级如何计算:从外向内算
- cache相连方式及其优缺点
- 全相联映射结构、特征、查找方法(地址index中的一部分查索引表,高位部分与cache相比较,比较前要看valid位)
- 直接映射结构、特征、查找方法
- 组相连映射结构、特征、查找方法
- cache命中率的计算
- I-cache、D-cache分开计算(刚开始的命中率往往是0,增加相连度可以增加命中率)
- cache写策略
- 写回(write back)的优缺点
- 写直达(write through)的优缺点
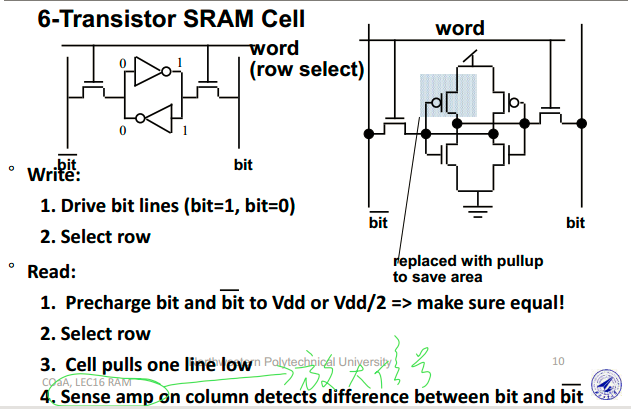
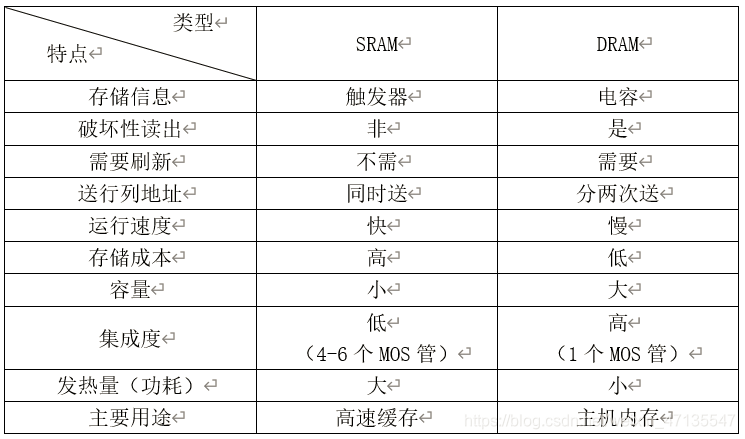
SRAM
SRAM的结构、工作原理
DRAM
DRAM的结构、工作原理
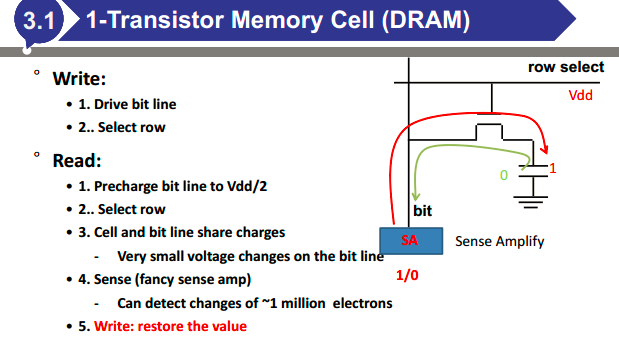
DRAM刷新
DRAM为什么要刷新(晶体管很难关断,导致电荷会释放)
DRAM怎么刷新(进行一次假读)
DRAM刷新时间的计算
DRAM容量1Gb,分为4个Bank,每行大小1KB,每行刷新需要50ns,JEDEC要求每64ms刷新一遍所有DRAM单元,请问刷新占用的时间比例是多少?
JEDEC:Joint Electron Device Engineering Council. http://www.jedec.org 固态技术学会
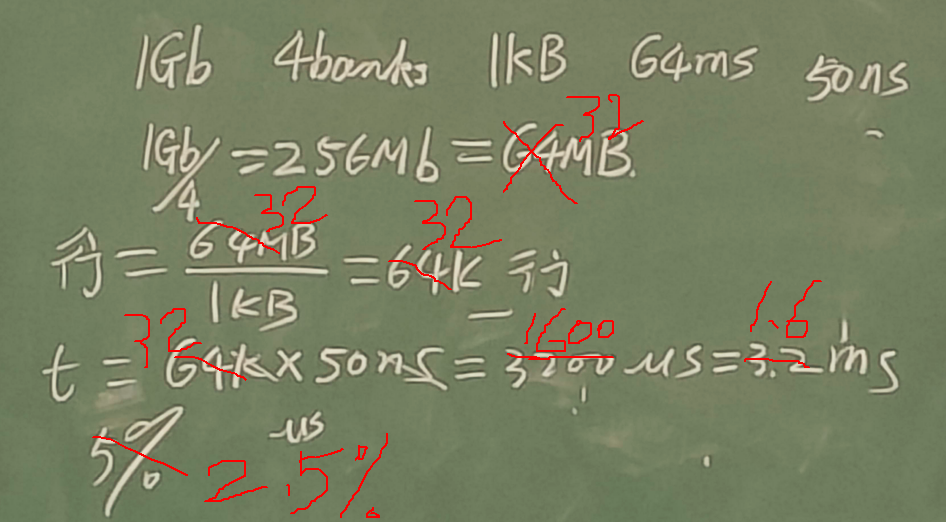
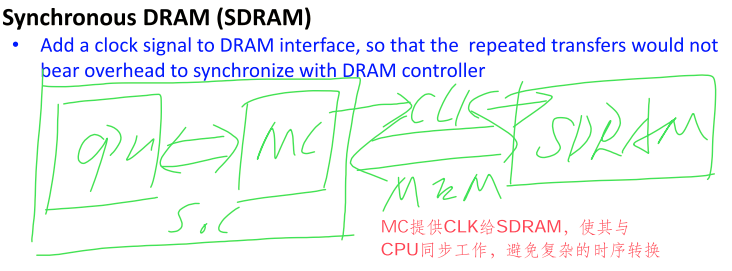
SDRAM
千万注意这是DRAM,跟SRAM没半毛钱关系。
SRAM vs DRAM
cache
- 为什么用cache(内存与CPU间的速度差异越来越大)
- 为什么能引入cache(数据和指令在空间、时间上的局部性)
- 平均访存延迟(AMAT)的计算
- 计算公式:\(T=高一级访存延迟+miss\_rate\times下一级访存延迟\)
- 多级如何计算:从外向内算
- cache相连方式及其优缺点
- 全相联映射结构、特征、查找方法(地址index中的一部分查索引表,高位部分与cache相比较,比较前要看valid位)
- 直接映射结构、特征、查找方法
- 组相连映射结构、特征、查找方法
- cache命中率的计算
- I-cache、D-cache分开计算(刚开始的命中率往往是0,增加相连度可以增加命中率)
- cache写策略
- 写回(write back)的优缺点
- 写直达(write through)的优缺点
Why cache

内存与CPU间的速度差异越来越大


内存中,越大、越快的存储越贵,难以满足要求
Why can use cache
数据和指令在空间、时间上的局部性:


时间局部性:如果你刚刚做了某件事,很可能很快你会再次做同样的事情。
一个程序倾向于多次引用同一个内存位置,并且都是在一个很小的时间窗口内
(最近访问的数据将在不久的将来再次访问)

想法:将最近访问的数据存储在自动管理的快速内存(称为缓存)中
预测:数据将很快再次访问
空间局部性:如果你做了某事,很可能你会做类似/相关的事情(在空间中)
程序倾向于一次引用一组内存位置
(内存中的附近数据将在不久的将来被访问)

想法:在自动管理的快速内存中存储与最近访问的地址相邻的地址
预期:附近的数据将很快被访问
平均访存延迟(AMAT)的计算
平均访存延迟(AMAT)的计算
- 计算公式:\(T=高一级访存延迟+miss\_rate\times下一级访存延迟\)
- 多级如何计算:从外向内算
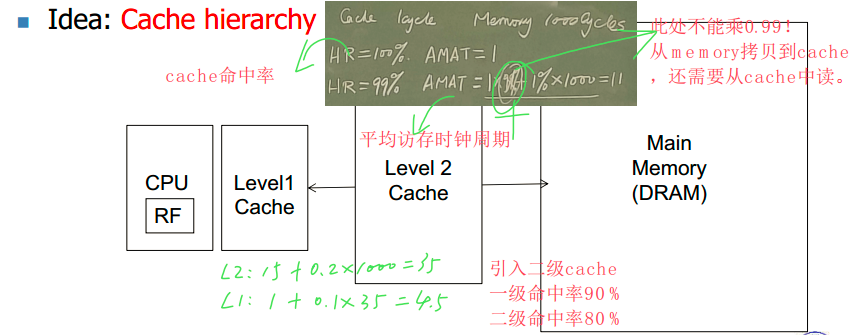
例如,当计算机有两级cache时,L1 cache命中率90%,L2 cache命中率80%,L1、L2、memory访存时间分别为1、15、1000,计算平均访存延迟。
多级如何计算:从外向内算

cache相连方式
- 全相联映射结构、特征、查找方法(地址index中的一部分查索引表,高位部分与cache相比较,比较前要看valid位)
- 直接映射结构、特征、查找方法
- 组相连映射结构、特征、查找方法

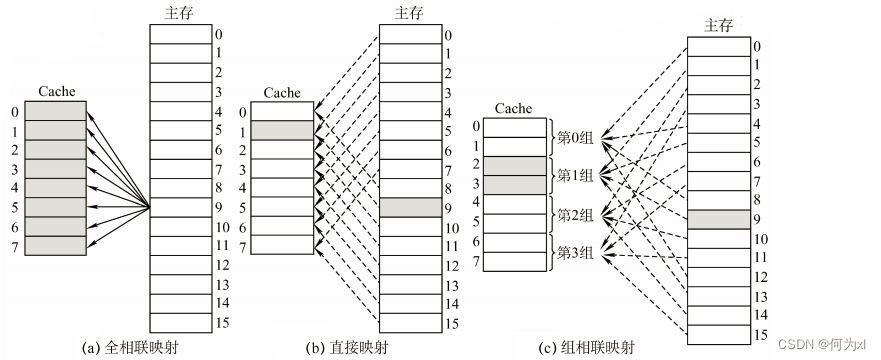
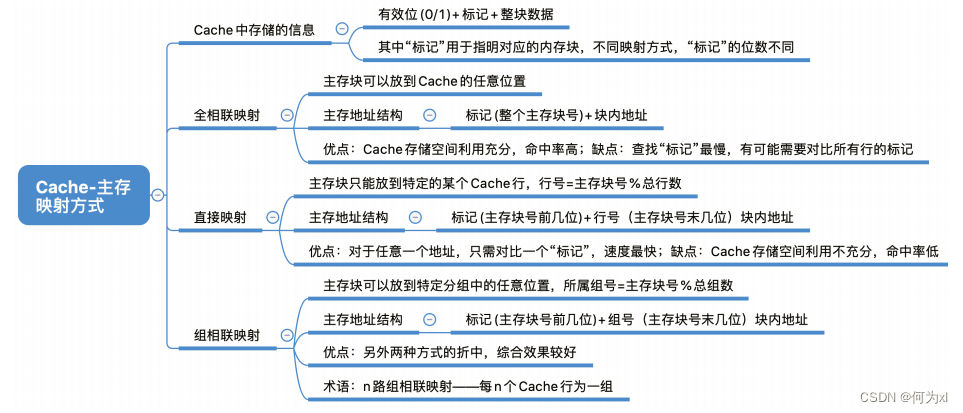
全相联映射:主存块可以放在 Cache 的任意位置。
直接映射:每个主存块只能放到一个特定的位置:
Cache块号 = 主存块号 % Cache总块数
组相联映射:Cache块分为若干组,每个主存块可放到特定分组中的任意一个位置: 组号 = 主存块号 % 分组数
全相联映射(随意放)

cache有n块,不分组(也就是分1个组),每组内有n个块,所以行号位数(此时可以理解成特殊的组号)就是\(log_21=0\)。
CPU 访问主存地址 1…1101001110:
①主存地址的前22位,对比Cache中所有块的标记;
②若标记匹配且有效位=1,则Cache命中,访问块内地址为 001110 的单元。
③若未命中或有效位 = 0,则正常访问主存。
直接映射(只能放固定位置)
直接映射,主存块在Cache中的位置 = 主存块号 % Cache总块数。

当 Cache总块数 = \(2^n\),则主存块号末尾n位直接反映它在Cache 中的位置。将主存块号的其余位作为标记即可。
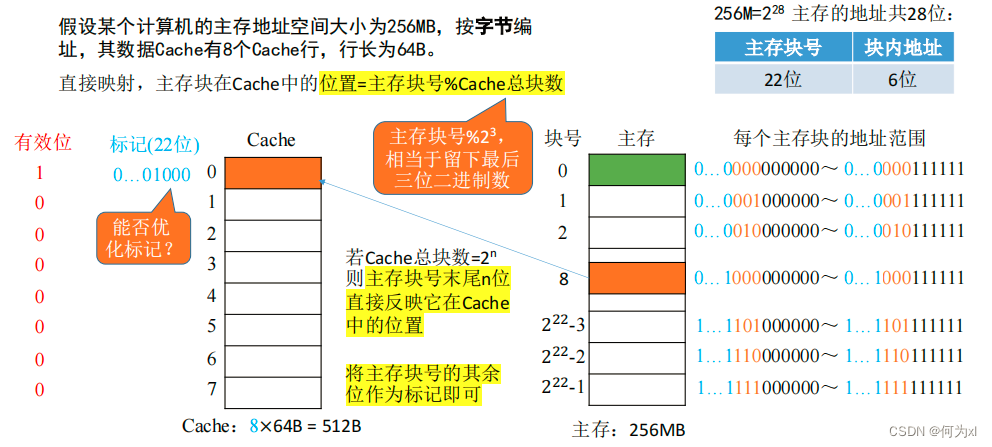
此时主存地址为:
cache有n块,每组内有1个块,那么就是\(n/1\)个组,所以行号位数(此时可以理解成特殊的组号)就是\(log_2n\)。
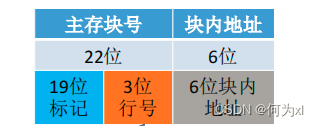
CPU 访问主存地址 0…01000 001110 :
①根据主存块号的后 3位确定Cache行 。
②若主存块号的前 19 位与Cache标记匹配且有效位=1,则Cache命中,访问块内地址为 001110 的单元。
③若未命中或有效位=0,则正常访问主存。
组相联映射(可放到特定分组)
n 路组相联映射 —— n块为一组
eg:2路组相联映射——2块为一组
组相联映射,所属分组 = 主存块号 % 分组数
cache有n块,每组内有m个块,那么就是\(n/m\)个组,所以组号位数就是\(log_2\frac{n}{m}\)。
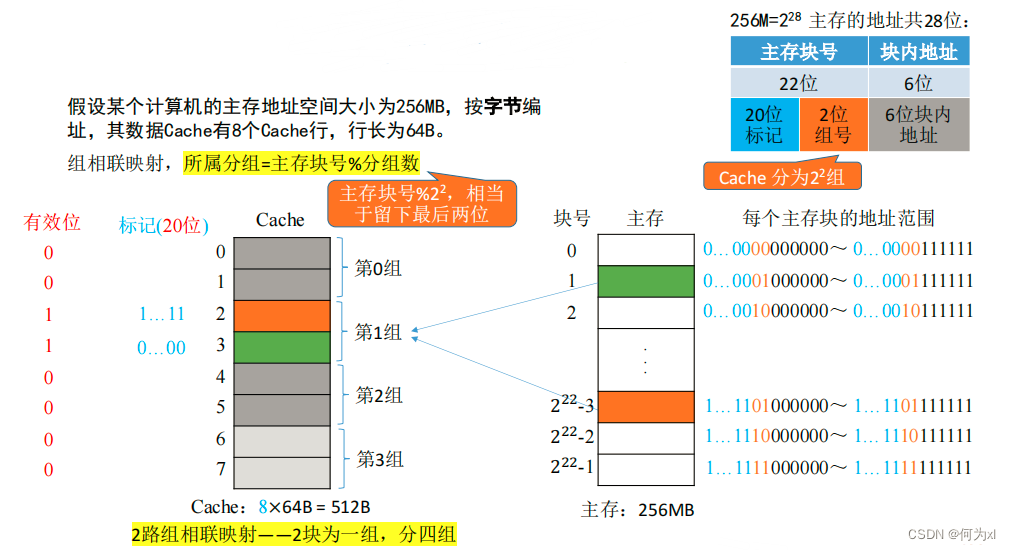
CPU 访问主存地址1…1101001110 :
①根据主存块号的后 2位确定所属分组号。
②若主存块号的前20位与分组内的某个标记匹配且有位=1, 则Cache命中,访问块内地址为 001110的单元。
③若未命中或有效位=0,则正常访问主存。
Cache - 主存的映射方式总结

关联度:有多少块可以映射到同一个索引(或集合)?
更高的关联性会带来:
- ++更高的命中率
- --更慢的缓存访问时间(命中延迟和数据访问延迟)
- --更昂贵的硬件(更多的比较器)
更高的关联性带来的回报越来越少
对于一级cache,采用小相连【快】
eg.直接映射或2组相连
二级三级cache,采用大相连【高命中】
eg.最大32组相连
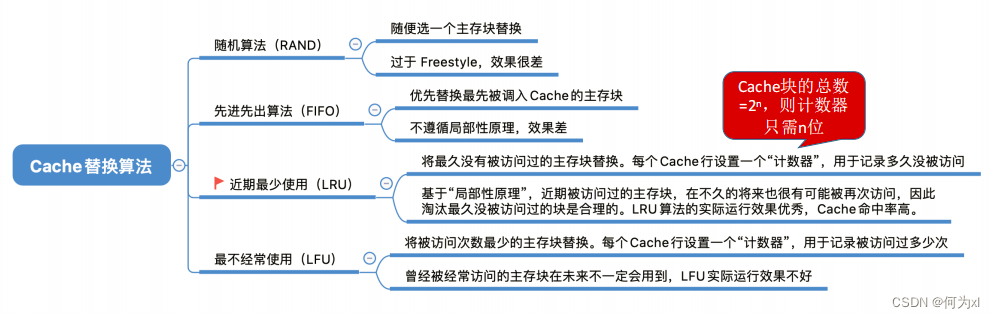
cache替换策略
cache写策略
当写操作命中cache时

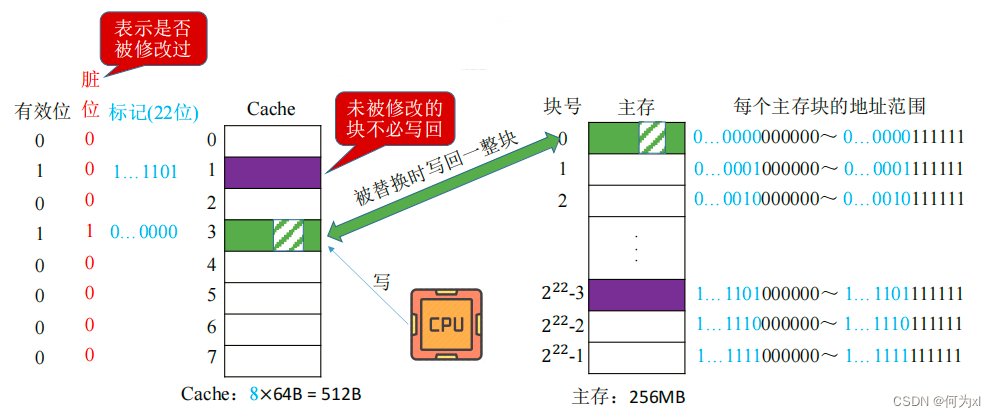
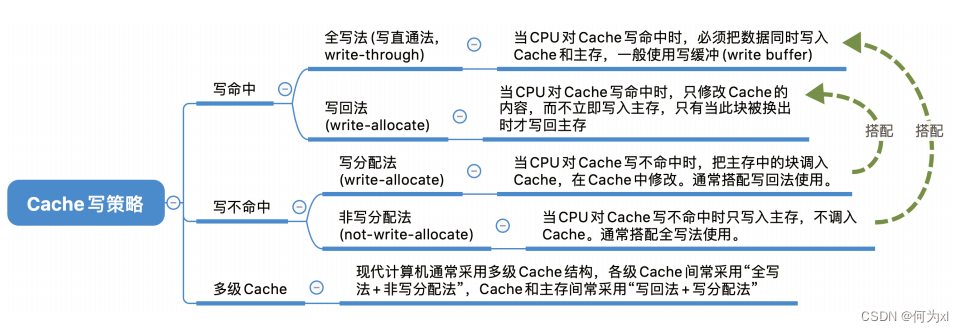
- 写回法(write-back)
写回法(write-back) —— 当CPU对Cache写命中时,只修改Cache的内容,而不立即写入主存,只有当此块被换出时才写回主存。
减少了访存次数,但存在数据不一致的隐患。
- 写直通法,write-through
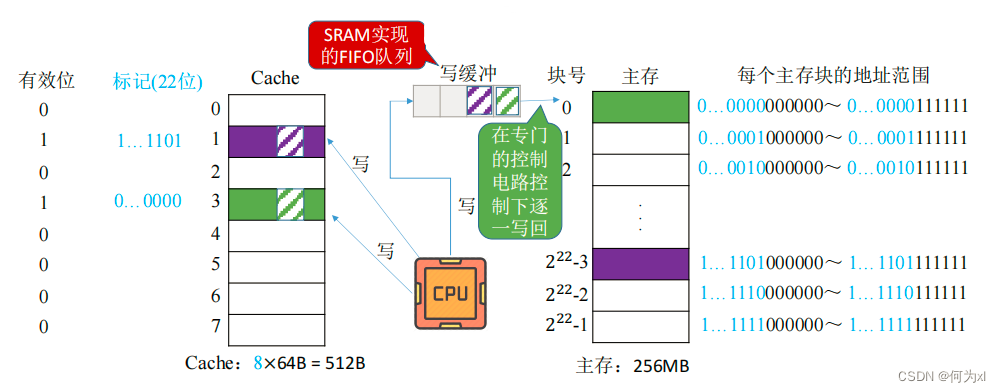
全写法(写直通法,write-through) —— 当CPU对Cache写命中时,必须把数据同时写入 Cache 和主存,一般使用写缓冲(write buffer)。使用写缓冲,CPU写的速度很快,若写操作不频繁,则效果很好。若写操作很频繁,可能会因为写缓冲饱和而发生阻塞。
访存次数增加,速度变慢,但更能保证数据一致性。Cache块被替换时无需写回。
当写操作未命中cache时
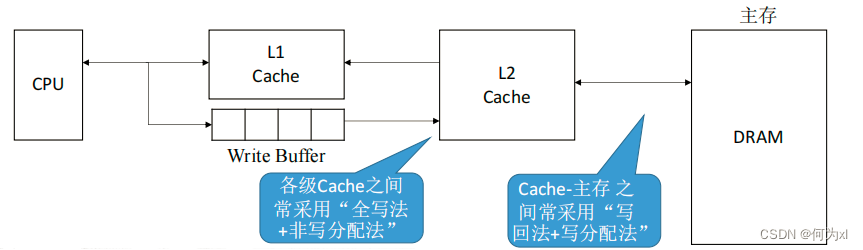
- 写分配法
写不命中时,把主存中的块调入Cache,在Cache中修改。
搭配写回法使用。
写回法(write-back) —— 当CPU对Cache写命中时,只修改Cache 的内容,而不立即写入主存,只有当此块被换出时才写回主存。
+ 可以合并写入,而不是将每个写入单独写入下一级
+更简单,因为写入未命中可以与读取未命中相同的方式处理
-需要(?)传输整个缓存块
- 非写分配法
非写分配法(not-write-allocate)——当 CPU 对 Cache 写不命中时只写入主存,不调入Cache。搭配全写法使用。
全写法(写直通法,write-through) —— 当 CPU 对 Cache 写命中时,必须把数据同时写入Cache 和主存,一般使用写缓冲(write buffer)。
+ 如果写入的空间局部性较低,则可节省缓存空间(可能提高缓存命中率)
cache命中率的计算
I-cache、D-cache分开计算(刚开始的命中率往往是0,增加相连度可以增加命中率)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号