虚拟内存
虚拟内存:进程和操作系统的中间层
虚拟内存,就是机器上运行的一个个的进程,访问的都是虚拟的内存,比如C语言中的指针指向的内存地址,或者gdb调试工具看到的地址,都是虚拟的,并不是机器上的实际物理内存,虚拟内存是相对于物理内存来说的,物理内存,简单来说DDR,是真正可以访问到的内存空间,比如8G DDR,那可用的物理内存就是8G
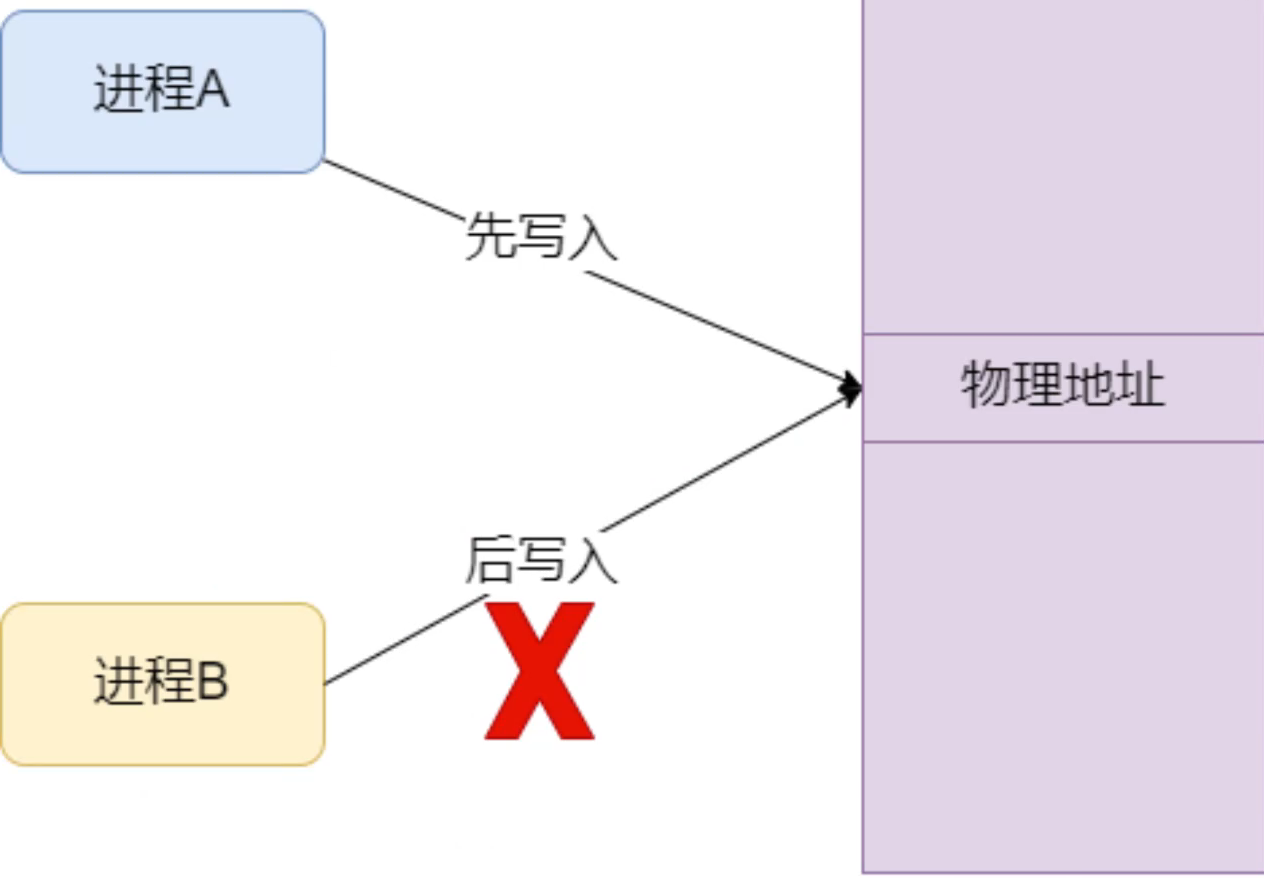
在一台计算机上,如果只有单个进程独享整个物理内存,也是可以的,但是只存在于baremetal上。现在的操作系统都是支持多进程并发运行的,当两个进程同时对同一块物理内存进行读写时,显然是有冲突的,如下图。此外,进程申请的内存可能还并没有使用,如果有太多的进程同时申请了大量的内存,也会导致物理内存空间不够用。
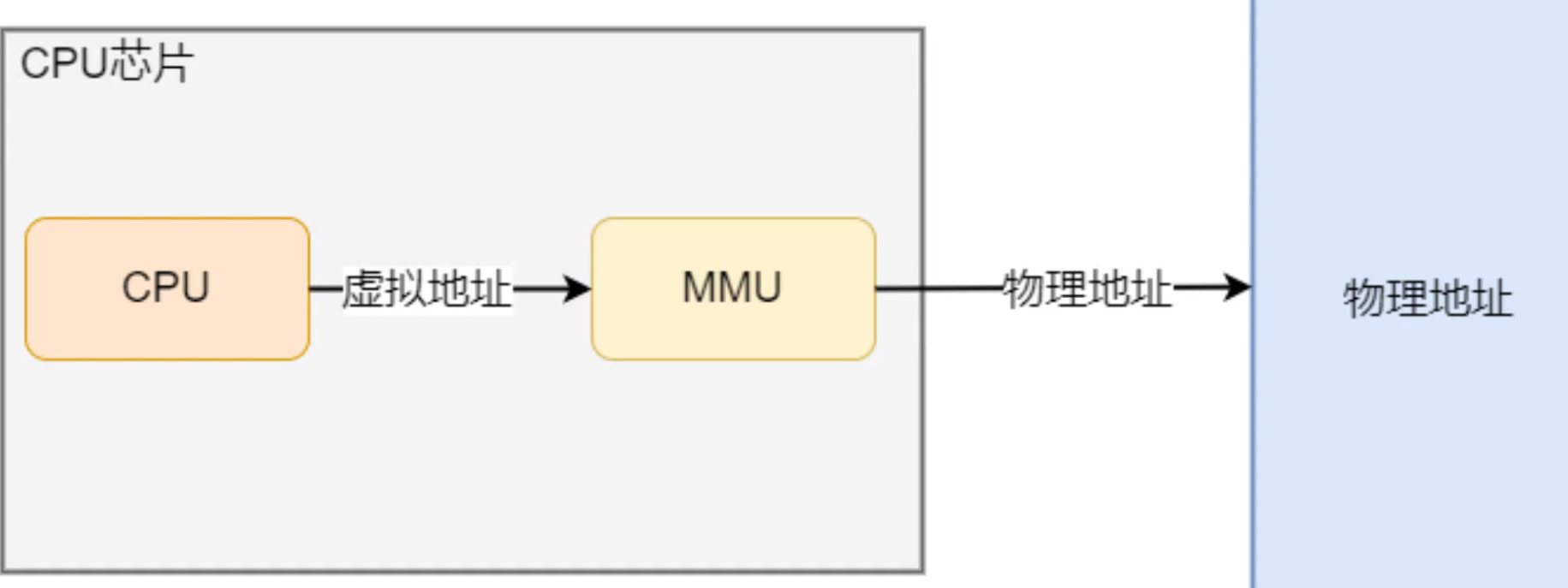
为了解决上面的问题,防止多进程运行时造成的内存地址的冲突,操作系统引入了虚拟内存,为每个进程都提供了一个独立的虚拟内存空间,使得进程认为自己独占全部的内存资源。引入虚拟内存之后,进程访问的虚拟内存地址通过CPU内部集成的内存管理单元MMU转换成物理地址,然后再通过物理地址访问内存,如下图:
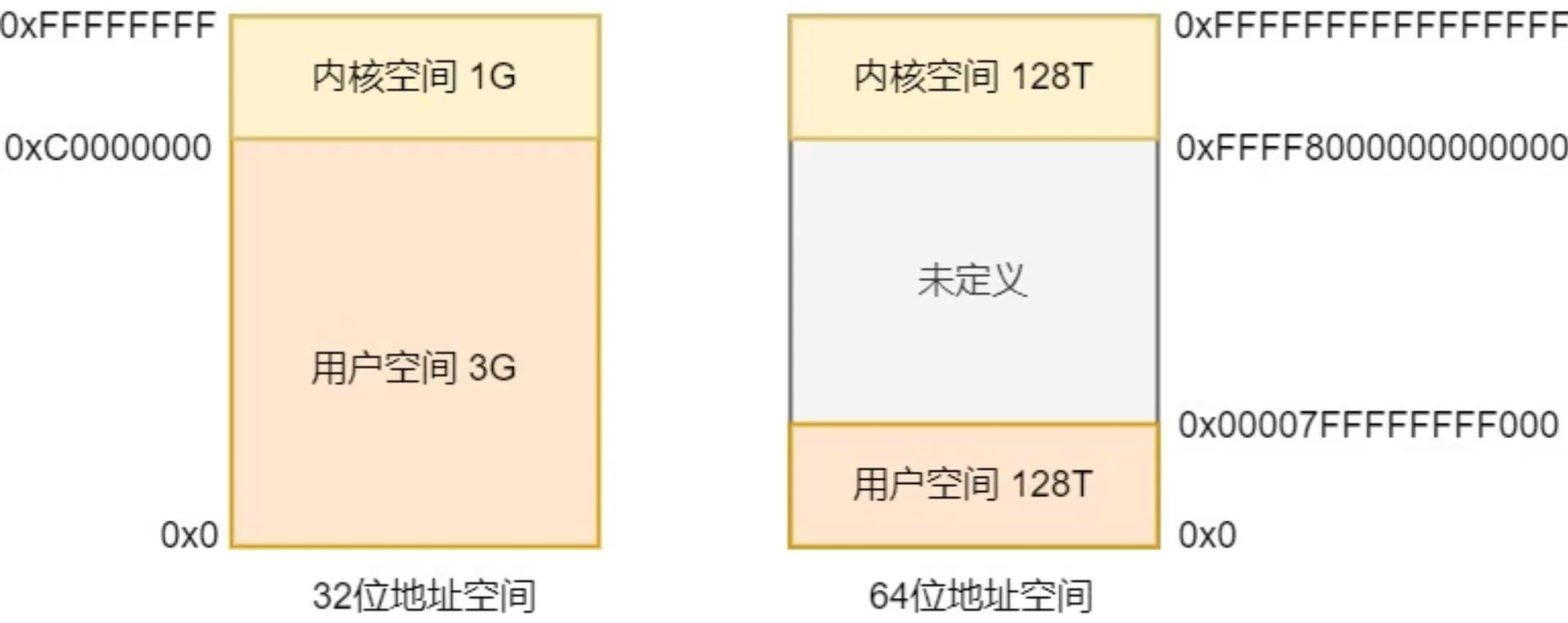
对于系统上运行的进程来说,在32位系统之上,可以拥有4GB虚拟内存空间(2^32 = 0xFFFFFFFF,也就是4G),在64位系统上,在可拥有256T虚拟内存空间
虽然每个进程的地址空间都包含了内核空间,但这些内核空间,其实都关联的是相同的物理内存
对于进程虚拟内存的用户空间,从低往高,又可以分为六个不同的内存段:
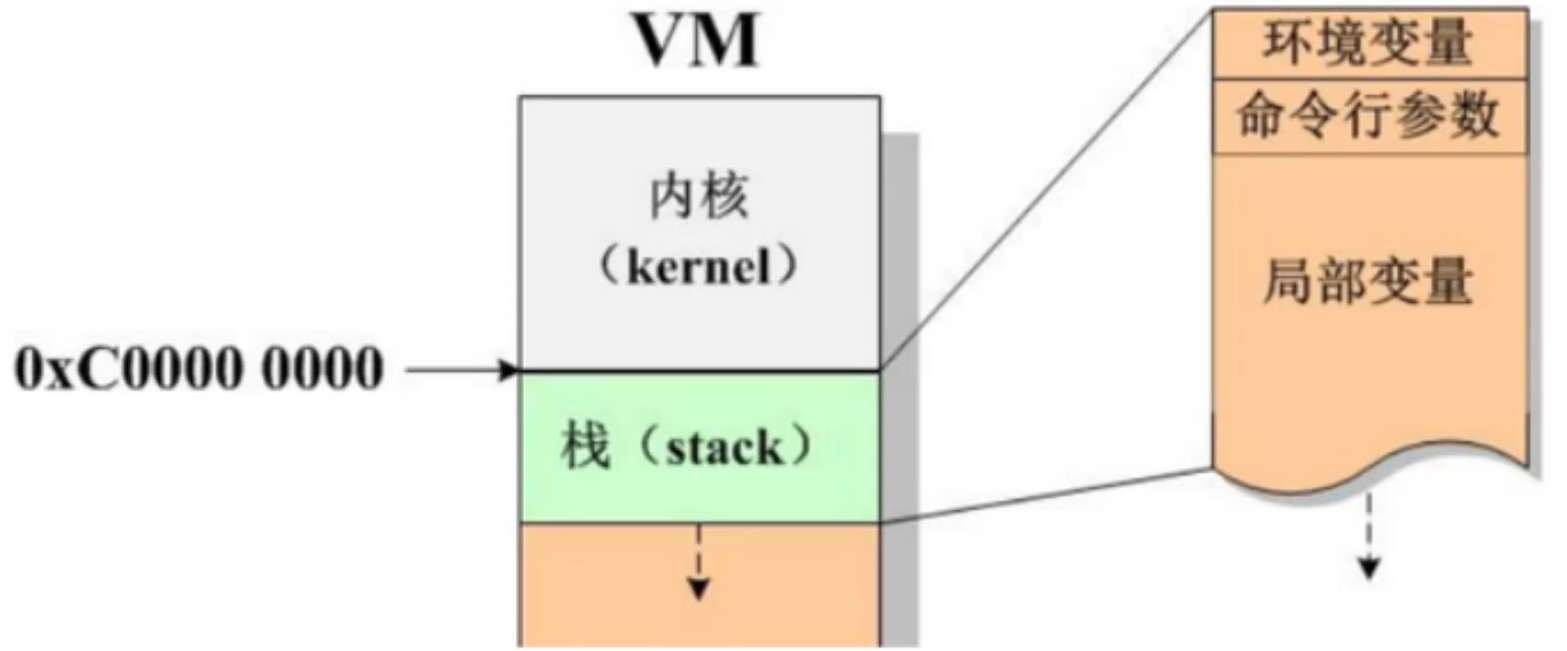
0xFFFFFFFF | 内核空间 0xC0000000 栈(向下增长,环境变量,命令行参数,局部变量) | 文件映射段(低地址向高地址增长) | 堆(向上增长,动态内存开辟是在堆上开辟的) .bss(数据段,包含.bss未初始化的静态数据,.data已初始化的静态数据,.rodata常量) .data .text(代码段,包含.text用户代码和.init系统初始化代码,程序运行时就已经确定) 不可访问段 0x00000000
文件映射段,主要包括共享内存,动态链接库等共享资源
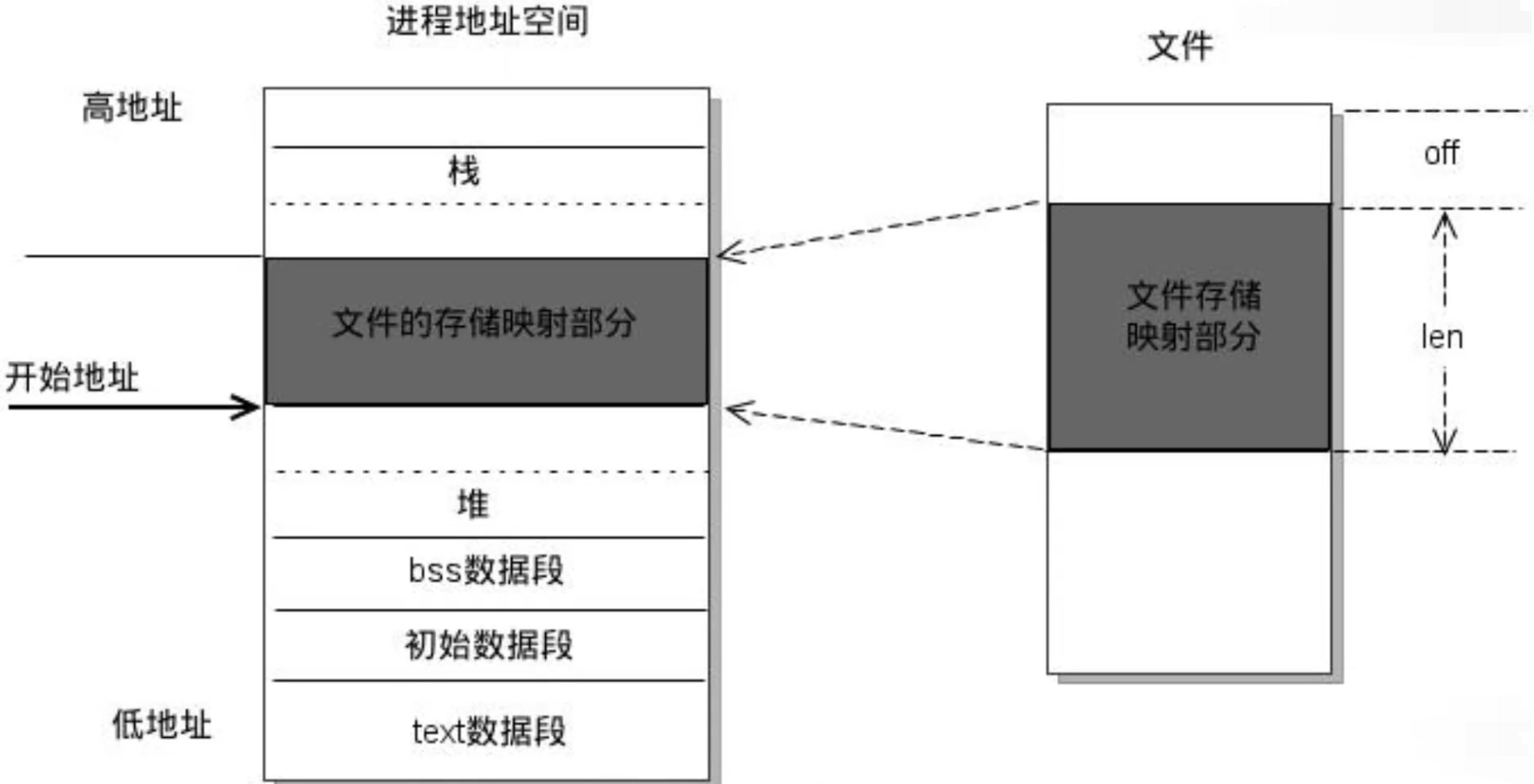
当每一个函数被调用时,就会将参数压入调用栈中,调用结束返回值也会被放回栈中,同时每调用一次函数就会创建一个新的栈,所以在递归较深时容易导致栈溢出,栈内存的申请和释放由编译器自动完成,栈容量由系统预先定义,栈从高地址向低地址增长。
堆和文件映射段的内存是动态分配的,比如说C标准库的malloc或者mmap,就可以分别在堆和文件映射段动态分配内存
由于每个进程都有这么大的地址空间,导致所有进程的虚拟内存加起来,自然要比实际物理内存大得多,所以并不是所有的虚拟内存都会分配物理内存,只有实际使用的虚拟内存才会分配物理内存
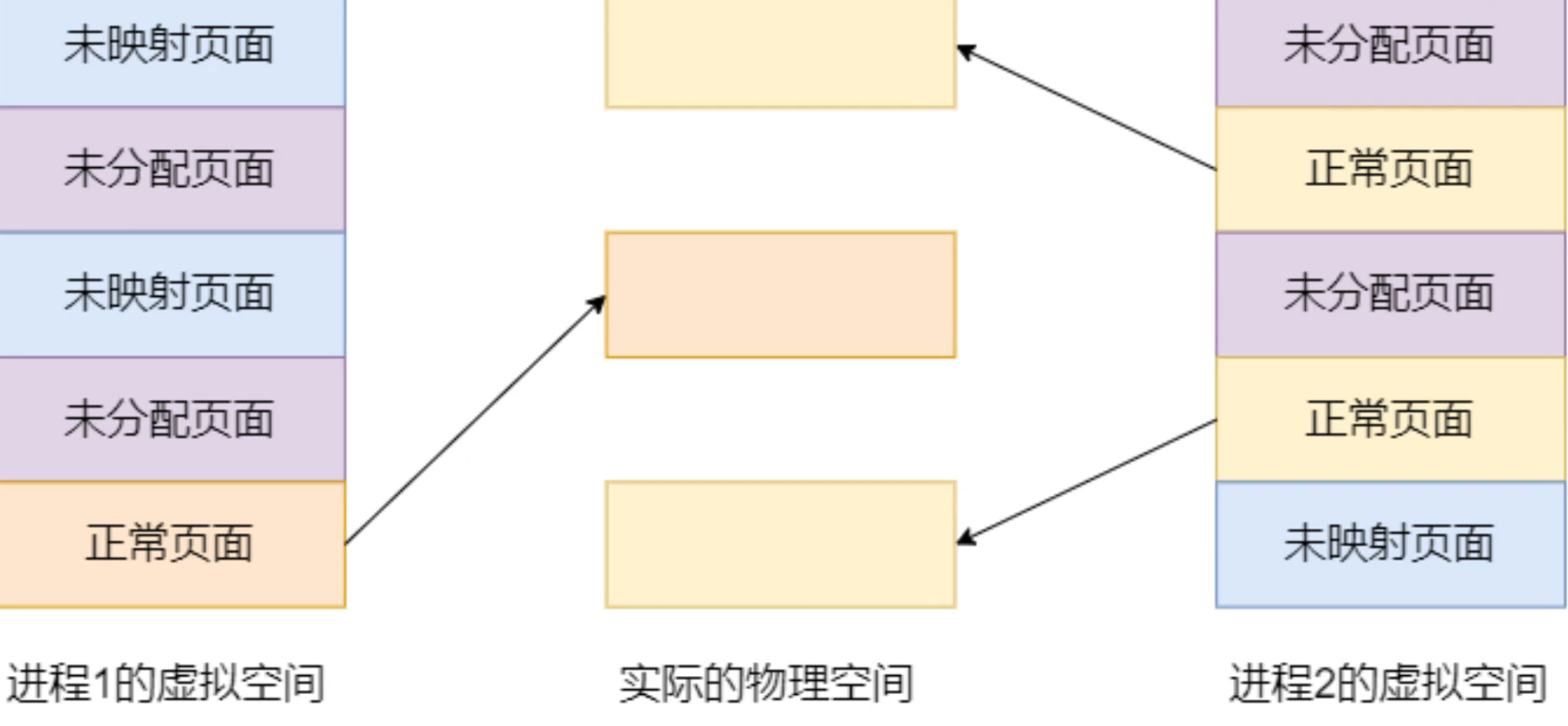
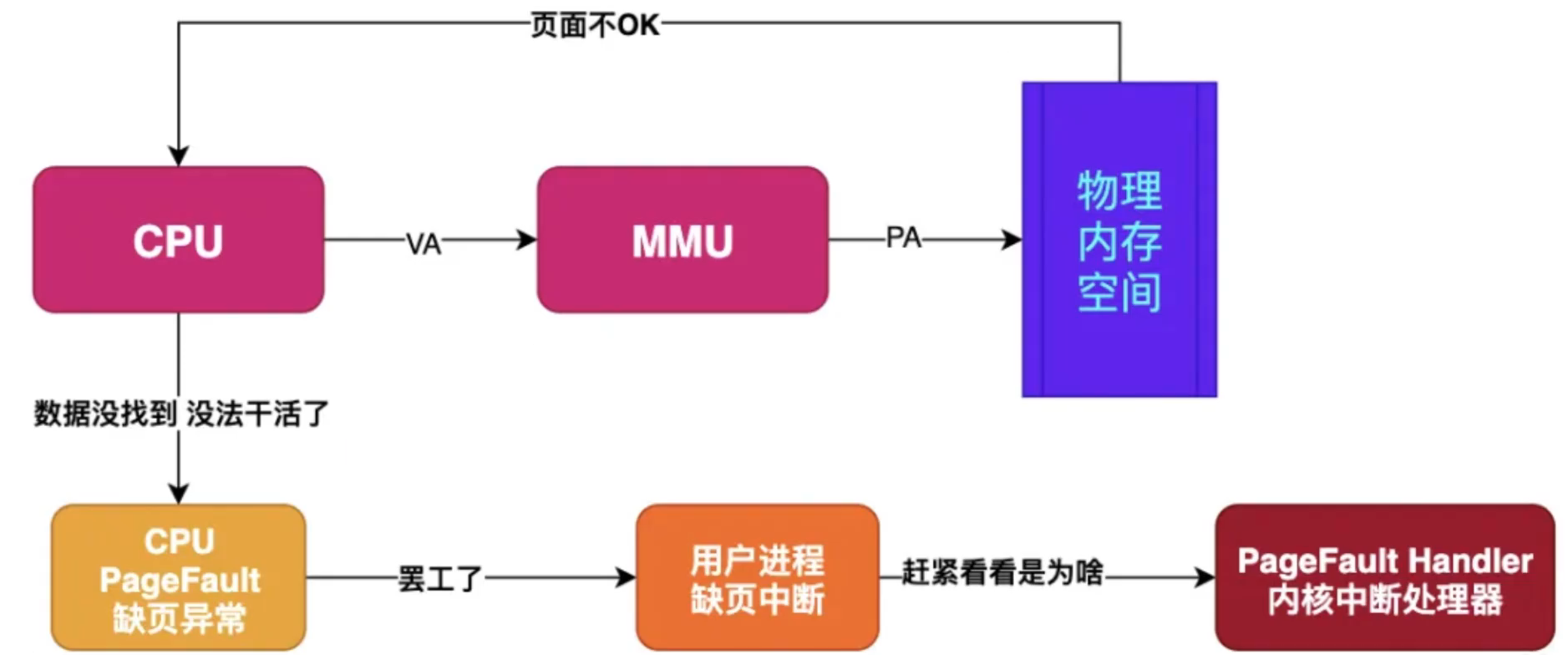
当进程对某块虚拟内存进行读写时,CPU就会去访问这块内存,这时如果发现这块虚拟内存没有映射到物理内存,CPU就会产生缺页中断,进程会从用户态切换到内存态,并将缺页中断交给内核的缺页中断函数进行处理,这时才会真正地为它分配物理内存
操作系统使用分段和分页地机制,管理虚拟地址与物理地址的映射关系。内存分段机制,简单理解就是根据程序申请使用内存的需要,来把物理内存分成一段一段内存来进行管理。比如程序需要100M的内存,分段机制就给1段100M连续空间的物理内存与之对应。内存分页将整个虚拟内存和物理内存空间分成一段段固定大小的片。虚拟内存与物理内存的映射,以这个片为最小单位进行管理,这个片就称为页。
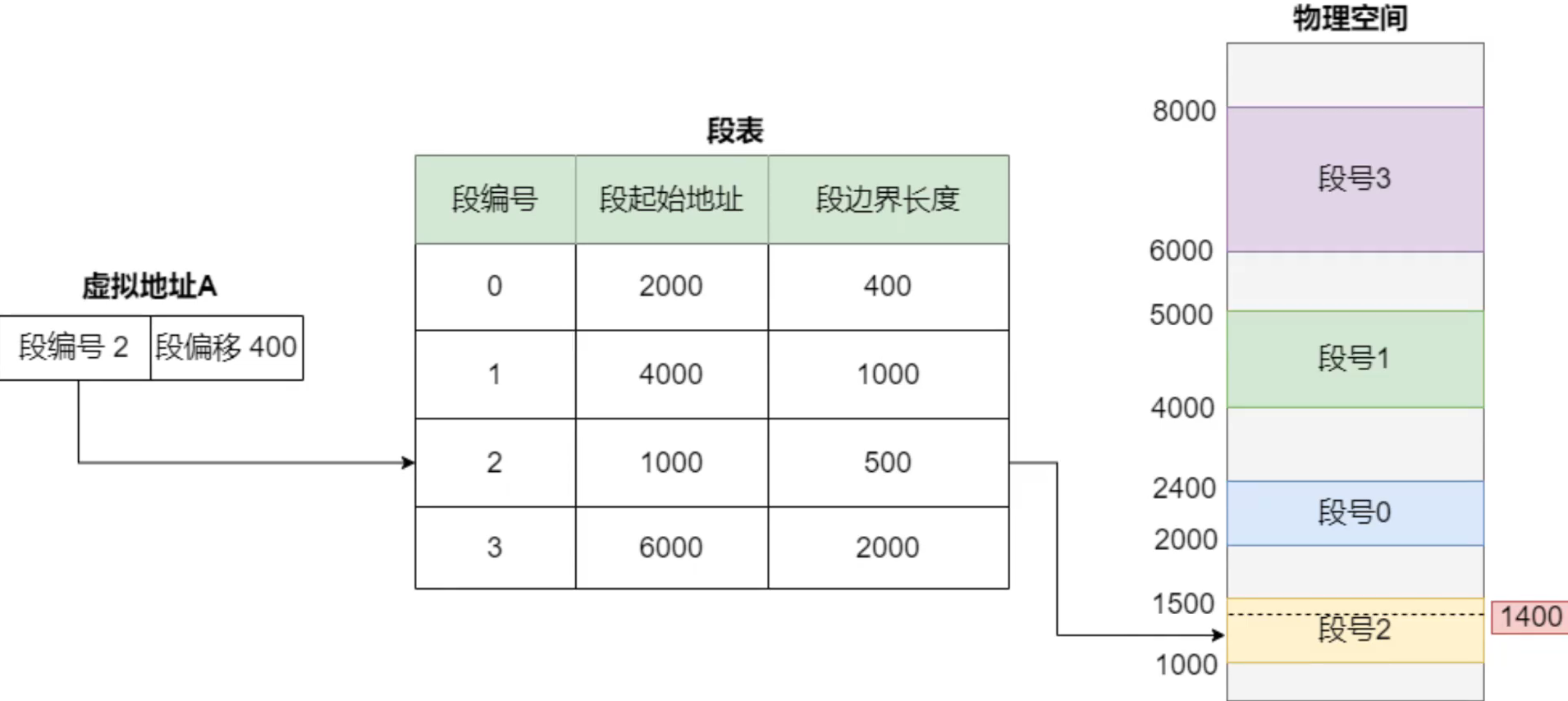
在Linux系统上,页的大小为4KB,此外,为了解决页表过大的问题,操作系统引入了多级页表机制,为了解决页表访问慢的问题,在CPU中还加入了TLB页表缓存机制。
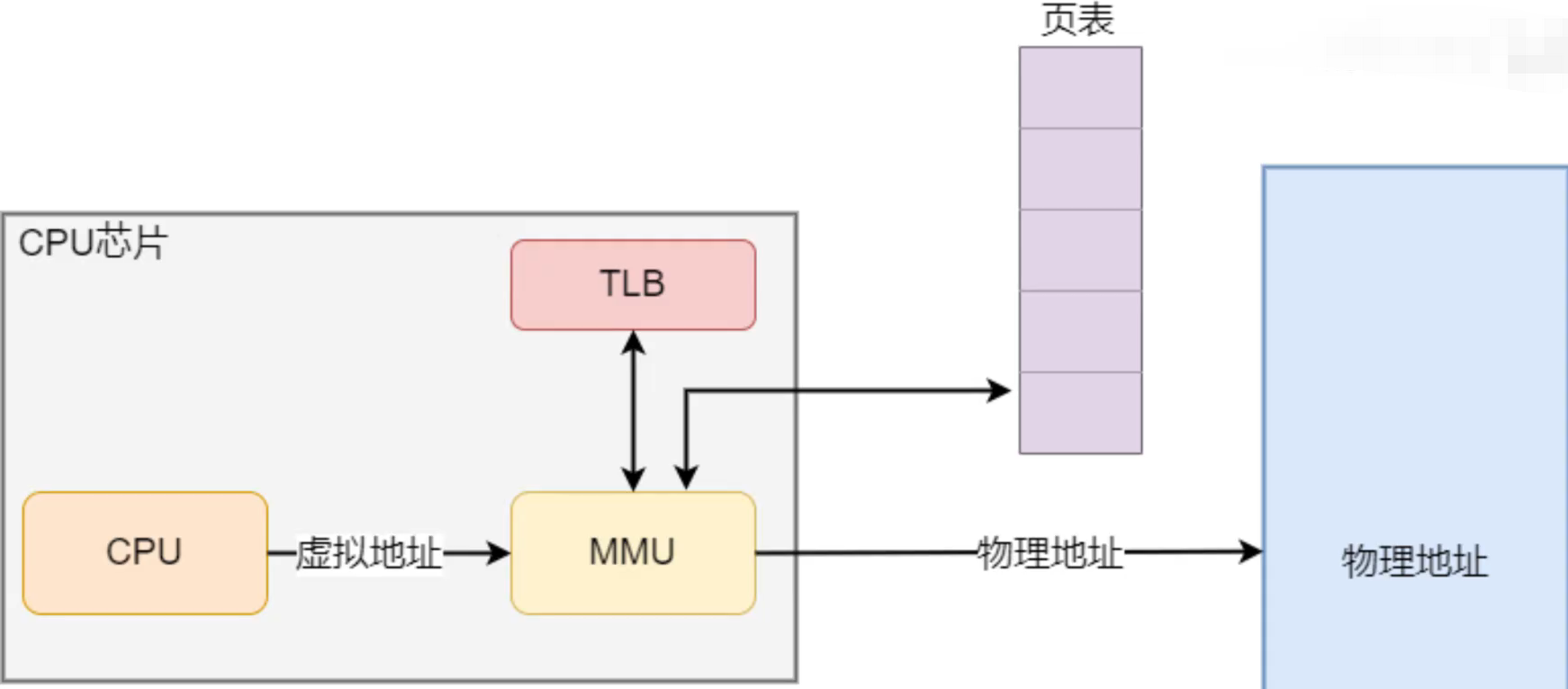
总结一下虚拟内存是怎么工作的:
当每个进程创建的时候,内核会为进程分配4G的虚拟内存,当进程还没有开始运行时,这只是一个内存布局。实际上并不立即就把虚拟内存对应位置的程序数据和代码(比如.text .data段)拷贝到物理内存中,只是建立好虚拟内存和磁盘文件之间的映射就好(叫做存储器映射)。这个时候数据和代码还是在磁盘上的。当运行到对应的程序时,进程去寻找页表,发现页表中地址没有存放在物理内存上,而是在磁盘上,于是发生缺页异常,于是将磁盘上的数据拷贝到物理内存中。
另外在进程运行过程中,要通过malloc来动态分配内存时,也只是分配了虚拟内存,即为这块虚拟内存对应的页表项做相应设置,当进程真正访问到此数据时,才引发缺页常。
可以认为虚拟空间都被映射到了磁盘空间中(事实上也是按需要映射到磁盘空间上,通过mmap,mmap是用来建立虚拟空间和磁盘空间的映射关系的)
虚拟内存的注意点:
关于虚拟内存有三点需要注意:
4G的进程地址空间被人为的分为两个部分--用户空间与内核空间。用户空间从0到3G(0xc0000000),内核空间占据3G到4G。用户进程通常情况下只能访问用户空间的虚拟地址,不能访问内核空间的虚拟地址。例外情况只有用户进程进行系统调用(代表用户进程在内核态执行)等时刻可以访问到内核空间。
用户空间对应进程,所以每当进程切换,用户空间就会跟着变化;而内核空间是由内核负责映射,它并不会跟着进程变化,是固定的。内核空间地址有自己对应的页表,用户进程各自有不同的页表。
每个进程的用户空间都是完全独立、互不相干的。
一、4G地址空间解析图
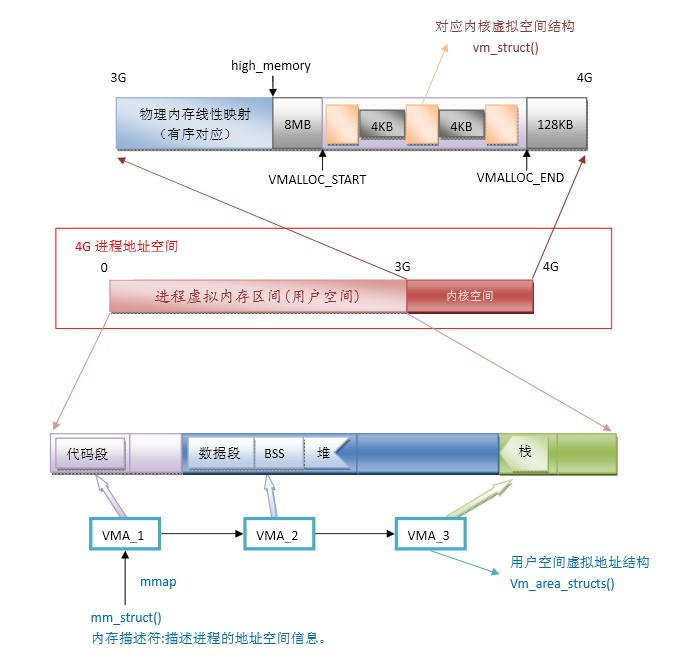
上图展示了整个进程地址空间的分布,其中4G的地址空间分为两部分,在用户空间内,对应了内存分布的五个段:数据段、代码段、BSS段、堆、栈。在上篇文章中有详细的介绍。
二、虚拟地址空间分配及其与物理内存对应图
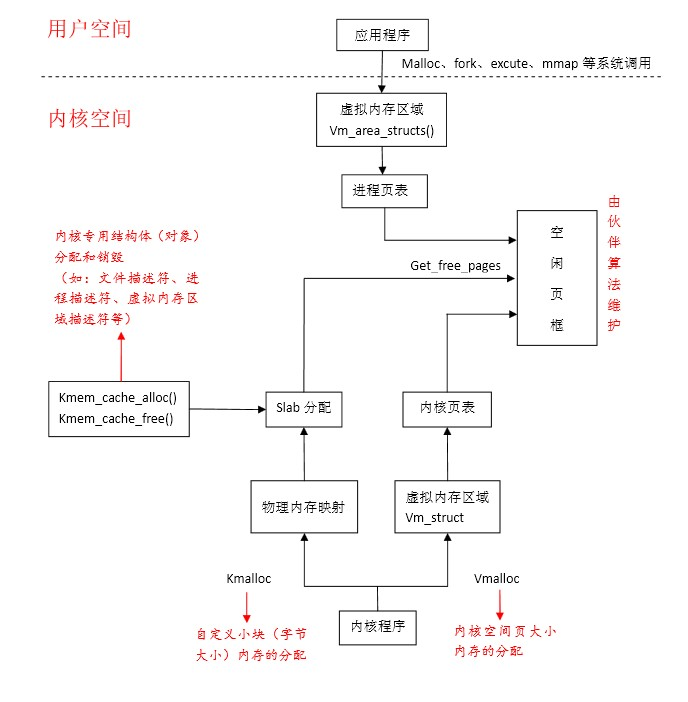
这个图示内核用户空间的划分,图中最重要的就是高端内存的映射
其中kmalloc和vmalloc函数申请的空间对应着不同的区域,同时又不同的含义。
三、物理内存分配图
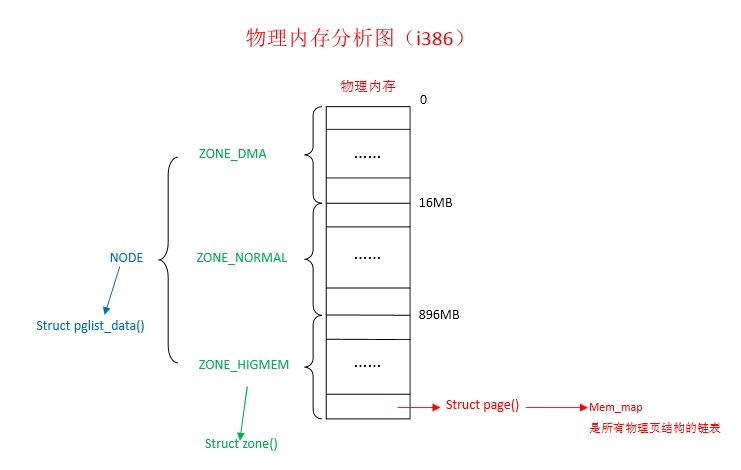
这张图中页解释了三者的不同关系,和上篇文章中的内容有相似之处。
伙伴算法:
一种物理内存分配和回收的方法,物理内存所有空闲页都记录在BUDDY链表中。首选,系统建立一个链表,链表中的每个元素代表一类大小的物理内存,分别为2的0次方、1次方、2次方,个页大小,对应4K、8K、16K的内存,没一类大小的内存又有一个链表,表示目前可以分配的物理内存。例如现在仅存需要分配8K的物理内存,系统首先从8K那个链表中查询有无可分配的内存,若有直接分配;否则查找16K大小的链表,若有,首先将16K一分为二,将其中一个分配给进程,另一个插入8K的链表中,若无,继续查找32K,若有,首先把32K一分为二,其中一个16K大小的内存插入16K链表中,然后另一个16K继续一分为二,将其中一个插入8K的链表中,另一个分配给进程........以此类推。当内存释放时,查看相邻内存有无空闲,若存在两个联系的8K的空闲内存,直接合并成一个16K的内存,插入16K链表中。(伙伴算法用于物理内存分配方案)
SLAB算法:
是一种对伙伴算的一种补充,对于用户进程的内存分配,伙伴算法已经够好了,但对于内核进程,还需要存在一类很小的数据(字节大小,比如进程描述符、虚拟内存描述符等),若每次给几个字节的数据分配一个4KB的页,实在太浪费,于是就有了SLBA算法,SLAB算法其实就是把一个页用力劈成一小块一小块,然后再分配
页面置换算法:
操作系统中使用虚拟内存管理技术时,当物理内存不足以容纳所有需要同时运行的进程或程序时,需要将部分数据从内存中暂时移出,以便为其他数据让出空间。这个过程就是页面置换,即将某些页面(通常以固定大小的块为单位)从物理内存中换出到磁盘上,以便为新的页面或数据腾出空间。
当一个程序需要访问一个不在内存中的页面时,就会发生缺页中断,操作系统会选择一个页面进行置换,将其写回到磁盘并将新的页面加载到内存中,以使程序继续执行。页面置换算法就是用来确定哪些页面需要被换出内存、哪些页面需要被保留在内存中,以及选择换出哪个页面的一种策略。通过合理选择页面置换算法,可以有效提高系统的性能和资源利用率。
页面置换算法有:
- LRU(Least Recently Used,最近最少使用):
LRU算法是一种基于页面访问时间的置换算法,它选择最近最久未被使用的页面进行替换。LRU算法的实现方式有很多种,包括使用栈、队列、哈希表等数据结构来维护页面的访问顺序。
- FIFO(First-In-First-Out,先进先出):
FIFO算法是一种简单的页面置换算法,它选择最早进入内存的页面进行替换。FIFO算法通过一个队列来维护页面的进入顺序,当需要替换页面时,选择队列中最早进入的页面进行替换。
- Clock算法:
Clock算法也称为二次机会算法,是对FIFO算法的改进。Clock算法使用一个指针按照顺时针方向扫描页面链表,当找到一个未被访问的页面时进行替换。这种算法通过一个简单的循环链表来维护页面的访问状态。
- LFU(Least Frequently Used,最不经常使用):
LFU算法是一种基于页面访问频率的置换算法,它选择最不经常被使用的页面进行替换。LFU算法通过维护页面的访问次数来确定哪些页面是最不经常被使用的,然后选择其中访问次数最少的页面进行替换。
遇到一个有意思的问题:
一个进程最多可以创建多少个线程?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号