
mysql
alter table emp MODIFY dept_id int;
-- 删除字段
alter table emp drop COLUMN dept_id;
之前就当是 热身了,跟着这个老师 你会觉得 真的能学到很多东西。要好好努力了!
上面两个语句是通用性很强的语句。是 在 oracle 里面也支持的语法。
今天要练习的点:
主外键, 多表联查,内连接 外链接 -左外链接 右外链接 全外链接
以及一些 通用性语法规则。感觉点不是特别多。应该 可以的。
给不会的点,做标记就可以了。
Point 1:
这个里面varchar 和 char 两种方式 都是代表字符串,varchar 可变长度字符串。char 不可变长度字符串。
两者各有优势,char 不可变则可以让 查询速度更快。
Varchar 长度可变,所以可以节省空间,但是 查询速度会相应降低
举例:
Create table stu(
Name char(10);
);
Create table stu(
Name varchar(10);
);
Insert into stu values ('nihao');
在char类型中仍然占用10个字符。
但是varchar里面只占用5个字符。
所以结果是char中更浪费空间,但是查询效率更高,因为在
varchar里面是按位 n i h a o 就是 一个 字符 一个 字符 来进行比较,所以查询效率会很低。
modify只能用来更改字段属性。
而change 既可以更改字段名 也可以为字段更改字段类型 以及字段的约束。
2015.10.27练习题:
一、
1、创建emp表:
emp_id int, 员工编号
emp_name varchar(20),员工姓名
emp_age int,员工年龄
emp_address varchar(50),员工住址
emp_date varchar(20)入职时间
2、删除该表 (因为
规范的命名是:数据库后缀名为:db 表名后缀名是 tb
字段名的前部分是表名 ,后部分是属性名中间用 下划线链接。举例
emp_tb_id
emp_tb_name)
3、重新添加该表,表名为emp_tb
4、为了操作方便,为表改名 为emp。
5、创建dept表:
dept_id int,
dept_name varchar(20)
6、添加字段 为emp表 添加一个 dept_id 字段。
7、修改此字段为 varchar(20)。利用 modify关键字
8、将此字段属性值改回为int类型。利用change关键字
区别:
modify只能用来更改字段属性。
而change 既可以更改字段名 也可以为字段更改 字段类型 以及字段的约束。
9、*删除字段 删除 入职时间列。
最好是用alter table emp drop column 列名。这个 column在mysql里面可写可不写,但是但是在其他语法结构里面,就十分重要。所以最好记住这个关键字。
10、插入数据:

11、修改数据:
(1)将地址为空的员工的地址改为北京,(2)部门号设置为2.
12、删除数据:
二、
我们常见的约束有哪些?至少写出6个。行级约束和列级约束分别指什么,请对这六个约束,进行相应分类。约束的意义在哪里?
三、
Char 和 varchar 有什么异同点?
四、约束的三种添加方式?
-- 1
create table emp(
emp_id int,
emp_name varchar(20),
emp_age int,
emp_address varchar(20),
emp_date date
);
-- 2
drop table emp;
-- 3
create table emp_tb(
emp_id int,
emp_name varchar(20),
emp_age int,
emp_address varchar(20),
emp_date date
);
-- 4
alter table emp_tb rename emp;
-- 5
create table dept(
dept_id int,
dept_name varchar(20)
);
-- 6
alter table emp add column dept_id int;
-- 7
alter table emp modify dept_id varchar(20);
-- 8
alter table emp change dept_id dept_id int;
-- 9
alter table emp drop column emp_date;
-- 10
SELECT * from emp;
insert into emp (emp_id,emp_name, emp_age, emp_address)values (1,'张三',23,'北京');
insert into emp (emp_id,emp_name,emp_age) values (2,'wangwu',45)
-- 11
update emp set emp_address='北京' where emp_address is null;
update emp set dept_id=2;
-- 12
delete from emp;
数据库的约束操作:为了保持数据的完整性:
我们知道的关键字有:
not null, primary key, unique foreign key default CHECK(这个 mysql语法里面没有)
他们可以分成行级约束 和列级约束。
两者的区别在于,行级约束是指,行与行之间存在制约关系,即:某一行取值为a 另一行的取值收到a的制约,不可以再为a。这就属于行级约束。
列级约束,是相对于自身的一种约束,比如 不能为空,即 只跟自己有关系的约束条件。
根据这种定义:我们可以将上面六种关键字进行如下分类:
行级约束:primary key;unique
列级约束:not null;foreign key;default;CHECK
针对约束有两种添加方式,有一种我们已经熟知的直接在属性后面添加。
举例:
Create table student(
Stuid int primary key,
Stuname varchar(20)
);
第二种,在创建表的最后一行进行添加。
Create table student(
Stuid int,
Stuname varchar (20),
Constraint pk_student_id primary key (stuid)
);
四个部分来修饰 括号 千万万千 注意了!
约束 给出需要系统知道的名称 约束类型 (列名)
constraint pk_emp_tb3_address default '北京' (emp_address) 结尾添加 默认值约束 并不容易。
数据库错误 150 是什么? 怎么解决
constraint unique (emp_address) 这也是可行的。
外键约束添加方式:
好吧 也是 醉了 在外面可以 添加,在创建的里面 就是 添加不上。
这个 地方还要多巩固
约束 的添加方式
在表结尾 添加的方式
以及在表外添加的方式。
这里写笔记吧,我觉得 我会的!!!
emp_age Between A and B
等价于:emp_age >=A and emp_age<=B
Select * from emp where id in (20,8,4,2)
查询emp中的所有信息 当id 为 20或者8或者 4或者 2 。
反向查询 select * from emp where id not in (20,8, 4,2)
查询emp表中 id 不等于 20 8 4 2 的员工的所有信息
Between and 和 in 之间 是有区别的。
Between and是一个 区间
In 是一个 我们自己定义的范围
模糊查询
Select * from emp where name like 'a%';
在emp表中查找 name 以a打头的名字
Select * from emp where name like '%a'
在emp表中 查找 以a结尾的名字
Select * from emp where name like '%a%'
在emp表中 查找 名字中包含a的名字
Select * from emp where name like '_a%'
在emp表中 查找 名字为“空格a 哒哒哒”形式的名字
换句话说 “_” 是占位符
“%” 是通配符
通过 我们的理解易得:
Select from where 的查询顺序是:
From where select
Order by 的顺序:
Select * from TABLE where COLUMN1=? Order by COLUMN2 desc,COLUMN3
Asc
从表中查找列名1等于问号 的所有信息 以COLUMN2 降序排序 当COLUMN2的值相等时,以COLUMN3 进行排序。
根据这个套路 所以 先做 select from where order by 四者的顺序是
from where select order 进行的。
所以 现在给出这样一张表:
Create table emp(
Emp_id int,
Emp_name varchar(20),
Salary int//月薪
);
现在题目为:按照年薪对emp查询出的结果进行排序:
Select *,salary*12 年薪 from emp where 1=1 order by 年薪;
聚合函数:
Select count (*) from emp;查询一共有多少条记录
Select max(emp_age) from emp;查询 员工的最大年龄
Select min(emp_age) from emp;查询员工的最小年龄
Select avg(sal) from emp;查询员工的平均工资
Select sum(sal),avg(sal) max(sal)from emp;查询emp表中 的每月工资总和 平均工资 和工资最大值
!!!
如果有分组查询 select 后面只能显示 分组字段 或者分组函数。
例如下面这条语句:
Select avg(sal),max(sal),dept_id from emp group by dept_id;
查询平均工资 和最大工资 还有部门编号 从员工表中,通过 部门编号进行分组。
际上并未拥有次最大工资,这样在其他数据库中认为是不安全的。当然最初设计这款数据库的人认为,我就要显示某个人举例平均工资和最大工资的一个数量上的关系,可能这样他就允许了这样一种情况。
其实,在mysql里面是可以显示*的。但是 这样会出现奇怪的数据集合,在其他的数据库里面是不允许这样的语句出现的。所以 在这里 就要记住,如果有分组查询那么select后面只能显示 分组字段或者分组函数。
!!!
聚合和分组查询一起使用的时候,函数计算数据是分组后的数据
举例:
Select avg(sal),max(sal),dept_id from emp group by dept_id having avg(sal)>1800
从emp表中 查询平均工资 最大工资 部门编号 通过 部门编号来分组 其中显示 平均工资大于1800的数据。
什么时候 会分组这个要多做一些练习才能分析出来
关于分组查询的问题:
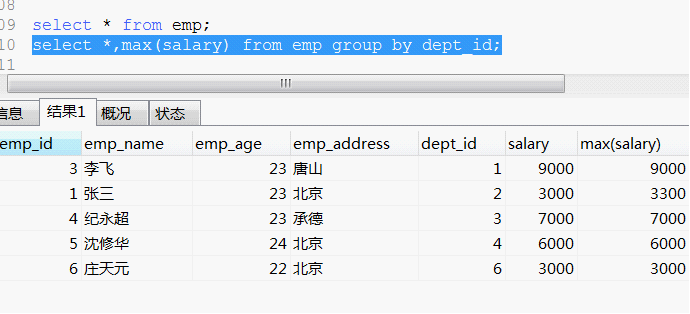
我们想要挑选不同部门的最大工资:然后发现在第二个部门里面,最高工资是3300,如果此时 我们将salary列去掉。

就会发现张三得到了最高工资。这样的语法结构在mysql里面是被允许的。但是在其他数据库系统里面是不被允许的。其他数据库认为这样做 不安全。
所以 这可以算是一个语法特性。
所以这就是 我们记录的笔记:
如果有分组查询,那么分组查询的显示条件只能有:分组字段或者分组函数(聚合函数)
也即是 select 后面只能是 分组字段 或者 分组函数或者叫聚合函数。
所以下面这句话看着,就很顺眼,也很好理解:
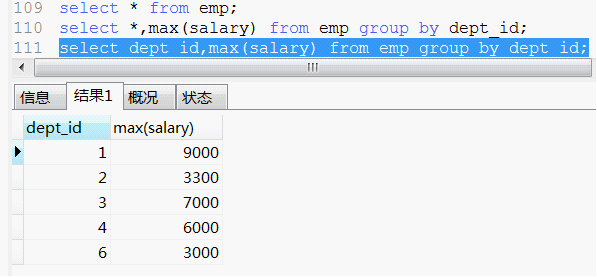
前面是部门编号 后面是部门对应的最高工资。
聚合函数 (分组函数)一起使用的时候函数计算数据是分组后的数据。
聚合函数 就是 分组函数
所以 我们可以排一下序了
From where group by having select order by

看到我们的排序,你发现 having 在select 前面,所以 在having 里面不可能有 “平均工资” 这个 条目,这样做是非法的。
也就是说: 这也是mysql的一个特性。在其他数据库里面,是不允许这样做的。
而且 能很清晰的知道 这条语法的意义:
找到不同部门里面的平均工资 和最高工资。
我们可以完善一下 对应一下部门表得到 完整的想要的 数据:
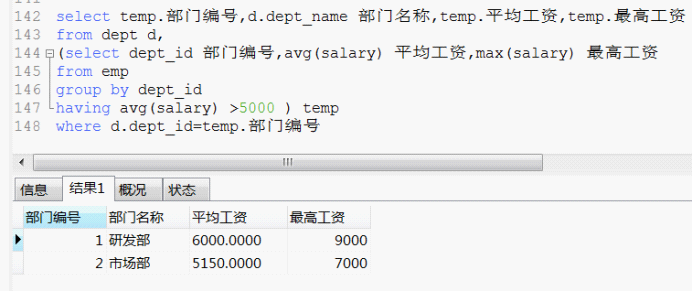
那种写法并不存在,或者 就应该起一个别名。因为程序也不打算算两次 既然我们在前面已经得到了相关数据的话。
后面用到的所有数据 应该是 已经出现过了的!!!
好吧 脑袋有点儿 浆糊了 主要是 太乱了,一直在吵吵,或者 一上午 都在干同一件事,真的可能体力不支了。
好吧 编一个 场景:
要举办联谊会了,要求找到不同部门之间同年龄的员工。

最全查询顺序:
Select from where group by having order by limit
七者的执行顺序:
From where group by having select order by limit
符合这个规范执行的就是 绝对通用的数据库查询与法。
其次加一个
分组查询的显示部分只能有 分组条件 或者分组函数。
内外联:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号