Gemma一键部署教程,基于Ollama超简单。
一、下载,安装ollama
1.安装 ollama,下载后无脑安装。
https://ollama.com/
https://github.com/ollama/ollama
2.打开cmd命令窗口,安装 Gemma:
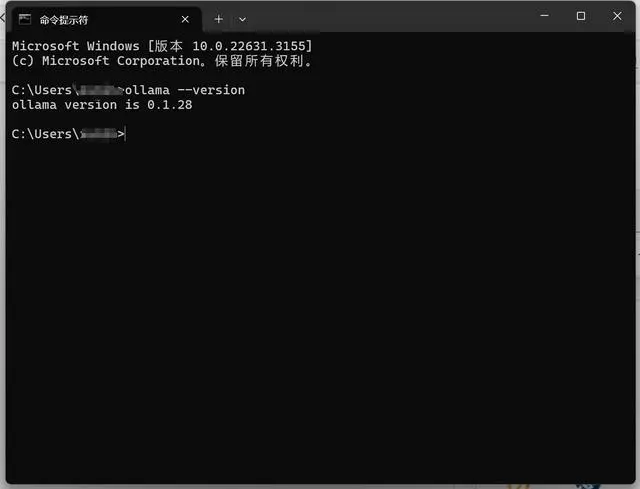
按住 “windows+R ”,输入cmd ,运行:进入CMD命令提示符窗口。
输入“ollama --version",当看到ollama版本号正确显示时,就已经完成安装了。
二、拉取并运行Gemma模型
这一步我们直接使用最简单的方法,使用Ollama来拉取Gemma的模型文件。请注意,由于文件服务器在国外,所以我们需要一些魔法上网的技巧,请自行研究。
以对电脑配置要求最低的Gemma 2b基础版模型为例,在命令提示符中,我们输入ollama run gemma:2b代码并回车,Ollama会自动从模型库中拉取模型文件并进行运行。
当模型加载后,会显示success的标识,此时我们就可以输入汉字与Gemma:2b进行对话了。

已经可以用中文对话了, 就是 本地模型,有点智障。。。
下面上文心一言生成的,当个对比:
一、前期准备
- 选择一个支持GPU的服务器系统版本:由于大型模型需要GPU进行运算,建议选择支持GPU显卡的服务器系统版本。例如,可以选择Ubuntu 22.04作为服务器系统版本。
- 安装Ollama:Ollama支持macOS、Windows、Linux和Docker等多种安装方式。以Windows系统为例,可以从Ollama的官网或GitHub页面下载最新的Windows版本安装包,
- 并按照提示完成安装。安装完成后,运行Ollama,并验证版本号是否正确显示。
二、部署Gemma模型
- 拉取并运行Gemma模型:在CMD命令提示符中,使用相关命令拉取并运行Gemma模型。这一步可能涉及具体的命令和参数设置,需要根据实际情况进行调整。
三、验证部署是否成功
可以通过访问特定的IP地址或端口来验证Gemma模型是否已成功部署。例如助考笔记,可以访问ip:11434来查看Ollama是否成功部署。
请注意,以上步骤仅为大致流程,具体的操作可能因环境和需求的不同而有所差异。在进行部署时,建议参考Ollama和Gemma的官方文档或相关教程,以确保操作的准确性和有效性。此外,对于大型模型的部署和运行,还需要考虑服务器硬件资源、网络带宽等因素,以确保模型的稳定运行和高效性能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号