Spark Shuffle
Spark Shuffle
Shuffling是一个分布在不同分区数据进行重新分配(重新分区)的过程。这个分配过程可能会引起数据在不同JVM进程或者集群的不同节点间移动。
Shuffling是在不同stage之间进行数据传输的过程
| 提示 | 为了避免shuffle产生的开销,应该尽量使用现有分区进行操作,利用部分聚合来减少数据传输。 |
可能引起shuffle的操作包括:
- 重新分区操作,如repartition和coalesce等
- 除了counting以外的ByKey操作,如groupByKey和reduceByKey等
- join操作,如cogroup和join等
我们应该尽量避免使用groupByKey,用reduceByKey或combineByKey代替。
groupByKey将所有数据进行shuffle,会很慢。
reduceByKey仅对数据的每个分区中的sub-aggregations结果进行shuffle。
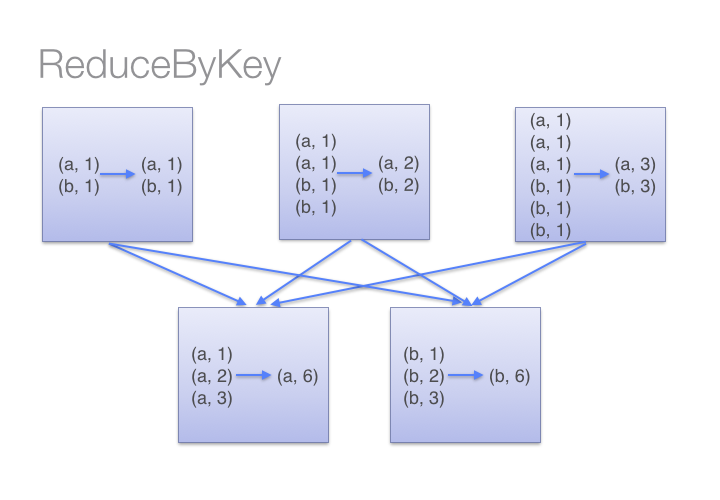
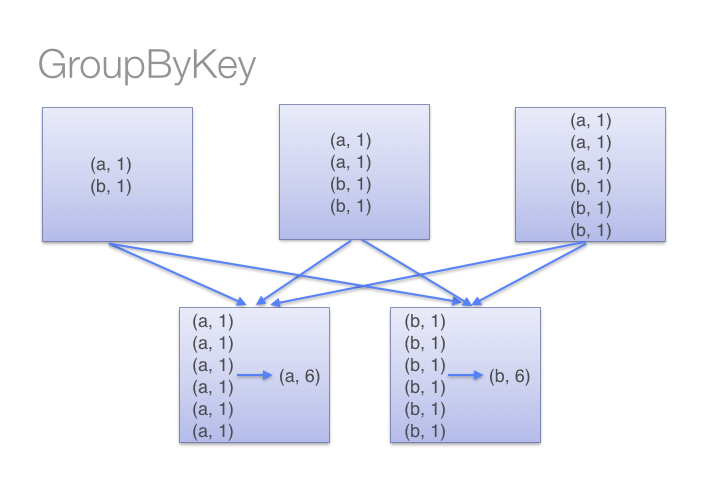
例如,让我们看两种不同的WordCount例子,一种使用reduceByKey,另一种使用groupByKey:
val words = Array("one", "two", "two", "three", "three", "three")
val wordPairsRDD = sc.parallelize(words).map(word => (word, 1))
val wordCountsWithReduce = wordPairsRDD
.reduceByKey(_ + _)
.collect()
val wordCountsWithGroup = wordPairsRDD
.groupByKey()
.map(t => (t._1, t._2.sum))
.collect()
两种方法得到结果是一样的,但如输入的是大型数据集,reduceByKey效果会好得多,因为我们在reducer上提前进行了部分聚合来减少数据传输。而当调用groupByKey时, 我们需要对所有的键值对进行shuffle,造成了大量不需要的数据传输。
参考下图。
|
|
除了reduceByKey之外,以下函数也可以用来代替groupByKey:
- combineByKey
- foldByKey
可能引起shuffle的操作
以下是可能会引起shuffle的操作:
- cogroup
- groupWith
- join
- leftOuterJoin
- rightOuterJoin
- groupByKey
- reduceByKey
- combineByKey
- distinct
- intersection
- repartition
- coalesce
Shuffle的优化
Shuffle是一个开销很大的操作,因为它涉及磁盘I/O,数据序列化和网络I/O等。
在Spark的shuffle操作中:
- map任务来组织数据,
- reduce任务来对数据进行聚合。
map任务的结果会保存在内存中(直到没有可用内存为止)。 然后,这些结果会基于目标分区进行排序并写入单个文件。 然后在reduce操作时,读取相关文件中的相应的block。
我们可以通过配置相关参数对shuffle操作进行调优[TO-DO]。
参考资料
shuffle-operations
prefer_reducebykey_over_groupbykey
Shuffle

 浙公网安备 33010602011771号
浙公网安备 33010602011771号