正则表达式
RegExp 三大方法
本文的 RegExp 采用直接量语法表示:/pattern/attributes。attributes 有三个选择,i、m 和 g,m(多行匹配)不常用直接省略,所以一个 pattern(匹配模式)可以表示如下:
var pattern = /hello/ig;
i(ignore)表示不区分大小写(地搜索匹配),比较简单,以下例子中不加述说;g(global)表示全局(搜索匹配),即找到一个后继续找下去,相对复杂,以下各种方法中会特别介绍。
既然是 RegExp 的三大方法,所以都是 pattern.test/exec/complie 的格式。
test
主要功能:检测指定字符串是否含有某个子串(或者匹配模式),返回 true 或者 false。
示例如下:
var s = 'you love me and I love you';
var pattern = /you/;
var ans = pattern.test(s);
console.log(ans); // true
如果 attributes 用了 g,则可以继续找下去,其中还会涉及 lastIndex 属性(参照 exec 中搭配 g 的介绍)。
exec
主要功能:提取指定字符串中的符合要求的子串(或者匹配模式),返回一个数组存放匹配结果;如果没有,则返回 null。(也可自己写方法循环提取所有或者指定 index 的数据)
exec 可以说是 test 的升级版本,因为它不仅可以检测,而且检测到了可以直接提取结果。
示例如下:
var s = 'you love me and I love you';
var pattern = /you/;
var ans = pattern.exec(s);
console.log(ans); // ["you", index: 0, input: "you love me and I love you"]
console.log(ans.index); // 0
console.log(ans.input); // you love me and I love you
输出的东西很有意思。此数组的第 0 个元素是与正则表达式相匹配的文本,第 1 个元素是与 RegExpObject 的第 1 个子表达式相匹配的文本(如果有的话),第 2 个元素是与 RegExpObject 的第 2 个子表达式相匹配的文本(如果有的话),以此类推。
啥叫 “与子表达式相匹配的文本”?看下面的例子:
var s = 'you love me and I love you';
var pattern = /y(o?)u/;
var ans = pattern.exec(s);
console.log(ans); // ["you", "o", index: 0, input: "you love me and I love you"]
console.log(ans.length) // 2
所谓的子表达式就是 pattern 里()内的东西(具体可以参考下文对子表达式的介绍)。再看上面例子的数组长度,是 2!!index 和 input 只是数组属性(chrome 中以上的输出可能会让人误会)。
除了数组元素和 length 属性之外,exec () 方法还返回两个属性。index 属性声明的是匹配文本的第一个字符的位置。input 属性则存放的是被检索的字符串 string。我们可以看得出,在调用非全局的 RegExp 对象的 exec () 方法时,返回的数组与调用方法 String.match () 返回的数组是相同的。
如果使用 "g" 参数,exec () 的工作原理如下(还是以上的例子 ps:如果 test 使用 g 参数类似):
- 找到第一个 "you",并存储其位置
- 如果再次运行 exec (),则从存储的位置(lastIndex)开始检索,并找到下一个 "you",并存储其位置
当 RegExpObject 是一个全局正则表达式时,exec () 的行为就稍微复杂一些。它会在 RegExpObject 的 lastIndex 属性指定的字符处开始检索字符串 string。当 exec () 找到了与表达式相匹配的文本时,在匹配后,它将把 RegExpObject 的 lastIndex 属性设置为匹配文本的最后一个字符的下一个位置。这就是说,我们可以通过反复调用 exec () 方法来遍历字符串中的所有匹配文本。当 exec () 再也找不到匹配的文本时,它将返回 null,并把 lastIndex 属性重置为 0。这里引入 lastIndex 属性,这货只有跟 g 和 test(或者 g 和 exec)三者搭配时才有作用。它是 pattern 的一个属性,一个整数,标示开始下一次匹配的字符位置。
实例如下:
var s = 'you love me and I love you';
var pattern = /you/g;
var ans;
do {
ans = pattern.exec(s);
console.log(ans);
console.log(pattern.lastIndex);
}
while (ans !== null)
结果如下:

应该还容易理解,当第三次循环时,找不到 “you" 了,于是返回 null,lastIndex 值也变成 0 了。
如果在一个字符串中完成了一次模式匹配之后要开始检索新的字符串(仍然使用旧的 pattern),就必须手动地把 lastIndex 属性重置为 0。
compile
主要功能:改变当前匹配模式(pattern)
这货是改变匹配模式时用的,用处不大,略过。详见 JavaScript compile () 方法
String 四大护法
和 RegExp 三大方法分庭抗礼的是 String 的四大护法,四大护法有些和 RegExp 三大方法类似,有的更胜一筹。
既然是 String 家族下的四大护法,所以肯定是 string 在前,即 str.search/match/replace/split 形式。
既然是 String 的方法,当然参数可以只用字符串而不用 pattern。
search
主要功能:搜索指定字符串中是否含有某子串(或者匹配模式),如有,返回子串在原串中的初始位置,如没有,返回 - 1。
是不是和 test 类似呢?test 只能判断有木有,search 还能返回位置!当然 test () 如果有需要能继续找下去,而 search 则会自动忽略 g(如果有的话)。实例如下:
var s = 'you love me and I love you';
var pattern = /you/;
var ans = s.search(pattern);
console.log(ans); // 0
话说和 String 的 indexOf 方法有点相似,不同的是 indexOf 方法可以从指定位置开始查找,但是不支持正则。
match
主要功能:和 exec 类似,从指定字符串中查找子串或者匹配模式,找到返回数组,没找到返回 null
match 是 exec 的轻量版,当不使用全局模式匹配时,match 和 exec 返回结果一致;当使用全局模式匹配时,match 直接返回一个字符串数组,获得的信息远没有 exec 多,但是使用方式简单。
实例如下:
var s = 'you love me and I love you';
console.log(s.match(/you/)); // ["you", index: 0, input: "you love me and I love you"]
console.log(s.match(/you/g)); // ["you", "you"]
replace
主要功能:用另一个子串替换指定字符串中的某子串(或者匹配模式),返回替换后的新的字符串 str.replace (' 搜索模式 ',' 替换的内容 ') 如果用的是 pattern 并且带 g,则全部替换;否则替换第一处。
实例如下:
var s = 'you love me and I love you';
console.log(s.replace('you', 'zichi')); // zichi love me and I love you
console.log(s.replace(/you/, 'zichi')); // zichi love me and I love you
console.log(s.replace(/you/g, 'zichi')); // zichi love me and I love zichi
如果需要替代的内容不是指定的字符串,而是跟匹配模式或者原字符串有关,那么就要用到 $ 了(记住这些和 $ 符号有关的东东只和 replace 有关哦)。

怎么用?看个例子就明白了。
var s = 'I love you';
var pattern = /love/;
var ans = s.replace(pattern, '$`' + '$&' + "$'");
console.log(ans); // I I love you you
没错,'$`' + '$&' +"$'" 其实就相当于原串了!
replace 的第二个参数还能是函数,看具体例子前先看一段介绍:

第一个参数是匹配到的子串,接下去是子表达式匹配的值,如果要用子表达式参数,则必须要有第一个参数(表示匹配到的串),也就是说,如果要用第 n 个参数代表的值,则左边参数都必须写出来。最后两个参数跟 exec 后返回的数组的两个属性差不多。
var s = 'I love you';
var pattern = /love/;
var ans = s.replace(pattern, function(a) { // 只有一个参数,默认为匹配到的串(如还有参数,则按序表示子表达式和其他两个参数)
return a.toUpperCase();
});
console.log(ans); // I LOVE you
split
主要功能:分割字符串
字符串分割成字符串数组的方法(另有数组变成字符串的 join 方法)。直接看以下例子:
var s = 'you love me and I love you';
var pattern = 'and';
var ans = s.split(pattern);
console.log(ans); // ["you love me ", " I love you"]
如果你嫌得到的数组会过于庞大,也可以自己定义数组大小,加个参数即可:
var s = 'you love me and I love you';
var pattern = /and/;
var ans = s.split(pattern, 1);
console.log(ans); // ["you love me "]
RegExp 字符
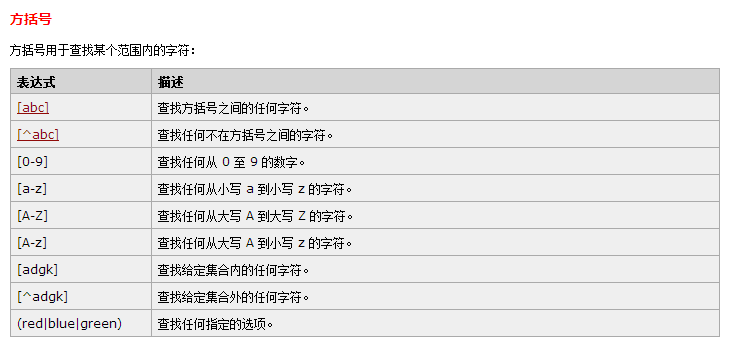
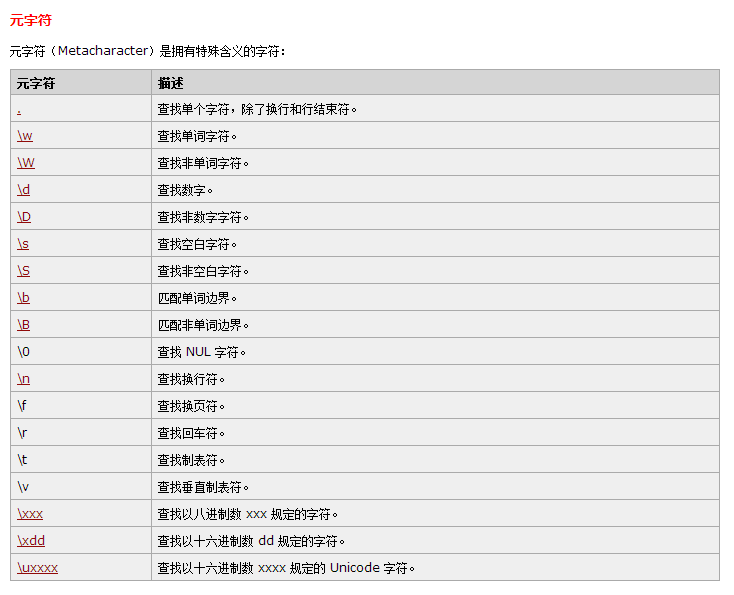
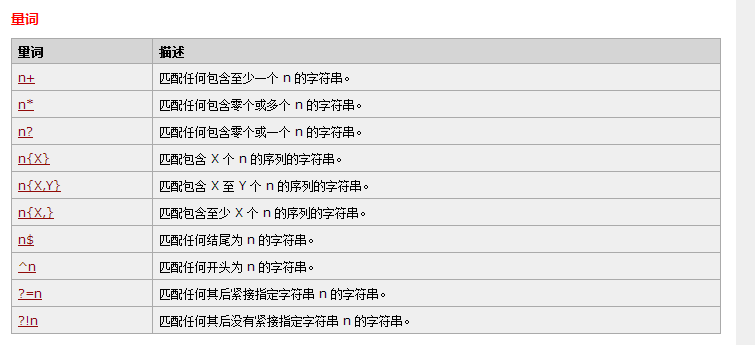
- \s 任意空白字符 \S 相反 空白字符可以是: 空格符 (space character) 制表符 (tab character) 回车符 (carriage return character) 换行符 (new line character) 垂直换行符 (vertical tab character) 换页符 (form feed character)
- \b 是正则表达式规定的一个特殊代码,代表着单词的开头或结尾,也就是单词的分界处。虽然通常英文的单词是由空格,标点符号或者换行来分隔的,但是 \b 并不匹配这些单词分隔字符中的任何一个,它只匹配一个位置。(和 ^ $ 以及零宽断言类似)
- \w 匹配字母或数字或下划线 [a-z0-9A-Z_] 完全等同于 \w
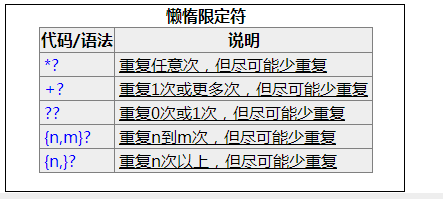
贪婪匹配和懒惰匹配
什么是贪婪匹配?贪婪匹配就是在正则表达式的匹配过程中,默认会使得匹配长度越大越好。
var s = 'hello world welcome to my world';
var pattern = /hello.*world/;
var ans = pattern.exec(s);
console.log(ans) // ["hello world welcome to my world", index: 0, input: "hello world welcome to my world"]
以上例子不会匹配最前面的 hello world,而是一直贪心的往后匹配。
那么我需要最短的匹配怎么办?很简单,加个‘?’即可,这就是传说中的懒惰匹配,即匹配到了,就不往后找了。
var s = 'hello world welcome to my world';
var pattern = /hello.*?world/;
var ans = pattern.exec(s);
console.log(ans) // ["hello world", index: 0, input: "hello world welcome to my world"]
懒惰限定符(?)添加的场景如下:
子表达式
表示方式
用一个小括号指定:
var s = 'hello world';
var pattern = /(hello)/;
var ans = pattern.exec(s);
console.log(ans);
子表达式出现场景
在 exec 中数组输出子表达式所匹配的值:
var s = 'hello world';
var pattern = /(h(e)llo)/;
var ans = pattern.exec(s);
console.log(ans); // ["hello", "hello", "e", index: 0, input: "hello world"]
在 replace 中作为替换值引用:
var s = 'hello world';
var pattern = /(h\w*o)\s*(w\w*d)/;
var ans = s.replace(pattern, '$2 $1')
console.log(ans); // world hello
子表达式的序号问题
简单地说:从左向右,以分组的左括号为标志,第一个出现的分组的组号为 1,第二个为 2,以此类推。
复杂地说:分组 0 对应整个正则表达式实际上组号分配过程是要从左向右扫描两遍的:第一遍只给未命名组分配,第二遍只给命名组分配--因此所有命名组的组号都大于未命名的组号。可以使用 (?:exp) 这样的语法来剥夺一个分组对组号分配的参与权.
后向引用
如果我们要找连续两个一样的字符,比如要找两个连续的 c,可以这样 /c {2}/,如果要找两个连续的单词 hello,可以这样 /(hello){2}/,但是要在一个字符串中找连续两个相同的任意单词呢,比如一个字符串 hellohellochinaworldworld,我要找的是 hello 和 world,怎么找?
这时候就要用后向引用。看具体例子:
var s = 'hellohellochinaworldworld';
var pattern = /(\w+)\1/g;
var a = s.match(pattern);
console.log(a); // ["hellohello", "worldworld"]
这里的 \1 就表示和匹配模式中的第一个子表达式(分组)一样的内容,\2 表示和第二个子表达式(如果有的话)一样的内容,\3 \4 以此类推。(也可以自己命名,详见参考文献)
或许你觉得数组里两个 hello 两个 world 太多了,我只要一个就够了,就又要用到子表达式了。因为 match 方法里是不能引用子表达式的值的,我们回顾下哪些方法是可以的?没错,exec 和 replace 是可以的!
exec 方式
var s = 'hellohellochinaworldworld';
var pattern = /(\w+)\1/g;
var ans;
do {
ans = pattern.exec(s);
console.log(ans);
} while(ans !== null);
// result
// ["hellohello", "hello", index: 0, input: "hellohellochinaworldworld"] index.html:69
// ["worldworld", "world", index: 15, input: "hellohellochinaworldworld"] index.html:69
如果输出只要 hello 和 world,console.log (ans [1]) 即可。
replace 方式
var s = 'hellohellochinaworldworld';
var pattern = /(\w+)\1/g;
var ans = [];
s.replace(pattern, function(a, b) {
ans.push(b);
});
console.log(ans); // ["hello", "world"]
如果要找连续 n 个相同的串,比如说要找出一个字符串中出现最多的字符:
String.prototype.getMost = function() {
var a = this.split('');
a.sort();
var s = a.join('');
var pattern = /(\w)\1*/g;
var a = s.match(pattern);
a.sort(function(a, b) {
return a.length < b.length;
});
var letter = a[0][0];
var num = a[0].length;
return letter + ': ' + num;
}
var s = 'aaabbbcccaaabbbcccccc';
console.log(s.getMost()); // c: 9
如果需要引用某个子表达式(分组),请认准后向
零宽断言
别被名词吓坏了,其实解释很简单。
它们用于查找在某些内容 (但并不包括这些内容) 之后的东西,也就是说它们像 \b,^,$ 那样用于指定一个位置,这个位置应该满足一定的条件 (即断言)
(?=exp)
零宽度正预测先行断言,它断言自身出现的位置的后面能匹配表达式 exp。
// 获取字符串中以ing结尾的单词的前半部分
var s = 'I love dancing but he likes singing';
var pattern = /\b\w+(?=ing\b)/g;
var ans = s.match(pattern);
console.log(ans); // ["danc", "sing"]
(?!exp)
零宽度负预测先行断言,断言此位置的后面不能匹配表达式 exp
// 获取第五位不是i的单词的前四位
var s = 'I love dancing but he likes singing';
var pattern = /\b\w{4}(?!i)/g;
var ans = s.match(pattern);
console.log(ans); // ["love", "like"]
javascript 正则只支持前瞻,不支持后瞻((?<=exp) 和 (?<!exp))。
关于零宽断言的具体应用可以参考综合应用一节给字符串加千分符。
其他
字符转义
因为某些字符已经被正则表达式用掉了,比如. * () /\ [],所以需要使用它们(作为字符)时,需要用 \ 转义
var s = 'http://www.cnblogs.com/zichi/';
var pattern = /http:\/\/www\.cnblogs\.com\/zichi\//;
var ans = pattern.exec(s);
console.log(ans); // ["http://www.cnblogs.com/zichi/", index: 0, input: "http://www.cnblogs.com/zichi/"]
分支条件
如果需要匹配 abc 里的任意字母,可以用 [abc],但是如果不是单个字母那么简单,就要用到分支条件。
分支条件很简单,就是用 | 表示符合其中任意一种规则。
var s = "I don't like you but I love you";
var pattern = /I.*(like|love).*you/g;
var ans = s.match(pattern);
console.log(ans); // ["I don't like you but I love you"]
答案执行了贪婪匹配,如果需要懒惰匹配,则:
var s = "I don't like you but I love you";
var pattern = /I.*?(like|love).*?you/g;
var ans = s.match(pattern);
console.log(ans); // ["I don't like you", "I love you"]
综合应用
去除字符串首尾空格(replace)
String.prototype.trim = function() {
return this.replace(/(^\s*)|(\s*$)/g, "");
};
var s = ' hello world ';
var ans = s.trim();
console.log(ans.length); // 12
给字符串加千分符(零宽断言)
String.prototype.getAns = function() {
var pattern = /(?=((?!\b)\d{3})+$)/g;
return this.replace(pattern, ',');
}
var s = '123456789';
console.log(s.getAns()); // 123,456,789
2017/12/25 看到个更 hack 的方式:
let a = 123456789 // int type
console.log(a.toLocaleString('en-US')) // "123,456,789"
console.log(a.toLocaleString()) // "123,456,789"
找出字符串中出现最多的字符(后向引用)
String.prototype.getMost = function() {
var a = this.split('');
a.sort();
var s = a.join('');
var pattern = /(\w)\1*/g;
var a = s.match(pattern);
a.sort(function(a, b) {
return a.length < b.length;
});
var letter = a[0][0];
var num = a[0].length;
return letter + ': ' + num;
}
var s = 'aaabbbcccaaabbbcccccc';
console.log(s.getMost()); // c: 9
字符转义(replace)
function escapeHtml(str) {
return str.replace(/[<>"&]/g, function(a) {
switch (a) {
case "<":
return "<";
case ">":
return ">";
case "&":
return "&";
case "\"":
return """;
}
});
}
var ans = escapeHtml('<>"&');
console.log(ans); // <>"&
常用匹配模式(持续更新)
- 只能输入汉字:/[1]{0,}$/
- 匹配双字节字符 (包括汉字在内):[^\x00-\xff]
总结
- test:检查指定字符串中有没有某子串(或某匹配模式),返回 true 或者 false;如有必要可以进行全局模式搜索。
- exec:检查指定字符串中有没有某子串(或者匹配模式),如有返回数组(数组信息丰富,可参考上文介绍),如没有返回 null;如有必要可以进行全局搜索找出所有子串(或者匹配模式)的信息, 信息中含有匹配模式中子表达式所对应的字符串。
- compile:修改正则表达式中的 pattern
- search:检查指定字符串中有没有某子串(或者匹配模式),如有返回子串(或者匹配模式)在原串中的开始位置,如没有返回 - 1。不能进行全局搜索。
- match:检查指定字符串中有没有某子串(或者匹配模式),非全局模式下返回信息和 exec 一致;如进行全局搜索,直接返回字符串数组。(如不需要关于每个匹配的更多信息,推荐用 match 而不是 exec)
- replace:检查指定字符串中有没有某子串(或者匹配模式),并用另一个子串代替(该子串可以跟原字符串或者搜索到的子串有关);如启动 g,则全局替换,否则只替换第一个。replace 方法可以引用子表达式所对应的值。
- split:用特定模式分割字符串,返回一个字符串数组;与 Array 的 join 方法正好相反。
- 子表达式:用括号括起来的正则匹配表达式,用后向引用可以对其进行引用;也可以和 exec 或者 replace 搭配获取其真实匹配值。
- 后向引用 :对子表达式所在分组进行引用。
- 零宽断言:和 \b ^ 以及 $ 类似的某个位置概念。
参考
\u4e00-\u9fa5 ↩︎


 浙公网安备 33010602011771号
浙公网安备 33010602011771号