golang版并发爬虫
准备爬取内涵段子的几则笑话,先查看网址:http://www.budejie.com/text/
简单分析后发现每页的url呈加1趋势
第一页: http://www.budejie.com/text/1
第二页:http://www.budejie.com/text/2
...
每页的段子:
<a href="/detail-28278217.html"> 内容</a>
<a href="/detail-28270675.html"> 内容</a>
....
所以正则表达式的解释规则是<a href="/detail-\d{8}.html">(?s:(.*?))</a>,第一个分组的内容就是需要的文字。
代码如下:
package main import ( "fmt" "regexp" "strconv" "net/http" "log" "os" "strings" ) func onespider(n int, ch chan int) { url := "http://www.budejie.com/text/" + strconv.Itoa(n) resp, err := http.Get(url) if err != nil { log.Fatal("get error") } defer resp.Body.Close() reg, err1 := regexp.Compile(`<a href="/detail-\d{8}.html">(?s:(.*?))</a>`) if err1 != nil { log.Fatal("compile error") } var respstring string buf := make([]byte, 1024) for { n, _ := resp.Body.Read(buf) if n == 0 { break } respstring += string(buf[:n]) } cont := reg.FindAllStringSubmatch(respstring, -1) file, _ := os.OpenFile("./爬虫/"+"第"+strconv.Itoa(n)+"页爬虫.txt", os.O_RDWR|os.O_TRUNC|os.O_CREATE, 0666) defer file.CLose() var i int for _, value := range cont { if len(value[1]) < 100 { continue } value[1] = strings.Replace(value[1], "<br />", "\n", -1) index := strconv.Itoa(i+1) file.Write([]byte("第"+index+"则段:\n"+value[1]+"\n\n\n")) i++ } ch <- n } func Spider(s, e int) { ch := make(chan int) for i := s; i <= e; i++ { go onespider(i, ch) } for i := s; i <= e; i++ { n := <- ch fmt.Printf("第%d页爬取完毕\n", n) } } func main(){ var start, end int fmt.Println("输入起始页") fmt.Scan(&start) fmt.Println("输入终止页") fmt.Scan(&end) Spider(start, end) }
运行截图:
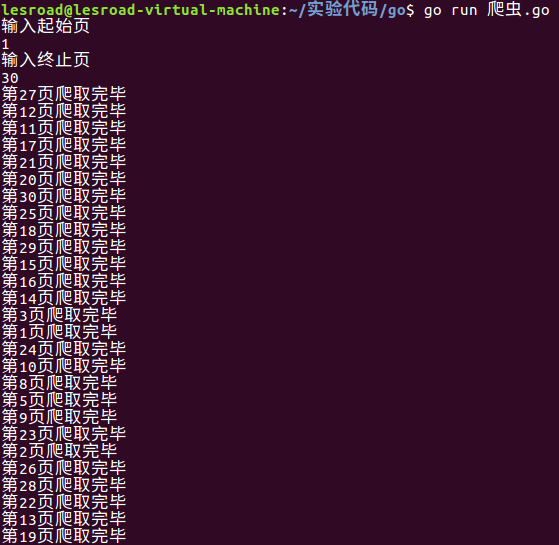
效果截图:
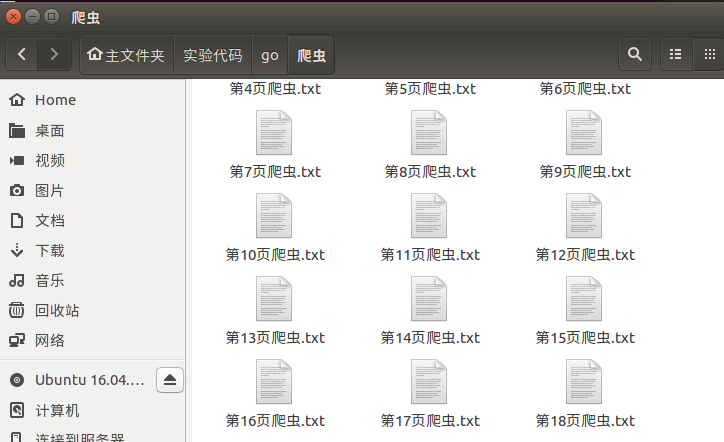
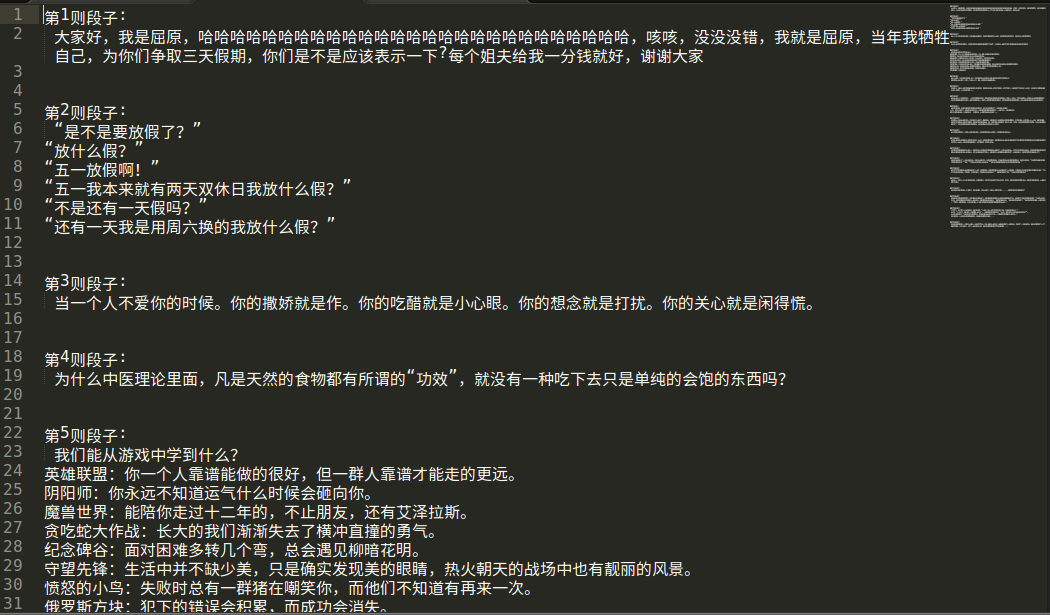
最后我发现第2页之后的段子都是重复的。。。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号