

Flask中的后端并发思考(以Mysql:too many connections为例)
之前写过一篇《CentOS 下部署Nginx+Gunicorn+Supervisor部署Flask项目》,最近对该工程的功能进行了完善,基本的功能单元测试也做了。
觉得也是时候进行一下压力测试了,所以利用Jmeter对部署到服务器的项目进行了简单的压力测试。在之前的笔记中写过,这个API的资源获取,为了不对数据库造成大量的读取压力,采用了Redis进行缓存,所以大量的GET方法下的接口都很坚挺,基本没有出乱子,但是在其中一个需要Log数据到Mysql的接口出问题了,具体表示是数据库插入失败。检查服务器上的Mysql日志发现,错误内容为:
ERROR 1040: Too many connections
想起来之前一篇笔记中遇到Mysql server has gone away的问题,其中一步是需要对数据库的time_out进行设置,所以自然而然,搜索这个问题的解决方案中,最初步的自然是增大mysql对于最大连接数的上限:
show variables like 'max_connections'; +-----------------+-------+ | Variable_name | Value | +-----------------+-------+ | max_connections | 151 | +-----------------+-------+ 1 row in set (0.00 sec)
然后对mysql的最大连接数进行修改来尝试解决问题。具体可见参考一。可是这个方法有两个问题:
1.最大连接数设置到多少比较合适?太大Mysql会占用服务资源。
2.极端高并发情况下,只是允许更大的连接,可是Mysql的I/O瓶颈还是会造成有些服务如果等待Mysql操作完成再返回很可能很久甚至超时。
考虑到我这个接口中,是存储日志,也就是大量写入Mysql数据而且无需校检。所以我决定采用异步来解决这个问题:
1.请求过来的时候先处理请求并立即返回给客户端
2.日志写入这个功能做成异步,也就是后台操作,考虑到高并发通常不会太持久,把日志写入的压力分散到后面的时间是比较可行的一个办法。
所以找到了这个异步操作的Python库Celery, 简单来说就是把耗时的操作丢给他去处理,Flask(或者说Gunicorn)不管这个操作而在处理完成请求之后直接返回。
对于为什么Flask应用一步步加上了Redis, 加上了Gunicorn(Gevent),到现在需要Celery, 我画了几张张图来理解。
一个典型的Flask应用(自带调试WSGI):
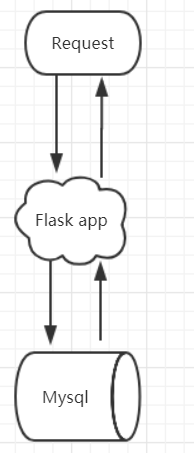
但是这个的问题在于他是阻塞的,每次请求过来没处理完没办法处理下一个请求!所以在调试的时候,会有提示你:
WARNING: Do not use the development server in a production environment.
Use a production WSGI server instead.
所以真正用的时候我们都要吧WSGI更换成Gunicorn, 利用服务器的多进程来达到并发,也就是同时处理多个请求。事实上,在利用了协成的Gevent后,每一个gunicorn的worker还可以处理多个请求:
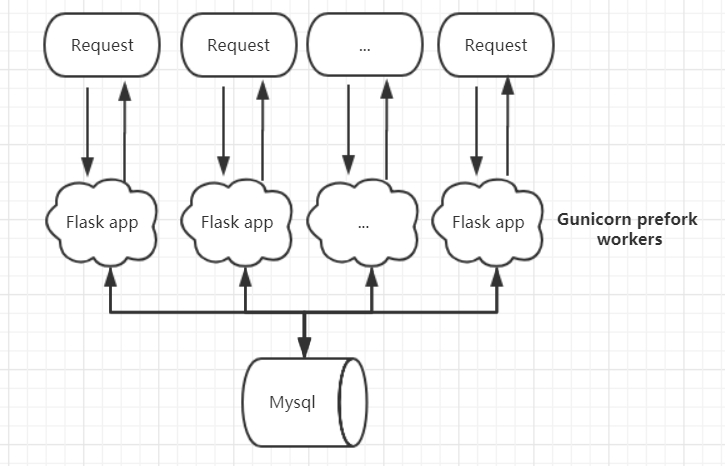
到这一步后的问题是每个worker都要去对mysql的资源进行处理,这就造成数据库压力大而且响应速度慢。所以我们就利用Redis来缓存常用的数据在内存中来达到加速资源访问的目的:
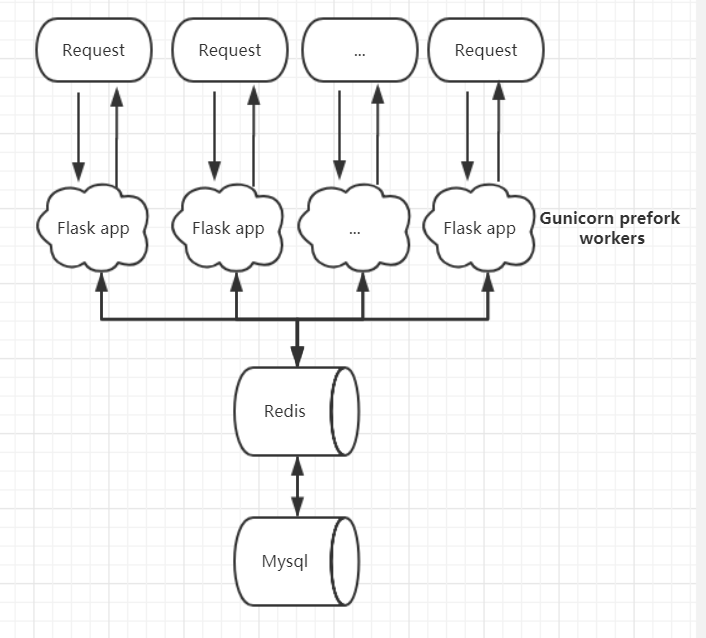
但是,今天的问题出来了,利用Redis达到了对资源缓存减轻数据库压力的目的,但是对Mysql的写入呢,每个worker 每个请求还是要直接写入数据库(比如我的api的Log),那么这个在高并发的时候就是个问题了。所以利用Celery,而celery本身不存储资源,他需要一个中间人来帮忙存储异步处理的数据,既然官方推荐也有Redis我自然就把redis作为中间人。也就是说Celery会以队列的形式,不断的从中间人那里拿到自己的任务并后台进行处理。
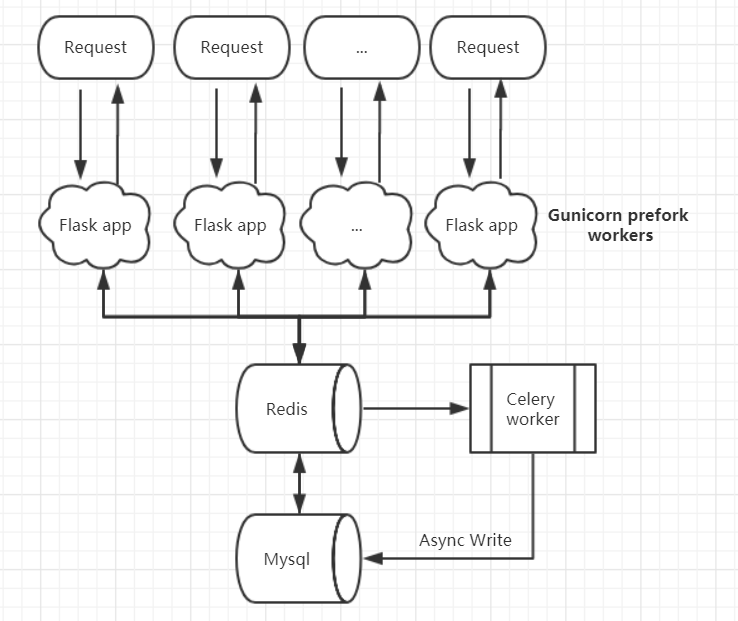
也就是说每次请求,如果还有对数据库的写入,那么我们把它延迟执行而不是等它执行完毕才返回给客户。这样子Flask就可以不断的接收新请求,而且通过对于延迟执行时间的调度,我们可以把高峰时间的写入请求压力分散到后续的时间中去。
总结起来:
1.Gunicorn和gevent保证了flask可以同时处理多个请求
2.利用Redis/Memecached 缓存可以减轻数据库的读取压力
2.但是如果请求耗时(比如大量的数据库插入,发送验证邮件等),你这个进程资源还是有被卡住的可能。
3.而利用Celery来后台处理耗时任务可以保证Flask能够较快响应而且不被阻塞,同时减轻了数据库的高峰写入压力。
注意:
1.Celery的worker和Gunicorn一样需要启动,可以与flask服务放在一起通过supervisor来管理,这样他们可以保持协同工作。
2.Windows的Celery只支持到3.1.25,所以你如果在windows上调试,请指定该版本。
3.如果你的后台任务是操作数据库,操作完成后记得释放数据库连接,例如Session.remove(Sqlalchemy scoped_session).
3.具体的操作步骤可见参考
参考:
1.https://bluemedora.com/mysql-performance-max-connections/

