


集群及Redis集群搭建
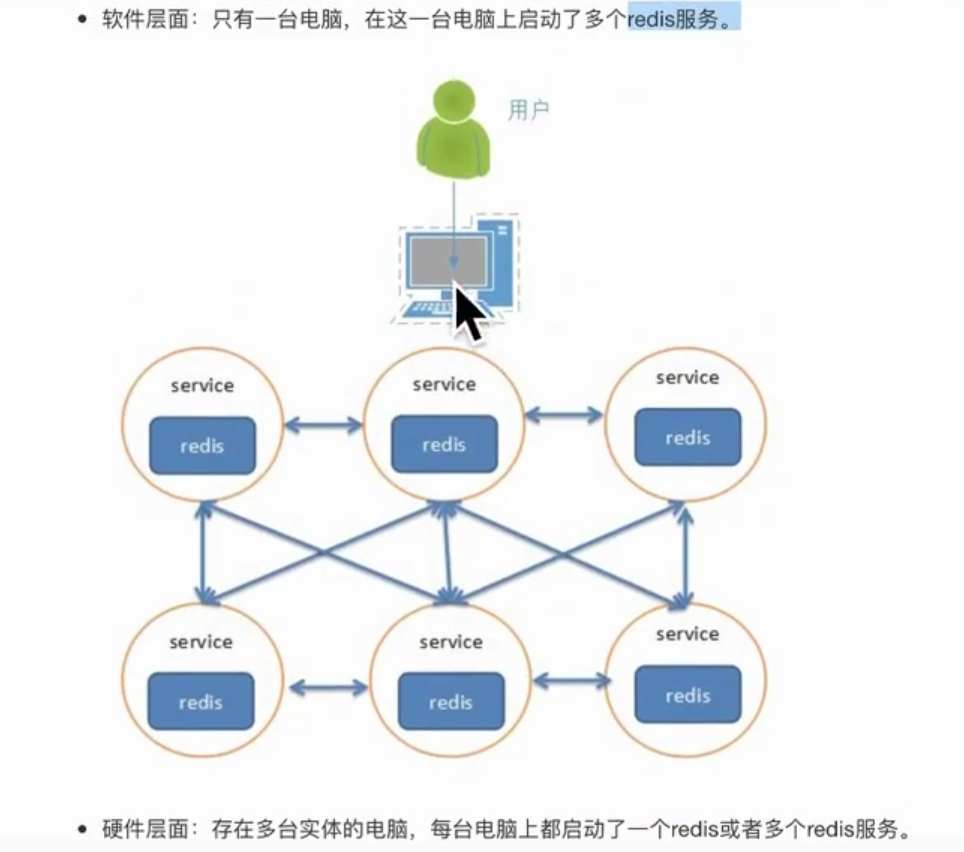
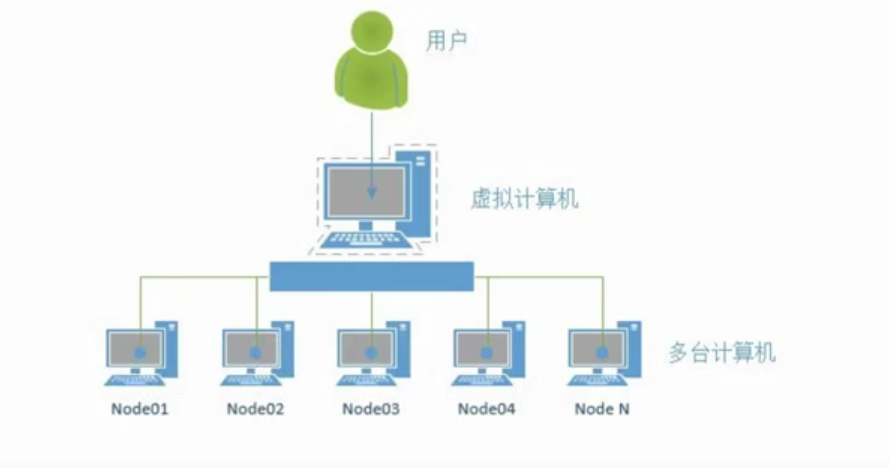
什么是集群
为什么要实现服务器集群
什么是服务器集群?
服务器集群就是指将很多服务器集中起来一起进行同一种服务,在客户端看来就像是只有一个服务器,集群可以利用多个计算机进行并行计算从而获得很高的计算速度,也可以用多个计算机做备份,从而使得任何一个机器坏了整个系统还是能正常运行。一旦在服务器上安装并运行了群集服务,该服务器即可加入群集。群集化操作可以减少单点故障数量,并且实现了群集化资源的高可用性。
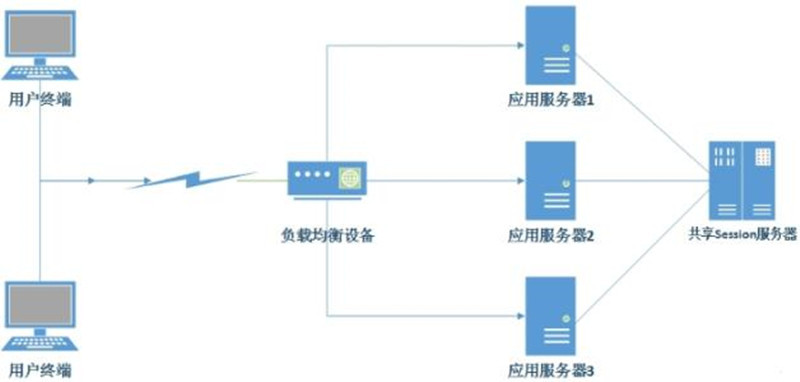
为什么要实现服务器集群?
实现服务器集群主要视为了负载均衡(有两台以上的服务器或者站点提供服务)服务器服务将来自客户端的请求,基于某种算法,尽量平分请求到集群的机器中,从而避免一台服务器因为在太高而出现故障,而即使其中某个机器出现故障,负载均衡会自动规避选择,使得用户也能正常访问服务。
Redis集群
Redis集群搭建
实际操作如下:
准备工作
版本:4.0.2
下载地址:https://redis.io/download
离线版本:(链接: https://pan.baidu.com/s/1bpwDtOr 密码: 4cxk)
源码编译:
wget http://download.redis.io/releases/redis-4.0.2.tar.gz
tar xzf redis-4.0.2.tar.gz
cd redis-4.0.2
make
//这步比较重要,否则会报:redis-server:command not found ,经过调试发现,我原来省略了第六步,我以为执行到Make命令,编译就可以了,不需要执行Make install命令,我以为Make install命令的作用就是拷贝redis的相关文件 //到/usr/local/bin这个目录下,原来不是,如果不执行,redis-server redis.conf 这个命令是不会执行的。
cd src
make install
注意:
首次安装需要安装gcc,通过如下命令安装
sudo apt-get install build-essential
在make时可能出现错误,error: jemalloc/jemalloc.h: No such file or directory,通过如下命令解决。
make MALLOC=libc
安装Redis-Cluster
安装Ruby
gem source -l --如果是https://rubygems.org 则需要更换为
gem source -a https://gems.ruby-china.com
sudo apt-get install ruby
安装Redis.gem
sudo gem install redis
要想开启Redis Cluster模式,有几项配置是必须的。此外为了方便使用和后续的测试,我还额外做了一些配置:
- 绑定地址:bind 192.168.XXX.XXX。不能绑定到127.0.0.1或localhost,否则指导客户端重定向时会报”Connection refused”的错误。
- 开启Cluster:cluster-enabled yes
- 集群配置文件:cluster-config-file nodes-7000.conf。这个配置文件不是要我们去配的,而是Redis运行时保存配置的文件,所以我们也不可以修改这个文件。
- 集群超时时间:cluster-node-timeout 15000。结点超时多久则认为它宕机了。
- 槽是否全覆盖:cluster-require-full-coverage no。默认是yes,只要有结点宕机导致16384个槽没全被覆盖,整个集群就全部停止服务,所以一定要改为no
- 后台运行:daemonize yes
- 输出日志:logfile “./redis.log”
- 监听端口:port 7000
安装过程
1. 下载并解压
cd /root/softwarewget http://download.redis.io/releases/redis-4.0.2.tar.gztar -zxvf redis-4.0.2.tar.gz 2. 编译安装
cd redis-3.2.4 make && make install
3. 将 redis-trib.rb 复制到 /usr/local/bin 目录下
cp /usr/local/redis/src/redis-trib.rb /usr/local/bin
4. 创建 Redis 节点
首先在 192.168.1.128 机器上 /root/software/redis-4.0.2 目录下创建 redis_cluster 目录;
mkdir redis_cluster
在 redis_cluster 目录下,创建名为7000、7001、7002的目录,并将 redis.conf 拷贝到这三个目录中
mkdir 7000 7001 7002
cp redis.conf redis_cluster/7000 cp redis.conf redis_cluster/7001 cp redis.conf redis_cluster/7002
分别修改这三个配置文件,修改如下内容

port 7000 //端口7000,7002,7003
bind 本机ip //默认ip为127.0.0.1 需要改为其他节点机器可访问的ip 否则创建集群时无法访问对应的端口,无法创建集群
daemonize yes //redis后台运行
pidfile /var/run/redis_7000.pid //pidfile文件对应7000,7001,7002
cluster-enabled yes //开启集群 把注释#去掉
cluster-config-file nodes_7000.conf //集群的配置 配置文件首次启动自动生成 7000,7001,7002
cluster-node-timeout 15000 //请求超时 默认15秒,可自行设置
appendonly yes //aof日志开启 有需要就开启,它会每次写操作都记录一条日志
- 接着在另外一台机器上(192.168.1.210),的操作重复以上三步,只是把目录改为7003、7004、7005,对应的配置文件也按照这个规则修改即可
5. 启动各个节点
第一台机器上执行
redis-server redis_cluster/7000/redis.conf
redis-server redis_cluster/7001/redis.conf
redis-server redis_cluster/7002/redis.conf
另外一台机器上执行
redis-server redis_cluster/7003/redis.conf
redis-server redis_cluster/7004/redis.conf
redis-server redis_cluster/7005/redis.conf
6. 检查 redis 启动情况
##一台机器<br>ps -ef | grep redis
root 61020 1 0 02:14 ? 00:00:01 redis-server 127.0.0.1:7000 [cluster]
root 61024 1 0 02:14 ? 00:00:01 redis-server 127.0.0.1:7001 [cluster]
root 61029 1 0 02:14 ? 00:00:01 redis-server 127.0.0.1:7002 [cluster]
netstat -tnlp | grep redis
tcp 0 0 127.0.0.1:17000 0.0.0.0:* LISTEN 61020/redis-server
tcp 0 0 127.0.0.1:17001 0.0.0.0:* LISTEN 61024/redis-server
tcp 0 0 127.0.0.1:17002 0.0.0.0:* LISTEN 61029/redis-server
tcp 0 0 127.0.0.1:7000 0.0.0.0:* LISTEN 61020/redis-server
tcp 0 0 127.0.0.1:7001 0.0.0.0:* LISTEN 61024/redis-server
tcp 0 0 127.0.0.1:7002 0.0.0.0:* LISTEN 61029/redis-server
##另外一台机器
ps -ef | grep redis
root 9957 1 0 02:32 ? 00:00:01 redis-server 127.0.0.1:7003 [cluster]
root 9964 1 0 02:32 ? 00:00:01 redis-server 127.0.0.1:7004 [cluster]
root 9971 1 0 02:32 ? 00:00:01 redis-server 127.0.0.1:7005 [cluster]
root 10065 4744 0 02:38 pts/0 00:00:00 grep --color=auto redis
netstat -tlnp | grep redis
tcp 0 0 127.0.0.1:17003 0.0.0.0:* LISTEN 9957/redis-server 1
tcp 0 0 127.0.0.1:17004 0.0.0.0:* LISTEN 9964/redis-server 1
tcp 0 0 127.0.0.1:17005 0.0.0.0:* LISTEN 9971/redis-server 1
tcp 0 0 127.0.0.1:7003 0.0.0.0:* LISTEN 9957/redis-server 1
tcp 0 0 127.0.0.1:7004 0.0.0.0:* LISTEN 9964/redis-server 1
tcp 0 0 127.0.0.1:7005 0.0.0.0:* LISTEN 9971/redis-server 1
7.创建集群
Redis 官方提供了 redis-trib.rb 这个工具,就在解压目录的 src 目录中,第三步中已将它复制到 /usr/local/bin 目录中,可以直接在命令行中使用了。使用下面这个命令即可完成安装。
旧版本:redis-trib.rb create --replicas 1 192.168.31.245:7000 192.168.31.245:7001 192.168.31.245:7002 192.168.31.210:7003 192.168.31.210:7004 192.168.31.210:7005
新版本:redis-cli --cluster create 192.168.1.128:7000 192.168.1.128:7001 192.168.1.128:7002 192.168.1.128:7003 192.168.1.128:7004 192.168.1.128:7005 --cluster-replicas 1
其中,前三个 ip:port 为第一台机器的节点,剩下三个为第二台机器。
等等,出错了。这个工具是用 ruby 实现的,所以需要安装 ruby。安装命令如下:
yum -y install ruby ruby-devel rubygems rpm-buildgem install redis
之后再运行 redis-trib.rb 命令,会出现如下提示:
输入 yes 即可,然后出现如下内容,说明安装成功。
root@ubuntu:/usr/local/bin# redis-cli --cluster create 192.168.1.128:7000 192.168.1.128:7001 192.168.1.128:7002 192.168.1.128:7003 192.168.1.128:7004 192.168.1.128:7005 --cluster-replicas 1
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 192.168.1.128:7004 to 192.168.1.128:7000
Adding replica 192.168.1.128:7005 to 192.168.1.128:7001
Adding replica 192.168.1.128:7003 to 192.168.1.128:7002
>>> Trying to optimize slaves allocation for anti-affinity
[WARNING] Some slaves are in the same host as their master
M: a7fc709d02b83ec867607c22d3c534be3e0000fb 192.168.1.128:7000
slots:[0-5460] (5461 slots) master
M: 70afa7458e4590fba639a78c825768177db31e18 192.168.1.128:7001
slots:[5461-10922] (5462 slots) master
M: 909df21251b0e20478bca733824be8e16c1b358e 192.168.1.128:7002
slots:[10923-16383] (5461 slots) master
S: 33acb0d4ad2807d6640c7561d49cd8d67abb0e2d 192.168.1.128:7003
replicates 70afa7458e4590fba639a78c825768177db31e18
S: 1b299135a4d8a32e40d617653ede06fab4e04883 192.168.1.128:7004
replicates 909df21251b0e20478bca733824be8e16c1b358e
S: a608c784ba53a56505bbf6a1f4a798b741fe2354 192.168.1.128:7005
replicates a7fc709d02b83ec867607c22d3c534be3e0000fb
Can I set the above configuration? (type 'yes' to accept): yes
8. 集群验证
在第一台机器上连接集群的7002端口的节点,在另外一台连接7005节点,连接方式为 redis-cli -h 192.168.1.128 -c -p 7002 ,加参数 -C 可连接到集群,因为上面 redis.conf 将 bind 改为了ip地址,所以 -h 参数不可以省略。
在7002节点执行命令 :
leslie@ubuntu:/usr/local/bin$ redis-cli -h 192.168.1.128 -c -p 7002
192.168.1.128:7002> set name "leslie"
-> Redirected to slot [5798] located at 192.168.1.128:7001
OK
192.168.1.128:7001>get name
"leslie"
然后在另外一台7002端口,查看 key 为 hello 的内容, get hello ,执行结果如下:

说明集群运作正常。
简单说一下原理
redis cluster在设计的时候,就考虑到了去中心化,去中间件,也就是说,集群中的每个节点都是平等的关系,都是对等的,每个节点都保存各自的数据和整个集群的状态。每个节点都和其他所有节点连接,而且这些连接保持活跃,这样就保证了我们只需要连接集群中的任意一个节点,就可以获取到其他节点的数据。
Redis 集群没有并使用传统的一致性哈希来分配数据,而是采用另外一种叫做哈希槽 (hash slot)的方式来分配的。redis cluster 默认分配了 16384 个slot,当我们set一个key 时,会用CRC16算法来取模得到所属的slot,然后将这个key 分到哈希槽区间的节点上,具体算法就是:CRC16(key) % 16384。所以我们在测试的时候看到set 和 get 的时候,直接跳转到了7000端口的节点。
Redis 集群会把数据存在一个 master 节点,然后在这个 master 和其对应的salve 之间进行数据同步。当读取数据时,也根据一致性哈希算法到对应的 master 节点获取数据。只有当一个master 挂掉之后,才会启动一个对应的 salve 节点,充当 master 。
需要注意的是:必须要3个或以上的主节点,否则在创建集群时会失败,并且当存活的主节点数小于总节点数的一半时,整个集群就无法提供服务了。
