面试准备——(二)专业知识(6)数据库
羽中总结;
索引 --》b树、b+树的区别
事务的隔离级别和对应解决的几种问题,mysql的默认事务隔离级别
手写sql语句(招银网络)(列出平均分大于80分的学生的信息
)
数据库范式
sql语句的执行顺序
如何对一行数据数据加锁
left join ,inner join
1. 索引
索引是一种数据结构,对数据库表中的一或多列的值进行排序,是为了帮助MYSQL高效获取数据。
优点:
- 大大加快了数据的检索速度
- 保证了数据的唯一性
- 加速了表与表之间的联系
- 在使用order by、group by子句进行数据索引的时候,可以显著减少时间
缺点:
- 索引需要占用物理内存
- 如果修改、增加、删除表中数据,索引也要动态维护。
索引的类型:
根据索引的功能,可以将索引划分为四类:普通索引、唯一索引、主键索引、聚集索引
2. 使用索引查询一定能提高查询的性能吗?为什么
不一定。通常通过索引查询数据比全表扫描要快,但是因为索引需要空间来存储,也需要动态维护,这意味着增、添、改三个操作会为此多付出4、5次I/O操作。所以,不必要的索引反而会时查询速度变慢。对于索引范围查询适用于两种情况:
- 基于一个范围的检索,一般查询返回结果集<表中记录数的30%
- 基于非唯一性索引
3. B树、B+树的区别
1. 相关术语:
结点的度(阶):含有子树的个数
树的度:所有结点最大的度
结点的层次/深度:从根节点开始,根为第一层,根的子结点为第二层,以此类推。
树的深度:一棵树中所有结点的层次的最大值。
结点的高度:从叶子结点开始,叶子结点作为1, 自底向上累加的
虽然结点的深度可能相同,但是它的高度不一定相同
2. B树
B树是平衡多路查找树,主要用于文件系统的索引。
1)定义:对于一个度数为d的B树,
- 每个结点最多有d个孩子
- 如果根结点不是叶子结点,那它至少有两个孩子
- 每个非叶子结点(非根结点)孩子:⎡d/2⎤<=n<=d 每个非叶子结点含有
n个关键字信息和n+1个指向孩子的指针
- ,[n, p0, k1, p1, k2,p2,...,kn,pn]:
- ki(i=1,...n)为关键字,且按升序排列,即:k(i-1)<k(i)
- pi(i=0,...,n)为指向子树根的指针,且p(i-1)指向子树中所有的关键字均小于k(i),都大于k(i-1)
- 每个叶子结点都在同一层,并且不包含任何关键字信息
例如:这是一个3阶B树,
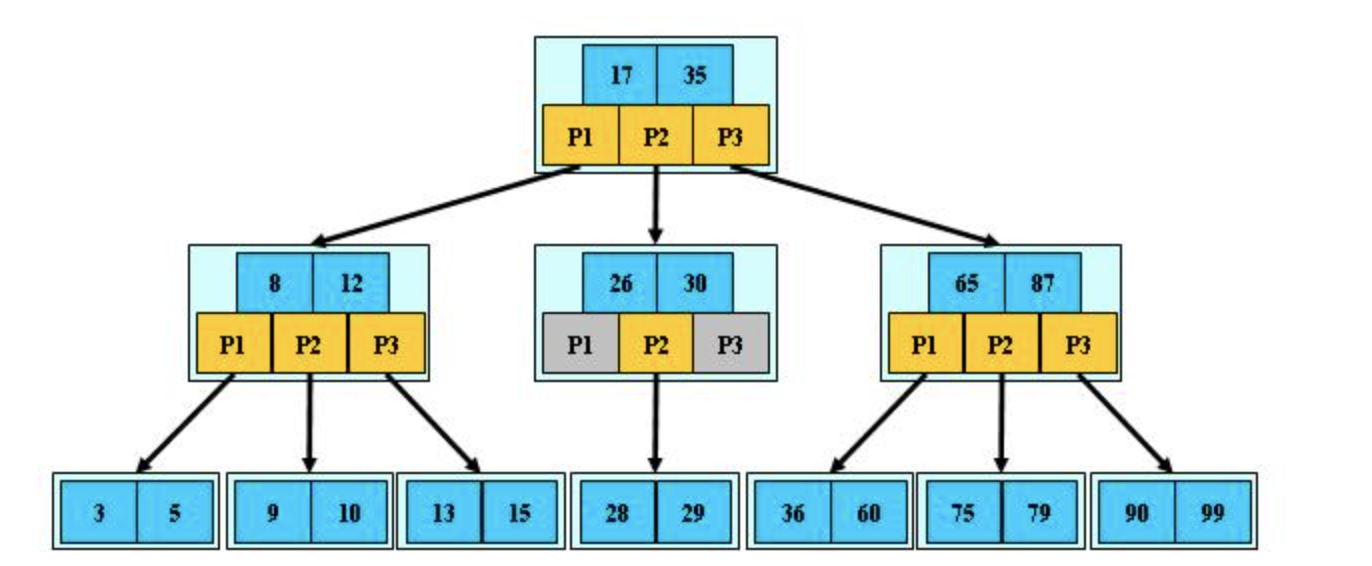
2)B树结点的代码实现
#define MAX 10 /*定义B树的最大阶数为10*/ typdef int KeyType /*KeyType为关键字类型*/ typedef struct BTNode{ int keynum; /*当前结点拥有的关键字数目*/ KeyType key[keynum+1]; /*key[0]不用,有keynum个关键字*/ struct BTNode *parent; struct BTNode *child[keynum+1]; /*孩子结点的指针:child[0, 1, ...., keynum]*/ }
3)B树的复杂度和高度
对于一个含有n个关键字,d阶B树,它的高度h<=log⎡d/2⎤((n+1)/2)+1
- 根为1个结点,他至少有两个孩子,也就是第二层至少有2个结点,
- 其余非叶子结点,至少有:⎡d/2⎤个结点,因此第三层至少有:2*⎡d/2⎤
- 以此类推:第四层至少有:2*⎡d/2⎤2 、第五层至少有:2*⎡d/2⎤3,...,第l层至少有:2*⎡d/2⎤l-2个结点
所以:
1+2+2*⎡d/2⎤+...+2*⎡d/2⎤h-2 <=n =>1+2*(1-2*⎡d/2⎤h-1)/(1-⎡d/2⎤)<=n =>1+2*(⎡d/2⎤-1)(2*⎡d/2⎤h-1-1)/(⎡d/2⎤-1)<=n 因为d>2 =>h<=log⎡d/2⎤((n+1)/2)+1
4)检索一个key,其查找结点个数的复杂度:O(logd(N))
3. B+树
与B树的不同之处:
1)内结点不存储数据,只存储指针,看做索引的一部分,结点中含有其子树根结点中最大(最小)关键字——B树的内结点包含了部分关键字信息
2)叶子结点包含了全部关键字信息,及指向含有这些关键字记录的指针,且叶子结点本身按照关键字从小到大的顺序链接。
通常在B+树上有两个头指针,一个指向根节点,一个指向关键字最小的叶子结点。
B树的查找过程:
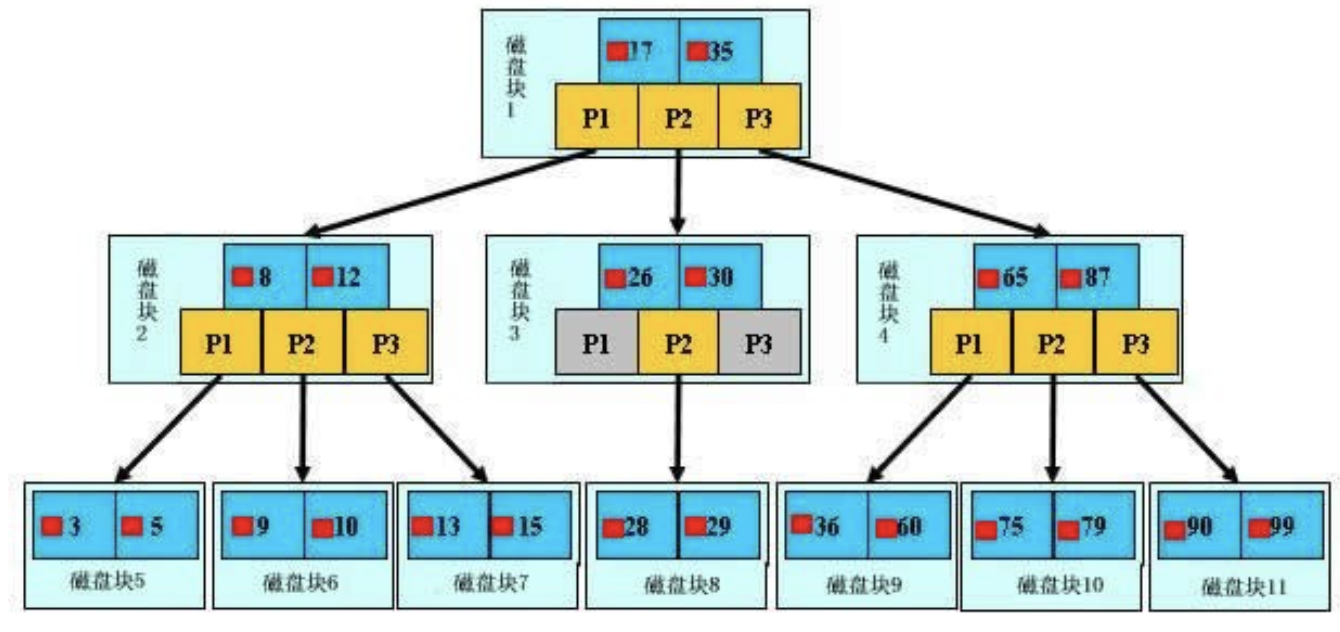
其中,浅蓝色的是磁盘块,其中存放了数据项和指针;例如:磁盘1包含了数据项:17,35,但是只是作为索引,而不是真的关键字,所有的关键字都包含在叶子结点。
例如:要查找29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO,29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询,总计三次IO。
B+树特性:
1. 内结点存放索引,关键字都存放在叶子结点。——每个磁盘盘存放数据量更多——减少IO次数
因为IO次数取决于B+树的高度h,假设当前数据表的数据为N,每个磁盘块的数据项的数量是m,则h=logm+1N。
2. 最左匹配原则。
当b+树的数据项是复合的数据结构,比如(name,age,sex)的时候,b+数是按照从左到右的顺序来建立搜索树的,比如当(张三,20,F)这样的数据来检索的时候,b+树会优先比较name来确定下一步的所搜方向,如果name相同再依次比较age和sex,最后得到检索的数据;但当(20,F)这样的没有name的数据来的时候,b+树就不知道下一步该查哪个节点,因为建立搜索树的时候name就是第一个比较因子,必须要先根据name来搜索才能知道下一步去哪里查询。比如当(张三,F)这样的数据来检索时,b+树可以用name来指定搜索方向,但下一个字段age的缺失,所以只能把名字等于张三的数据都找到,然后再匹配性别是F的数据了, 这个是非常重要的性质,即索引的最左匹配特性。
4. 事务,事务的隔离级别和对应解决的几种方法,MySql的默认事务隔离级别
1. 事务:是指作为单个逻辑工作单元执行的一系列操作,要么完全执行,要么完全不执行,是一个不可分隔的工作单位。事务是数据库系统维护数据一致性的单位,在每个事务结束时,都能保持数据的一致性。
事务的四个特性:ACID
- 原子性:是指事务所包含的操作要么全部成功,要么全部失败回滚
- 一致性:事务执行之前和执行之后都是一致性状态。
- 隔离性:多个并发事务相互隔离
- 持久性:一旦一个事务提交了,那么对数据库中的数据修改是持久的
2. 事务的隔离性:
当多个线程都开启事务操作数据库中的数据时,数据库系统要进行隔离操作,以保证各个线程获取数据的准确性。如果不考虑隔离性,会产生三个问题:
1)脏读:指在一个事务处理过程中读取了另一个未提交事务中的数据
2)不可重复读:对于数据库中某个数据,一个事务范围内多次查询却得到了不同的数据值,也就是在查询间隔,另一个事务提交了。(读取了前一个事务提交的数据)
3)幻读(虚读):幻读是事务非独立执行时发生的现象。
例如:事务T1对一个表中所有的行的某个数据项做了从“1”到“2”的更改,这时事务T2插入了一行,T1 就会发现还有一行没有修改。
幻读和不可重复读都是读取了另一条已经提交的事务(这点就脏读不同),所不同的是不可重复读查询的都是同一个数据项,而幻读针对的是一批数据整体(比如数据的个数)。
3. MySQL数据库为我们提供的四种隔离级别:
① Serializable (串行化):可避免脏读、不可重复读、幻读的发生。——级别最高,执行效率最低
② Repeatable read (可重复读):可避免脏读、不可重复读的发生。(MYSQL中默认)
③ Read committed (读已提交):可避免脏读的发生。
④ Read uncommitted (读未提交):最低级别,任何情况都无法保证。——级别最低,效率最高
另外:隔离级别的设置只对当前链接有效。
- 对于使用MySQL命令窗口而言,一个窗口就相当于一个链接,当前窗口设置的隔离级别只对当前窗口中的事务有效;
- 对于JDBC操作数据库来说,一个Connection对象相当于一个链接,而对于Connection对象设置的隔离级别只对该Connection对象有效,与其他链接Connection对象无关。
5. 数据库的乐观锁和悲观锁是什么?
数据库管理系统中的并发控制,是确保在多个事务同时存取数据库中的同一数据时,不会破坏事务的隔离性以及数据库的统一性。
乐观锁和悲观锁时并发控制中主要采用的技术手段。
乐观锁:假设不会发生并发冲突,只是在提交时检查是否违反数据的完整性。
悲观锁:假设会发生并发冲突,屏蔽一切可能违反数据库完整性的操作。
6. 数据库中的超键、候选键、主键、外键
超键:在关系中能唯一标识元组的属性集
候选键:能唯一的标志每个实体的属性或者属性组。(不含有多余属性的超键)
主键:在实体集中区分不同实体的候选码,一个实体集只能有一个主键,但是能有多个候选码。
外键:一个属性同时存在在表1和表2找那个,他不是表1的主键,是表2的主键,则可以称它是表1的外健键
例如,假设有如下两个表:
学生(学号,姓名,性别,身份证号,教师编号)
教师(教师编号,姓名,工资)
1. 超键:在学生表中,任何包含了学号、身份证号的属性集,都称作“超键”;任何包含了“教师编号”的属性集都称为“超键”
2. 候选键属于超键,它是最小的超键,就是说如果再去掉候选键中的任何一个属性它就不再是超键了。学生表中的候选键为:(学号)、(身份证号)。
3. 主键:从候选键中选择一个。例如:学号
4. 外键:教师编号在学生表中不是主键,但是在教师表中是主键,所以教师编号是外键。
7. 数据库的范式
范式:设计关系数据库的规范,越高的范式,数据库冗余度越小。
1. 第一范式1NF:所有关系数据库都满足
数据库表中的字段都是单一属性,不可分割。
2. 第二范式2NF:——必须满足1NF
在1NF基础上,要求实体的属性完全依赖于候选码(在1NF基础上消除非主属性对主码的部分函数依赖)
3. 第三范式3NF——是2NF子集,必须满足2NF
在1NF基础上,任何非主属性不依赖于其它非主属性(在2NF基础上消除传递依赖)
第三范式(3NF)要求一个关系中不包含已在其它关系中包含的非主关键字信息。
例如:存在一个部门信息表,其中每个部门有部门编号(dept_id)、部门名称、部门简介等信息。那么在员工信息表中列出部门编号后就不能再将部门名称、部门简介等与部门有关的信息再加入员工信息表中。如果不存在部门信息表,则根据第三范式(3NF)也应该构建它,否则就会有大量的数据冗余。
4. 巴斯-科德范式(BCNF)——是对3NF的修改
在1NF基础上,任何非主属性不能对主键子集依赖(在3NF基础上消除对主码子集的依赖)
举例:
1. 1NF:设计学生信息表:(学号,学生姓名、年龄、性别、课程、课程学分、系别、学科成绩,系办地址、系办电话)
2. 2NF:
原则:任何非主属性完全依赖于候选码。
最初的学生信息表,存在依赖:(学号,课程)——>(学生姓名,年龄,课程,系别)
因此不满足第二范式的要求,会产生如下问题:
1) 数据冗余:同一门课程由n个学生选修,"学分"就重复n-1次;同一个学生选修了m门课程,姓名和年龄就重复了m-1次。
2)更新异常:
- 若调整了某门课程的学分,数据表中所有行的"学分"值都要更新,否则会出现同一门课程学分不同的情况。
- 假设要开设一门新的课程,暂时还没有人选修。这样,由于还没有"学号"关键字,课程名称和学分也无法记录入数据库。
3)删除异常 :假设一批学生已经完成课程的选修,这些选修记录就应该从数据库表中删除。但是,与此同时,课程名称和学分信息也被删除了。很显然,这也会导致插入异常。
所以将表拆分为三个表:
- 学生:Student(学号,姓名,年龄,性别,系别,系办地址、系办电话);
- 课程:Course(课程名称,学分);
- 选课关系:SelectCourse(学号,课程名称,成绩)。
3. 3NF
原则:消除2NF上的传递依赖
接着看上面的学生表Student(学号,姓名,年龄,性别,系别,系办地址、系办电话),关键字为单一关键字"学号",因为存在如下决定关系:
(学号)→ (姓名,年龄,性别,系别,系办地址、系办电话
但是还存在下面的决定关系:
(学号) → (系别)→(系办地点,系办电话)
即存在非关键字段"系办地点"、"系办电话"对关键字段"学号"的传递函数依赖。
它也会存在数据冗余、更新异常、插入异常和删除异常的情况。
根据第三范式把学生关系表分为如下两个表就可以满足第三范式了:
学生:(学号,姓名,年龄,性别,系别);
系别:(系别,系办地址、系办电话)。
上面的数据库表就是符合I,Ⅱ,Ⅲ范式的,消除了数据冗余、更新异常、插入异常和删除异常。
8. SQL语句中:drop、delete、truncate
三个都是表示删除:
- 定义:drop和truncate表示删除表格的结构,delete是删除数据
- 速度:一般来说:drop>truncate>delete
- SQL语句类型:delete是dml数据操控语言,这个操作会放在rollback segment,事务提交以后才生效。如果有相应的触发器,执行的时候被触发;drop和truncate是ddl数据定义语言,操作立即生效,不会放在rollback segment,无法回滚,操作不触发触发器trigger。
drop
9.drop、delete与truncate分别在什么场景之下使用?
- drop:不再需要一张表的时候:比如删除一个索引:alter table drop index index_name
- truncate:保留表,只删除其中的数据
- delete:删除部分数据,加上where子句
10. 什么是视图?以及视图的使用场景
视图:是一张虚拟的表,通常是一个表或者多个表的行或列的子集,具有和物理表相同的功能。可以对视图进行增添查改,但是不会影响基本表,它使得我们获取数据更容易,相比于多表查询
适用场景:
- 只暴露部分数据给访问者,并且访问者的操作不会影响基本表数据
- 查询的数据来源于多个表,而查询者希望以统一的方式查询,建立一个视图,不必考虑数据来源于不同表的差异。
11. SQL语句的执行顺序
每个步骤都会产生一张虚拟表,该虚拟表作为下一步的输入。但是这些虚拟表队对调用者都是不可用的,直到最后一步才会返回给调用者。
(8)SELECT (9)DISTINCT (11)<Top Num> <select list> (1)FROM [left_table] (3)<join_type> JOIN <right_table> (2)ON <join_condition> (4)WHERE <where_condition> (5)GROUP BY <group_by_list> (6)WITH <CUBE | RollUP> (7)HAVING <having_condition> (10)ORDER BY <order_by_list>
逻辑查询处理阶段:
1. FROM:对FROM中的前两个表执行笛卡尔积(交叉联接)生成虚拟表VT1
2. ON:对VT1应用筛选器。只用对<join condition>为真的才能被插入VT2
3. OUTER(JOIN):
- left join:把左表作为保留表
- right join:把右表作为保留表
- full join:两个表都是保留
- inner join:至少又一个匹配才返回
把在保留表中未找到匹配的行将作为外部行插入到VT2中,生成VT3。
如果FROM中含有两个以上的表,则则对上一个联接生成的结果表和下一个表重复执行1~3操作,直到处理完所有的表。
4. WHERE:对VT3应用WHERE筛选器,只有使<where_condition>为true的行才被插入VT4。
5. GROUP BY:按GROUP BY子句中的列表对VT4行进行分组,生成VT5
6. CUBE|ROLLUP:把超组(Suppergroups)插入VT5,生成VT6。
7. HAVING:对VT6应用HAVING筛选器。只有使<having_condition>为true的组才会被插入VT7.
8. SELECT:处理SELECT列表生成VT8
9. DISTINCT:将重复咧从VT8中移除,生成VT9
10. ORDER BY:将VT9中的行按ORDER BY 子句中的列列表排序,生成游标(VC10).
11. TOP:从VC10的开始处选择指定数量或比例的行,生成表VT11,并返回调用者。
12. 比较 inner join、left join、right join

14. MyISAM和InnoDB
1. MyISAM 适合于一些需要大量查询的应用,但其对于有大量写操作并不是很好。甚至你只是需要update一个字段,整个表都会被锁起来,而别的进程,就算是读进程都无法操作直到读操作完成。另外,MyISAM 对于 SELECT COUNT(*) 这类的计算是超快无比的。
2. InnoDB 的趋势会是一个非常复杂的存储引擎,对于一些小的应用,它会比 MyISAM 还慢。他是它支持“行锁” ,于是在写操作比较多的时候,会更优秀。并且,他还支持更多的高级应用,比如:事务。
15. 什么是存储过程?有哪些优缺点?
存储过程就是一些预编译的T-SQL语句组成的代码块,这个代码块像一个方法一样实现一些功能(对单表的增添改查),给它一个名字,需要时调用它就行了。
优点:
- 由于数据库启动时,是先编译后执行。然而存储过程是一个编译过的代码段,所以执行效率高。
- 在网络交互时可以代替大量的T-SQl语句,所以也能降低网络的通信量,提高通信速率
- 通过存储过程能够使没有权限的用户在控制之下间接地存取数据库,从而确保数据的安全。
16. 手写SQL语句


 浙公网安备 33010602011771号
浙公网安备 33010602011771号