同步、异步、阻塞、非阻塞
同步与异步描述的是被调用者的
如果是同步,B在接到A的调用后,会立即执行要做的事。A的本次调用可以得到结果。
如果是异步,B在接到A的调用后,不保证会立即执行要做的事,但是保证会去做,B在做好了之后会通知A。A的本次调用得不到结果,但是B执行完之后会通知A。
阻塞与非阻塞描述的是调用者的
如果是阻塞,A在发出调用后,要一直等待,等着B返回结果。
如果是非阻塞,A在发出调用后,不需要等待,可以去做自己的事情。
同步不一定阻塞,异步也不一定非阻塞。没有必然关系。
举例
- 老张把水壶放到火上,一直在水壶旁等着水开。(同步阻塞)
- 老张把水壶放到火上,去客厅看电视,时不时去厨房看看水开没有。(同步非阻塞)
- 老张把响水壶放到火上,一直在水壶旁等着水开。(异步阻塞)
- 老张把响水壶放到火上,去客厅看电视,水壶响之前不再去看它了,响了再去拿壶。(异步非阻塞)
- 概要
- 1和2的区别是,调用方在得到返回之前所做的事情不一样,一个是等,一个是看电视
- 1和3的区别是,被调用方对于烧水的处理不一样。一个不会响,一个会响
IO
为了保护操作系统的安全,通过缓存加快系统读写,会将内存分为用户空间和内核空间两个部分。如果用户想要操作内核空间的数据,则需要把数据从内核空间拷贝到用户空间(数据会放到内核空间的page cache中,这种也叫缓存IO)。
客户端处理请求步骤
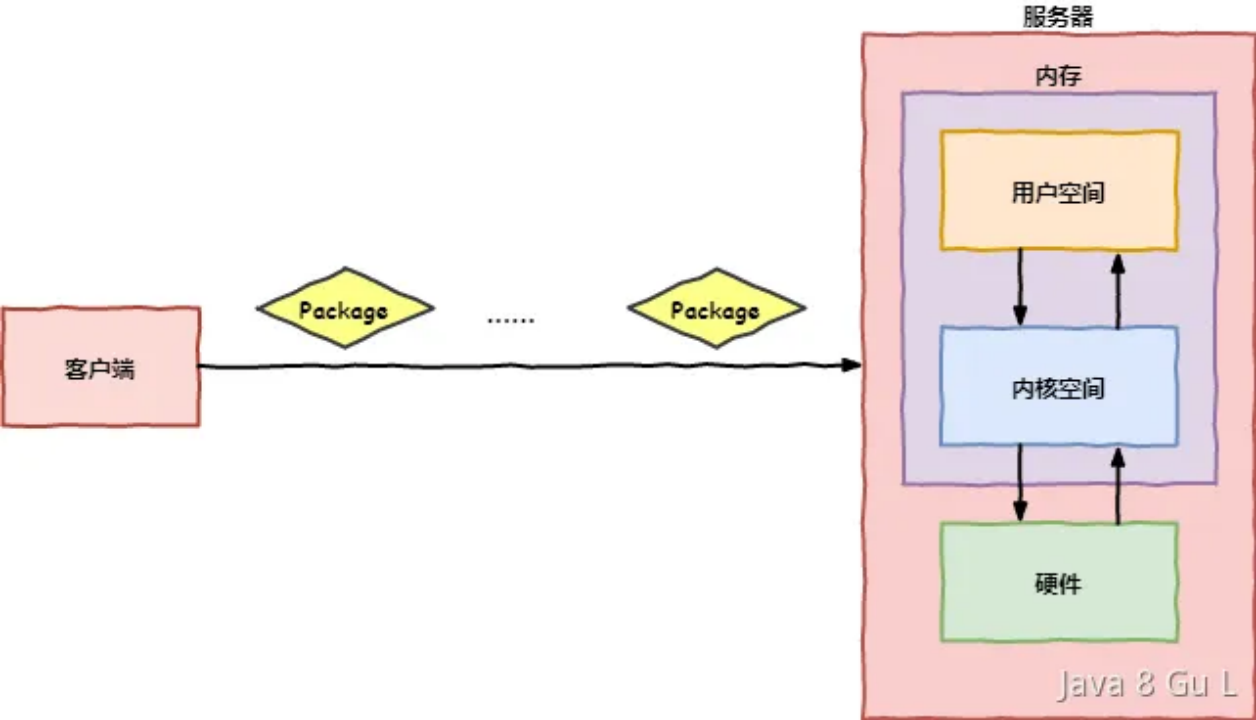
- 1、服务器的网络驱动接受到消息之后,向内核申请空间,并在收到完整的数据包(这个过程会产生延时,因为有可能是通过分组传送过来的)后,将其复制到内核空间;
- 2、数据从内核空间拷贝到用户空间;
- 3、用户程序进行处理。
linux读操作
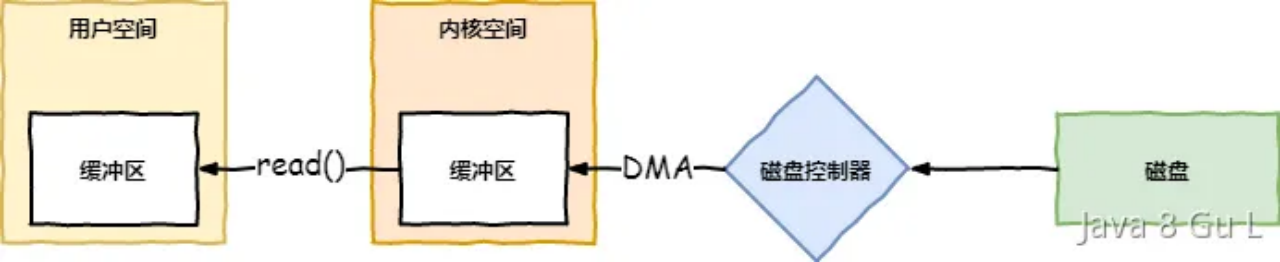
- 1、通过read系统调用,向内核发送读请求
- 2、内核向硬件发送读指令,并等待读就绪
- 3、DMA把将要读取的数据复制到指定的内核缓存区中
- 4、内核将数据从内核缓存区拷贝到用户进程空间中
由此诞生了5种IO方式
同步阻塞型IO模型
同步非阻塞型IO模型
- 在这里recv不管有没有获得到数据都返回,如果没有数据的话就过段时间再调用recv看看,如此循环
IO复用模型
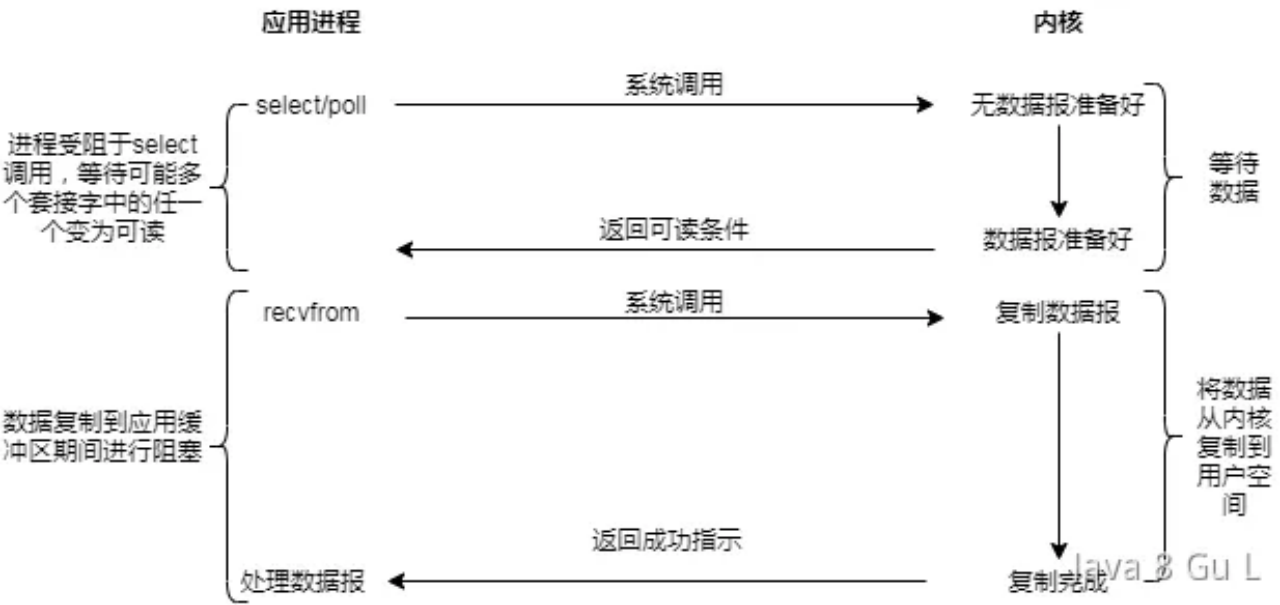
- 调用recv之前会先调用select或poll,这两个系统调用都可以在内核准备好数据(网络数据已经到达内核了)时告知用户进程,它准备好了,这时候再调用recv时是一定有数据的。因此在这一模型中,进程阻塞于select或poll,而没有阻塞在recv上
- 就相当于,小J来银行办理业务,大堂经理告诉他现在所有柜台都有人在办理业务,等有空位再告诉他。于是小J就等啊等(select或poll调用中),过了一会儿大堂经理告诉他有柜台空出来可以办理业务了,但是具体是几号柜台,你自己找下吧,于是小J就只能挨个柜台地找。
- select、poll、epoll
- select
- 是最原始的 I/O 多路复用技术,几乎在所有的平台中都支持,它的缺点是最多只能监听 1024 个文件描述符
- select函数可以监听read,write,except的fd。当select返回后,可以遍历对应的fd_set来寻找就绪的fd,从而进行业务处理
- 包含大量fd的数组被整体复制于用户态和内核的地址空间之间,而不论这些文件描述符是否就绪,其开销也随着文件描述符数量增加而线性增大
- poll
- 在 select 的基础上增加了支持监听更多的文件描述符的能力,但是复杂度随着监听的文件描述符数量的增加而增加
- 同select一样,poll返回后,也是需要轮询pollfd来获取就绪的fd。不仅如此,所有的fds也是在内核态和用户态中来回切换,也会影响效率
- 但是因为fds基于链表,所以就没有了最长1024的限制
- epoll
- 在 poll 的基础上进一步优化了复杂度,可以支持更多的文件描述符,并且具有更高的效率
- 每次注册新的事件调用epoll_ctl时,epoll会把所有的fd拷贝进内核,而不是在epoll_wait的时候重复拷贝。epoll保证了每个fd在整个过程中只会拷贝一次。
- epoll会通过epoll_wait查看是否有就绪的fd,如果有就绪的fd,就会直接使用(O(1))。而不是像之前两个一样,每次需要手动遍历才能得到就绪的fd(O(n))
- epoll是通过epoll_wait来获取就绪的fd,那么如果就绪的fd一直没有被消费,该如何处理呢?
- LT(level trigger)(默认)模式
- 当epoll_wait检测到描述符事件发生并将此事件通知应用程序,应用程序可以不立即处理该事件。下次调用epoll_wait时,会再次响应应用程序并通知此事件
- ET(edge trigger)模式
- 当epoll_wait检测到描述符事件发生并将此事件通知应用程序,应用程序必须立即处理该事件。如果不处理,下次调用epoll_wait时,不会再次响应应用程序并通知此事件。
信号驱动模型
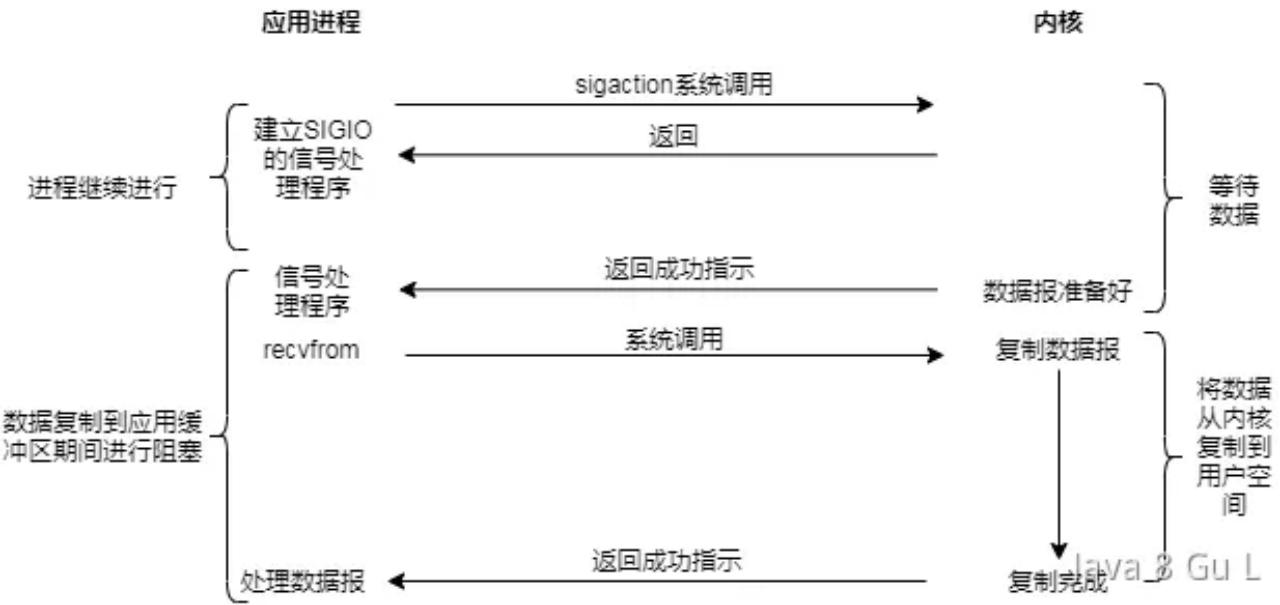
- 此处会通过调用sigaction注册信号函数,在内核数据准备好的时候系统就中断当前程序,执行信号函数(在这里调用recv)
- 小J让大堂经理在柜台有空位的时候通知他(注册信号函数),等没多久大堂经理通知他,因为他是银行的VIPPP会员,所以专门给他开了一个柜台来办理业务,小J就去特席柜台办理业务了。但即使在等待的过程中是非阻塞的,但在办理业务的过程中依然是同步的。
异步IO模型
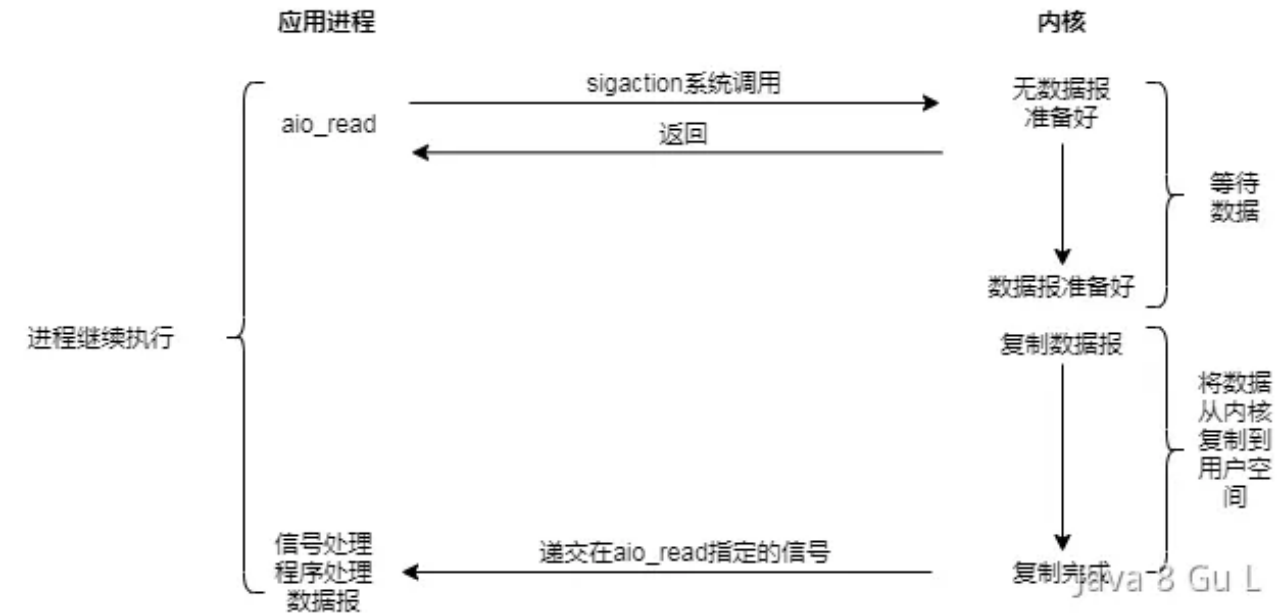
- 调用aio_read令内核把数据准备好,并且复制到用户进程空间后执行事先指定好的函数
- 小J交代大堂经理把业务给办理好了就通知他来验收,在这个过程中小J可以去做自己的事情。这就是真正的异步IO。
零拷贝
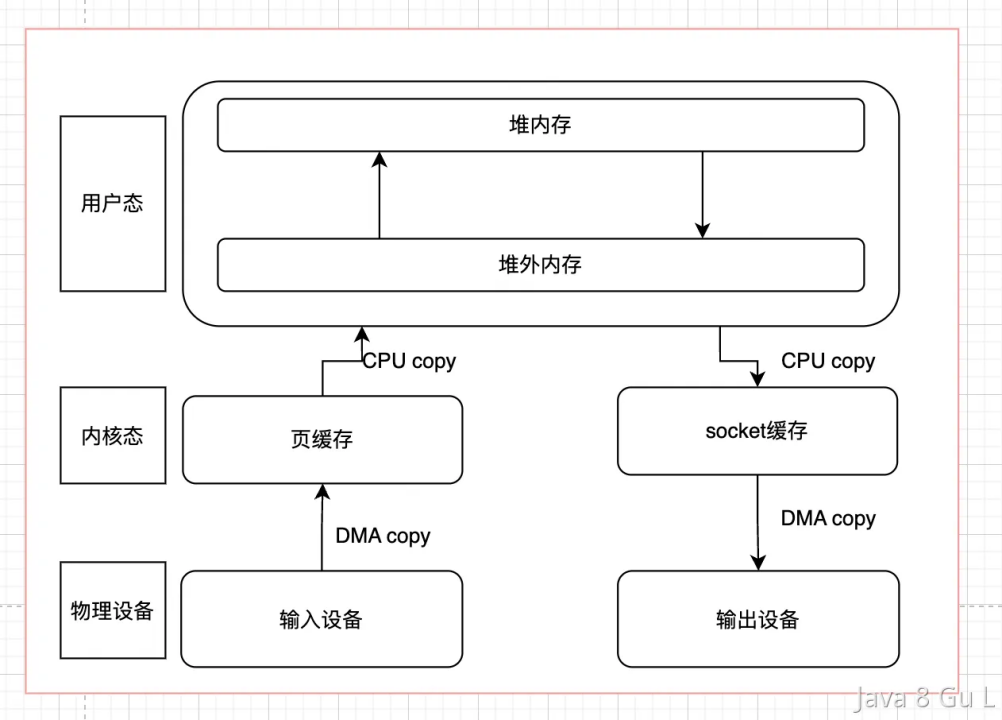
- 如果不考虑用户态的内存拷贝和物理设备到驱动的数据拷贝,我们会发现,这其中会涉及4次数据拷贝。同时也会涉及到4次进程上下文的切换
- 对于Java程序,还会多了一个堆外内存和堆内存之间的copy
所谓的零拷贝,作用就是通过各种方式,在特殊情况下,减少数据拷贝的次数/减少CPU参与数据拷贝的次数
常见的零拷贝方式有mmap,sendfile,dma,directI/O等
扩展
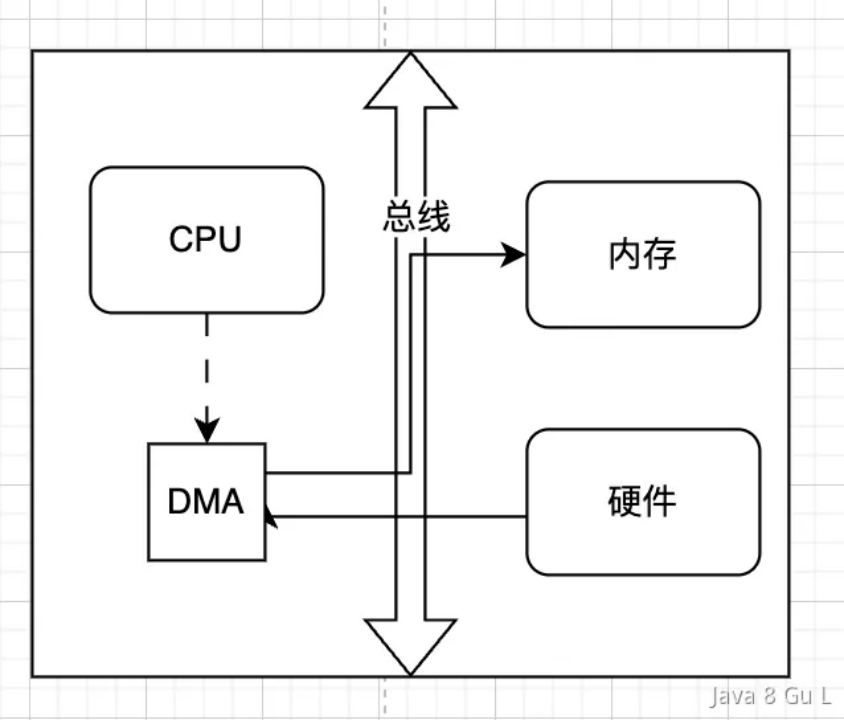
- DMA
- 正常的IO流程中,不管是物理设备之间的数据拷贝,如磁盘到内存,还是内存之间的数据拷贝,如用户态到内核态,都是需要CPU参与的
-
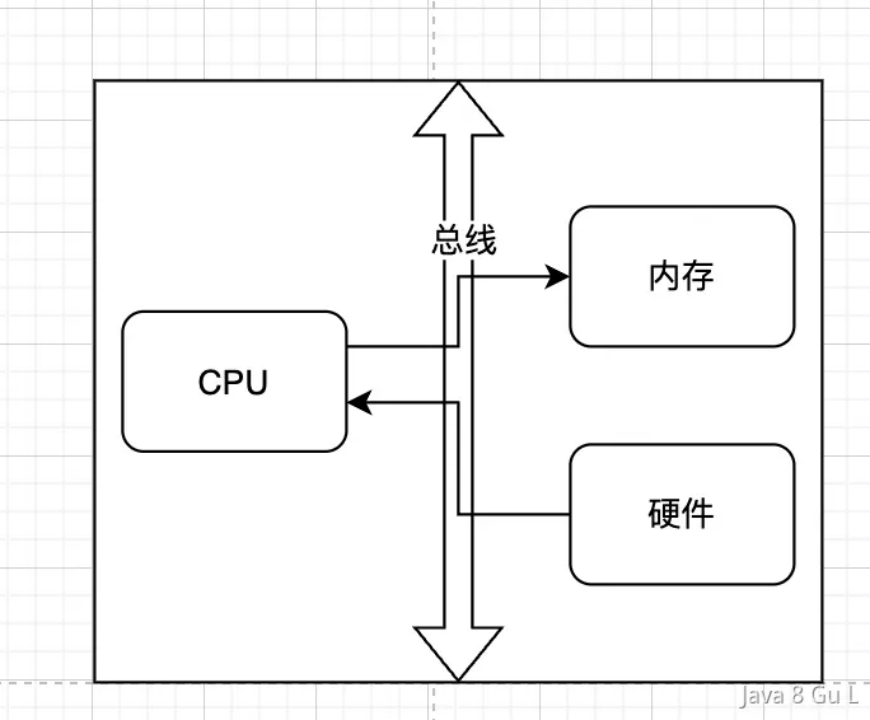
- 如果是比较大的文件,这样无意义的copy显然会极大的浪费CPU的效率,所以就诞生了DMA
- DMA的全称是Direct Memory Access,顾名思义,DMA的作用就是直接将IO设备的数据拷贝到内核缓冲区中。使用DMA的好处就是IO设备到内核之间的数据拷贝不需要CPU的参与,CPU只需要给DMA发送copy指令即可,提高了处理器的利用效率
-
- mmap
- mmap,全称是memory map,翻译过来就是内存映射,顾名思义,就是将内核态和用户态的内存映射到一起,避免来回拷贝
-
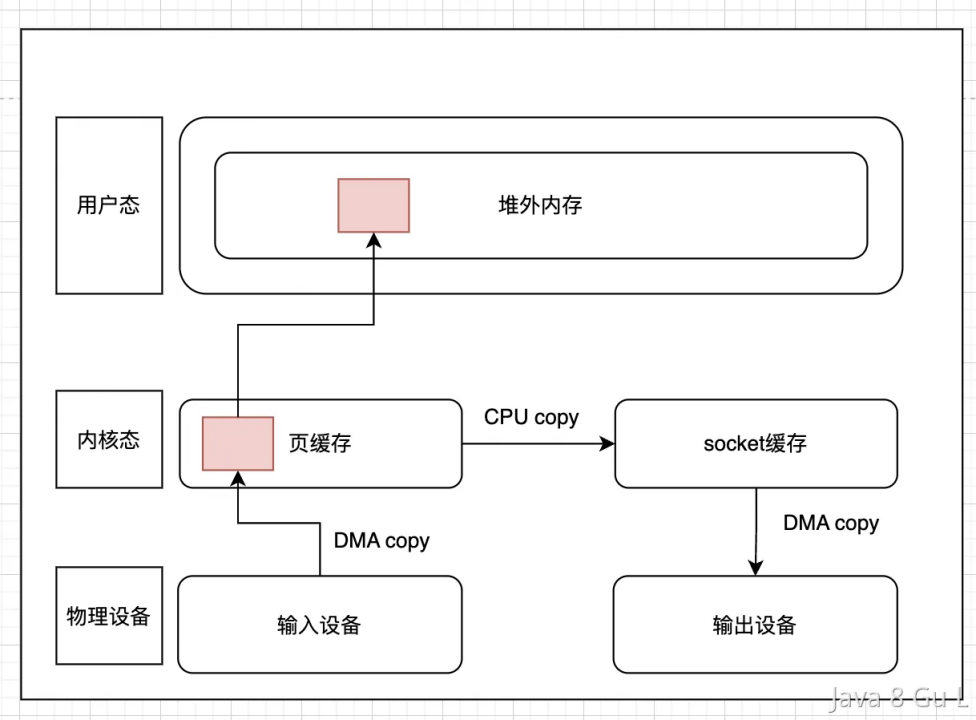
- 采用mmap + write的方式,内存拷贝的次数会变为3次,上下文切换则依旧是4次。
- 问题
- mmap 使用时必须实现指定好内存映射的大小,因此 mmap 并不适合变长文件;
- 因为mmap在文件更新后会通过OS自动将脏页回写到disk中,所以在随机写很多的情况下,mmap 方式在效率上不一定会比带缓冲区的一般写快
- 因为mmap必须要在内存中找到一块连续的地址块,如果在 32-bits 的操作系统上,虚拟内存总大小也就 2GB左右(32位系统的地址空间最大为4G,除去1G系统,用户能使用的内存最多为3G左右(windows内核较大,一般用户只剩下2G可用)。),此时就很难对 4GB 大小的文件完全进行 mmap,所以对于超大文件来讲,mmap并不适合
- sendfile
- 如果只是传输数据,并不对数据作任何处理,可以通过sendfile的方式,只做文件传输,而不通过用户态进行干预
-
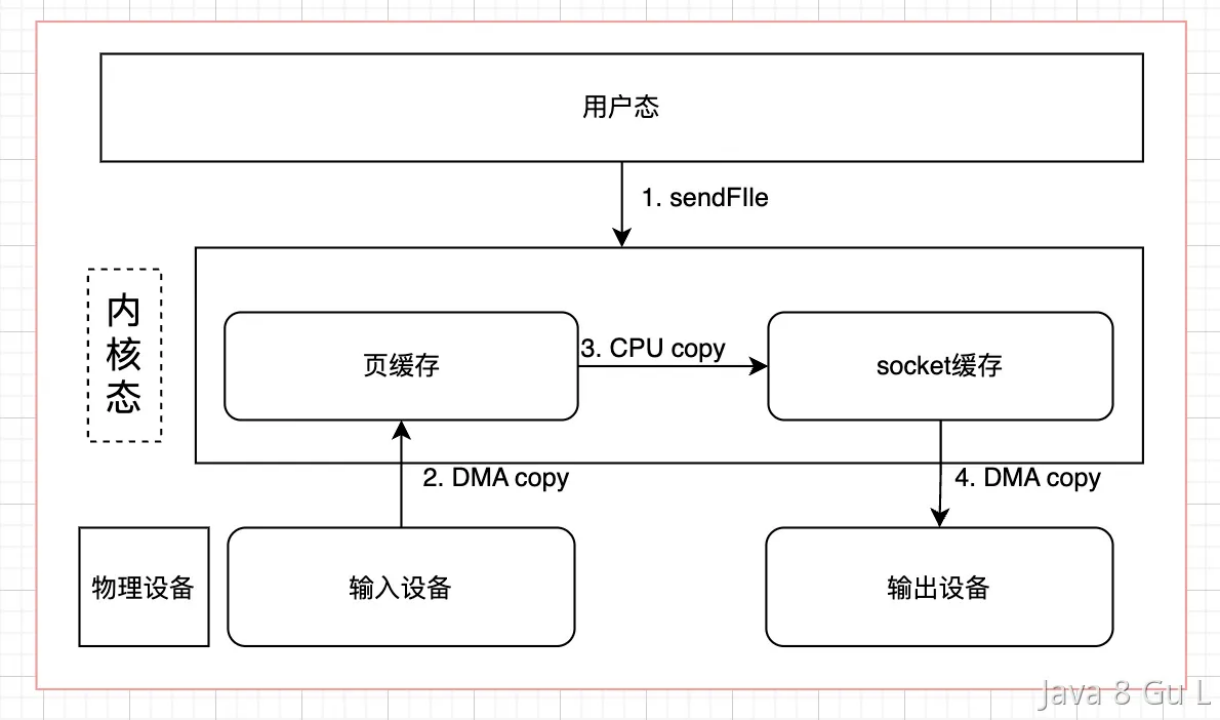
- 为什么内核要拷贝两次(page cache -> socket cache),能不能省略这个步骤?
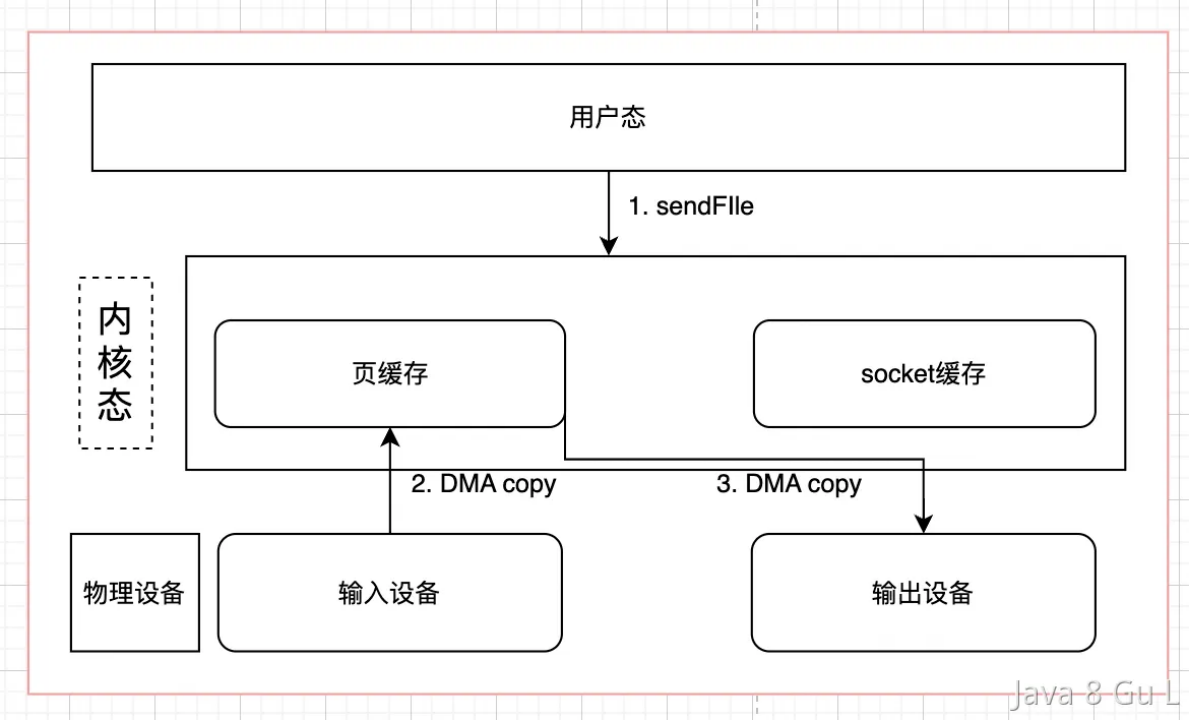
- sendfile + DMA Scatter/Gather
- DMA gather是LInux2.4新引入的功能,它可以读page cache中的数据描述信息(内存地址和偏移量)记录到socket cache中,由 DMA 根据这些将数据从读缓冲区拷贝到网卡,相比之前版本减少了一次CPU拷贝的过程
-
- direct I/O
- 之前的mmap可以让用户态和内核态共用一个内存空间来减少拷贝,其实还有一个方式,就是硬件数据不经过内核态的空间,直接到用户态的内存中,这种方式就是Direct I/O。换句话说,Direct I/O不会经过内核态,而是用户态和设备的直接交互,用户态的写入就是直接写入到磁盘,不会再经过操作系统刷盘处理。
- 这样确实拷贝次数减少,读取速度会变快,但是因为操作系统不再负责缓存之类的管理,这就必须交由应用程序自己去做,譬如MySql就是自己通过Direct I/O完成的,同时MySql也有一套自己的缓存系统
- 同时,虽然direct I/O可以直接将文件写入磁盘中,但是文件相关的元信息还是要通过fsync缓存到内核空间中
posted @
2024-03-15 13:45
梦醒点灯
阅读(
50)
评论()
收藏
举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号