DotnetSpider5 爬博客园新闻
只要是爬虫必须爬一下博客园.不知道为什么反正都这样..就跟hello world一样吧
DotnetSpider 是非常优秀的爬虫框架.无论扩展性 易用性 可读性. 已经跳进作者的坑4次了..DotnetSpider 现在版本是5 我是从2开始用的 最近打算跳入新坑
版本5的文档 https://github.com/dotnetcore/DotnetSpider/wiki
爬博客园其实作者是提供了Sample 不过比较简单
我这边为了跳新坑 重新改了下 对接了mysql
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 | public class CnblogsSpider : Spider { public static async Task RunAsync() { var builder = Builder.CreateDefaultBuilder<CnblogsSpider>(); builder.UseSerilog(); builder.UseQueueDistinctBfsScheduler<HashSetDuplicateRemover>(); await builder.Build().RunAsync(); } public CnblogsSpider(IOptions<SpiderOptions> options, SpiderServices services, ILogger<Spider> logger) : base( options, services, logger) { } protected override async Task InitializeAsync(CancellationToken stoppingToken) { await AddRequestsAsync(new Request("https://news.cnblogs.com/n/666228/")); await AddRequestsAsync(new Request("https://news.cnblogs.com/n/page/1/")); AddDataFlow(new ListNewsParser()); AddDataFlow(new MysqlNewStorage()); } protected override (string Id, string Name) GetIdAndName() { return (Guid.NewGuid().ToString(), "cnblogs"); } protected class MysqlNewStorage : StorageBase { public override async Task InitAsync() { await using var conn = new MySqlConnection(AppConfig.Configuration.GetConnectionString("Default")); //await conn.ExecuteAsync("create database if not exists cnblogs2;"); await conn.ExecuteAsync($@"create table if not exists article( id int auto_increment primary key, title varchar(500) not null, sContent varchar(2000) null);"); } protected override async Task StoreAsync(DataContext context) { var typeName = typeof(Article).FullName; var data = (Article)context.GetData(typeName); if (data != null && data is Article news) { await using var conn = new MySqlConnection(AppConfig.Configuration.GetConnectionString("Default")); var icount = conn.Query<int>($"SELECT count(id) FROM article WHERE title = '{data.Title}'").FirstOrDefault(); if (icount <= 0) { await conn.ExecuteAsync( $"INSERT IGNORE INTO article (title, sContent) VALUES (@Title,@SContent);", data); } } } } protected class ListNewsParser : DataParser { public ListNewsParser() { // AddRequiredValidator("news\\.cnblogs\\.com/n/page"); AddRequiredValidator(request => { return Regex.IsMatch(request.RequestUri.ToString(), "news.cnblogs.com"); }); AddFollowRequestQuerier(Selectors.XPath(".")); //AddRequiredValidator("cnblogs.com"); // if you want to collect every pages // AddFollowRequestQuerier(Selectors.XPath(".//div[@class='pager']")); } protected override Task Parse(DataContext context) { //var newsList = context.Selectable.SelectList(Selectors.XPath(".//div[@class='news_block']")); //if (newsList != null) //{ // foreach (var news in newsList) // { // var title = news.Select(Selectors.XPath(".//h2[@class='news_entry']"))?.Value; // var url = news.Select(Selectors.XPath(".//h2[@class='news_entry']/a/@href"))?.Value; // //var summary = news.Select(Selectors.XPath(".//div[@class='entry_summary']"))?.Value; // //var views = news.Select(Selectors.XPath(".//span[@class='view']"))?.Value.Replace(" 人浏览", ""); // if (!string.IsNullOrWhiteSpace(url)) // { // var request = context.CreateNewRequest(url); // //request.SetProperty("title", title); // //request.SetProperty("url", url); // //request.SetProperty("summary", summary); // //request.SetProperty("views", views); // context.AddFollowRequests(request); // } // } //} //var request = context.CreateNewRequest("http://baidu.com//"); //context.AddFollowRequests(request); var news_content = context.Selectable.Select(Selectors.XPath(".//div[@id='news_main']")); if (news_content != null) { var title = news_content.Select(Selectors.XPath(".//div[@id='news_title']"))?.Value; var content = news_content.Select(Selectors.XPath(".//div[@id='news_content']"))?.Value; var typeName = typeof(Article).FullName; context.AddData(typeName, new Article { Title = title.Trim(), SContent = content.Trim(), //Summary = context.Request.Properties["summary"]?.Trim(), //Views = int.Parse(context.Request.Properties["views"]), //Content = context.Selectable.Select(Selectors.XPath(".//div[@id='news_body']")).Value?.Trim() } ); } return Task.CompletedTask; } } public class Article { public string Title { get; set; } public string SContent { get; set; } } } |
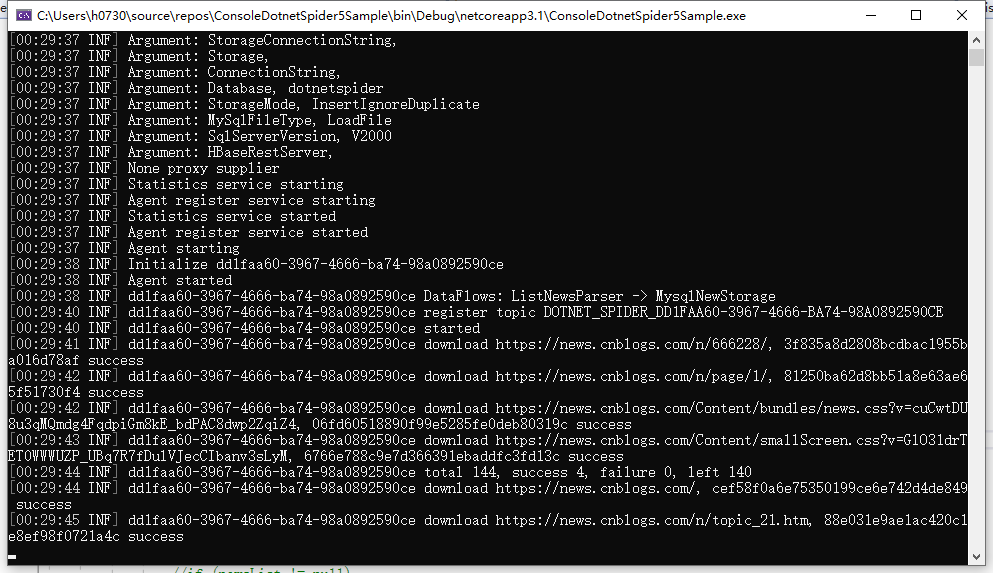
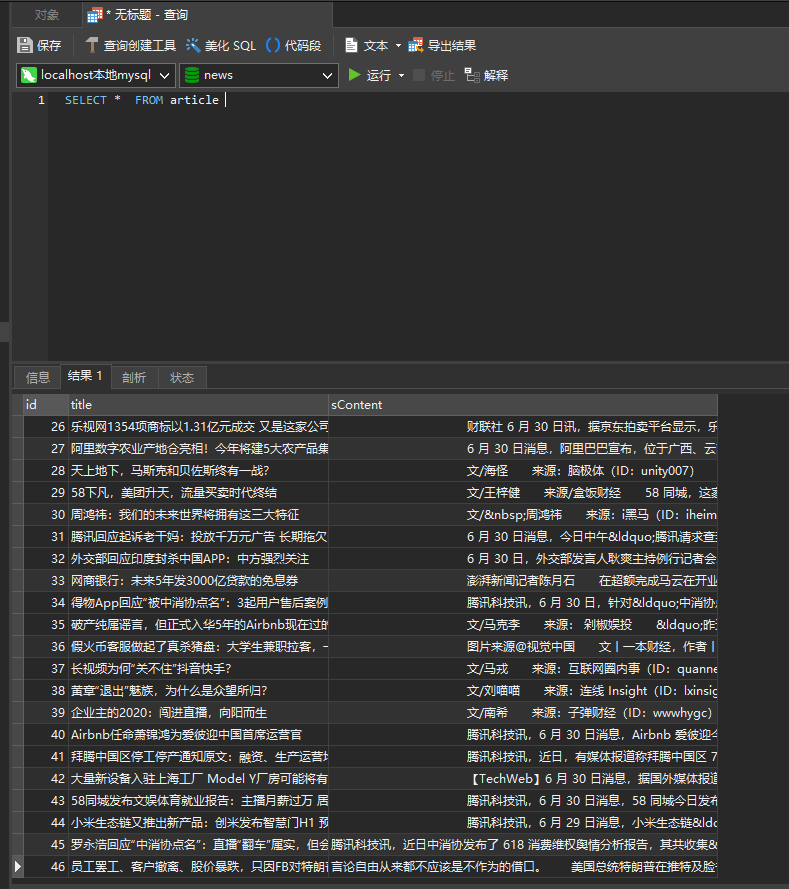
源码(https://files.cnblogs.com/files/leoxjy/ConsoleDotnetSpider5Sample.zip)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?