算法杂货铺——分类算法之贝叶斯网络(Bayesian networks)
2010-09-18 22:50 T2噬菌体 阅读(122186) 评论(25) 编辑 收藏 举报 在上一篇文章中我们讨论了朴素贝叶斯分类。朴素贝叶斯分类有一个限制条件,就是特征属性必须有条件独立或基本独立(实际上在现实应用中几乎不可能做到完全独立)。当这个条件成立时,朴素贝叶斯分类法的准确率是最高的,但不幸的是,现实中各个特征属性间往往并不条件独立,而是具有较强的相关性,这样就限制了朴素贝叶斯分类的能力。这一篇文章中,我们接着上一篇文章的例子,讨论贝叶斯分类中更高级、应用范围更广的一种算法——贝叶斯网络(又称贝叶斯信念网络或信念网络)。
在上一篇文章中我们讨论了朴素贝叶斯分类。朴素贝叶斯分类有一个限制条件,就是特征属性必须有条件独立或基本独立(实际上在现实应用中几乎不可能做到完全独立)。当这个条件成立时,朴素贝叶斯分类法的准确率是最高的,但不幸的是,现实中各个特征属性间往往并不条件独立,而是具有较强的相关性,这样就限制了朴素贝叶斯分类的能力。这一篇文章中,我们接着上一篇文章的例子,讨论贝叶斯分类中更高级、应用范围更广的一种算法——贝叶斯网络(又称贝叶斯信念网络或信念网络)。
2.1、摘要
在上一篇文章中我们讨论了朴素贝叶斯分类。朴素贝叶斯分类有一个限制条件,就是特征属性必须有条件独立或基本独立(实际上在现实应用中几乎不可能做到完全独立)。当这个条件成立时,朴素贝叶斯分类法的准确率是最高的,但不幸的是,现实中各个特征属性间往往并不条件独立,而是具有较强的相关性,这样就限制了朴素贝叶斯分类的能力。这一篇文章中,我们接着上一篇文章的例子,讨论贝叶斯分类中更高级、应用范围更广的一种算法——贝叶斯网络(又称贝叶斯信念网络或信念网络)。
2.2、重新考虑上一篇的例子
上一篇文章我们使用朴素贝叶斯分类实现了SNS社区中不真实账号的检测。在那个解决方案中,我做了如下假设:
i、真实账号比非真实账号平均具有更大的日志密度、各大的好友密度以及更多的使用真实头像。
ii、日志密度、好友密度和是否使用真实头像在账号真实性给定的条件下是独立的。
但是,上述第二条假设很可能并不成立。一般来说,好友密度除了与账号是否真实有关,还与是否有真实头像有关,因为真实的头像会吸引更多人加其为好友。因此,我们为了获取更准确的分类,可以将假设修改如下:
i、真实账号比非真实账号平均具有更大的日志密度、各大的好友密度以及更多的使用真实头像。
ii、日志密度与好友密度、日志密度与是否使用真实头像在账号真实性给定的条件下是独立的。
iii、使用真实头像的用户比使用非真实头像的用户平均有更大的好友密度。
上述假设更接近实际情况,但问题随之也来了,由于特征属性间存在依赖关系,使得朴素贝叶斯分类不适用了。既然这样,我去寻找另外的解决方案。
下图表示特征属性之间的关联:
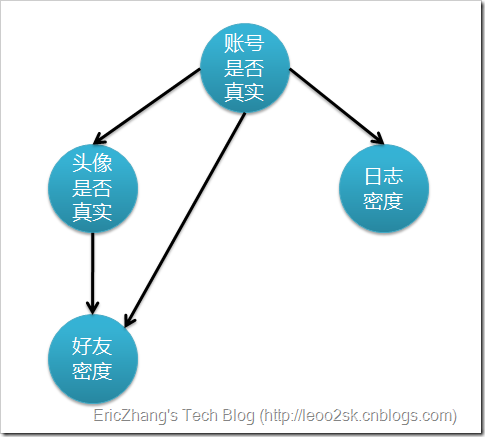
上图是一个有向无环图,其中每个节点代表一个随机变量,而弧则表示两个随机变量之间的联系,表示指向结点影响被指向结点。不过仅有这个图的话,只能定性给出随机变量间的关系,如果要定量,还需要一些数据,这些数据就是每个节点对其直接前驱节点的条件概率,而没有前驱节点的节点则使用先验概率表示。
例如,通过对训练数据集的统计,得到下表(R表示账号真实性,H表示头像真实性):
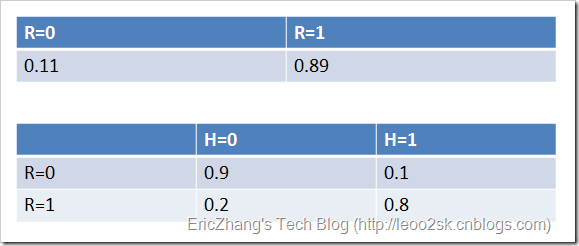
纵向表头表示条件变量,横向表头表示随机变量。上表为真实账号和非真实账号的概率,而下表为头像真实性对于账号真实性的概率。这两张表分别为“账号是否真实”和“头像是否真实”的条件概率表。有了这些数据,不但能顺向推断,还能通过贝叶斯定理进行逆向推断。例如,现随机抽取一个账户,已知其头像为假,求其账号也为假的概率:
也就是说,在仅知道头像为假的情况下,有大约35.7%的概率此账户也为假。如果觉得阅读上述推导有困难,请复习概率论中的条件概率、贝叶斯定理及全概率公式。如果给出所有节点的条件概率表,则可以在观察值不完备的情况下对任意随机变量进行统计推断。上述方法就是使用了贝叶斯网络。
2.3、贝叶斯网络的定义及性质
有了上述铺垫,我们就可以正式定义贝叶斯网络了。
一个贝叶斯网络定义包括一个有向无环图(DAG)和一个条件概率表集合。DAG中每一个节点表示一个随机变量,可以是可直接观测变量或隐藏变量,而有向边表示随机变量间的条件依赖;条件概率表中的每一个元素对应DAG中唯一的节点,存储此节点对于其所有直接前驱节点的联合条件概率。
贝叶斯网络有一条极为重要的性质,就是我们断言每一个节点在其直接前驱节点的值制定后,这个节点条件独立于其所有非直接前驱前辈节点。
这个性质很类似Markov过程。其实,贝叶斯网络可以看做是Markov链的非线性扩展。这条特性的重要意义在于明确了贝叶斯网络可以方便计算联合概率分布。一般情况先,多变量非独立联合条件概率分布有如下求取公式:
而在贝叶斯网络中,由于存在前述性质,任意随机变量组合的联合条件概率分布被化简成
其中Parents表示xi的直接前驱节点的联合,概率值可以从相应条件概率表中查到。
贝叶斯网络比朴素贝叶斯更复杂,而想构造和训练出一个好的贝叶斯网络更是异常艰难。但是贝叶斯网络是模拟人的认知思维推理模式,用一组条件概率函数以及有向无环图对不确定性的因果推理关系建模,因此其具有更高的实用价值。
2.4、贝叶斯网络的构造及学习
构造与训练贝叶斯网络分为以下两步:
1、确定随机变量间的拓扑关系,形成DAG。这一步通常需要领域专家完成,而想要建立一个好的拓扑结构,通常需要不断迭代和改进才可以。
2、训练贝叶斯网络。这一步也就是要完成条件概率表的构造,如果每个随机变量的值都是可以直接观察的,像我们上面的例子,那么这一步的训练是直观的,方法类似于朴素贝叶斯分类。但是通常贝叶斯网络的中存在隐藏变量节点,那么训练方法就是比较复杂,例如使用梯度下降法。由于这些内容过于晦涩以及牵扯到较深入的数学知识,在此不再赘述,有兴趣的朋友可以查阅相关文献。
2.5、贝叶斯网络的应用及示例
贝叶斯网络作为一种不确定性的因果推理模型,其应用范围非常广,在医疗诊断、信息检索、电子技术与工业工程等诸多方面发挥重要作用,而与其相关的一些问题也是近来的热点研究课题。例如,Google就在诸多服务中使用了贝叶斯网络。
就使用方法来说,贝叶斯网络主要用于概率推理及决策,具体来说,就是在信息不完备的情况下通过可以观察随机变量推断不可观察的随机变量,并且不可观察随机变量可以多于以一个,一般初期将不可观察变量置为随机值,然后进行概率推理。下面举一个例子。
还是SNS社区中不真实账号检测的例子,我们的模型中存在四个随机变量:账号真实性R,头像真实性H,日志密度L,好友密度F。其中H,L,F是可以观察到的值,而我们最关系的R是无法直接观察的。这个问题就划归为通过H,L,F的观察值对R进行概率推理。推理过程可以如下表示:
1、使用观察值实例化H,L和F,把随机值赋给R。
2、计算。其中相应概率值可以查条件概率表。
由于上述例子只有一个未知随机变量,所以不用迭代。更一般得,使用贝叶斯网络进行推理的步骤可如下描述:
1、对所有可观察随机变量节点用观察值实例化;对不可观察节点实例化为随机值。
2、对DAG进行遍历,对每一个不可观察节点y,计算,其中wi表示除y以外的其它所有节点,a为正规化因子,sj表示y的第j个子节点。
3、使用第三步计算出的各个y作为未知节点的新值进行实例化,重复第二步,直到结果充分收敛。
4、将收敛结果作为推断值。
以上只是贝叶斯网络推理的算法之一,另外还有其它算法,这里不再详述。

本文基于署名-非商业性使用 3.0许可协议发布,欢迎转载,演绎,但是必须保留本文的署名张洋(包含链接),且不得用于商业目的。如您有任何疑问或者授权方面的协商,请与我联系。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?