
自监督学习初识
自监督学习(self-supervised learning)可以看作是机器学习的一种“理想状态”,无需人工干涉,模型直接从无标签数据中自行学习,无需标注数据。模型寻找数据之间的关系,查找关联来给他们制定相应的标签,而整个自监督学习最重要的部分就是如何给未标记数据打上标签。
自监督学习中我认为比较麻烦是设置有效、合理的辅助任务(pretext)。以用来在大量的无标记数据中挖掘出对我们的任务有帮助的信息,再用这些信息对我们的模型进行训练,从而可以学习到对下游任务有价值的表征。
而对于自监督学习来说有几个比较困难的问题,比如对于大量的无标签数据,如何进行表征/表示学习?从数据的本身出发,如何设计有效的辅助任务 pretext?我们如何来评测提取到的表征的有效性?
自监督学习的预处理--微调 流程:首先从大量的无标签数据中通过 pretext 来训练网络(自动在数据中构造监督信息),得到预训练的模型,然后对于新的下游任务,和监督学习一样,迁移学习到的参数后微调即可。所以自监督学习的能力主要由下游任务的性能来体现。
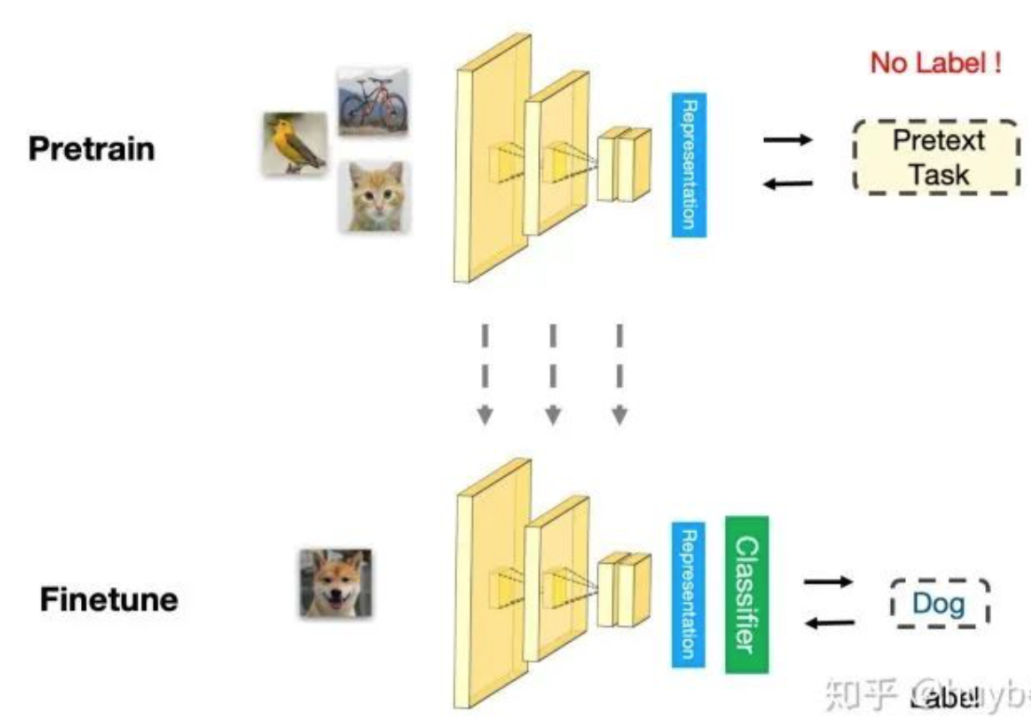
自监督学习的一些方法,目前研究主要是三种方法:1. 基于上下文(Context based) 2. 基于时序(Temporal Based)3. 基于对比(Contrastive Based)
未完待续~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号