html 面试相关知识点汇总
知识点汇总
- 知识点汇总
HTML5新特性,语义化
DTD
Document type Definition指为了程序间的数据交换而建立的关于标识符的一套语法规则
SGML,HTML,XML
- SGML 即Standard Globalized Markup Language 是用来定义标准的标记语言,简单的说,就是定义文档的元语言。
- HTML 是基于SGML的超链接语言,可以用于创建Web页面。在DTD内部定义了标签的规则,DTD就是使用SGML 语言创建的。
- XML 是从SGML 衍生而来的,它主要处理互联网方面的需求,HTML 有很多限制,XML 是SGML 的子集,可用于表示数据。
DOC类型
创建HTML页面时:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">
这句代码简单的介绍了HTML 版本号,有了Doctype,就引入了对应的DTD(定义了HTML文档的组织结构),在页面中添加的所有标签才会是合法的,简单的说DTD 就是定义HTML的语法规则。
即使在没有引入DTD的情况下,很多浏览器也可以识别HTML元素,因为它们自身包含对HTML 元素的定义,这就是为什么很多开发人员没有感受到DTD 的存在。
HTML5 与之前的版本区别
HTML5不是基于SGML 语言的,因此不需要DTD ,它是一种全新的标记语言,有自己的解析规则,HTML5的语法规则与之前版本有很大的差别,可以称的上是一种全新的语言。
HTML5 的Doctype 非常简单:
<!DOCTYPE html>
HTML5与HTML4.01之间的差异
在 HTML 4.01 中有三种 <!DOCTYPE> 声明。在 HTML5 中只有一种:
- HTML 4.01 Strict 该 DTD 包含所有 HTML 元素和属性,但不包括展示性的和弃用的元素(比如 font)。不允许框架集(Framesets)。
- HTML 4.01 Transitional,该 DTD 包含所有 HTML 元素和属性,包括展示性的和弃用的元素(比如 font)。不允许框架集(Framesets)。
- HTML 4.01 Frameset,该 DTD 等同于 HTML 4.01 Transitional,但允许框架集内容。
HTML5 新特性
-
理解新的页面结构语义
HTML 旧版本并没有标准的文档定义规则,比如如何定义文档Header或Footer等,很多人都在使用div来修饰一些CSS ,常常会导致不一致性。
HTML5 定义标准tag如Header,Footer,nav,FlipCaption等。这些标签可使得标记语言更有意义。
注意: 这些标签不提供特殊的渲染功能,仅仅使的HTML 文档结构更具有意义。 -
新的输入属性
之前为了获得不同的UI元素,如DatePicker,range Picker,color Picker等,会使用不同的类库。
HTML5 为输入元素引入了新属性“type”,看以下示例:
<input type="number" name="MyNuberElement" id="MyNumberElement" />
<input type="range" name="MyRangeElement" id="MyRangeElement"/>
<input type="color" id="MyColorElement" name="MyColorElement" />
<input type="date" id="MyDateElement" name="MyDateElement" />
<input type="time" id="MyTimeElement" name="MyTimeElement"/>
placeholder
HTML5的表单验证属性
-
Audio,video等多媒体支持
-
drag,drop,geolocation,本地存储localStorage,web worker
HTML的语义化
(1)HTML语义化让页面的内容结构化,结构更清晰,便于对浏览器、搜索引擎解析;
(2)即使在没有样式CSS的情况下也能以一种文档格式显示,并且是容易阅读的;
(3)搜索引擎的爬虫也依赖于HTML标记来确定上下文和各个关键字的权重,有利于SEO;
(4)使阅读源代码的人更容易将网站分块,便于阅读、维护和理解。
浏览器的标准模式和怪异模式
所谓的标准模式是指,浏览器按W3C标准解析执行代码;怪异模式则是使用浏览器自己的方式解析执行代码,因为不同浏览器解析执行的方式不一样,所以我们称之为怪异模式。浏览器解析时到底使用标准模式还是怪异模式,与你网页中的DTD声明直接相关,DTD声明定义了标准文档的类型(标准模式解析)文档类型,会使浏览器使用相应的方式加载网页并显示,忽略DTD声明,将使网页进入怪异模式(quirks mode)。
如果你的网页代码不含有任何声明,那么浏览器就会采用怪异模式解析,便是如果你的网页代码含有DTD声明,浏览器就会按你所声明的标准解析。
标准模式中IE6不认识!important声明,IE7、IE8、Firefox、Chrome等浏览器认识;而在怪异模式中,IE6/7/8都不认识!important声明,这只是区别的一种,还有很多其它区别。所以,要想写出跨浏览器CSS,你最好采用标准模式。
document对象有个属性compatMode,它有两个值:
- BackCompat 对应quirks mode
- CSS1Compat 对应strict mode
最大的异同点是对于盒模型中内容的width和height的计算方式不同
浏览器模式
IE11改名为“用户代理字符串”。就是用来设置navigator.userAgent和navigator.appVersion.
它唯一需要注意的是,在不同的IE版本中,它与文档模式的关系可不相同。
IE89中,倘若浏览器模式被设置为Internet Explorer7,那么文档模式的只能设置为7,6,5;
IE11中,用户代理字符串设置和文档模式可谓是没有半毛钱关系。
文档模式
文档模式用于设置浏览器的渲染模式和对应的JS引擎特性.
对于以Webkit、Molliza等作为内核的浏览器来说,DOM树的解析、渲染,JS的API等主要与内核版本挂钩;而对于IE浏览器而言,这些从IE6开始就跟文档模式挂钩了。
-
怪异模式
IE6789的是IE5.5的文档模式,IE10+和Chrome等浏览器是W3C规范的怪异模式。 -
标准模式 (非怪异模式)
W3C标准的文档模式,但各浏览器的实现阶段不尽相同。 -
准标准模式 (有限怪异模式)
由于该模式离W3C标准仍然有一段距离,因此被称作准标准模式(或有限怪异模式)。IE6、7的标准模式实际上就是准标准模式,而IE8+才有实质上的标准模式
兼容模式
在兼容模式中,页面以宽松的向后兼容的方式显示,模拟老式浏览器的行为以防止站点无法工作。当DTD没有定义时,即开启兼容也称混杂模式.
js的严格模式
ECMASript5最早引入了"严格模式",通过严格模式,可以在函数内部选择进行较为严格的全局或局部的错误条件检测.使用严格模式的好处就是可以提早知道代码中存在的错误.为未来的规范定义做铺垫.
将"use strict"放在脚本文件的第一行,则整个脚本都将以"严格模式"运行。
将"use strict"放在函数体的第一行,则整个函数以"严格模式"运行。
使用data-*的好处
data-* 属性用于存储私有页面后应用的自定义数据。
data-* 属性可以在所有的 HTML 元素中嵌入数据。
自定义的数据可以让页面拥有更好的交互体验(不需要使用 Ajax 或去服务端查询数据)。
通过HTML5的规范之后,可以根据element的dataset属性,直接获取数据.
data-* 属性是 HTML5 新增的。
meta标签
<meta> 元素可提供有关页面的元信息(meta-information),比如针对搜索引擎和更新频度的描述和关键词。
<meta> 标签位于文档的头部,不包含任何内容。<meta> 标签的属性定义了与文档相关联的名称/值对。
meta标签根据属性的不同,可分为两大部分:http-equiv 和 name 属性。
- http-equiv:相当于http的文件头作用,它可以向浏览器传回一些有用的信息,以帮助浏览器正确地显示网页内容。
- name属性:主要用于描述网页,与之对应的属性值为content,content中的内容主要是便于浏览器,搜索引擎等机器人识别,等等。
常用的有viewport,charset,lang;
viewport content 参数:
- width viewport 宽度(数值/device-width)
- height viewport 高度(数值/device-height)
- initial-scale 初始缩放比例
- maximum-scale 最大缩放比例
- minimum-scale 最小缩放比例
- user-scalable 是否允许用户缩放(yes/no)
meta viewport原理
桌面上视口宽度等于浏览器宽度,但在手机上有所不同。
-
布局视口
手机上为了容纳为桌面浏览器设计的网站,默认布局视口宽度远大于屏幕宽度,为了让用户看到网站全貌,它会缩小网站 -
视觉视口
屏幕的可视区域,即物理像素尺寸 -
理想视口
当网站是为手机准备的时候使用。通过meta来声明。早期iPhone理想视口为320x480px
所以,在没有缩放的情况下,屏幕的CSS像素宽度其实是指理想视口的宽度,而meta标签:
<meta name="viewport" content="width=device-width,minimum-scale=1.0,maximum-scale=1.0,user-scalable=no"/>
指定了布局视口=理想视口,并且禁止缩放。所以添上width=device-width的 viewport meta后页面变大了(一开始页面内容小得看不清),实际上是布局视口变小了。
HTML5废弃的元素
表现性元素
- basefont
- big
- center
- font
- s
- strike
- tt
- u
框架类元素
- frame
- frameset
- noframes
属性值
- align
- body标签上的link、vlink、alink、text属性
- bgcolor
- height和width
- iframe元素上的scrolling属性
- valign
- hspace和vspace
- table标签上的cellpadding、cellspacing和border属性
- header标签上的profile属性
- 链接标签a上的target属性
- img和iframe元素的longdesc属性
浏览器内核
Trident(ie内核);
Gecko(Firefox内核);
Webkit(chrome内核,safari内核);
Blink(chrome新内核);
浏览器兼容写法
CSS hack和filter原理
利用浏览器自身的bug来实现特定浏览器的样式
利用浏览器对CSS的完善度来实现,例如某些CSS规则或语法的支持程度,原理类似目前我们经常使用的 -webkit- 之类的属性;
IE条件注释
IE的条件注释仅仅针对IE浏览器,对其他浏览器无效;例如下面的语法:
<!-- [if IE]>
//你想要执行的代码
<![endif]-->
<!-- [if lt IE 8]>
//你想要执行的代码
<![endif]-->
<!-- [if ! IE 8]>
//你想要执行的代码
<![endif]-->
!important 关键字
!important 在css中是声明拥有最高优先级,也就是说,不管css的其他优先级,只要!important出现,他的优先级就最高!遨游1.6及更低版本、IE6及更低版本浏览器不能识别它。尽管这个!important 很实用,但是非到必要的时刻,不要使用它!
属性过滤器(较为常用的hack方法)
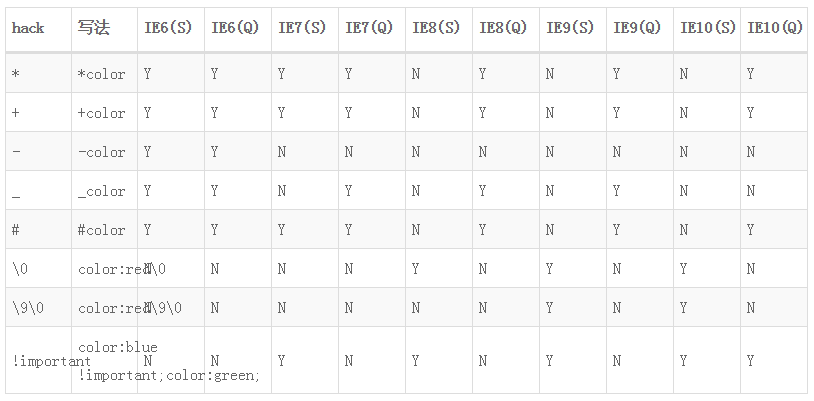
针对不同的IE浏览器,可以使用不同的字符来让特定的版本的IE浏览器进行样式控制。
| 字符 | 例子 | 说明 |
|---|---|---|
| _ | _color:red | ie6识别 |
- | *color:red | ie6/7可以识别
\9 | color:red\9 | ie8以下可以识别
更多hack写法
CSS兼容方案
a标签css顺序
link -> visited -> hover -> active
24位的png图片
IE6不支持透明咋办?使用png透明图片呗,但是需要注意的是24位的PNG图片在IE6是不支持的,解决方案有两种:
- 使用8位的PNG图片
- 为IE6准备一套特殊的图片
透明度
opacity: 0.8; //通用
filter: alpha(opacity=80); //IE
filter:progid:DXImageTransform.Microsoft.Alpha(style=0,opacity=80); //IE6的写法
IE6双边距
行内属性设置了块级属性(display: block;)后,会产生双倍边距。
解决方案是在添加一个 display: inline; 或者 display: table;
js兼容
ie监听方法:attachEvent()和detachEvent();
普通监听方法:addEventListener()和removeEventListener();
css js放置位置和原因
浏览器本身是多线程的:
- javascript引擎线程
- 界面渲染线程
- 浏览器事件触发线程
- Http请求线程
而JS运行在浏览器中,是单线程的,每个浏览器页面就是一个JS线程。
当我们在浏览器的地址栏里输入一个url地址,访问一个新页面时候,页面展示的快慢就是由一个单线程所控制,这个线程叫做UI线程,UI线程会根据页面里资源(资源是html文件、图片、css等)书写的先后顺序,它会按照资源的类型发起http请求来获取资源,当http请求处理完毕也就意味着资源加载结束。
但是碰到javascript文件则不同,它的加载过程被分为两步,第一步和加载css文件和图片一样,就是执行一个http请求下载外部的js文件,但是javascript完成http操作后并不意味操作完毕,UI线程就会通知javascript引擎线程来执行它,如果javascript代码执行时间过长,那么用户就会明显感觉到页面的延迟。
为什么浏览器不能把javascript代码的加载过程拆分为下载和执行两个并行的过程,这样就可以充分利用时间完成http请求,这样不是就能提升页面的加载效率了吗?答案当然是否定的。
因为javascript是一个图灵完备的编程语言,js代码是有智力的,它除了可以完成逻辑性的工作,还可以通过操作页面元素来改变页面的UI渲染,如果我们忽略javascript对网页UI界面渲染的影响,让它下载和运行是分开的(也可以理解为js代码可以延迟执行),结果会造成页面展示的混乱,或多次重绘。很显然,这样的做法是不合适的,因此,js脚本的下载和执行必须是一个完整的操作,是不能被割裂的。
渐进式渲染
对渲染进行分割 从具体的使用的场景, 不同的 Level 实际上对应不同的页面内容.
论坛是一个比较清晰的例子, 想象一个论坛:
网页的静态部分
- HTML 固定的内容, 比如导航栏和底部
- 页面首屏的内容, 比如一个论坛的话题
- 页面首屏看不到的内容, 比如话题下面多少回复
- 切换路由才会显示的页面, 比如导航的另一个页面
对于这样的情况, 显然有若干种可行的渲染分割的方案
全在客户端渲染
1, 2, 3 在服务端渲染, 4 等到用户点击从浏览器抓
1, 2 在服务器渲染, 评论由客户端加载
只有 1 在服务端渲染, 动态的数据全部由客户端抓取.
而这些方案对于服务端来说, 性能的开销各不相同, 形成一个梯度,
而最后一种情况, 服务端预编译页面就好了, 几乎没有渲染负担.
根据实际的场景, 可以有更多 Level 可以设计.. 只是没这么简单罢了.
html模板语言
通过重新定义html片段规则,解析之后,生成可被浏览器所识别的html片段,就是html模板语言.
离线存储
在线情况下,浏览器发现html头部有manifest属性,它会请求manifest文件,如果是第一次访问app,那么浏览器就会根据manifest文件的内容下载相应的资源并且进行离线存储。如果已经访问过app并且资源已经离线存储了,那么浏览器就会使用离线的资源加载页面,然后浏览器会对比新的manifest文件与旧的manifest文件,如果文件没有发生改变,就不做任何操作,如果文件改变了,那么就会重新下载文件中的资源并进行离线存储。
离线情况下,浏览器就直接使用离线存储的资源。
-
oncached:当离线资源存储完成之后触发这个事件,这个是文档的说法,我在Chrome上面测试的时候并没有触发这个事件。
-
onchecking:当浏览器对离线存储资源进行更新检查的时候会触发这个事件
-
ondownloading:当浏览器开始下载离线资源的时候会触发这个事件
-
onprogress:当浏览器在下载每一个资源的时候会触发这个事件,每下载一个资源就会触发一次。
-
onupdateready:当浏览器对离线资源更新完成之后会触发这个事件
-
onnoupdate:当浏览器检查更新之后发现没有资源更新的时候触发这个事件
浏览器中的缓存
以三个部分来把浏览器的缓存机制说清楚:
- 强缓存
- 协商缓存
- 缓存位置
强缓存
浏览器中的缓存作用分为两种情况,一种是需要发送HTTP请求,一种是不需要发送。
首先是检查强缓存,这个阶段不需要发送HTTP请求。
如何来检查呢?通过相应的字段来进行,但是说起这个字段就有点门道了。
在HTTP/1.0和HTTP/1.1当中,这个字段是不一样的。在早期,也就是HTTP/1.0时期,使用的是Expires,而HTTP/1.1使用的是Cache-Control。让我们首先来看看Expires。
Expires
Expires即过期时间,存在于服务端返回的响应头中,告诉浏览器在这个过期时间之前可以直接从缓存里面获取数据,无需再次请求。比如下面这样:
Expires: Wed, 22 Nov 2019 08:41:00 GMT
表示资源在2019年11月22号8点41分过期,过期了就得向服务端发请求。
这个方式看上去没什么问题,合情合理,但其实潜藏了一个坑,那就是服务器的时间和浏览器的时间可能并不一致,那服务器返回的这个过期时间可能就是不准确的。因此这种方式很快在后来的HTTP1.1版本中被抛弃了。
Cache-Control
在HTTP1.1中,采用了一个非常关键的字段:Cache-Control。这个字段也是存在于
它和Expires本质的不同在于它并没有采用具体的过期时间点这个方式,而是采用过期时长来控制缓存,对应的字段是max-age。比如这个例子:
Cache-Control:max-age=3600
代表这个响应返回后在 3600 秒,也就是一个小时之内可以直接使用缓存。
如果你觉得它只有max-age一个属性的话,那就大错特错了。
它其实可以组合非常多的指令,完成更多场景的缓存判断, 将一些关键的属性列举如下:
- public: 客户端和代理服务器都可以缓存。因为一个请求可能要经过不同的代理服务器最后才到达目标服务器,那么结果就是不仅仅浏览器可以缓存数据,中间的任何代理节点都可以进行缓存。
- private: 这种情况就是只有浏览器能缓存了,中间的代理服务器不能缓存。
- no-cache: 跳过当前的强缓存,发送HTTP请求,即直接进入协商缓存阶段。
- no-store:非常粗暴,不进行任何形式的缓存。
- s-maxage:这和max-age长得比较像,但是区别在于s-maxage是针对代理服务器的缓存时间。
值得注意的是,当Expires和Cache-Control同时存在的时候,Cache-Control会优先考虑。
当然,还存在一种情况,当资源缓存时间超时了,也就是强缓存失效了,接下来怎么办?没错,这样就进入到第二级屏障——协商缓存了。
协商缓存
强缓存失效之后,浏览器在请求头中携带相应的缓存tag来向服务器发请求,由服务器根据这个tag,来决定是否使用缓存,这就是协商缓存。
具体来说,这样的缓存tag分为两种: Last-Modified 和 ETag。这两者各有优劣,并不存在谁对谁有绝对的优势,跟上面强缓存的两个 tag 不一样。
Last-Modified
即最后修改时间。在浏览器第一次给服务器发送请求后,服务器会在响应头中加上这个字段。
浏览器接收到后,如果再次请求,会在请求头中携带If-Modified-Since字段,这个字段的值也就是服务器传来的最后修改时间。
服务器拿到请求头中的If-Modified-Since的字段后,其实会和这个服务器中该资源的最后修改时间对比:
如果请求头中的这个值小于最后修改时间,说明是时候更新了。返回新的资源,跟常规的HTTP请求响应的流程一样。
否则返回304,告诉浏览器直接用缓存。
ETag
ETag 是服务器根据当前文件的内容,给文件生成的唯一标识,只要里面的内容有改动,这个值就会变。服务器通过响应头把这个值给浏览器。
浏览器接收到ETag的值,会在下次请求时,将这个值作为If-None-Match这个字段的内容,并放到请求头中,然后发给服务器。
服务器接收到If-None-Match后,会跟服务器上该资源的ETag进行比对:
如果两者不一样,说明要更新了。返回新的资源,跟常规的HTTP请求响应的流程一样。
否则返回304,告诉浏览器直接用缓存。
两者对比
在精准度上,ETag优于Last-Modified。优于 ETag 是按照内容给资源上标识,因此能准确感知资源的变化。而 Last-Modified 就不一样了,它在一些特殊的情况并不能准确感知资源变化,主要有两种情况:
编辑了资源文件,但是文件内容并没有更改,这样也会造成缓存失效。
Last-Modified 能够感知的单位时间是秒,如果文件在 1 秒内改变了多次,那么这时候的 Last-Modified 并没有体现出修改了。
在性能上,Last-Modified优于ETag,也很简单理解,Last-Modified仅仅只是记录一个时间点,而 Etag需要根据文件的具体内容生成哈希值。
另外,如果两种方式都支持的话,服务器会优先考虑ETag。
缓存位置
前面我们已经提到,当强缓存命中或者协商缓存中服务器返回304的时候,我们直接从缓存中获取资源。那这些资源究竟缓存在什么位置呢?
浏览器中的缓存位置一共有四种,按优先级从高到低排列分别是:
- Service Worker
- Memory Cache
- Disk Cache
- Push Cache
Service Worker
Service Worker 借鉴了 Web Worker的 思路,即让 JS 运行在主线程之外,由于它脱离了浏览器的窗体,因此无法直接访问DOM。虽然如此,但它仍然能帮助我们完成很多有用的功能,比如离线缓存、消息推送和网络代理等功能。其中的离线缓存就是 Service Worker Cache。
Service Worker 同时也是 PWA 的重要实现机制,关于它的细节和特性,我们将会在后面的 PWA 的分享中详细介绍。
Memory Cache 和 Disk Cache
Memory Cache指的是内存缓存,从效率上讲它是最快的。但是从存活时间来讲又是最短的,当渲染进程结束后,内存缓存也就不存在了。
Disk Cache就是存储在磁盘中的缓存,从存取效率上讲是比内存缓存慢的,但是他的优势在于存储容量和存储时长。稍微有些计算机基础的应该很好理解,就不展开了。
好,现在问题来了,既然两者各有优劣,那浏览器如何决定将资源放进内存还是硬盘呢?主要策略如下:
比较大的JS、CSS文件会直接被丢进磁盘,反之丢进内存
内存使用率比较高的时候,文件优先进入磁盘
Push Cache
即推送缓存,这是浏览器缓存的最后一道防线。它是 HTTP/2 中的内容,虽然现在应用的并不广泛,但随着 HTTP/2 的推广,它的应用越来越广泛。
总结
对浏览器的缓存机制来做个简要的总结:
首先通过 Cache-Control 验证强缓存是否可用
如果强缓存可用,直接使用
否则进入协商缓存,即发送 HTTP 请求,服务器通过请求头中的If-Modified-Since或者If-None-Match字段检查资源是否更新
若资源更新,返回资源和200状态码
否则,返回304,告诉浏览器直接从缓存获取资源。
HTTPS为什么让数据传输更安全
谈到HTTPS, 就不得不谈到与之相对的HTTP。HTTP的特性是明文传输,因此在传输的每一个环节,数据都有可能被第三方窃取或者篡改,具体来说,HTTP 数据经过 TCP 层,然后经过WIFI路由器、运营商和目标服务器,这些环节中都可能被中间人拿到数据并进行篡改,也就是我们常说的中间人攻击。
为了防范这样一类攻击,我们不得已要引入新的加密方案,即 HTTPS。
HTTPS并不是一个新的协议, 而是一个加强版的HTTP。其原理是在HTTP和TCP之间建立了一个中间层,当HTTP和TCP通信时并不是像以前那样直接通信,直接经过了一个中间层进行加密,将加密后的数据包传给TCP, 响应的,TCP必须将数据包解密,才能传给上面的HTTP。这个中间层也叫安全层。安全层的核心就是对数据加解密。
接下来我们就来剖析一下HTTPS的加解密是如何实现的。
对称加密和非对称加密
概念
首先需要理解对称加密和非对称加密的概念,然后讨论两者应用后的效果如何。
对称加密是最简单的方式,指的是加密和解密用的是同样的密钥。
而对于非对称加密,如果有 A、 B 两把密钥,如果用 A 加密过的数据包只能用 B 解密,反之,如果用 B 加密过的数据包只能用 A 解密。
加解密过程
接着我们来谈谈浏览器和服务器进行协商加解密的过程。
首先,浏览器会给服务器发送一个随机数client_random和一个加密的方法列表。
服务器接收后给浏览器返回另一个随机数server_random和加密方法。
现在,两者拥有三样相同的凭证: client_random、server_random和加密方法。
接着用这个加密方法将两个随机数混合起来生成密钥,这个密钥就是浏览器和服务端通信的暗号。
对称加密和非对称加密的结合
可以发现,对称加密和非对称加密,单独应用任何一个,都会存在安全隐患。那我们能不能把两者结合,进一步保证安全呢?
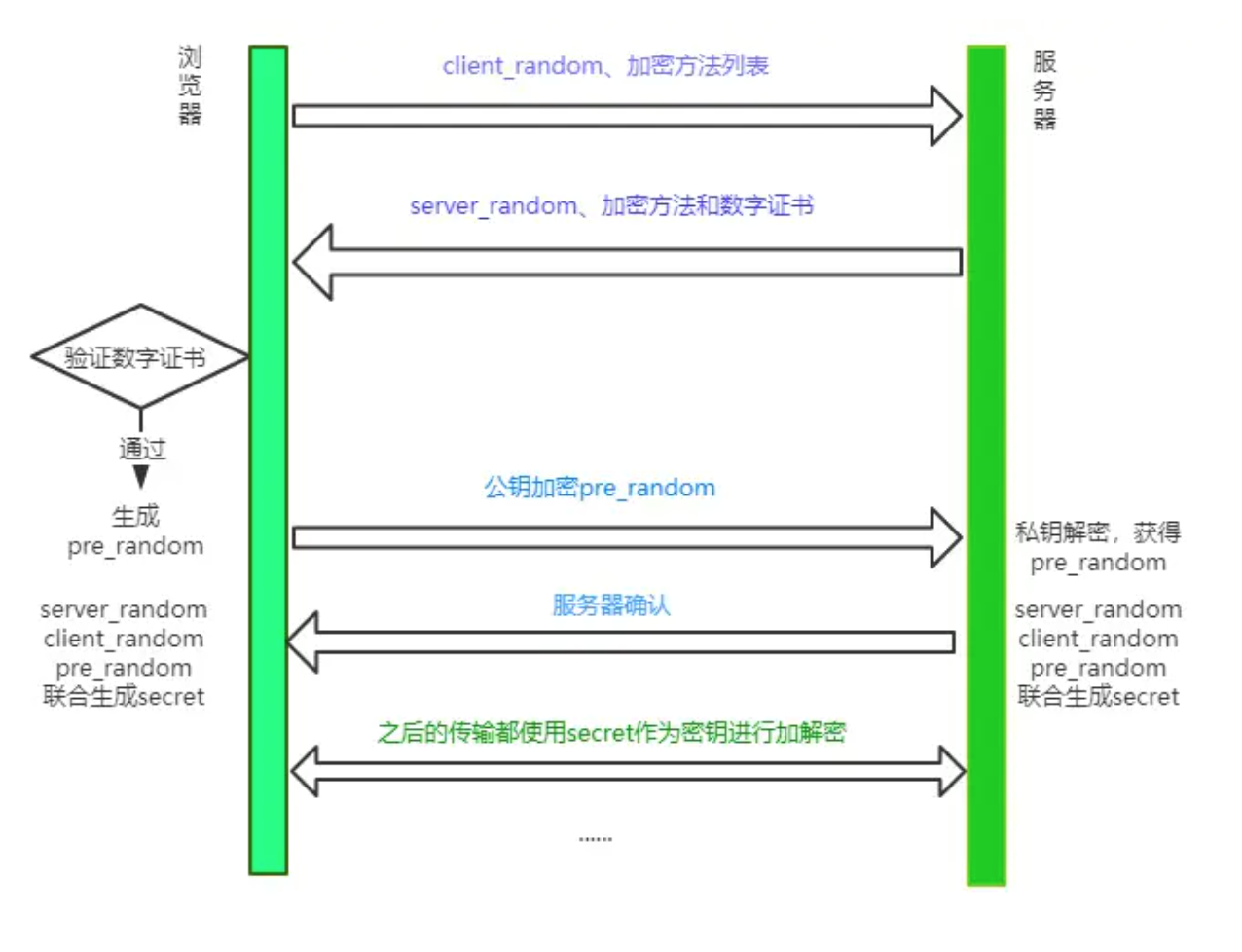
其实是可以的,演示一下整个流程:
- 浏览器向服务器发送client_random和加密方法列表。
- 服务器接收到,返回server_random、加密方法以及公钥。
- 浏览器接收,接着生成另一个随机数pre_random, 并且用公钥加密,传给服务器。(敲黑板!重点操作!)
- 服务器用私钥解密这个被加密后的pre_random。
现在浏览器和服务器有三样相同的凭证:client_random、server_random和pre_random。然后两者用相同的加密方法混合这三个随机数,生成最终的密钥。
然后浏览器和服务器尽管用一样的密钥进行通信,即使用对称加密。
这个最终的密钥是很难被中间人拿到的,为什么呢? 因为中间人没有私钥,从而拿不到pre_random,也就无法生成最终的密钥了。
回头比较一下和单纯的使用非对称加密, 这种方式做了什么改进呢?本质上是防止了私钥加密的数据外传。单独使用非对称加密,最大的漏洞在于服务器传数据给浏览器只能用私钥加密,这是危险产生的根源。利用对称和非对称加密结合的方式,就防止了这一点,从而保证了安全。
添加数字证书
尽管通过两者加密方式的结合,能够很好地实现加密传输,但实际上还是存在一些问题。黑客如果采用 DNS 劫持,将目标地址替换成黑客服务器的地址,然后黑客自己造一份公钥和私钥,照样能进行数据传输。而对于浏览器用户而言,他是不知道自己正在访问一个危险的服务器的。
事实上HTTPS在上述结合对称和非对称加密的基础上,又添加了数字证书认证的步骤。其目的就是让服务器证明自己的身份。
传输过程
为了获取这个证书,服务器运营者需要向第三方认证机构获取授权,这个第三方机构也叫CA(Certificate Authority), 认证通过后 CA 会给服务器颁发数字证书。
这个数字证书有两个作用:
服务器向浏览器证明自己的身份。
把公钥传给浏览器。
这个验证的过程发生在什么时候呢?
当服务器传送server_random、加密方法的时候,顺便会带上数字证书(包含了公钥), 接着浏览器接收之后就会开始验证数字证书。如果验证通过,那么后面的过程照常进行,否则拒绝执行。
现在我们来梳理一下HTTPS最终的加解密过程:
尾语
相关知识点仅供参考,具有一定的时效性,博主比较懒,博客仅做一个记录,更新的内容会在github里https://github.com/leomYili/my-learning-notes/tree/master/interview
