IMDB-WIKI - 具有年龄和性别标签的500k +脸部图像
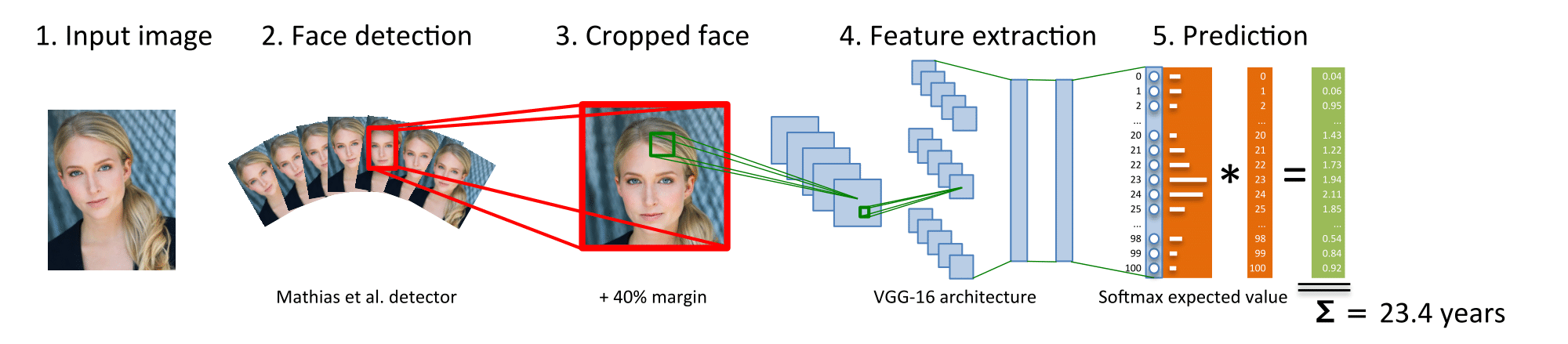
在本文中,我们通过深度学习来处理静态脸部图像的表观年龄估计。我们的卷积神经网络(CNN)使用VGG-16架构,并在ImageNet上预先进行图像分类。另外,由于有明显的年龄注明图像数量有限,我们探索了可用年龄的爬网式互联网面部图像的优势。我们从这个网站上公布的IMDb和维基百科的五百万个名人影像。这是迄今为止最大的年龄预测公共数据集。我们将年龄回归问题作为深度分类问题,随后是softmax预期值细化,并显示出对CNN的直接回归训练的改进。我们提出的方法,深度展望(DEX)的表观年龄,首先检测测试图像中的脸部,然后从裁剪面上的20个网络的集合中提取CNN预测。DEX的CNN在被抓取的图像上进行了分配,然后在提供的图像上进行了明显的年龄注释。DEX不使用显式的面部地标。我们的DEX是ChaLearn LAP 2015挑战赛(第一名),对明显的年龄估计,超过115个注册队伍,显着优于人类参考。
我们的年龄估计模型正在我们的网站howhot.io上使用,它在互联网上传播,并广泛覆盖社会媒体和新闻界(Techcrunch,Hackernews,Reddit#1,Evening Standard,Spiegel)。
从没有面部地标的单一形象深刻期待真实和明显的年龄
国际计算机视觉学报(IJCV),2016年
在本文中,我们提出了一种深度学习解决方案,从单一的面部图像来估计年龄,而不使用面部地标,并引入IMDB-WIKI数据集,这是面向年龄和性别标签的最大的公众数据集。如果真正的年龄估计研究跨越了数十年,则从脸部图像中观察年龄估计或其他人感觉到的年龄的研究是最近的一个尝试。我们通过对ImageNet进行图像分类预先训练的VGG-16架构的卷积神经网络(CNN)来处理这两个任务。我们将年龄估计问题作为深度分类问题,随后是softmax期望值细化。我们的解决方案的关键因素是:从大数据深入学习的模型,强大的面部对齐和年龄回归的预期值。
PDFIMDB-WIKI数据集
据我们所知,这是最大的可公开提供的面部图像数据,具有性别和年龄标签进行培训。我们为年龄和性别预测提供预训模型。

描述
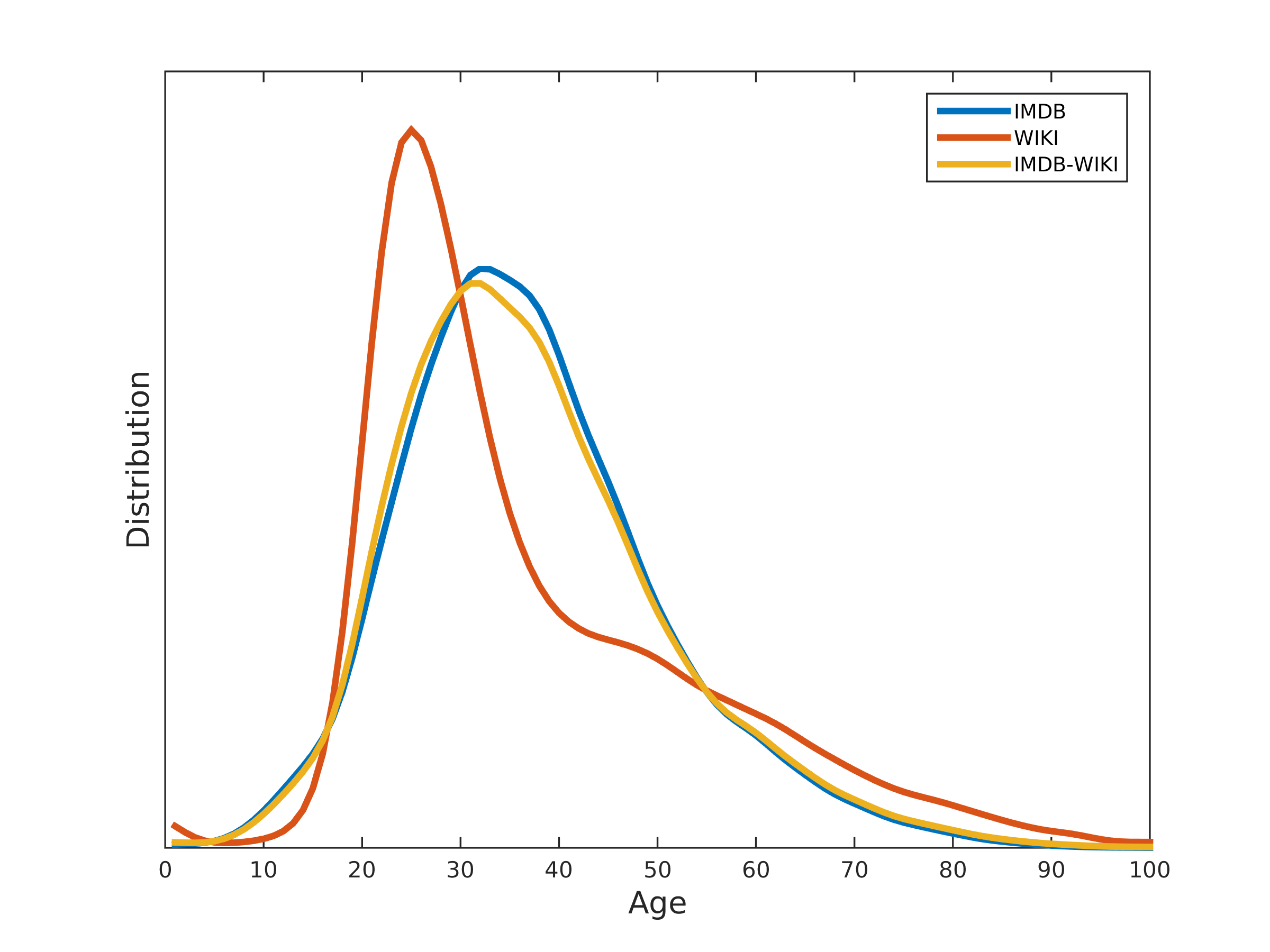
由于公开的面部图像数据通常是中小尺寸的,很少超过成千上万的图像,而且经常没有年龄信息,我们决定收集大量的名人数据。为此,我们列出了IMDb网站上列出的最受欢迎的十万名演员,并自动从他们的配置文件爬行,出生日期,姓名,性别以及与该人相关的所有图片。此外,我们使用相同的元信息从维基百科的人员页面中抓取了所有个人资料图片。我们删除了没有时间戳的照片(拍摄照片的日期)。假设具有单面的图像可能显示演员,并且时间戳和出生日期是正确的,我们能够为每个这样的图像分配生物(实际)年龄。当然,我们不能保证指定的年龄信息的准确性。除了错误的时间戳,许多图像仍然是电影 - 可以延长制作时间的电影。共有来自IMDb的20,284名名人和维基百科的62,328名,共获得了460,723张脸谱,共523,051张。
由于某些图像(特别是IMDb)包含了几个人,因此我们只使用第二个强大的脸部检测低于阈值的照片。为了使所有年龄段的网络得到同等的区别,我们要平衡培训的年龄分布。有关详细信息,请参阅论文。
用法
对于IMDb和维基百科图像,我们提供了一个单独的.mat文件,可以加载包含所有元信息的Matlab。格式如下:
- dob:出生日期(Matlab序列号)
- photo_taken:拍摄照片的年份
- full_path:文件路径
- 性别:女性为0,男性为1,NaN为未知
- 名称:名人的名字
- face_location:脸的位置。在Matlab运行中裁剪脸部
IMG(face_location(2):face_location(4),face_location(1):face_location(3),:)) - face_score:检测器得分(越高越好)。Inf意味着在图像中没有找到任何脸,而face_location则只返回整个图像
- second_face_score:具有第二高分的脸部检测器分数。这对于忽略具有多个脸部的图像很有用。如果没有检测到第二面,则second_face_score为NaN。
- celeb_names(仅限IMDB):所有名人名单的列表
- celeb_id(仅限IMDB):名人名称的索引
[年龄,〜] = datevec(datenum(wiki.photo_taken,7,1)-wiki.dob);
下载图像和元数据
在这里,您可以下载原始图像和元数据。我们还提供一个版本与裁剪的面孔(40%的边缘)。这个版本要小得多。
我们注意到维基百科的一些图像是坏的。我们计划在未来解决这个问题。现在请忽略这些图像。
IMDB
下载图片第1部分(26 GB) md5sum
下载图像第2部分(28 GB) md5sum
下载图片第3部分(29 GB) md5sum
下载图像第4部分(26 GB) md5sum
下载图片第5部分(29 GB) md5sum
下载图片第6部分(27 GB) md5sum
下载图片第7部分(27 GB) md5sum
下载图片第8部分(26 GB) md5sum
下载图像第9部分(24 GB) md5sum
下载图片元数据 md5sum
仅下载面(7 GB) md5sum
WIKI
用边缘提取脸的代码
该代码允许用户以边缘提取脸部。对于我们预先训练的模型,我们在四面都使用了40%的宽度和高度的边距(默认设置)。在脚本的顶部有用于提取所有面部图像的样本代码。
下载Caffe模型
在本节中,我们为Caffe提供预先训练的模型。对于所有型号,我们使用从Mathias等获得的脸部40%的边缘。人脸检测器。对于年龄估计,输出层有101个神经元(0-100年,每年1个)。要获得预测的年龄,您需要在softmax归一化输出概率上取预期值。对于性别预测,输出层有2个神经元(女性为0,男性为1)。
注意:在训练模型时,我们使用Imagenet的意思。
对IMDB-WIKI进行实时估算
该模型在IMDB-WIKI数据集上进行了培训。年龄分布平衡,被用作夏洛伊表观年龄估计挑战的预训练。
在LAP数据集上训练的表观年龄估计
*获得LAP挑战的明显年龄估计
此模型是以前型号的微调版本。该模型在ChaLearn表观年龄估计挑战的数据集上进行了微调。这些模型的合奏成为挑战的第一名(115队)。
性别预测
这个模型预测了一个人的性别。
引文
如果您正在使用数据集或预培训的模型,请添加引用。
@article {罗特-IJCV-2016, 作者= {Rasmus Rothe和Radu Timofte和Luc Van Gool}, title = {从没有脸部地标的单一图像深入预测真实和明显的年龄}, journal = {国际计算机视觉学报(IJCV)}, 年= {2016}, 月= {七月}, }
@InProceedings {罗特-ICCVW-2015, 作者= {Rasmus Rothe和Radu Timofte和Luc Van Gool}, title = {DEX:从单一图像深度预测明显的年龄}, booktitle = {IEEE国际计算机视觉研讨会(ICCVW)}, year = {2015}, 月= {十二月} }
执照
请注意,此数据集仅用于学术研究目的。所有的图像都是从互联网收集的,版权属于原始所有者。如果任何图像属于您,并且您希望将其删除,请通知我们,我们将立即将其从我们的数据集中删除。
每一个不曾起舞的日子,都是对生命的辜负。
But it is the same with man as with the tree. The more he seeks to rise into the height and light, the more vigorously do his roots struggle earthward, downward, into the dark, the deep - into evil.
其实人跟树是一样的,越是向往高处的阳光,它的根就越要伸向黑暗的地底。----尼采

 浙公网安备 33010602011771号
浙公网安备 33010602011771号