Caffe fine-tuning 微调网络
Caffe fine-tuning 微调网络
转载请注明出处,楼燚(yì)航的blog,http://www.cnblogs.com/louyihang-loves-baiyan/
目前呢,caffe,theano,torch是当下比较流行的Deep Learning的深度学习框架,楼主最近也在做一些与此相关的事情。在这里,我主要介绍一下如何在Caffe上微调网络,适应我们自己特定的新任务。一般来说我们自己需要做的方向,比如在一些特定的领域的识别分类中,我们很难拿到大量的数据。因为像在ImageNet上毕竟是一个千万级的图像数据库,通常我们可能只能拿到几千张或者几万张某一特定领域的图像,比如识别衣服啊、标志啊、生物种类等等。在这种情况下重新训练一个新的网络是比较复杂的,而且参数不好调整,数据量也不够,因此fine-tuning微调就是一个比较理想的选择。
微调网络,通常我们有一个初始化的模型参数文件,这里是不同于training from scratch,scrachtch指的是我们训练一个新的网络,在训练过程中,这些参数都被随机初始化,而fine-tuning,是我们可以在ImageNet上1000类分类训练好的参数的基础上,根据我们的分类识别任务进行特定的微调。
这里我以一个车型的识别为例,假设我们有431种车型需要识别,我的任务对象是车,现在有ImageNet的模型参数文件,在这里使用的网络模型是CaffeNet,是一个小型的网络,其实别的网络如GoogleNet也是一样的原理。那么这个任务的变化可以表示为:
任务:分类
类别数目:1000(ImageNet上1000类的分类任务)------> 431(自己的特定数据集的分类任务431车型)那么在网络的微调中,我们的整个流程分为以下几步:
- 依然是准备好我们的训练数据和测试数据
- 计算数据集的均值文件,因为集中特定领域的图像均值文件会跟ImageNet上比较General的数据的均值不太一样
- 修改网络最后一层的输出类别,并且需要加快最后一层的参数学习速率
- 调整Solver的配置参数,通常学习速率和步长,迭代次数都要适当减少
- 启动训练,并且需要加载pretrained模型的参数
简单的用流程图示意一下:
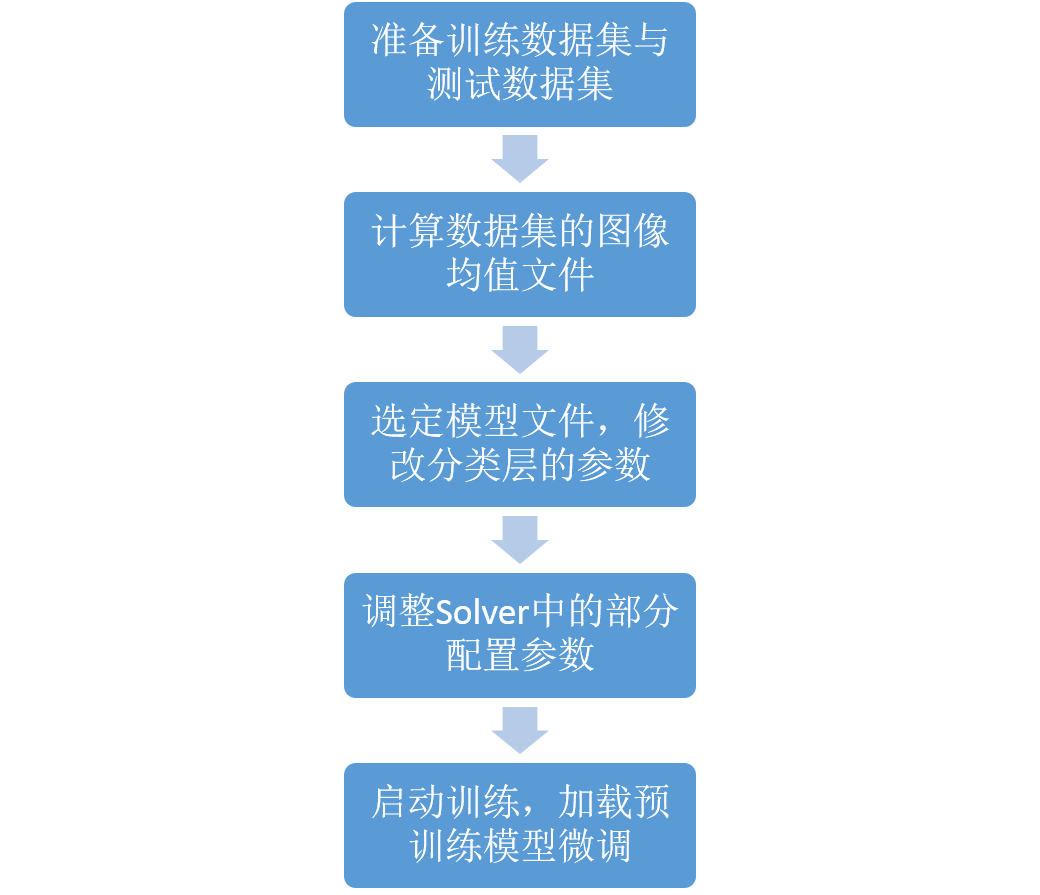
1.准备数据集
这一点就不用说了,准备两个txt文件,放成list的形式,可以参考caffe下的example,图像路径之后一个空格之后跟着类别的ID,如下,这里记住ID必须从0开始,要连续,否则会出错,loss不下降,按照要求写就OK。
这个是训练的图像label,测试的也同理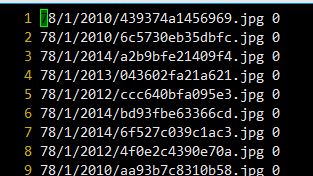
2.计算数据集的均值文件
使用caffe下的convert_imageset工具
具体命令是
/home/chenjie/louyihang/caffe/build/tools/convert_imageset /home/chenjie/DataSet/CompCars/data/cropped_image/ ../train_test_split/classification/train_model431_label_start0.txt ../intermediate_data/train_model431_lmdb -resize_width=227 -resize_height=227 -check_size -shuffle true
其中第一个参数是基地址路径用来拼接的,第二个是label的文件,第三个是生成的数据库文件支持leveldb或者lmdb,接着是resize的大小,最后是否随机图片顺序
3.调整网络层参数
参照Caffe上的例程,我用的是CaffeNet,首先在输入层data层,修改我们的source 和 meanfile, 根据之前生成的lmdb 和mean.binaryproto修改即可
最后输出层是fc8,
1.首先修改名字,这样预训练模型赋值的时候这里就会因为名字不匹配从而重新训练,也就达成了我们适应新任务的目的。
1.调整学习速率,因为最后一层是重新学习,因此需要有更快的学习速率相比较其他层,因此我们将,weight和bias的学习速率加快10倍。
原来是fc8,记得把跟fc8连接的名字都要修改掉,修改后如下
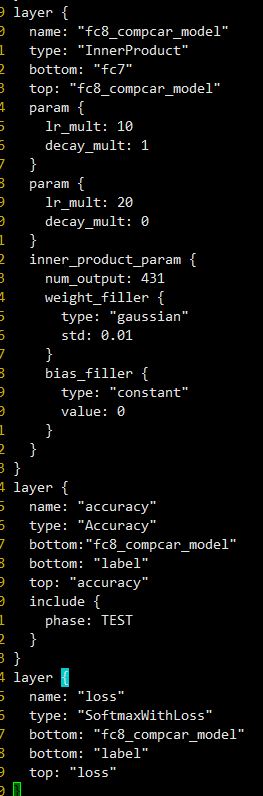
4.修改Solver参数
原来的参数是用来training from scratch,从原始数据进行训练的,因此一般来说学习速率、步长、迭代次数都比较大,在fine-tuning 微调呢,也正如它的名字,只需要微微调整,以下是两个对比图
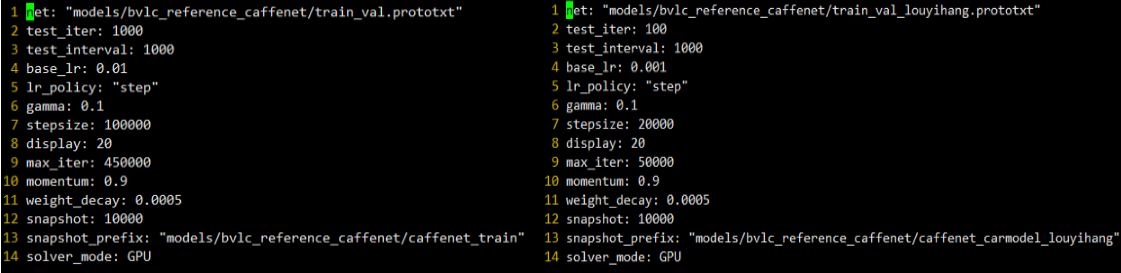
主要的调整有:test_iter从1000改为了100,因为数据量减少了,base_lr从0.01变成了0.001,这个很重要,微调时的基本学习速率不能太大,学习策略没有改变,步长从原来的100000变成了20000,最大的迭代次数也从450000变成了50000,动量和权重衰减项都没有修改,依然是GPU模型,网络模型文件和快照的路径根据自己修改
5.开始训练!
首先你要从caffe zoo里面下载一下CaffeNet网络用语ImageNet1000类分类训练好的模型文件,名字是bvlc_reference_caffenet.caffemodel
训练的命令如下:

OK,最后达到的性能还不错accuray 是0.9,loss降的很低,这是我的caffe初次体验,希望能帮到大家!
每一个不曾起舞的日子,都是对生命的辜负。
But it is the same with man as with the tree. The more he seeks to rise into the height and light, the more vigorously do his roots struggle earthward, downward, into the dark, the deep - into evil.
其实人跟树是一样的,越是向往高处的阳光,它的根就越要伸向黑暗的地底。----尼采

 浙公网安备 33010602011771号
浙公网安备 33010602011771号