迁移学习:数据不足时如何深度学习

策划|Tina
编辑|大愚若智
使用深度学习技术解决问题的过程中,最常见的障碍在于训练模型过程中所需的海量数据。需要如此多的数据,原因在于机器在学习的过程中会在模型中遇到大量参数。在面对某一领域的具体问题时,通常可能无法得到构建模型所需规模的数据。然而在一个模型训练任务中针对某种类型数据获得的关系也可以轻松地应用于同一领域的不同问题,这就是所谓的迁移学习。
我认为实现人工智能的难度无异于建造火箭。需要有一个强大的引擎,还有大量的燃料。如果空有强大的引擎但缺乏燃料,火箭肯定是无法上天的。如果只有一个单薄的引擎,有再多燃料也无法起飞。如果要造火箭,强大的引擎和大量燃料是必不可少的。以此来类比深度学习的话,深度学习引擎可以看作火箭引擎,而我们为算法提供的海量数据可以看作是燃料。 — Andrew Ng
最近深度学习技术突然开始大肆流行,并在语言翻译、玩策略游戏,以及无人驾驶汽车等涉及到数百万数据量的领域取得了醒目的成果。使用深度学习技术解决问题的过程中,最常见的障碍在于训练模型过程中所需的海量数据。需要如此多的数据,原因在于机器在学习的过程中会在模型中遇到大量参数。
例如这些模型中常见的参数数量范围包括:
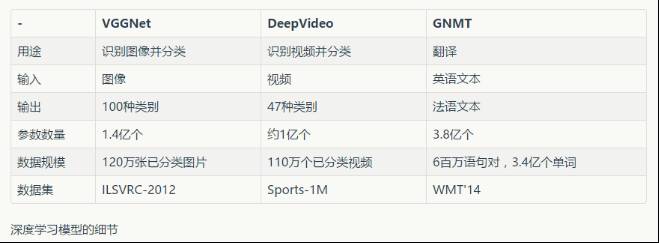
深度学习
神经网络(即深度学习)是一种分层式结构,但又能堆叠在一起(就像乐高积木)。
深度学习技术其实就是一种大规模神经网络,我们可以将这种网络看作一种流程图,数据从一端进入,相互引用/了解后从另一端输出。我们还可以将神经网络拆分成多个部分,从任何一部分中得到自己需要的推理结果。也许无法得到有意义的结果,但依然可以这样做,例如Google DeepDream就是这样做的。
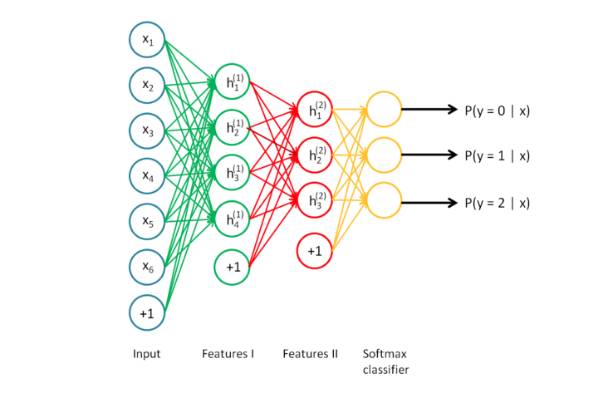
规模(模型) ∝ 规模(数据) ∝ 复杂度(问题)
在模型的规模和所需数据量的规模之间存在一种有趣的近似于线性的关系。基本推论在于,对于特定的问题(例如类别的数量),模型必须足够大,以便得到数据之间的关系(例如图片中的材质和形状,文本中的语法,以及语音中的音素)。模型中的前序层可以识别所输入内容中不同组成之间的高级别关系(例如边缘和模式),后续层可以识别有助于最终做决策所需的信息,这些信息通常有助于区分不同的结果。因此如果问题的复杂度较高(例如图像分类),所需的参数数量和数据量就会非常大。
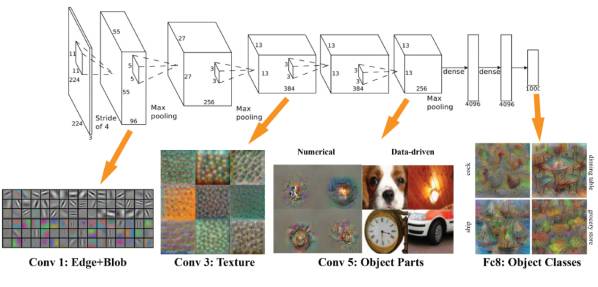
AlexNet在每个环节“看到”的内容
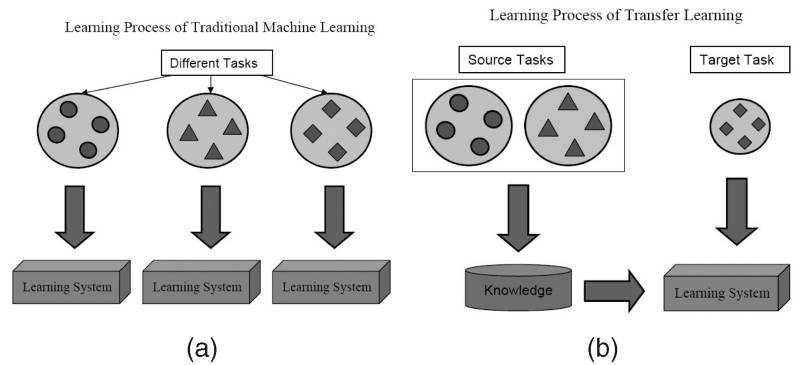
迁移学习来了!
在面对某一领域的具体问题时,通常可能无法得到构建模型所需规模的数据。然而在一个模型训练任务中针对某种类型数据获得的关系也可以轻松地应用于同一领域的不同问题。这种技术也叫做迁移学习(Transfer Learning)。
Qiang Yang、Sinno Jialin Pan,“A Survey on Transfer Learning”,IEEE Transactions on Knowledge & Data Engineering,vol. 22, no. , pp. 1345–1359, October 2010, doi:10.1109/TKDE.2009.191
迁移学习就像是一个没人愿意保守的最高机密。尽管业内人人皆知,但外界毫不知情。
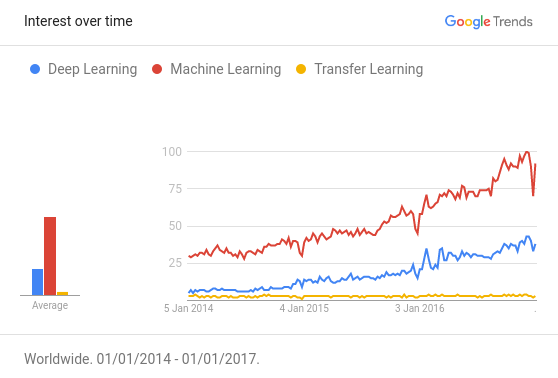
谷歌搜索中,机器学习、深度学习,以及迁移学习三个关键字的搜索趋势变化
根据Awesome — Most Cited Deep Learning Papers所公布的深度学习领域最主要的论文统计,超过50%的论文使用了某种形式的迁移学习或预训练。对于资源(数据和计算能力)有限的人,迁移学习技术的重要性与日俱增,然而这一概念尚未得到应有程度的社会影响。最需要这种技术的人甚至至今都不知道这种技术的存在。
如果深度学习是圣杯,数据是守门人,那么迁移学习就是大门钥匙。
借助迁移学习技术,我们可以直接使用预训练过的模型,这种模型已经通过大量容易获得的数据集进行过训练(虽然是针对完全不同的任务进行训练的,但输入的内容完全相同,只不过输出的结果不同)。随后从中找出输出结果可重用的层。我们可以使用这些层的输出结果充当输入,进而训练出一个所需参数的数量更少,规模也更小的网络。这个小规模网络只需要了解特定问题的内部关系,同时已经通过预培训模型学习过数据中蕴含的模式。通过这种方式,即可将经过训练检测猫咪的模型重新用于再现梵高的画作。
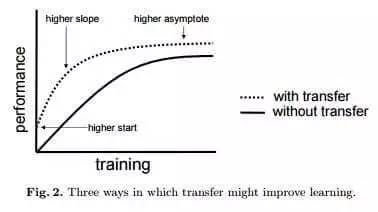
迁移学习技术的另一个重大收益在于可以对模型进行完善的“通用化”。大型模型往往会与数据过度拟合(Overfit),例如建模所用数据量远远超过隐含的现象数量,在处理未曾见过的数据时效果可能不如测试时那么好。由于迁移学习可以让模型看到不同类型的数据,因此可以习得更出色的底层规则。
过度拟合,更像是学习过程中的死记硬背。 — James Faghmous
迁移学习可减小数据量
假设想要终结裙子到底是蓝黑色还是白金色的争议,首先需要收集大量已获证实是蓝黑色和白金色的裙子图片。如果要使用类似上文提到的方式(包含1.4亿个参数!)自行构建一个准确的模型并对其进行训练,至少需要准备120万张图片,这基本上是无法实现的。这时候可以试试迁移学习。
如果使用迁移学习技术,训练所需的参数数量计算方式如下:
参数的数量 = [规模(输入) + 1] * [规模(输出) + 1]= [2048+1]*[1+1]~ 4098 个参数
所需参数数量由1.4*10⁸个减少至4*10⊃3;个,降低了五个数量级!只要收集不到100个图片就够了。松了口气!
如果实在没耐心继续阅读,希望立刻知道裙子的颜色,可以直接跳至本文末尾看看如何自行构建一个这样的模型。
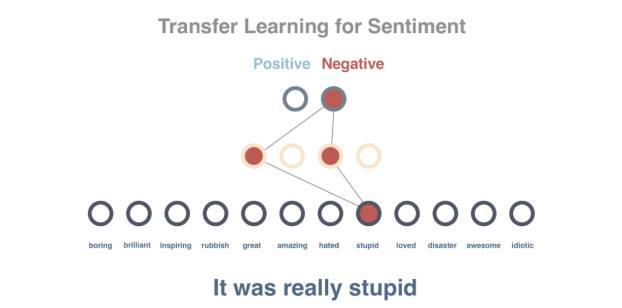
迁移学习循序渐进指南 — 使用示例进行情绪分析
在这个示例中共有72篇影评。
-
62篇不包含明确的情绪,将用于对模型进行预训练
-
8篇包含明确的情绪,将用于对模型进行训练
-
2篇包含明确的情绪,将用于对模型进行测试
由于只有8个包含标签的句子(包含明确情绪的句子),因此首先可以预训练模型进行上下文预测。如果只使用这8个句子训练模型,准确度可达50%(这样的准确度和抛硬币差不多)。
我们将使用迁移学习技术解决这个问题,首先使用62个句子训练模型,随后使用第一个模型的部分内容,以此为基础训练出一个情绪分类器。使用随后8个句子进行训练后,用最后2个句子测试得到了100%的精确度。
第1步
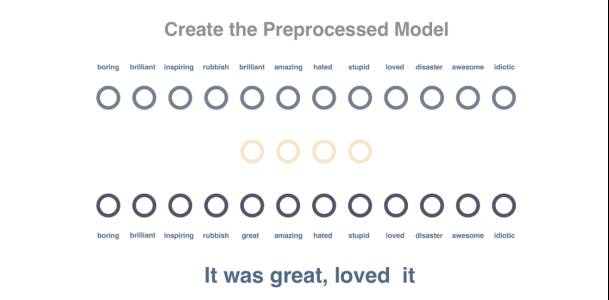
我们将训练一个对词语之间的关系进行建模的网络。将句子中包含的一个词语传递进去,并尝试预测该词语出现在同一个句子中。在下列代码中嵌入的矩阵其大小为vocabulary x embedding_size,其中存储了代表每个词语的向量(这里的大小为“4”)。
graph = tf.Graph()
with graph.as_default():
train_inputs = tf.placeholder(tf.int32, shape=[batch_size])
train_labels = tf.placeholder(tf.int32, shape=[batch_size, 1])
valid_dataset = tf.constant(valid_examples, dtype=tf.int32)
with tf.device('/cpu:0'):
embeddings = tf.Variable(tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0))
embed = tf.nn.embedding_lookup(embeddings, train_inputs)
nce_weights = tf.Variable(tf.truncated_normal([vocabulary_size, embedding_size], stddev=1.0 / math.sqrt(embedding_size)))
nce_biases = tf.Variable(tf.zeros([vocabulary_size]))
loss = tf.reduce_mean(tf.nn.nce_loss(nce_weights, nce_biases, embed, train_labels, num_sampled, vocabulary_size))
optimizer = tf.train.GradientDescentOptimizer(1.0).minimize(loss)
norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keep_dims=True))
normalized_embeddings = embeddings / norm
valid_embeddings = tf.nn.embedding_lookup(normalized_embeddings, valid_dataset)
similarity = tf.matmul(valid_embeddings, normalized_embeddings, transpose_b=True)
init = tf.global_variables_initializer()
pretraining_model.py托管于GitHub,可查看源文件
第2步
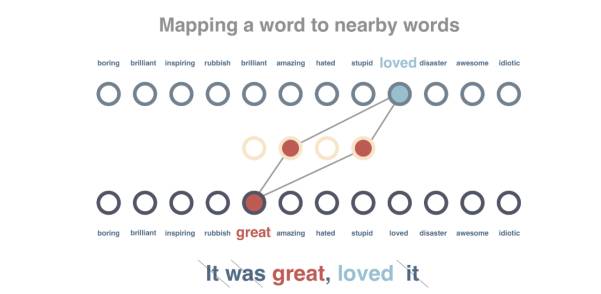
我们继续对这个图表进行训练,让相同上下文中出现的词语可以获得类似的向量表征。我们会对这些句子进行预处理,移除所有停用词(Stop word)并实现标记化(Tokenizing)。随后一次传递一个词语,尽量缩短该词语向量与周边词语之间的距离,并扩大与上下文不包含的随机词语之间的距离。
with tf.Session(graph=graph) as session: init.run() average_loss = 0 for step in range(10001): batch_inputs, batch_labels = generate_batch(batch_size, num_skips, skip_window) feed_dict = {train_inputs: batch_inputs, train_labels: batch_labels} _, loss_val, normalized_embeddings_np = session.run([optimizer, loss, normalized_embeddings], feed_dict=feed_dict) average_loss += loss_val final_embeddings = normalized_embeddings.eval()
training_the_pretrained_model.py托管于GitHub,可查看源文件
第3步
随后我们会试着预测句子的情绪。目前已经有10个(8个训练用,2个测试用)句子带有正面和负面的标签。由于上一步得到的模型已经包含从所有词语中习得的向量,并且这些向量的数值属性可以代表词语的上下文,借此可进一步简化情绪的预测。
此时我们并不直接使用句子,而是将句子的向量设置为所含全部词语的平均值(这一任务实际上是通过类似LSTM的技术实现的)。句子向量将作为输入传递到网络中,输出结果为内容为正面或负面的分数。我们用到了一个隐藏的中间层,并通过带有标签的句子对模型进行训练。如你所见,虽然每次只是用了10个样本,但这个模型实现了100%的准确度。
input = tf.placeholder("float", shape=[None, x_size])y = tf.placeholder("float", shape=[None, y_size])w_1 = tf.Variable(tf.random_normal((x_size, h_size), stddev=0.1))w_2 = tf.Variable(tf.random_normal((h_size, y_size), stddev=0.1))h = tf.nn.sigmoid(tf.matmul(X, w_1))yhat = tf.matmul(h, w_2)predict = tf.argmax(yhat, dimension=1)cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(yhat, y))updates = tf.train.GradientDescentOptimizer(0.01).minimize(cost)sess = tf.InteractiveSession()init = tf.initialize_all_variables()sess.run(init)for epoch in range(1000): for i in range(len(train_X)): sess.run(updates, feed_dict={X: train_X[i: i + 1], y: train_y[i: i + 1]}) train_accuracy = numpy.mean(numpy.argmax(train_y, axis=1) == sess.run(predict, feed_dict={X: train_X, y: train_y})) test_accuracy = numpy.mean(numpy.argmax(test_y, axis=1) == sess.run(predict, feed_dict={X: test_X, y: test_y})) print("Epoch = %d, train accuracy=%.2f%%, test accuracy=%.2f%%" % (epoch+1,100.*train_accuracy,100.* test_accuracy))
training_the_sentiment_model.py托管于GitHub,查看源文件
虽然这只是个示例,但可以发现在迁移学习技术的帮助下,精确度从50%飞速提升至100%。若要查看完整范例和代码请访问下列地址:
https://gist.github.com/prats226/9fffe8ba08e378e3d027610921c51a78
迁移学习的一些真实案例
#### 图像识别:
图像增强

风格转移
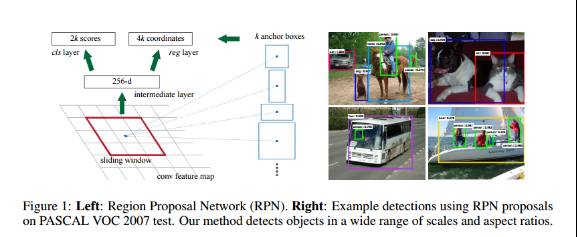
对象检测
皮肤癌检测
#### 文字识别:
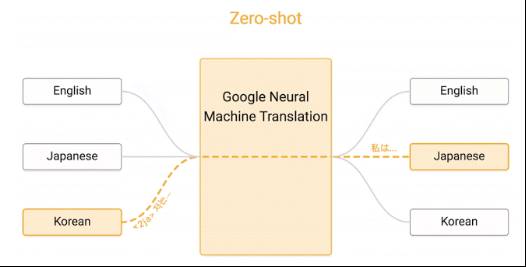
Zero Shot翻译
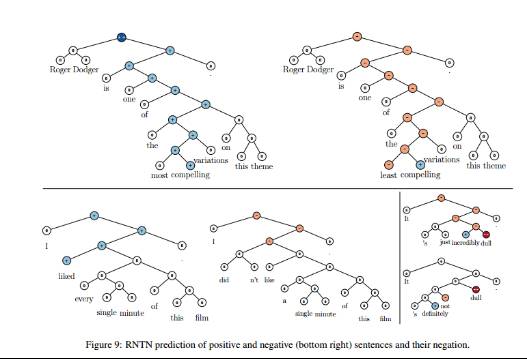
情绪分类
迁移学习实现过程中的难点
虽然可以用更少量的数据训练模型,但该技术的运用有着更高的技能要求。只需要看看上述例子中硬编码参数的数量,并设想一下要在模型训练完成前不断调整这些参数,迁移学习技术使用的难度之大可想而知。
迁移学习技术目前面临的问题包括:
-
找到预训练所需的大规模数据集
-
决定用来预训练的模型
-
两种模型中任何一种无法按照预期工作都将比较难以调试
-
不确定为了训练模型还需要额外准备多少数据
-
使用预训练模型时难以决定在哪里停止
-
在预训练模型的基础上,确定模型所需层和参数的数量
-
托管并提供组合后的模型
-
当出现更多数据或更好的技术后,对预训练模型进行更新
数据科学家难觅。找到能发现数据科学家的人其实一样困难。 — Krzysztof Zawadzki
NanoNets让迁移学习变得更简单
亲身经历过这些问题后,我们开始着手通过构建支持迁移学习技术的云端深度学习服务,并尝试通过这种简单易用的服务解决这些问题。该服务中包含一系列预训练的模型,我们已针对数百万个参数进行过训练。你只需要上传自己的数据(或在网络上搜索数据),该服务即可针对你的具体任务选择最适合的模型,在现有预训练模型的基础上建立新的NanoNet,将你的数据输入到NanoNet中进行处理。
Nanonet对程序员是免费的,可以用来学习和看看效果。
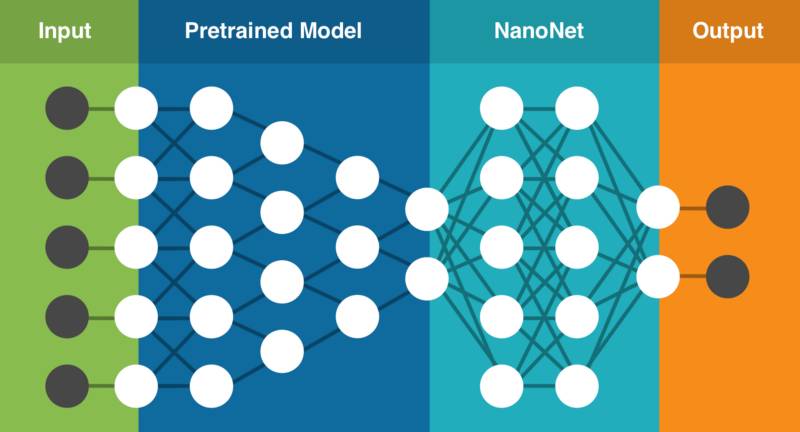
NanoNets的迁移学习技术(该架构仅为基本呈现)
构建NanoNet(图像分类)
1.在这里选择你要处理的分类。
2.一键点击开始搜索网络并构建模型(你也可以上传自己的图片)。

3.解决蓝金裙子的争议(模型就绪后我们会通过简单易用的Web界面让你上传测试图片,同时还提供了不依赖特定语言的API)。

若要开始构建你的第一个NanoNet,可访问:www.nanonets.ai。
原文作者:Sarthak Jain,点击“阅读原文”查看英文链接。
今日荐文
点击下方图片即可阅读

用两个使用Caffe的小项目案例演示迁移学习的实用性
每一个不曾起舞的日子,都是对生命的辜负。
But it is the same with man as with the tree. The more he seeks to rise into the height and light, the more vigorously do his roots struggle earthward, downward, into the dark, the deep - into evil.
其实人跟树是一样的,越是向往高处的阳光,它的根就越要伸向黑暗的地底。----尼采

 浙公网安备 33010602011771号
浙公网安备 33010602011771号