基于Overfeat的图片分类、定位、检测
原文地址:http://blog.csdn.net/hjimce/article/details/50187881
作者:hjimce
一、相关理论
本篇博文主要讲解来自2014年ICLR的经典图片分类、定位物体检测overfeat算法:《OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks》,至今为止这篇paper,已然被引用了几百次,把图片分类、定位、检测一起搞,可见算法牛逼之处非同一般啊。开始前,先解释一下文献的OverFeat是什么意思,只有知道了这个单词,我们才能知道这篇文献想要干嘛,OverFeat说的简单一点就是特征提取算子,就相当于SIFT,HOG等这些算子一样。Along with this paper, we release a feature extractor named “OverFeat”,这是文献对overfeat定义的原话。
这篇文献最牛逼的地方,在于充分利用了卷积神经网络的特征提取功能,它把分类过程中,提取到的特征,同时又用于定位检测等各种任务,牛逼哄哄啊。只需要改变网络的最后几层,就可以实现不同的任务,而不需要从头开始训练整个网络的参数。
其主要是把网络的第一层到第五层看做是特征提取层,然后不同的任务共享这个特征提取层。基本用了同一个网络架构模型(特征提取层相同,分类回归层根据不同任务稍作修改、训练)、同时共享基础特征。
二、计算机视觉的三大任务
开始讲解paper算法前,先让我们来好好学习一下计算机视觉领域中:分类、定位、检测这三者的区别。因为文献要一口气干掉这三个任务,所以先让我们需要好好区分一下这三个任务的区别:
A、图片分类:给定一张图片,为每张图片打一个标签,说出图片是什么物体,然而因为一张图片中往往有多个物体,因此我们允许你取出概率最大的5个,只要前五个概率最大的包含了我们人工标定标签(人工标定每张图片只有一个标签,只要你用5个最大概率,猜中其中就可以了),就说你是对的。
B、定位任务:你除了需要预测出图片的类别,你还要定位出这个物体的位置,同时规定你定位的这个物体框与正确位置差不能超过规定的阈值。
C、检测任务:给定一张图片,你把图片中的所有物体全部给我找出来(包括位置、类别)。
OK,解释完三个任务,我们接着就要正式开始学习算法了,我们先从最简单的任务开始讲起,然后讲定位,最后讲物体检测,分三大部分进行讲解。
三、Alexnet图片分类回顾
因为paper的网络架构方面与Alexnet基本相同,所以先让我们来好好回顾一下Alexnet的训练、测试:
(1)训练阶段:每张训练图片256*256,然后我们随机裁剪出224*224大小的图片,作为CNN的输入进行训练。
(2)测试阶段:输入256*256大小的图片,我们从图片的5个指定的方位(上下左右+中间)进行裁剪出5张224*224大小的图片,然后水平镜像一下再裁剪5张,这样总共有10张;然后我们把这10张裁剪图片分别送入已经训练好的CNN中,分别预测结果,最后用这10个结果的平均作为最后的输出。
overfeat这篇文献的图片分类算法,在训练阶段采用与Alexnet相同的训练方式,然而在测试阶段可是差别很大,这就是文献最大的创新点(overfeat的方法不是裁剪出10张224*224的图片进行结果预测平均,具体方法请看下面继续详细讲解)。
四、基础学习
开始讲解overfeat这篇文献的算法前,让我们先来学两招很重要的基础招式:FCN、offset max-pooling,等我们学完这两招,再来学overfeat这篇paper算法。
1、FCN招式学习
FCN又称全卷积神经网络,这招是现如今是图片语义分割领域的新宠(来自文献:《Fully Convolutional Networks for Semantic Segmentation》),同时也看懂overfeat这篇文献所需要学会的招式。
我们知道对于一个各层参数结构都设计好的网络模型来说,输入的图片大小是固定的,比如Alexnet设计完毕后,网络输入图片大小就是227*227。这个时候我们如果输入一张500*500的图片,会是什么样的结果?我们现在的希望是让我们的网络可以一直前向传导,让一个已经设计完毕的网络,也可以输入任意大小的图片,这就是FCN的精髓。FCN算法灵魂:
1、把卷积层-》全连接层,看成是对一整张图片的卷积层运算。
2、把全连接层-》全连接层,看成是采用1*1大小的卷积核,进行卷积层运算。
下面用一个例子,讲解怎么让一个已经设计好的CNN模型,可以输入任意大小的图片:

如上图所示,上面图中绿色部分表示:卷积核大小。假设我们设计了一个CNN模型,输入图片大小是14*14,通过第一层卷积后我们得到10*10大小的图片,然后接着通过池化得到了5*5大小的图片。OK,关键部分来了,接着要从:5*5大小的图片-》1*1大小的图片:
(1)传统的CNN:如果从以前的角度进行理解的话,那么这个过程就是全连接层,我们会把这个5*5大小的图片,展平成为一个一维的向量,进行计算(写cnn代码的时候,这个时候经常会在这里加一个flatten函数,就是为了展平成一维向量)。
(2)FCN:FCN并不是把5*5的图片展平成一维向量,再进行计算,而是直接采用5*5的卷积核,对一整张图片进行卷积运算。
其实这两个本质上是相同的,只是角度不同,FCN把这个过程当成了对一整张特征图进行卷积,同样,后面的全连接层也是把它当做是以1*1大小的卷积核进行卷积运算。
从上面的例子中,我们看到网络的输入是一张14*14大小的图片,这个时候加入我就用上面的网络,输入一张任意大小的图片,比如16*16大小的图片,那么会是什么样的结果?具体请看下面的示意图:
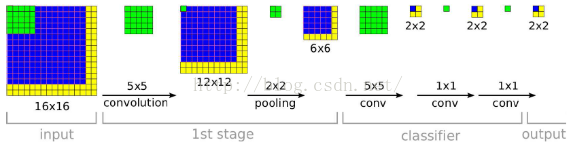
这个时候你就会发现,网络最后的输出是一张2*2大小的图片。这个时候,我们就可以发现采用FCN网络,可以输入任意大小的图片。同时需要注意的是网络最后输出的图片大小不在是一个1*1大小的图片,而是一个与输入图片大小息息相关的一张图片了。
OK,这个时候我们回来思考一个问题,比如Alexnet网络设计完毕后,我们也用FCN的思想,把全连接层看成是卷积层运算,这个时候你就会发现如果Alexnet输入一张500*500图片的话,那么它将得到1000张10*10大小的预测分类图,这个时候我们可以简单采用对着每一张10*10大小的图片求取平均值,作为图片属于各个类别的概率值。
其实Alexnet在测试阶段的时候,采用了对输入图片的四个角落进行裁剪,进行预测,分别得到结果,最后的结果就是类似对应于上面2*2的预测图。这个2*2的每个像素点,就类似于对应于一个角落裁剪下来的图片预测分类结果。只不过Alexnet把这4个像素点,相加在一起,求取平均值,作为该类别的概率值。
需要注意的是,一会儿overfeat就是把采用FCN的思想把全连接层看成了卷积层,让我们在网络测试阶段可以输入任意大小的图片。
2、offset max-pooling
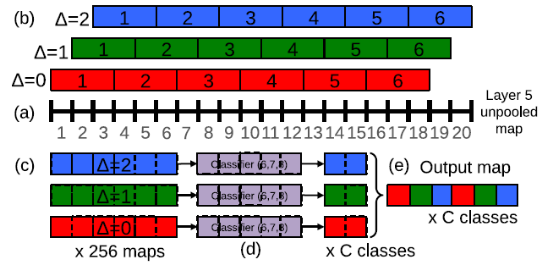
再让我们来学习一招大招,这一招叫offset 池化。为了简单起见,我们暂时不用二维的图像作为例子,而是采用一维作为示例,来讲解池化:

如上图所示,我们在x轴上有20个神经元,如果我们选择池化size=3的非重叠池化,那么根据我们之前所学的方法应该是:对上面的20个,从1位置开始进行分组,每3个连续的神经元为一组,然后计算每组的最大值(最大池化),19、20号神经元将被丢弃,如下图所示:

我们也可以在20号神经元后面,人为的添加一个数值为0的神经元编号21,与19、20成为一组,这样可以分成7组:[1,2,3],[4,5,6]……,[16,17,18],[19,20,21],最后计算每组的最大值,这就是我们以前所学CNN中池化层的源码实现方法了。
上面我们说到,如果我们只分6组的话,我们除了以1作为初始位置进行连续组合之外,也可以从位置2或者3开始进行组合。也就是说我们其实有3种池化组合方法:
A、△=0分组:[1,2,3],[4,5,6]……,[16,17,18];
B、△=1分组:[2,3,4],[5,6,7]……,[17,18,19];
C、△=2分组:[3,4,5],[6,7,8]……,[18,19,20];
对应图片如下:
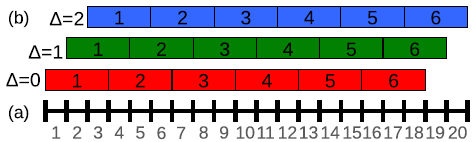
以往的CNN中,一般我们只用了△=0,得到池化结果后,就送入了下一层。于是文献的方法是,把上面的△=0、△=1、△=2的三种组合方式的池化结果,分别送入网络的下一层。这样的话,我们网络在最后输出的时候,就会出现3种预测结果了。
我们前面说的是一维的情况,如果是2维图片的话,那么(△x,△y)就会有9种取值情况(3*3);如果我们在做图片分类的时候,在网络的某一个池化层加入了这种offset 池化方法,然后把这9种池化结果,分别送入后面的网络层,最后我们的图片分类输出结果就可以得到9个预测结果(每个类别都可以得到9种概率值,然后我们对每个类别的9种概率,取其最大值,做为此类别的预测概率值)。
OK,学完了上面两种招式之后,文献的算法,就是把这两种招式结合起来,形成了文献最后测试阶段的算法,接着我们就来讲讲怎么结合。
五、overfeat图片分类
我们先从文献是怎么搞图片分类的开始说起,训练阶段基本变化不大,最大的区别在于网络的测试阶段。
1、paper网络架构与训练阶段
(1)网络架构
对于网络的结构,文献给出了两个版本,快速版、精确版,一个精度比较高但速度慢;另外一个精度虽然低但是速度快。下面是高精度版本的网络结构表相关参数:
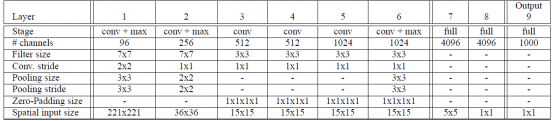
表格参数说明:
网络输入:从上面的表格,我们知道网络输入图片大小为221*221;
网络结构方面基本上和AlexNet是一样的,也是使用了ReLU激活,最大池化。不同之处在于:(a)作者没有使用局部响应归一化层;(b)然后也没有采用重叠池化的方法;(c)在第一层卷积层,stride作者是选择了2,这个与AlexNet不同(AlexNet选择的跨步是4,在网络中,如果stride选择比较大得话,虽然可以减少网络层数,提高速度,但是却会降低精度)。
这边需要注意的是我们需要把f7这一层,看成是卷积核大小为5*5的卷积层,总之就是需要把网络看成我们前面所学的FCN模型,没有了全连接层的概念,因为在测试阶段我们可不是仅仅输入221*221这样大小的图片,我们在测试阶段要输入各种大小的图片,具体请看后面测试阶段的讲解。
(2)网络训练
训练输入:对于每张原图片为256*256,然后进行随机裁剪为221*221的大小作为CNN输入,进行训练。
优化求解参数设置:训练的min-batchs选择128,权重初始化选择高斯分布的随机初始化:
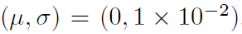
然后采用随机梯度下降法,进行优化更新,动量项参数大小选择0.6,L2权重衰减系数大小选择10-5次方。学习率一开始选择0.05,然后根据迭代次数的增加,每隔几十次的迭代后,就把学习率的大小减小一半。
然后就是DropOut,这个只有在最后的两个全连接层,才采用dropout,dropout比率选择0.5,也就是网络的第6、7层。
2、网络测试阶段
这一步需要声明一下,网络结构在训练完后,参数的个数、结构是固定的,而这一步的算法并没有改变网络的结构,也更不肯可能去改变网络参数。
我们知道在Alexnet的文献中,他们预测的方法是输入一张图片256*256,然后进行multi-view裁剪,也就是从图片的四个角进行裁剪,还有就是一图片的中心进行裁剪,这样可以裁剪到5张224*224的图片。然后把原图片水平翻转一下,再用同样的方式进行裁剪,又可以裁剪到5张图片。把这10张图片作为输入,分别进行预测分类,在后在softmax的最后一层,求取个各类的总概率,求取平均值。
然而Alexnet这种预测方法存在两个问题:首先这样的裁剪方式,把图片的很多区域都给忽略了,说不定你这样的裁剪,刚好把图片物体的一部分给裁剪掉了;另外一方面,裁剪窗口重叠存在很多冗余的计算,像上面我们要分别把10张图片送入网络,可见测试阶段的计算量还是蛮大的。
Overfeat算法:训练完上面所说的网络之后,在测试阶段,我们不再是用一张221*221大小的图片了作为网络的输入,而是用了6张大小都不相同的图片,也就是所谓的多尺度输入预测,如下表格所示:
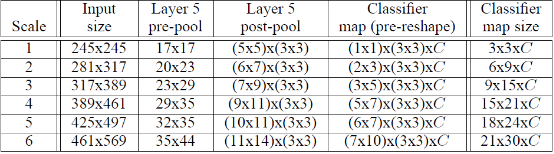
测试阶段网络输入图片大小分别是245*245,281*317……461*569。
然后当网络前向传导到layer 5的时候,就使出了前面我们所讲的FCN、offset pooling这两招相结合的招式。在这里我们以输入一张图片为例(6张图片的计算方法都相同),讲解layer 5后面的整体过程,具体流程示意图如下:
从layer-5 pre-pool到layer-5 post-pool:这一步的实现是通过池化大小为(3,3)进行池化,然后△x=0、1、2,△y=0、1、2,这样我们可以得到对于每一张特征图,我们都可以得到9幅池化结果图。以上面表格中的sacle1为例,layer-5 pre-pool大小是17*17,经过池化后,大小就是5*5,然后有3*3张结果图(不同offset得到的结果)。
从layer-5 post-pool到classifier map(pre-reshape):我们知道在训练的时候,从卷积层到全连接层,输入的大小是4096*(5*5),然后进行全连接,得到4096*(1*1)。但是我们现在输入的是各种不同大小的图片,因此接着就采用FCN的招式,让网络继续前向传导。我们从layer-5 post-pool到第六层的时候,如果把全连接看成是卷积,那么其实这个时候卷积核的大小为5*5,因为训练的时候,layer-5 post-pool得到的结果是5*5。因此在预测分类的时候,假设layer-5 post-pool 得到的是7*9(上面表格中的scale 3),经过5*5的卷积核进行卷积后,那么它将得到(7-5+1)*(9-5+1)=3*5的输出。
然后我们就只需要在后面把它们拉成一维向量摆放就ok了,这样在一个尺度上,我们可以得到一个C*N个预测值矩阵,每一列就表示图片属于某一类别的概率值,然后我们求取每一列的最大值,作为本尺度的每个类别的概率值。
最后我们一共用了6种不同尺度(文献好像用了12张,另外6张是水平翻转的图片),做了预测,然后把这六种尺度结果再做一个平均,作为最最后的结果。
OK,至此overfeat图片分类的任务就结束了,从上面过程,我们可以看到整个网络分成两部分:layer 1~5这五层我们把它称之为特征提取层;layer 6~output我们把它们称之为分类层。
六、定位任务
后面我们用于定位任务的时候,就把分类层(上面的layer 6~output)给重新设计一下,把分类改成回归问题,然后在各种不同尺度上训练预测物体的bounding box。
我们把用图片分类学习的特征提取层的参数固定下来,然后继续训练后面的回归层的参数,网络包含了4个输出,对应于bounding box的上左上角点和右下角点,然后损失函数采用欧式距离L2损失函数。
说到这边,感觉好累,因为后面基本上没有比较好玩的算法,所以就讲到这边,不然这篇文章就又要写十几页了。
个人总结:个人感觉学习这篇文献最重要的在于学习FCN、offset pooling,然后把它们结合起来,提高分类任务的精度,同时也让我们看到了CNN特征提取、迁移学习的强大威力。
参考文献:
1、《Fully Convolutional Networks for Semantic Segmentation》
2、《OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks》
**********************作者:hjimce 时间:2015.12.5 联系QQ:1393852684 原创文章,转载请保留作者、原文地址信息********************
每一个不曾起舞的日子,都是对生命的辜负。
But it is the same with man as with the tree. The more he seeks to rise into the height and light, the more vigorously do his roots struggle earthward, downward, into the dark, the deep - into evil.
其实人跟树是一样的,越是向往高处的阳光,它的根就越要伸向黑暗的地底。----尼采

 浙公网安备 33010602011771号
浙公网安备 33010602011771号