[Python自学] day-6 (编程范式、类、继承)
一、编程范式
- 面向过程编程:
- 使用一系列指令来告诉计算机一步一步完成任务。是一种Top-down language。如果只是写一些简单的脚本,用面向过程是极好的,但如果你要处理的任务是复杂的,切需要不断迭代和维护,那还是使用面向对象最方便。
- 面向对象编程:
- OOP编程利用类和对象来创建各种模型来实现对真是世界的描述,使用面向对象的原因一方面是因为它可以使程序的维护和扩展变得简单,并且可以大大提高程序开发效率,另外基于面向对象的程序可以使他人更容易理解,是团队开发变得容易。
- 函数式编程
二、类和对象
1.类定义
class Dog: def __init__(self,name): self.name = name def bulk(self): print("%s is bulking,wang wang wang!" % self.name) print(Dog) #返回<class '__main__.Dog'>
class Dog: def __init__(self,name): #构造函数 self.name = name def bulk(self): print("%s is bulking,wang wang wang!" % self.name)
2.实例变量和类变量
class Dog: n = 123 #类变量 def __init__(self,name): self.name = name #self.name为实例变量,也叫静态属性 def bulk(self): #类方法,也叫动态属性 print("%s is bulking,wang wang wang!" % self.name)
print(Dog.n) #通过类调用 print(dog1.n) #通过实例调用
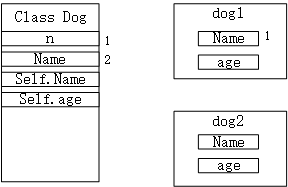
class Dog: n = 123 def __init__(self,name): self.name = name def bulk(self): print("%s is bulking,wang wang wang!" % self.name) dog1 = Dog("Alex") dog2 = Dog("Jack") dog1.age = 10 #给dog1对象增加属性age del dog1.name #删除dog1的name属性 print(Dog.name) print(dog1.name) #报错,找不到该属性。如果类变量里也有一个name,则会打印类变量name print(dog1.age)
class Dog: n = 123 def __init__(self,name): self.name = name def bulk(self): print("%s is bulking,wang wang wang!" % self.name) dog1 = Dog("Alex") dog2 = Dog("Jack") dog1.n = 234 #实际上是在dog1对象中添加了一个新的变量n=234,类中的变量n未改变 print(Dog.n) #输出123 print(dog1.n) #输出234 print(dog2.n) #输出123
class Dog: n_list = [] def __init__(self,name): self.name = name def bulk(self): print("%s is bulking,wang wang wang!" % self.name) dog1 = Dog("Alex") dog2 = Dog("Jack") dog1.n_list.append("from dog1") #都操作的类属性的内存地址 dog2.n_list.append("from dog2") #都操作的类属性的内存地址 Dog.n_list.append("from Dog") #都操作的类属性的内存地址 print(dog1.n_list) #输出["from dog1","from dog2","from Dog"] print(dog2.n_list) #输出["from dog1","from dog2","from Dog"] print(Dog.n_list) #输出["from dog1","from dog2","from Dog"]
class Person: nationality = "中国" #大部分人国籍 def __init__(self,name,age,id): self.name = name self.age = age self.id = id def sleep(self): print("sleep") p1 = Person("Leo",32,"513902") p2 = Person("Alex",22,"511027") p3 = Person("Acala",40,"400910") p3.nationality = "日本" #p3修改国籍 print(p3.nationality) #输出"日本"
3.析构函数
import time class Person: def __init__(self): print("构造函数") def __del__(self): print("析构函数") p = Person() #执行构造函数 time.sleep(2) del p #执行析构函数
4.私有方法和私有属性
class Person: def __init__(self,name,money): self.name = name self.__money = money #__money私有属性 p = Person("Leo",10000) print(p.name) print(p.__money) #无法直接访问
class Person: def __init__(self,name,money): self.name = name self.__money = money def buy_something(self,price): self.__money -= price print("cost RMB %d" % price) def get_money(self): #通过内部访问私有变量,提供给外部一个专用方法 return self.__money p = Person("Leo",10000) p.buy_something(4000) print(p.name) print(p.get_money()) #获取私有属性的值
二、类的继承(Inheritance)
1.继承的作用
主要作用:减少代码量
class People: def __init__(self,name,age): self.name = name self.age = age def eat(self): print("{name} is eating",format(name=self.name)) def sleep(self): print("{name} is sleeping".format(name=self.name)) class Man(People): #继承People pass man1 = Man("Leo",32) man1.sleep()
2.子类添加新方法
class Man(People): #继承People def swim(self): print("{name} is swimming".format(name=self.name)) man2 = Man("Lion",23) man2.swim()
3.子类覆盖父类方法
class Man(People): #继承People def swim(self): print("{name} is swimming".format(name=self.name)) def sleep(self): print("{name} is not sleeping".format(name=self.name)) man1 = Man("Leo",32) man1.sleep()
4.子类方法调用父类方法
class Man(People): #继承People def swim(self): print("{name} is swimming".format(name=self.name)) def sleep(self,time): People.sleep(self) #使用父类名调用sleep,但必须将该对象self传入 print("{name} is not sleeping...{time}".format(name=self.name,time=time)) man1 = Man("Leo",32) man1.sleep(30)
另一种调用父类方法的写法:
class Man(People): #继承People def __init__(self,name,age,money): #People.__init__(self,name,age) super(Man,self).__init__(name,age) #另一种写法,好处是如果修改了父类名,不需要在每个调用父类方法的地方修改 self.money=money
5.子类构造函数传更多参数
class Man(People): #继承People def __init__(self,name,age,money): #新增money参数 People.__init__(self,name,age) #调用父类构造函数 self.money=money def get_money(self): print("{name} have {money} yuan!".format(name=self.name,money=self.money)) def swim(self): print("{name} is swimming".format(name=self.name)) def sleep(self,time): People.sleep(self) #使用父类名调用sleep,但必须将该对象传入 print("{name} is not sleeping...{time}".format(name=self.name,time=time)) man1 = Man("Leo",32,5000) man1.get_money()
6.经典类和新式类
经典类和新式类:
class People: #经典类 pass class People(object): #新式类,必须这么写,前面的super方法也是新式类中的用法。 pass
7.多继承
经典类和新式类的多继承是不同的。
class People(object): def __init__(self,name,age): self.name=name self.age=age print("init of People") def eat(self): print("%s is eating!" % (self.name)) class Relation(object): def make_friend(self,obj): print("%s make friend with %s" % (self.name,obj.name)) class Man(People,Relation): #当Relation类中没有构造函数时,这里多继承的顺序调换没关系,因为super找最前面一个类的构造方法。同样找到的是People的构造方法 def __init__(self,name,age): super(Man,self).__init__(name,age) m1 = Man("Leo",32)
解释:多继承是按类的顺序来继承的,所以在Man(People,Relation)中,两个父类的位置是有影响的。假如Relation没有构造函数,People和Relation位置调换,子类中的super也能找到People的构造方法并执行。如果Relation中有自己的构造方法,并且参数不是name,age(例如def __init__(self,noney)),那就会报错,因为在初始化m1的时候传入的name和age与Relation的构造函数要求参数不一致。
class People(object): def __init__(self,name,age): self.name=name self.age=age print("init of People") def eat(self): print("%s is eating!" % (self.name)) class Relation(object): def __init__(self,n1,n2): #用n1,n2来接收name,age print(self.name) def make_friend(self,obj): print("%s make friend with %s" % (self.name,obj.name)) class Man(Relation,People): #先继承Relation,后继承People def __init__(self,name,age): super(Man,self).__init__(name,age) m1 = Man("Leo",32)
解释:上面代码中Relation类有构造函数,并通过n1和n2来接收m1初始化时传入的"leo"和32。参数能够接收后,打印self.name报错,说'Man' object has no attribute 'name'。因为继承顺序是Relation->People,在Relation中调用self.name时,name还没有被初始化。
总结:多继承中,继承顺序是从左到右,如果子类没有构造方法,则会自动去寻找父类构造方法,从第一个继承的父类开始找,并且执行找到的第一个父类构造方法(参数必须与该父类构造方法参数一致,否则报错)。如果子类中有构造方法,并在构造方法中显示调用父类构造方法,执行方法同前者。
8.新式类和经典类区别
构造函数查找顺序问题:
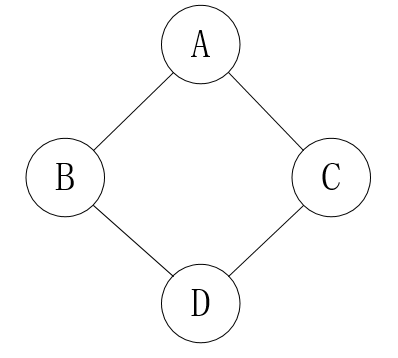
有A B C D四个类,继承关系如下代码:
class A: pass class B(A): pass class C(A): pass class D(B,C): pass
继承关系如下图所示:
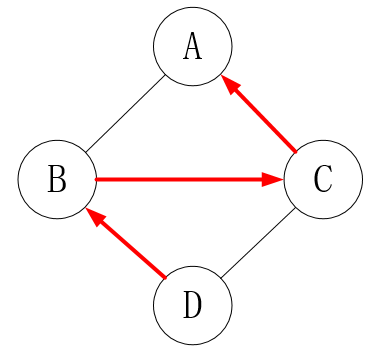
通过测试,Python3.0+的构造函数查找顺序默认如下:(先找同级,都没有的话再找上一级,叫广度优先。Python3上经典和新式都是按广度优先的)
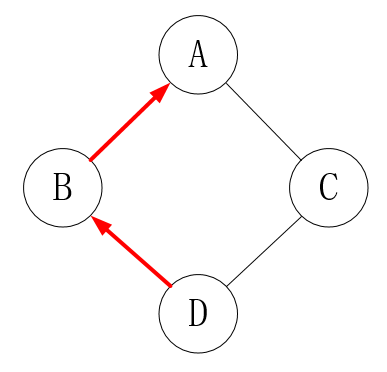
Python2.0+的查询顺序是默认深度优先,如下图:(经典类默认深度优先,新式类按广度优先)
总结:这个广度优先或深度优先顺序叫做MRO(方法解析顺序)。这个顺序不光使用与构造函数(构造函数只是经常自动寻找父类构造函数而已),还适用于所有想使用super调用父类方法的场景(例如我们手动调用父类方法)。
###

