[Python自学] day-4 (字符串、装饰器、生成式、生成器、迭代器、内置方法、JSON、pickle、目录结构)
一、字符串转为字典(eval):也可以用于转列表、集合等
s1 = "['name','leo']" s_list = eval(s1) #字符串转换为列表 print(s_list[1]) s2 = "{'name':'leo','age':32}" s_dict = eval(s2) #字符串转换为字典 print(s_dict['name']) s3 = "{1,2,3,4}" s_set = eval(s3) #字符串转换为集合 print(s_set.remove(4)) s4 = "(1,2,3,4)" s_tuple = eval(s4) #字符串转换为元组 print(s_tuple[1])
二、装饰器(decorator)
装饰器定义:本质是函数。功能是用来装饰其他函数,即为其他函数添加附加功能。
遵循原则:
- 不能修改被装饰函数的源代码。
- 被装饰函数的调用方式不能改变。
总结:装饰器对于被装饰函数,是完全透明的。
实现装饰器知识储备:
- 函数即“变量”
- 高阶函数
- 嵌套函数
eg.
import time def timer(func1): #装饰器 def warpper(*args,**kwargs): start_time = time.time() func1(*args,**kwargs) #调用被装饰的函数 end_time = time.time() print("使用时间{time}s".format(time = int(end_time- start_time))) return warpper @timer def func(str): for i in range(40): print("func() "+str) time.sleep(0.1) func("Hello World")
函数即变量:
变量x=1在内存中的存储方式见下图:
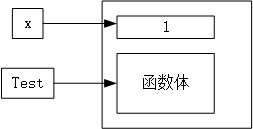
定义一个函数,相当于将函数体赋值给变量test。test="函数体"。该函数体仅仅是一串字符。
def test(): pass
Python内存回收机制:
x=1 #对数字1存在的内存有一个引用x y=x #对数字1存在的内存添加了另外一个引用。 del x #删除x引用 del y #删除y引用
函数或变量定义的顺序:只要在调用前定义好所有需要的变量或函数,则运行没有影响。解释器先解释了定义的语句,然后才解释运行的语句。所以定义的先后无所谓。参照上面《函数即变量》所述。函数定义时,会将函数体存在到内存中,使用函数名作为引用名。当运行到该函数时,解释器会根据函数名去查找内存中的函数体,如果在调用前未定义,则会报错。若已经定义,则解释执行。所以函数调用与函数定义的先后顺序无关。
高阶函数:
满足以下两个条件就叫高阶函数:
- 把一个函数名当做实参传给另外一个函数。
- 返回值中包含函数名。
def bar(): print("in bar") def test(func_name): func_name() test(bar)
import time def deco(func): start_time = time.time() func() end_time = time.time() print("func run time is %s" % (end_time-start_time)) def test1(): time.sleep(2)
deco(test1)
装饰器实现-2:使用函数嵌套
import time def timer(func): #将test1传递给func形参。func=test1 def deco(): start_time = time.time() #获取开始时间 func() #此处调用test1() end_time = time.time() #获取结束时间 print("Func Run Time is %s" % (end_time-start_time)) return deco #将deco函数的地址返回 def test1(): time.sleep(2)
test1 = timer(test1) #将timer()返回的deco地址覆盖到test1 test1() #调用test1,相当于调用deco.
使用语法糖“@”。
@timer #相当于test1 = timer(test1) def test1(): time.sleep(2)
装饰器实现-4:传递被装饰函数的参数
import time def timer(func): def deco(*args,**kwargs): #接收来自test1的参数 start_time = time.time() res = func(*args,**kwargs) #将deco接收到的参数传递给test1 end_time = time.time() print("Func Run Time is %s" % (end_time-start_time)) return res #deco返回test1的返回值 return deco @timer def test1(name,age): print(name,age) time.sleep(2) return "Result" #被装饰函数有返回值 print(test1("Leo",31)) #调用test1相当于调用deco。传递参数,相当于传递给deco。
import time def timer(time_type): #装饰器的参数传递到最外层 def outer(func): #被装饰函数传递到该层 def deco(*args,**kwargs): #接收来自test1的参数 start_time = time.time() res = func(*args,**kwargs) #将deco接收到的参数传递给test1 end_time = time.time() print("Func Run Time is %s" % (end_time-start_time)) return res return deco return outer @timer(time_type="t_type") #此时,timer有括号,则执行timer(time_type = "t_type"),返回outer。test1=outer(test1)。 def test1(name,age): print(name,age) time.sleep(2) return "Result" print(test1("Leo",31)) #调用test1相当于调用deco。传递参数,相当于传递给deco。
注意:当@后面的装饰器带括号,例如timer(time_type='t_type'),这是调用timer函数。timer()返回的是outer函数,实际上装饰器是outer,修饰test1的也是outer。
重点:装饰器非常重要的一点。就是当一个函数被另一个函数装饰时,装饰函数是在定义被装饰函数之后就执行了,无需我们手动调用。相当于装饰器为我们将被装饰函数预先进行了修改。例如,我们的装饰器为某个空字典添加一个值,那么我们无需调用被装饰函数,直接读取字典,值就已经在里面了。
# 该字典为全局变量 URL_DICT = dict() def router(url): def set_func(func): # 装饰器为URL_DICT添加一个键值对 URL_DICT[url] = func def call_func(): return func() return call_func return set_func @router("index") def test1(): return "hello" if __name__ == "__main__": print(URL_DICT["index"]())
上述代码中,我们并未手动调用test1函数,但是"index":test1已经被放到URL_DICT中去了。这是因为装饰器是在程序被导入时默认执行的,他的效果就是将test1变成了set_func函数,在运行的途中,"index":test1被放置到了字典中。
装饰器的执行时间可以参考 Python何时执行装饰器
三、列表生成式
list_new = [ x*2 for x in range(10) ] #生成[0,2,4,6,8,10,12,14,16,18] print(list_new) def func(x): return x**2 list_new = [ func(x) for x in range(10) ] #range(10)的每一个元素都传递给func() print(list_new)
四、生成器
与列表生成式不同,列表生成式会在执行时直接生成一个全量的列表,比如rang(10000000),则会生成一个1千万元素的列表,非常占用内存空间。
生成器:( x*2 for x in range(10000000) )执行后产生一个generator object。这个对象就叫做生成器。使用生成器来循环列表,只会根据当前循环的次数实时产生列表元素,大量节省内存空间。
性能比较如下代码:利用前面所学的装饰器给两个循环函数加上运行时间。得出结果,生成式耗时2s,而生成器耗时几乎为0。
import time def timer(func): def wrapper(*args,**kwargs): start_time = time.time() func(*args,**kwargs) end_time = time.time() print("Time : %s" % (end_time-start_time)) return wrapper def func(x): return x*2 @timer def list_new_loop(): list_new = [ func(x) for x in range(10000000) ] print(type(list_new)) for i in list_new: if i ==100: break print(i) @timer def list_new2_loop(): list_new2 = ( func(x) for x in range(10000000)) print(type(list_new2)) for i in list_new2: if i ==100: break print(i) list_new_loop() list_new2_loop()
生成式和生成器的区别:
除了在循环中存在内存空间占用的区别。
另外还有一个很重要的区别:
生成器不能直接用下标取值,因为他并未在内存中存放实际列表的元素。必须循环到某个下标才能实时生成元素并取值。
可以使用__next__()实时生成下一个元素并取值。
l = ( x*2 for x in range(100)) print(l.__next__()) #同next(l)
但是没有方法可以取到前面的值。因为生成器为了节省内存,只记住当前位置的元素,前面使用过的就扔掉了。
另一种生成器产生方法:(前一种方法的底层实现是这种函数方法)
下面函数打印一个斐波那契数列:
#斐波那契 def feibonaq(max_num): n ,a ,b = 0 ,0 ,1 while n < max_num: print(b) a , b = b , a+b n += 1 feibonaq(20)
将其中的print(b)替换为yield b。则feibonaq()返回一个生成器。
#斐波那契
def feibonaq(max_num): n ,a ,b = 0 ,0 ,1 while n < max_num: yield b #使用yield b a , b = b , a+b n += 1 f = feibonaq(20) #返回一个<generator object feibonaq at 0x02B47360> print(f.__next__()) #获取一个b的值,也可以用next(f) print(f.__next__()) #获取下一个b的值 print(f.__next__()) print("Do other things") #可以做其他事情 print(f.__next__()) #再取下一个b的值
给yield传值:
def consumer(name): print("%s 准备吃包子啦!" % name) while True: baozi = yield #使consumer返回一个生成器generator,接受参数并赋值给baozi print("包子 [%s] 来了,被 [%s] 吃了!" % (baozi,name)) c = consumer("Leo") #返回一个生成器给c c.__next__() #开始触发生成器(必须) bz = "韭菜馅包子" c.send(bz) #传递参数给yield(重要)
单线程下实现并行效果:(nginx就是这种原理,单线程下并发效率比多线程还高)异步IO的雏形。
import time def consumer(name): print("%s 准备吃包子啦!" % name) while True: baozi = yield print("[%s] 被 [%s] 吃了!" % (baozi,name)) def productor(name): c = consumer("Leo") c1 = consumer("Kale") c.__next__() c1.__next__() print("[%s] 开始做包子了!" % name) for i in range(10): time.sleep(0.5) baozi_half = "包子的一半" baozi_other_half = "包子的另一半" print("老子做了一个包子,分成两半!") c.send(baozi_half) c1.send(baozi_other_half) productor("cooker")
程序解释:
- 为什么在c = consumer()后必须执行一次c.__next__()。以为c = consumer()只是将consumer函数变成一个生成器。第一次调用__next__(),是为了将程序走到baozi = yield这一步,并且打印前面的“准备吃包子啦”。
五、迭代器
可以循环的数据类型:list、tuple、dict、set、str、文件和生成器(一种数据结构)。这些可以循环的对象,统称为可迭代对象(Interable)。
判断一个对象是否是可迭代的对象:使用isinstance( [], interable )
from collections import Iterable print(isinstance([],Iterable)) #判断列表是否可迭代,返回True
from collections import * print(isinstance([],Iterator)) #列表不是迭代器,但是是可迭代对象 print(isinstance( (x*2 for x in range(5)) ,Iterator)) #生成器是迭代器,返回Ture f = open("log.txt","r+",encoding = "utf-8") print(isinstance(f,Iterator)) #文件句柄是迭代器。
print(dir(x*2 for x in range(5))) #方法中存在__next__(),所以是迭代器 print(dir([])) #[]不是一个迭代器,返回False next([]) #报错TypeError: 'list' object is not an iterator print(dir(dict)) #False print(dir(tuple)) #False print(dir(set)) #False
Python的Iterator对象表示的是一个数据流,Iterator对象可以被next()调用,并不断返回下一个数据,直到没有数据抛出StopIteration错误。
Iterator的计算是惰性的,只有在需要返回下一个数据时它才会计算。
Iterator甚至可以表示一个无限大的数据流,例如全体自然数。而使用list是永远不可能存储全体自然数的。
创建一个Iterator:for循环的底层实际就是用迭代器实现的,高效。
it = iter([1,2,3,4,5]) #创建一个迭代器it while True: try: x = next(it) #使用next获取每一个数据 print(x) except StopIteration as err: break
ran = range(10) ran_iter = ran.__iter__() print(type(ran_iter)) while True: try: print(ran_iter.__next__()) except StopIteration: break
六、内置方法(built-in)
all():参数为可迭代对象,例如列表、字典等。当所有的元素都为True则返回True。
print(all([1,2,3,4,5])) #返回True print(all([0,1,2,3,4])) #返回False
print(any([1,2,3,4,5])) #返回True print(any([0,1,2,3,4])) #返回True print(any([0,0,0])) #返回False
print(bin(255)) #打印0b11111111
bytes():转换为byte。
a = bytes("abcde",encoding="utf-8") print(a) #打印b'abcde'
bytearray():转换成byte列表格式。可修改字符。
b = bytearray("abcde",encoding="utf-8") print(b[0]) #打印a的ascii码 97 b[1] = 100 #把b改成d print(b[1]) print(b) #打印bytearray(b'adcde')
def test(): pass list_test = [1,2,3] print(callable(test)) #函数是可调用的,类也是可调用的 print(callable(list_test)) #列表是不可调用的
chr()和ord():chr将Unicode码转换为字符。ord将字符转换为Unicode码。
print(chr(10000)) #输出✐
print(ord("ぁ")) #输出12353
code = "for i in range(10):print(i)" #代码是字符串 exe = compile(code , "err.log" , "exec") #将字符串转换为可执行代码 print(exe) #打印<code object <module> at 0x03029128, file "", line 1> exec(exe) #执行代码 code = "print('hello')" eval(code) #eval()也可以执行
exec直接可以执行字符串代码:(拿compile()来干嘛?)
code = "for i in range(10):print(i)" exec(code)
dir():查看方法。
d = dict() print(dir(d))
print(divmod(5,2)) #返回(2,1),2为商,1为余数。
匿名函数:一个函数只用一次,不会在其他地方调用。则可以定义为匿名函数。
noname = lambda n:print(n) #将匿名函数赋值给变量 noname(5) #使用函数变量调用
匿名函数中不能使用复杂函数语句,例如for循环等。
lambda n:for i in range(10):print(i*n) #错误
res = filter(lambda n:n>5,range(10)) #过滤出range(10)中大于5个数,组成列表 for i in res: print(i)
def file_test(n): #过滤函数 if n > 5: return n res2 = filter(file_test,range(10)) #filter()第一个参数接受一个过滤规则函数,可以是匿名,也可以使普通函数 for i in res2: print(i)
res = map(lambda n:n*n,range(10)) #第一个参数是一个处理函数,而不是过滤函数 for i in res: print(i)
def map_test(n): #处理函数 return n*n res2 = map(map_test,range(10)) for i in res2: print(i)
reduce():需要导入functools
import functools res = functools.reduce( lambda x,y:x+y,range(10)) print(res)
相当于:即从0加到9。没一次加法结果赋值给x,y为下一个数。
def reduce_test(x,y): return x+y res = functools.reduce(reduce_test,range(10)) print(res)
import functools res = functools.reduce( lambda x,y:x*y,range(1,10)) print(res)
list_test = frozenset([1,2,3,4,5])
name = "Leo" if "name" in globals(): print("变量存在") else: print("变量不存在")
hash():中文名---散列。返回一个哈希值。可以使用hash值比较两个对象是否相同。也可以用于二分查找。
print(hash("Leo")) #相同的对象转成hash值是相同的,但每次计算的hash值是不同的 print(hash("Leo")) print(hash("leo")) print(hash("kale"))
def test(): name = "Leo" print(name) if "name" in locals(): print("存在") test()
max()和min():返回列表、元组、字典(key)、集合或多个参数中的最大值和最小值。
print(max([1,2,3,4,5,6])) #返回列表中的最大元素 print(min([1,3,2,5,4])) #返回列表中的最小元素 print(max(1,2,3,4)) #返回参数中最大 print(min({1,2,3})) #返回集合中最小元素
it = iter([1,2,3,4,5,6]) print(next(it)) #获取下一个元素 print(it.__next__()) #同上
print( oct(1122) ) #十进制转换为8进制,返回0o2142 print( oct(0x12AF) ) #16进制转换为8进制,返回0o11257 print(oct(0b1111)) #二进制转八进制0o17
print(pow(2,8)) #2的8次方,输出256
def test(): pass print(test) #打印函数变量的地址<function test at 0x006954F8> print(type(repr(test))) #转换为字符串<class 'str'>
print(round(1.34356,3))
d = range(10) print(d[slice(2,5)]) #打印 range(2, 5)
dict = {5:2,-5:11,1:42,99:12,12:32,-9:98}
print(sorted(dict)) #仅对key进行排序,输出[-9, -5, 1, 5, 12, 99]
print(sorted(dict.items())) #对所有字典元素按key排序,每个元素转换成元组。输出[(-9, 98), (-5, 11), (1, 42), (5, 2), (12, 32), (99, 12)]
print(sorted(dict.items(), key = lambda x:x[1])) #对所有字段元素按value排序。输出[(5, 2), (-5, 11), (99, 12), (12, 32), (1, 42), (-9, 98)]
a = [1,2,3,4] b = ['a','b','c','d'] for i in zip(a,b): #zip(a,b)返回一个迭代器 print(i) #打印结果(1,'a') (2,'b') (3,'c') (4,'d') a = [1,2,3,4,5,6] #如果两个列表元素数量不一致,则按少的那个合并。 b = ['a','b','c','d'] for i in zip(a,b): print(i) #打印结果(1,'a') (2,'b') (3,'c') (4,'d')
__import__('my_module')
import本质上是调用__import__()来动态导入模块的
例如:
import os os = __import__("os")
七、JSON序列化
将一个对象保存到硬盘中。例如一个字典:
import json dict = {"name":"Leo","age":32} f = open("JSON_test","w") f.write(json.dumps(dict)) #序列化 f.close() import json f = open("JSON_test","r") dict = json.loads(f.read()) #反序列化 print(dict["age"]) f.close()
主要用于不同语言之间进行数据交互。
不同语言中的类、函数等都是不一样的,所以默认只支持简单的。
XML逐步被JSON取代。
八、pickle序列化
使用方法和JSON一样,但是可以处理复杂数据。例如函数等。
import pickle def test_func(): print("Hello") f = open("JSON_test","wb") f.write(pickle.dumps(test_func)) #看似序列化的函数地址,实际上只是函数名称和参数 f.close()
import pickle def test_func(): #反序列化这边的程序必须有名字一样,参数一样的函数存在。否则报错 print("Hello1") print("hello2") f = open("JSON_test","rb") func = pickle.loads(f.read()) func() #只要名称和参数与序列化的函数一致,则可以正常运行 f.close()
九、dumps和dump、loads和load的区别
import pickle def test_func(): print("Hello") f = open("JSON_test","wb") pickle.dump(test_func,f) #同f.write(pickle.dumps(test_func)) f.close()
import pickle def test_func(): print("Hello1") print("hello2") f = open("JSON_test","rb") func = pickle.load(f) #同func = pickle.loads(f.read()) func() f.close()
注意:同一个数据可以dumps很多次,但都是在一行中连续写入的。loads的时候会报错。所以建议一次dumps对应一次loads。类似虚拟机的快照,每个快照单独存一个文件。
十、软件目录结构规范
Foo/ #项目名 |--bin/ #运行文件目录 | |--foo.py #foo用于运行程序,调用core/下的main.py | |--conf/ #配置文件目录 | |--settings.py #配置文件 | |--logs/ #日志目录 | |--core/ #主程序目录,名字自定义,可以叫core | |--tests/ #测试程序目录 | | |--__init__.py | | |--test_main.py | | | |--__init__.py #包里默认有该文件,文件为空,创建一个包,会自动创建该文件 | |--main.py #程序入口 | |--docs/ #文档目录 | |-conf.py | |--abc.rst | |--setup.py #安装脚本 |--requirements.txt #依赖,例如需要依赖django、mysql |--README #程序描述
- 软件定位,软件的基本功能
- 运行代码的方法:安装环境、启动命令等。
- 简要的使用说明。
- 代码目录结构说明,更详细点可以说明软件的基本原理。
- 常见问题说明
setup.py:
一般来说,用setup.py来管理代码的打包、安装、部署问题。业界标准是使用Python流行的打包工具setuptools来管理这些事情。可以打包成pip能够安装的python程序包。
requirements.txt:
- 方便开发者维护软件的包依赖。将开发过程中新增的包增加进这个列表汇总,避免的setup.py安装依赖时漏掉软件包。
- 方便读者明确项目使用了哪些Python包。
- 这个文件的格式是每一行包含一个包依赖的说明,通常是flask>=0.10这种格式,要求是这个格式能够pip识别,这样就可以简单的同构pip install -r requirements.txt来把所有Python需要的包依赖都安装好。
import其他目录的模块:
例如,bin/下的foo.py要导入core/main.py。
import os #导入os模块 import sys #导入sys模块 BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) #动态获取项目目录的绝对路径 sys.path.append(BASE_DIR) #将项目目录的绝对路径加入到系统变量中 from core import main #即可导入core目录下的main.py main.login() #执行main模块中的入口函数
保持学习,否则迟早要被淘汰*(^ 。 ^ )***
