[Python自学] 爬虫(2)爬虫基础流程
一、简单使用requests库
1.安装requests库
pip install requests
2.使用GET请求
import requests response = requests.get("https://www.baidu.com") # 使用get请求https://www.baidu.com首页 print(response.status_code) # 相应状态码,这里是200,表示请求成功 for key, value in response.headers.items(): # 循环打印响应头字段信息 print(key, ':', value) print(response.content) # 响应体
3.response中的信息
从返回的response中,我们可以看到响应的状态码、数据等。我们也能从里面获取请求的相关信息:
print(response.request.headers) # 该响应对应的请求头 print(response.request.url) # 请求头中的url print(response.url) # 响应中的url
二、GET请求
1.设置请求头字段
import requests headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.122 Safari/537.36"} response = requests.get("https://www.163.com", headers=headers)
2.带参数的请求
import requests headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.122 Safari/537.36", "cookie": "thw=cn; cna=XfAvF/WfbzICAXZwS36odZhN; v=0; cookie2=1c29389f2765e5b57433e46971794e19; t=32c93c0595de5fa4ac923efe86a6e4d3; _tb_token_=7ef6b598bb6ab; _samesite_flag_=true; lgc=leo4774177; dnk=leo4774177; tracknick=leo4774177; enc=kJQptvQhNiVigwCxKEAnEgLF%2FG%2FzrPDUEyVcFYEIcKNJQIvOVAM8vU9APEXeJgmFHPRnUkg2cOdVRsB7LbmtmQ%3D%3D; hng=CN%7Czh-CN%7CCNY%7C156; alitrackid=www.taobao.com; lastalitrackid=www.taobao.com; _m_h5_tk=f2796601f2d2f724588abe575b940bef_1588160049010; _m_h5_tk_enc=c55b606489c16402ff55e420a68657e3; sgcookie=EyyqTySJv9JdF7Zgo%2BnMa; uc3=nk2=D8br2h10hHkJBg%3D%3D&lg2=U%2BGCWk%2F75gdr5Q%3D%3D&vt3=F8dBxGR%2FgWPZNKmy%2BDE%3D&id2=UoLbu597%2By4B; csg=e6308e2d; skt=ce7de72f86b60910; existShop=MTU4ODIyNTI2Mw%3D%3D; uc4=nk4=0%40DeV01byyk1siAre0SBM69Cf%2FPJjq&id4=0%40UOrtaE4TUdpesPykiU%2FT25PLWRw%3D; _cc_=V32FPkk%2Fhw%3D%3D; tfstk=cfohBD0AC2zBMI3Ih9ZIeMXDeBLAZR7UM0uqbD7yB9dtNAiNiG7NuXX9I8hn2a1..; mt=ci=-1_0; JSESSIONID=194B8D8F3828E01EEB30CF25A813D535; uc1=cookie16=VT5L2FSpNgq6fDudInPRgavC%2BQ%3D%3D&cookie21=VT5L2FSpde4B2i0oOYgwnA%3D%3D&existShop=true&pas=0&cookie14=UoTUMtddIDHZ0A%3D%3D; l=eBrVL1heQo4A_sZDBOfwFurza77OKIRAguPzaNbMiT5P_vfp5pflWZb2mvL9CnGVh6AeR3yAaP02BeYBqCmWfdW22j-laCHmn; isg=BF9fY2KlfaTs2XmEBTEOn6zO7rPpxLNm4M7ve_GstI5VgH8C-ZaJttxaRhD-GIve"} p = {"q": "apple"} response = requests.get("https://s.taobao.com/search", headers=headers, params=p)
这样,请求的URL就会被拼接成 https://s.taobao.com/search?q=apple 。可以通过以下代码查看请求的url:
p = {"q": "apple"}
response = requests.get("https://s.taobao.com/search", headers=headers, params=p)
print(response.request.url) # https://s.taobao.com/search?q=apple
如果我们的参数是中文,则会被进行url编码:
p = {"q": "苹果"}
response = requests.get("https://s.taobao.com/search", headers=headers, params=p)
print(response.request.url) # https://s.taobao.com/search?q=%E8%8B%B9%E6%9E%9C
关于URLencoder和URLdecoder可以通过一些网页就可以轻松查询,或者使用urllib库进行编解码:
import urllib print(urllib.parse.unquote("%E8%8B%B9%E6%9E%9C")) # URL解码为“苹果”
三、POST请求
1.post的请求数据
post请求与get请求不同的是,post带数据。
以百度翻译为例:

通过F12查看第一个请求的请求体数据(检测语言为加泰罗尼亚语):
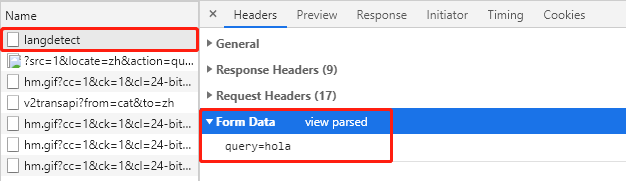
可以看到,在请求体中,数据为 query=hola 。
然后又通过AJAX发了第二个请求(具体翻译操作):
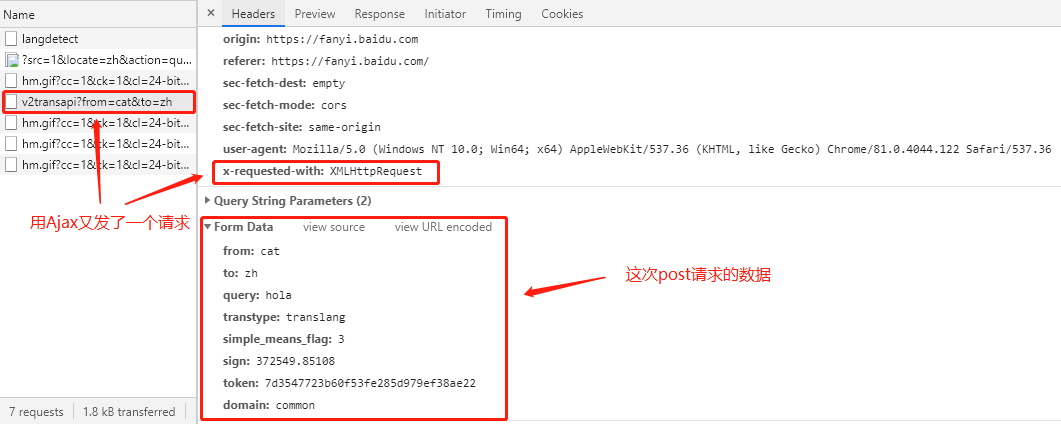
查看第二次请求的响应数据:
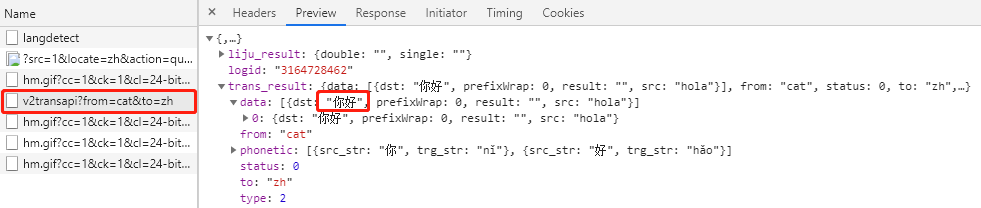
可以看到,响应数据为JSON数据,通过Preview可以看到解析后的响应数据。
四、使用代理
当我们频繁的爬取一个站点的数据时,就会被服务器发现我们是爬虫,这时可以使用代理IP来进行访问,隐藏自己的真实IP地址。
import requests headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.122 Safari/537.36"} proxies = {"http": "http://122.4.43.57:3472"} r = requests.get("http://www.163.com", proxies=proxies, headers=headers)
当我们在高频率的访问一个站点时,使用一个代理IP池来轮换请求,可以使服务器不容易发现异常爬取。
目前requests库也支持socks5代理:
proxies = {"http": "socks5://127.0.0.1:10808", "https": "socks5://127.0.0.1:10808"}
这样就可以爬取国外网站的数据了。
五、处理Cookie和session
当我们请求的站点需要cookie信息时(例如需要登陆),则可以使用requests.session来实现。
1.爬取需要登陆的页面
流程:
1)实例化requests.session
2)先使用session实例发送请求,登录网站,保存网站存放的cookie
3)再使用session实例请求登录之后的页面,session实例能够自动携带登录成功时保存的cookie
import requests headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.122 Safari/537.36" } post_data = {"LoginName": "leokale", "Password": "52XXXXXXX"} s = requests.session() s.post("https://account.cnblogs.com/signin", data=post_data, headers=headers) # 登录成功后,cookie保存在session实例中 r = s.get("https://i-beta.cnblogs.com/articles", headers=headers) # 再次请求登录后的页面时,自动携带cookie
2.使用已存在的cookie
我们知道cookie是生效时间是根据服务器设置cookie的时候指定的,所以通常cookie的生效时间还是比较长的。
所以,我们无需每次爬取都重新发送POST请求登录来获取cookie,而可以使用一个已经存在的cookie。
也就是说,我们可以配合另一个专门获取cookie的爬虫程序,将获取到的cookie放到数据库中,然后直接使用这些cookie。
使用已存在的cookie有两种方式:
1)将cookie放在headers中
import requests headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.122 Safari/537.36", "Cookie":"_ga=GA1.2.1763380430.1588126925; _gid=GA1.2.13520718.1588733383; .Cnblogs.AspNetCore.Cookies=CfDJ8B9DwO68dQFBg9xIizKsC6SeXD4EOsoadZWxDLDEB38Ycamn0RvCE_7cOuqmM0y_vunGMhlhnvCSf-uTk5PprrQ7NhmpuSVCh4dzl2LyRGF0yMnblMIKE71xaMkBGAi3p0mFHnTvZGg71gu8fr8fy4xvCJFt1Rfuxkk3SCHyU-hVtog3ctqOCF3GR1yCdUviI3jupFGE3e811x16Lej8cJ_WrvOhf6yKSySiZ5pvMWv0G0f4AP2mv-soR93knUuh7_alrcSPJpxyT4aXVyr5y21_qHjZxc8f6BmkCWvVosTFlyf-N5lWZSK6MCH_QHqE-k-fIv9DfDPciZmUCc31sbvpIVNNFMA6-vpwIIPNwCmQaCcc3OaQxPTYoess9oKR1EOQ3xGhKJ4gYoAWyAKhToqZuSyU9D8ijGJZBazs43HICt1Z_igvN4rhB8muQZ9bC1LEauUDdvonvNg50KCCp7lsjMERZBhoJQCrJsP66-utStlunlX4Lyskbc6-V75QOThDzgcghhCSwi-dhmarJtRtYzKHfLGW34rIuVGpZibo; .CNBlogsCookie=D5479A0623EB6C5040D046B53587AFB3346647BE02320CD77496D7494B0B15412CC9635A4E1E9F691A5F20D0470FA9E6094A22E1F5F858FC0BAF4FBEECD6AA956B94DA2FE40E133BAE61E9AC10B793D42DB9F6D8; _gat=1" } s = requests.session() r = s.get("https://i-beta.cnblogs.com/articles", headers=headers)
2)指定一个cookie字典
将cookie字符串处理成一个字典:
import requests headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.122 Safari/537.36" } # cookie字符串 cookies = "_ga=GA1.2.1763380430.1588126925; _gid=GA1.2.13520718.1588733383; .Cnblogs.AspNetCore.Cookies=CfDJ8B9DwO68dQFBg9xIizKsC6SeXD4EOsoadZWxDLDEB38Ycamn0RvCE_7cOuqmM0y_vunGMhlhnvCSf-uTk5PprrQ7NhmpuSVCh4dzl2LyRGF0yMnblMIKE71xaMkBGAi3p0mFHnTvZGg71gu8fr8fy4xvCJFt1Rfuxkk3SCHyU-hVtog3ctqOCF3GR1yCdUviI3jupFGE3e811x16Lej8cJ_WrvOhf6yKSySiZ5pvMWv0G0f4AP2mv-soR93knUuh7_alrcSPJpxyT4aXVyr5y21_qHjZxc8f6BmkCWvVosTFlyf-N5lWZSK6MCH_QHqE-k-fIv9DfDPciZmUCc31sbvpIVNNFMA6-vpwIIPNwCmQaCcc3OaQxPTYoess9oKR1EOQ3xGhKJ4gYoAWyAKhToqZuSyU9D8ijGJZBazs43HICt1Z_igvN4rhB8muQZ9bC1LEauUDdvonvNg50KCCp7lsjMERZBhoJQCrJsP66-utStlunlX4Lyskbc6-V75QOThDzgcghhCSwi-dhmarJtRtYzKHfLGW34rIuVGpZibo; .CNBlogsCookie=D5479A0623EB6C5040D046B53587AFB3346647BE02320CD77496D7494B0B15412CC9635A4E1E9F691A5F20D0470FA9E6094A22E1F5F858FC0BAF4FBEECD6AA956B94DA2FE40E133BAE61E9AC10B793D42DB9F6D8; _gat=1" # 将其处理为字典,每个cookie使用"; "分隔 cookie_dict = {i.split("=")[0]: i.split("=")[1] for i in cookies.split("; ")} print(cookie_dict) s = requests.session() r = s.get("https://i-beta.cnblogs.com/articles", headers=headers, cookies=cookie_dict)
===

