[计算机基础] 汇编学习(3)
一、编译和链接
1.概念
编译:就是将我们写的汇编代码翻译成机器码,可以供机器执行。
链接:将多个翻译好的机器码连接起来,形成最终的执行程序。
2.编译和链接为什么分开
为什么要将编译和链接分开呢?为什么不直接编译生成可执行文件?
这是因为,当我们的代码量非常大时,例如100W行代码,编译的过程可能耗时比较久,在这种情况下,如果我们的代码错误比较多,则进行修改调试的难度会很高,耗时也很长。如果我们将这些代码分割成很多小块,每一块单独进行编译(翻译),最终再将所有编译好的程序段(编译好,代表没有错误)连接起来,就可以形成最终的执行程序。如果在编译期间某段代码出现错误,我们进行修改后,只需要编译该小块代码就可以了。
# 如果是全部一起编译
100W行代码 ----> exe # 需要5分钟
# 编译+链接
t1.asm ----> OBJ # 可能只需要1秒
t2.asm ----> OBJ
t3.asm ----> OBJ
...
...
...
t1000.asm ----> OBJ
LINK ----> exe
二、汇编源程序
1.EXE可执行程序
思考一个问题,系统在执行一个exe程序的时候,他是如何知道该程序需要多大的内存?
因为在exe文件中,除了包含整个程序的代码,还包含了一些信息,这些信息包含了文件有多大,程序入口在哪里等等,这些信息叫做描述信息。
系统就是根据这些描述信息,对寄存器进行相关的设置。
2.start伪指令
在前面的章节中,我们看到过如下代码:
assume cs:code,ds:data,ss:stack data segment db 128 dup (0) data ends stack segment stack db 128 dup (0) stack ends code segment start: mov ax,stack mov ss,ax mov sp,128 call cpy_Boot mov ax,1001H mov ax,1002H mov ax,1003H mov ax,1004H mov ax,4C00H int 21H cpy_Boot: mov bx,1001H mov bx,1002H mov bx,1003H mov bx,1004H ret code ends end start
这段代码中,除了包含我们当前比较熟悉的汇编指令,还有一些不太了解的指令,例如start,这些指令叫做伪指令。
伪指令是用来告诉编译器(翻译软件)一些信息,从而使编译器生成程序的描述信息。例如start伪指令就是将我们设置的程序入口地址在哪里记录在exe文件的描述信息中,然后系统通过这个描述文件的内容去设置CS:IP,当然还有其他一些寄存器。
3.剖析exe中的描述信息
我们对上面的代码(t1.asm汇编文件)进行编译和连接,在途中生成t1.map文件(描述信息):
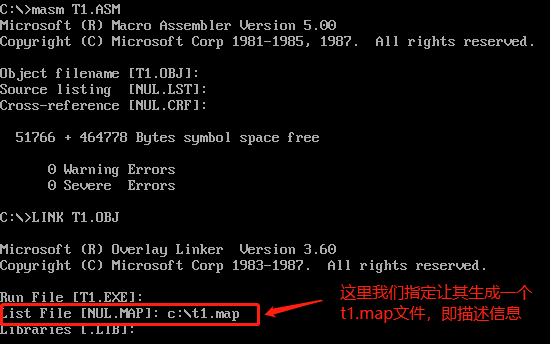
打开t1.map文件:
Start Stop Length Name Class 00000H 0007FH 00080H DATA 00080H 000FFH 00080H STACK 00100H 00128H 00029H CODE Program entry point at 0010:0000
我们可以看到,数据段、栈、代码(指令)段的长度和起始位置都已经记录在其中,最后还包含程序的入口点。
由于在我们代码中,start指向的是 Code segment 的开始,所以 Program entry point at 0010:0000 和CODE段的开始地址是一致的(标黄部分)。
如果我们将start修改到后面的指令,那么描述信息中的入口点也会改变。
4.assume伪指令
在程序的最开头,我们可以看到assume伪指令:
assume cs:code,ds:data,ss:stack data segment ... data ends stack segment stack ... stack ends code segment ... code ends
以 stack segment stack 为例,第一个stack是我们取的名字,可以任意取。后面的stack表示这是一个栈,没有这个stack会报Wraning。
系统是如何知道数据段、栈、代码段从哪里开始,就是通过 assume cs:code,ds:data,ss:stack 来得知的。这个assume伪指令用于假设指令地址为CS:code拼接成的物理地址,数据段的地址为DS:data拼接成的物理地址,栈地址为SS:stack拼接成的物理地址。
将以上代码写得更一般些:
assume cs:c,ds:d,ss:s d segment ... d ends s segment stack ... s ends c segment ... c ends
也就是说assume中的偏移地址的名字和下面段的名字一致就可以。
5.汇编代码与描述信息对应关系
在之前的获得的t1.map中:
Start Stop Length Name Class 00000H 0007FH 00080H DATA 00080H 000FFH 00080H STACK 00100H 00128H 00029H CODE Program entry point at 0010:0000
我们看到描述信息中每个段在内存中的顺序是DATA->STACK->CODE。
对应我们汇编代码t1.asm中的结构:
assume cs:code,ds:data,ss:stack data segment ... data ends stack segment stack ... stack ends code segment ... code ends
可以看到,汇编代码中对segment的定义顺序也是DATA->STACK->CODE。那么这两个顺序有没有必然的联系呢???
答案是这两者的顺序的对应的,当我们调换了代码的顺序(将CODE段放在代码的最前面),描述信息中的顺序也会改变:
assume cs:code,ds:data,ss:stack code segment start: mov ax,stack mov ss,ax mov sp,128 call cpy_Boot mov ax,1001H mov ax,1002H mov ax,1003H mov ax,1004H mov ax,4C00H int 21H cpy_Boot: mov bx,1001H mov bx,1002H mov bx,1003H mov bx,1004H ret code ends data segment db 128 dup (0) data ends stack segment stack db 128 dup (0) stack ends end start
对应的描述信息变为:
Start Stop Length Name Class 00000H 00028H 00029H CODE 00030H 000AFH 00080H DATA 000B0H 0012FH 00080H STACK Program entry point at 0000:0000
这里要注意一个细节,就是 end start 语句。这个语句是与前面的start伪指令成对出现的,代表所有汇编语言结束,
6.符号体系
在我们编写的汇编代码中,一部分是汇编指令,而有些是符号体系(编译器来执行的)。例如
mov bx,160*10 + 40*2 add ax,bx
注意,以上的指令都是在t1.asm汇编源文件中(还未经过编译器编译)。其中的 160*10 + 40*2 就是符号体系(而且这里的数字是十进制的,十六进制后面要带H),是有编译器来进行计算的,然后将计算的结果放在mov指令中。而第二句的add是汇编指令,是CPU来执行的。
7.程序退出
在前面的汇编代码中,有一段代码是这样的:
mov ax,4C00H int 21H
这段指令的意思是程序结束,将内存和寄存器换给系统,因为内存是有限的,如果程序不归还,则系统最终会耗尽内存。
将 4C00H 放到AX中,AH高位的4C表示程序带参数返回DOS系统,AL低位的00表示参数的值。
int 21H 中的int表示 interrupt ,即终端程序的意思,运行这个指令后,系统会根据前面设置的AH中的值来执行对应的操作。
注意,在debug中,一般的指令有 t来执行,而 int 21H 这条指令是用 p来执行:

8.PSP区
在程序被debug加载时,从ds:0开始的256个byte就是PSP区。
PSP区是用来系统与程序之间进行通信的。

从中我们可以看到程序的名称T1.EXE。
三、编译器规则
字母开头的数据前面要加0:
mov ax,0B800H
注意区分十进制和十六进制:
mov ax,10 ; 10进制 mov ax,10H ; 16 进制
汇编语言中使用 ";" 来注释:
mov ax,bx ; 将bx寄存器的值赋值到ax寄存器中
====
