[计算机基础] 汇编学习(2)
一、指令
1.指令的执行过程
在[计算机基础] 汇编学习(1)中,我们知道了CPU是通过CS:IP来确定哪些数据是指令的。
那么,CPU执行指令的简单流程如下:
1.CPU从CS:IP所指向的内存单元中读取指令,存放到指令缓存器中。 2.IP寄存器的值 = IP旧值 + 被读取指令的长度。 3.执行指令缓存器中的指令,回到步骤1。
2.指令的长度
我们使用 debug -u 查看指令的时候,可以看到指令的长度:
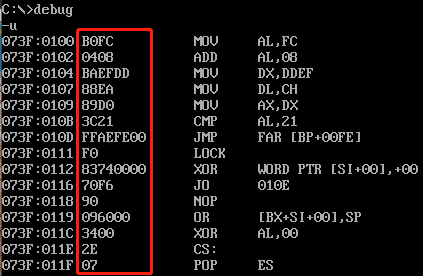
可以看到,每个指令的长度都不一定相等,从1 byte~n byte不等,至于指令的长度,是由指令集规定的,CPU会按照指令集来读取指令,就不会读错长度了。
3.jmp指令
jmp是jump的简写,JMP指令用于修改CS和IP这两个寄存器,可以决定CPU从哪里读取指令。
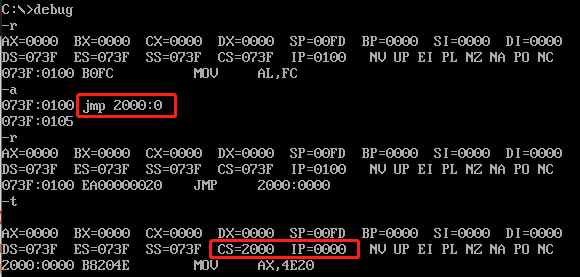
可以看到,我们使用JMP指令将CS寄存器的值修改为2000,将IP寄存器的值修改为0000。
注意:在8086 计算机中,只能通过JMP去修改CS:IP的值,而不能通过MOV指令去直接修改。
当然,以下指令是可以运行的:
JMP AX # 将AX寄存器中的值赋给IP寄存器
4.CALL指令
CALL指令也是一个跳转指令,他的实现类似于C语言中的执行一个函数,如下所示:
start: mov ax,stack mov ss,ax mov sp,128 call cpy_Boot # 跳转到cpy_Boot对应的位置,并保存下一条指令,即mov ax,1001的位置 mov ax,1001 mov ax,1002 cpy_Boot: mov bx,1001 mov bx,1002 ret # 获取下一条指令mov ax,1001的位置并跳转过去,类似于C语言的return
在执行到call指令时,先将call指令的下一条指令(mov ax,1001)的内存地址保存起来(内存中),然后执行cpy_Boot这个位置的指令,执行到ret指令的时候,取回保存在内存中的下一条指令(mov ax,1001)的地址,然后跳转过去接着执行后面的指令。
4.SUB指令
减法,类似于加法。使用前面的值减去后面的值,然后保存在前面的寄存器中。
SUB AX,BX # 相当于AX=AX-BX
二、debug调试工具
前面我们已经使用过了debug工具的一些功能,这节我们系统的了解一下debug工具的用法。
debug工具中,包含一下一些功能:
-r 查看和改变寄存器中的内容(注意,这是debug工具的功能,不是汇编语言) -d 查看内存中的内容(当成普通数据,即16进制数据),例如 d 1000:0 查看1000:0开始的128个字节的内容, d 1000:0 F 查看0~F即16个字节内容(一行)。 -u 查看内存中的内容,翻译成指令格式 -a 可以以汇编指令的形式输入指令(默认修改当前CS:IP位置),也可以指定位置 a 2000:0 -t 执行当前CS:IP所指向的指令 -e 改写内存中的内容,例如e 2000:0000,即从2000:0000位置开始写入数据,除了实时输入,还可以在后面直接跟ascii码,例如e 2000:0 "0123456789",他会从2000:0开始将值填为0123456789对应的16进制。
三、内存的访问
在第二章中,我们提到了CALL指令,在调用CALL指令时,会将他的下一条指令的地址保存起来。那么保存在什么地方呢?答案是内存中。
1.字型数据在内存中的排列顺序
一个字型数据占用2byte空间,那么他们在内存中存放时的排列顺序是怎么样的?
我们在2000:0的位置输入几个指令:
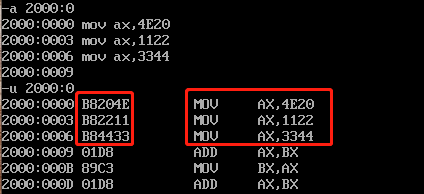
可以看到 MOV AX,4E20 指令对应的机器码是 B8204E , MOV AX,1122 指令对应的机器码是 B82211 。
可以看出,数据在内存中的顺序和我们指令中的顺序是反的,这是因为,对于16bit寄存器来说,4E被存储在AH(即高8位寄存器)中,20被存储在AL(即低8位寄存器)中。而在内存中,B8204E中的B8位于2000:0,20位于2000:1,4E位于2000:2。
所以,我们可以得出一个结论:
高地址内存 存放的是 字型数据的 高位字节
低地址内存 存放的是 字型数据的 低位字节
按以上内存中的数据,我们回答几个问题:
1.地址2000:0中存放的字节数据是多少?? 答案:B8H 2.地址2000:0中存放的字型数据是多少?? 答案:20B8H 3.地址2000:2中存放的字节数据是多少?? 答案:4EH 4.地址2000:2中存放的字型数据是多少?? 答案:B84EH 5.地址2000:1中存放的字型数据是多少?? 答案:4E20H
2.DS寄存器(从内存中读取数据)
前面我们了解了CS寄存器的作用(存储指令的段地址)。
DS寄存器用于存储访问数据的段地址。
首先,我们看一下当前1000:0地址的数据:
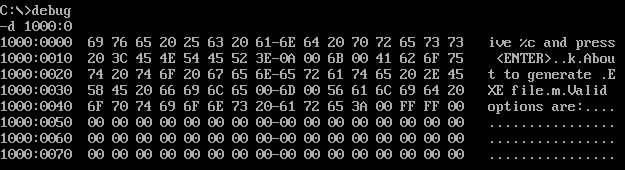
我们要读取其中的数据,先将DS寄存器的值修改为1000:

然后将1000:0开始的数据,一个一个赋值给AX寄存器:
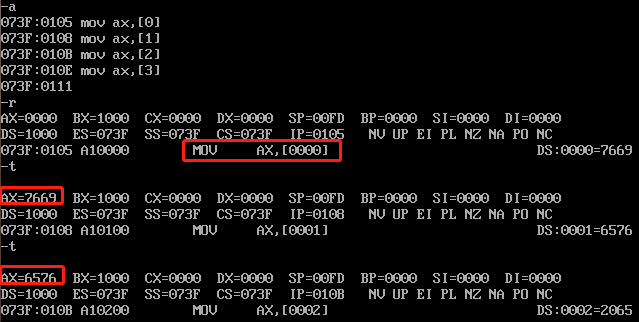
对比一下1000:0开始的数据,由于我们使用的是 MOV AX,[0] ,也就是将ds:0这个位置的数据拷贝到AX中,由于AX为16bit寄存器,所以就拷贝了两个byte,而又根据之前介绍的内存存储顺序,所以拷贝过来放到AX中的数据为 7669H 。同理,拷贝ds:1的数据,实际上拷贝的是ds:1和ds:2两个byte,所以是 6576H 。
注意:一个内存地址只存放8bit的数据,即一个byte。当我们以 MOV AX,[0] 这种方式拷贝数据的时候,实际上拷贝了0和1两个位置的数据,即16bit,2byte,因为AX是16bit寄存器。如果是 MOV AL,[0] ,由于AL是8bit寄存器,则只会拷贝0位置的数据。
3.拷贝寄存器数据到内存
在第2节中,我们通过ds寄存器中的数据作为内存段地址,然后配合偏移地址 [n] 实现了对内存数据的地位,然后通过MOV指令将数据从内存中拷贝到寄存器中。
那么,我们将操作反过来,就可以实现将寄存器中的数据拷贝到内存中:
MOV [0],AX MOV [2],AL
假设,AX中数据为4E20H,那么拷贝后,ds:0的数据为20H,ds:1的数据为4EH,ds:2的数据为20H。
四、栈
栈是一段连续的内存单元,也就是一段连续的内存地址。
栈的一个特性就是后进先出,有两个动作,一个叫入栈,一个叫出栈。
1.栈的数据从哪里来
栈的数据来自于寄存器或内存。使用 PUSH 指令将寄存器或内存的数据压到栈中,放在栈顶标记的上面(也就是最后一个数据的上面)。
2.栈顶标记
对于一个栈来说,始终有一个标记来表示最后一个数据在栈中的位置,在8086机器中,使用SS寄存器和SP寄存器组合出来的物理地址来作为栈顶标记。
SS寄存器:存储栈顶标记的段地址
SP寄存器:存储栈顶标记的偏移地址
当我们进行入栈和出栈操作时,栈顶标记会随着改变:
PUSH AX # 栈顶标记的偏移地址SP = SP - 2 POP BX # 栈顶标记的偏移地址SP = SP + 2
PUSH AX的意思是将AX寄存器中的数据(字型数据,16bit)压入栈,栈顶标记本来指向的是原来的最后一个数据,新压入一个数据后,栈顶标记进行了修改。
POP BX的意思是将栈中最后一个数据弹出栈,拷贝到BX寄存器中,栈顶标记也要进行修改。
3.栈在内存中的形态
从第2节中,我们可以看出,PUSH的时候SP-2,POP的时候SP+2。
也就是说栈底位于内存的高位,而栈顶位于内存的低位。
4.创建和操作一个栈
我们要在内存创建一个栈,需要关注两个事情:
1)栈底在哪里 2)栈空间有多大
栈顶在哪里,很好解决,就是SS:SP指向的物理位置。
而栈空间有多大,主要决定权在SP的值。
例如,我们在2000:0位置创建一个栈:

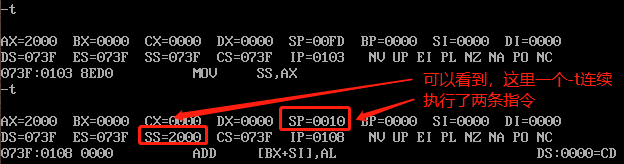
从上图中可以看到,在我们给SS赋值的时候,一个-t指令直接将SP赋值也完成了,我们可以理解为栈创建过程是一个自动化的原子操作,避免出错。
通过设置SS和SP,我们就创建了一个栈,现在来回答之前的问题:
1)栈底在哪里? 答案:栈底在SS:SP组成的物理位置,也就是20010H这个位置。 2)栈的空间有多大? 答案:栈的空间从SS:0 ----> SS:SP这个范围。也就是SP的大小,为10H,即16个byte。每次push是2个byte,也就是说这个栈最多push 8次。
我们尝试往里面存储数据和取出数据:
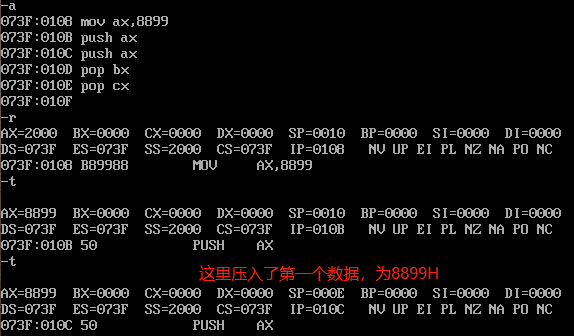

可以看到,我们压入的第一个8899H(这里也要注意高位和低位的问题,88位内存高位,99位内存低位)。
这里还要注意8899数据的前面:

在创建栈之前,2000:0开始的内存数据都是0,但创建栈之后,里面多出了一些数据,这些数据实际上是一些寄存器的数据,可以观察一下:

至于,为什么栈中要保存这些寄存器的值,与栈实现的功能有关,我们在后面会了解到具体原因。
继续执行指令:

最后我们观察一下栈中的情况:

可以看到,经过两次push和两次pop,栈的栈顶标记回到了SP=0010,说明栈中已经没有数据了。并且我们可以看到,栈中保存的寄存器的值发生了变化,出现了3个8899,分别代表AX、BX、CX三个寄存器中的值(AX是我们赋予的值,BX和CX是pop进去的值)。
5.栈的越界
假设我们的栈空间大小只有16byte,也就是只能支持push 8次(第4节中的例子)。
当我们push第9次的时候就会发生栈顶越界。
我们先执行8次push ax,将栈填满:

可以看到,我们已经存入了8个8899H数据。然后查看一下SP寄存器的数据:

可以看到SP的数据为0000H。
我们执行第9次push ax:
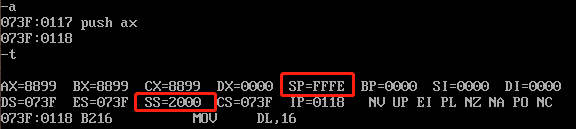
可以看到,执行第9次push ax后,SP继续减了2,变成了FFFEH,而SS不变。
此时,我们查看一下2000:FFF0位置的内存:

可以看到,我们的数据被成功的存储到内存中(栈以外的空间)。
这种将数据存储到栈之外的操作叫做栈越界,这是非常危险的操作,因为栈之外的内存空间可能保存的是非常重要的系统数据或指令,一旦破坏,可能引起一连串的错误,甚至导致系统崩溃。但对于8086CPU来说,没有提供这种越界的检验和警告功能,全部需要靠我们人工来控制。
PUSH操作可以引起栈顶的越界,同样的,POP操作也可以引起栈底的越界。栈底越界后的数据属于其他程序或系统的数据,如果被弹出,也会导致错误。
6.栈的最大空间
从前面的例子其实已经可以看出,栈的大小是等于SP的最大值的,也就是范围为0~FFFF。
FFFFH = 65536字节 = 32768字
所以,在8086机器中,一个栈最大能够容纳65536个字节(64KB)的数据,32768个字型数据,也就是支持32768次push。
那么,我们要创建一个最大空间的栈,SP应该赋值多少:
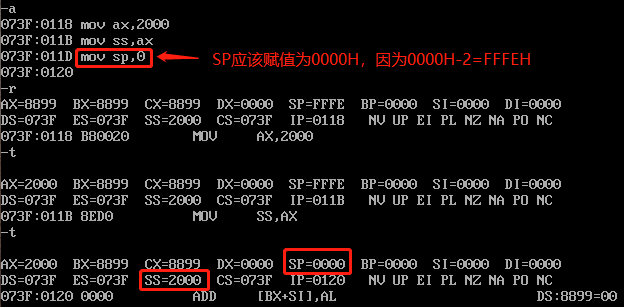
也就是说SP赋值为0000H时,栈的空间是最大的。这里千万注意,别以为SP=FFFFH的时候空间最大,因为FFFF实际上是没有存数据的。
7.栈操作实例
该实例的目标是搞清楚CALL指令执行时,将下一条指令的地址保存到了什么地方???
我们写一段汇编代码:
assume cs:code,ds:data,ss:stack data segment db 128 dup (0) data ends stack segment stack db 128 dup (0) stack ends code segment start: mov ax,stack mov ss,ax mov sp,128 call cpy_Boot mov ax,1001H mov ax,1002H mov ax,1003H mov ax,1004H mov ax,4C00H int 21H cpy_Boot: mov bx,1001H mov bx,1002H mov bx,1003H mov bx,1004H ret code ends end start
代码中,我们只关心标黄部分代码,其余暂时不用关心。
使用MASM.EXE和LINK.EXE将t1.asm编译连接成t1.exe后,我们使用debug.exe工具来调试:
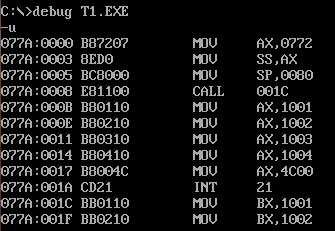
可以看到,t1.exe中的汇编指令如上图所示。我们边调试边解释:
1)第一句代码中的0772H,代表一个段地址,将其赋值给AX。然后在第二句中赋值给了SS,作为栈的段地址。
2)第三句 MOV SP,0080 表示将栈的偏移地址(栈底)赋值为0080H。
3)第四句,运行CALL指令的时候,我们要观察SP的变化:
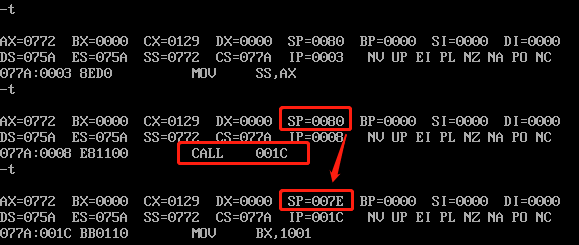
可以看到SP减了2,说明栈中有数据存入,我们看一下存入的数据是什么:
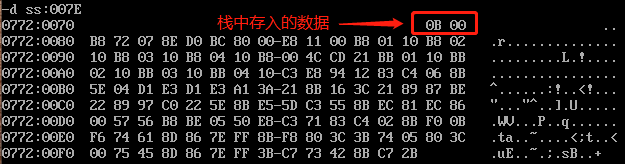
我们看到, 000BH 正是CALL指令后面一个指令的偏移地址,对应指令为 MOV AX,1001 。
除了将这个数据存放到了栈中,我们还可以发现CS:IP中的IP也发生了变化:
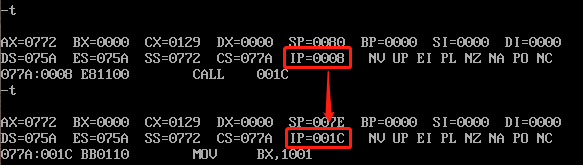
也就是说CALL指令进行的跳转,我们查看一下跳转到的CS:IP中的指令是什么:
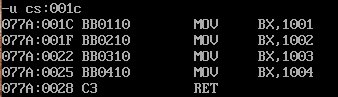
可以看到,跳转地址中的指令就是我们 CALL cpy_Boot 这段指令(代码中我们的别名叫cpy_Boot,但经过编译后,直接为偏移地址,即 CALL 001C )。
4)继续运行,后面运行的是 MOV BX,1001 , MOV BX,1002 , MOV BX,1003 , MOV BX,1004 。
5)运行RET指令的时候,会从栈中将保存的 000B 取出,我们观察一下栈SP的变化:
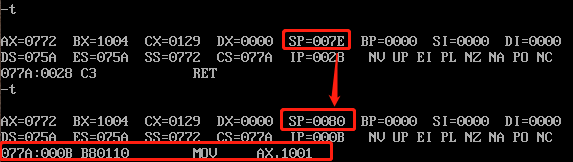
可以看到,执行完RET指令后,栈中数据被弹出,栈顶标记恢复到 0080H ,并且可以看到,下一条指令的地址为 000BH ,正好回到了CALL指令的下一条指令,即 MOV AX,1001 。
6)后面的执行过程,略。。。
总结:从以上实例过程,我们可以看到,栈可以用于临时存储数据使用。当我们执行一个CALL指令时,会为下一条指令保存一个记录(放在栈中),当CALL中的所有指令都执行完后,使用RET指令取回保存在栈中的记录,然后继续完成后续指令的执行。
思考(可能不正确):从汇编中栈的使用实例可以想到,为什么高级语言中的递归调用,层数过多时,会出现栈溢出的问题。当函数层层嵌套时,每嵌套一次,就会在栈中保留一个指令地址。从前面我们知道了栈是有最大空间的(8086CPU为32768个字),也就是说当我们的函数嵌套超过这个数时,栈就不够用了,当栈越界时,可能就会影响到系统或其他应用的内存数据,从而导致程序崩溃。
8.栈的其他用途
栈还可以作为复制内存数据的一种手段,例如要复制从10000H开始的一段数据到20000H,还要以逆序存放。
1)先设置ss为1000H,设置sp为0,也就是将10000H作为栈顶 2)将ds设置为2000H 3)然后使用POP ds:[E]、POP ds:[C]、POP ds:[A]、POP ds:[8]、POP ds:[6]、POP ds:[4]、POP ds:[2]、POP ds:[0]
这样就可以将10000H开始的8个字型数据逆序的拷贝到20000H开头的内存位置。
===

