[Python自学] Flask框架 (4) (Request&Session上下文管理、redis保存session、App&g上下文管理)
一、上下文管理理论基础
1.线程数据隔离
多线程访问一个数据:当内存中存在一个数据,多个线程都可以对其进行修改,如果要保证数据的一致性,则需要对其进行加锁。
多线程操作自己的数据:当需要每个线程都只能操作自己的数据,而该数据需要放置到一个全局的空间(例如全局变量)。则需要对其进行数据隔离,即线程只能访问自己存储的数据。
在threading模块中,我们可以使用threading.local来实现线程之间的数据隔离:
import threading import time # 定义一个threading.local对象 obj = threading.local def run(index): # 写入xxx=index obj.xxx = index # 10个线程 for i in range(10): t = threading.Thread(target=run, agrs=(i,)) t.start()
虽然每个线程都对obj写入了一个名为"xxx"的变量,值为自己的index。但是threading.local对象为各个线程做了数据隔离。
他的原理是,为每一个线程都开辟一块内存空间,实际上就是利用一个字典,将线程的唯一表示作为键key,线程存入的值放到该键对应的value中。如下所示:
# threading.local使用一个字典来保存各个线程的数据 { 1233: {'xxx': 0}, # 第0个线程的tid为1233,存入的值放在对应的字典中 1234: {'xxx': 1}, 1235: {'xxx': 2}, 1236: {'xxx': 3}, 1237: {'xxx': 4}, 1238: {'xxx': 5}, 1239: {'xxx': 6}, 1240: {'xxx': 7}, 1241: {'xxx': 8}, 1242: {'xxx': 9}, }
2.用字典实现一个threading.local类
import threading class Local(object): DIC = {} # DIC字典用于存放各线程的数据,通过key来隔离 # 从DIC中线程tid对应的字典中获取值 def __getattr__(self, item): tid = threading.get_ident() if tid in self.DIC: return self.DIC[tid].get(item) else: return None # 设置一个值,类似obj.xxx = 1 def __setattr__(self, key, value): # 获取该线程的tid tid = threading.get_ident() # 如果DIC中存在键为tid的数据 if tid in self.DIC: self.DIC[tid][key] = value else: self.DIC[tid] = {key: value} # 创建一个Local对象 obj = Local() def run(index): # 使用Local对象保存各线程的数据 obj.xxx = index # 开启10个线程 for i in range(10): t = threading.Thread(target=run, args=(i,)) t.start() # 打印最后的值 print( obj.DIC) # {2852: {'xxx': 0}, 13520: {'xxx': 1}, 10756: {'xxx': 2}, 7488: {'xxx': 3}, 8484: {'xxx': 4}, 13924: {'xxx': 5}, 10668: {'xxx': 6}, 10252: {'xxx': 7}, 11348: {'xxx': 8}, 10736: {'xxx': 9}}
3.将Local支持协程
我们实现的Local类,达到了和threading.local一样的效果,可以隔离线程的数据。但是我们如果使用的是协程,则需要对其进行扩展。
import threading try: import greenlet # 使用协程时,将协程获取唯一标识的方法赋值给get_ident get_ident = greenlet.getcurrent print("使用协程") except Exception as e: print("使用线程") # 没有使用协程时,将线程获取唯一标识的方法赋值给get_ident get_ident = threading.get_ident class Local(object): DIC = {} # DIC字典用于存放各线程的数据,通过key来隔离 # 从DIC中线程tid对应的字典中获取值 def __getattr__(self, item): tid = get_ident() if tid in self.DIC: return self.DIC[tid].get(item) else: return None # 设置一个值,类似obj.xxx = 1 def __setattr__(self, key, value): # 获取该线程的tid tid = get_ident() # 如果DIC中存在键为tid的数据 if tid in self.DIC: self.DIC[tid][key] = value else: self.DIC[tid] = {key: value} # 创建一个Local对象 obj = Local() def run(index): # 使用Local对象保存各线程的数据 obj.xxx = index # 开启10个线程 for i in range(10): t = threading.Thread(target=run, args=(i,)) t.start() # 打印最后的值 print(obj.DIC)
要扩展支持协程,其实很简单,就是让唯一标识从线程的唯一标识替换为协程的唯一标识。
4.线程、协程数据隔离和Flask的关系
虽然threading.local和Flask没有直接的关系,但是Flask中实现了一套利用此原理的数据隔离机制。类似我们第3.节中实现的支持线程和协程的版本。
在Flask中,请求相关的数据和session等数据都是通过上下文管理的。我们可以将上下文看成一个全局的数据存放点。而我们需要对其数据进行隔离,因为Flask有可能底层会使用多线程、协程等方式来运行。
多个线程或协程会同时接受来自用户的请求,而如果不进行数据隔离,则可能数据会相互覆盖,从而导致数据错误。
二、阅读Flask上下文源码所需的一些小知识点
1.偏函数
偏函数就是利用functools.partial帮我们为某个函数传入一些固定的参数:
import functools # 原本的函数 def add(a, b): return a + b # 使用functools.partial将add函数变为偏函数 new_func = functools.partial(add, 100) # 调用偏函数,只需要传递剩下的参数 res = new_func(1) print(res) # 打印结果为101
2.类的继承关系
类的继承关系可以参考:https://www.cnblogs.com/leokale-zz/p/8472560.html 中的第7节《多继承》和第8节《新式类和经典类的区别》。
我们调用父类方法,通常有两种方式:
class Foo(Base_1, Base_2): def func(self): # 方式一,使用super调用 super(Foo,self).func() # 如果在类内部调用父类方法,可以省略super的参数。即super().func() # 方式二,直接使用父类名调用 Base_1.func(self)
第二种方式很直接,指定父类名调用,如果父类没有对应的方法,则会报错。
而第一种方式super是安装继承顺序来逐级查找被调用的方法的。
例如以下代码:
class Base_1(object): def func(self): print("Base_1.func") class Base_2(object): def func(self): print("Base_2.func") class Foo(Base_1, Base_2): def func(self): # 方式一,使用super调用 super(Foo, self).func() # 打印 Base_1.func # 方式二,直接使用父类名调用 Base_2.func(self) # 打印 Base_2.func if __name__ == '__main__': f = Foo() f.func()
Foo类继承于Base_1和Base_2类,而Base_1和Base_2类继承自object。
我们执行f.func(),可以得到打印结果super执行了Base_1的func方法。
而当我们将Base_1的func方法去掉后(只有Base_2才有func方法):
class Base_1(object): pass class Base_2(object): def func(self): print("Base_2.func") class Foo(Base_1, Base_2): def func(self): # 方式一,使用super调用 super(Foo, self).func() # 打印 Base_2.func # 方式二,直接使用父类名调用 Base_2.func(self) # 打印 Base_2.func if __name__ == '__main__': f = Foo() f.func()
此时,super找到了Base_2的func方法。
所以,super可以执行父类的方法,但不一定会执行父类的方法。当Base_1和Base_2都没有func方法时,super还回去object类中查找func方法,结果是找不到,则报错。
我们总结一下super的查找顺序:

总结:super不是找父类,而是从左往右在多个父类中查找,如果找到了,则直接调用(前提是方法名和参数都一致,如果参数不一致,也要报错),不往后面继续查找,如果直到object都还没找到,则报错。
3.__getattr__、__setattr__以及__delattr__
在python的类中,有两个很重要的特殊方法__getattr__(self,item)和__setattr__(self,key,value):
class Foo(object): def __getattr__(self, item): print(item) def __setattr__(self, key, value): print(key, value)
这两个方法是在使用该类对象进行"."操作的时候会被调用。例如:
if __name__ == '__main__': obj = Foo() obj.name = 'Alex' # __setattr__被调用,打印name Alex obj.age # __getattr__被调用,打印age
注意,我们平时在使用对象的"."操作时,一般不会定义这两个方法。所以默认情况下,都会找到object类的__setattr__和__getattr__来执行,而object类的这两个方法默认的功能就是设置属性和获取属性的值。
如果我们在自己定义的类中重写了这两个方法,那么就可以自己设置"."操作的行为。
考虑以下特殊场景:(构造函数的属性初始化也会触发__setattr__方法)
class Foo(object): def __init__(self): self.storage = {} def __getattr__(self, item): print(item) def __setattr__(self, key, value): print(key, value) if __name__ == '__main__': obj = Foo() obj.name = 'Alex'
在该类的构造方法中,我们初始化了一个对象属性storage。那么按照我们前面所叙述的__setattr__的触发机制。这里应该打印以下信息:
storage {}
name Alex
即,构造函数中的self.storage = {}也会触发__setattr__方法。因为self代表Foo的对象obj(由__new__(Foo)产生),然后使用"."操作设置了storage。
__delattr__:
del obj.name
__delattr__也一样,使用del删除指定的属性,但只能使用"."操作。
注意:__setattr__、__getattr__、__delattr__应该和__setitem__、__getitem__、__delitem__区分。__xxxitem__是使用字典形式操作,例如obj['name'] = Alex,del obj['name']。
具体可以参考:[Python自学] day-7 (静态方法、类方法、属性方法、类的其他、类的来源、反射、异常处理、socket) 中《类的其他内容-7节》
4.基于列表实现栈
python中使用列表实现栈结构,很简单:
class Stack(object): def __init__(self): self._list = [] def push(self, x): self._list.append(x) def pop(self): return self._list.pop() def top(self): if self._list: return self._list[-1] else: return None if __name__ == '__main__': s = Stack() s.push('Alex') # 从栈顶压入"Alex" s.push('Leo') # 从栈顶压入"Leo" print(s.pop()) # 从栈顶弹出"Leo" print(s.pop()) # 从栈顶弹出"Alex" print(s.top()) # s中已经没有数据,打印None
三、源码中的Local类(数据隔离)
在前面的第一章《上下文管理理论基础》中的第3节,我们实现了一个Local类,用于线程、协程的数据隔离。
Flask中其实也是这种实现方式,我们来看看源码是怎么样的:
try: # 使用使用协程,则使用getcurrent作为唯一标识符获取方法 from greenlet import getcurrent as get_ident except ImportError: # 如果使用线程,则使用get_ident作为唯一标识符获取方法 try: from thread import get_ident except ImportError: from _thread import get_ident class Local(object): # 用于限定向外暴露的属性 __slots__ = ("__storage__", "__ident_func__") # 构造函数,由于我们要在这个类中重写object的__setattr__方法,所以构造函数初始化属性直接调用object原始的__setattr__方法 # __storage__私有属性用于存放每个线程或协程的数据 # __ident_func__私有属性用于存放获取唯一标识符的方法(线程为get_ident,协程为getcurrent) def __init__(self): object.__setattr__(self, "__storage__", {}) object.__setattr__(self, "__ident_func__", get_ident) # 返回__storage__的迭代器 def __iter__(self): return iter(self.__storage__.items()) # def __call__(self, proxy): # """Create a proxy for a name.""" # return LocalProxy(self, proxy) # 释放整个线程或协程对应的数据 def __release_local__(self): self.__storage__.pop(self.__ident_func__(), None) # 获取数据(对应各自线程或协程) def __getattr__(self, name): try: return self.__storage__[self.__ident_func__()][name] except KeyError: raise AttributeError(name) # 设置数据(对应各自线程或协程) def __setattr__(self, name, value): ident = self.__ident_func__() storage = self.__storage__ try: storage[ident][name] = value except KeyError: storage[ident] = {name: value} # 删除线程或协程自己的数据 def __delattr__(self, name): try: del self.__storage__[self.__ident_func__()][name] except KeyError: raise AttributeError(name)
注释掉的部分,我们不用关心。特别注意标黄的部分。
我们可以发现,Flask源码中的Local类,和我们自己实现的Local类几乎相同。我们判断字典中是否存在键使用的是if else,而源码中使用的是异常捕获(可以学习借鉴)。
四、源码中的LocalStack类(利用Local实现数据隔离的栈结构)
在Local类中,我们可以使用obj.attr的方式来往字典中存放值(线程或协程隔离的)。那么,我们可以在该字典中维持一个栈:
if __name__ == '__main__': obj = Local() obj.stack = [] obj.stack.append('Alex') obj.stack.append('Leo') print(obj.stack.pop()) print(obj.stack.pop())
虽然这样可以操作字典中的stack,但不是很方便。在Flask源码中实现了一个代理类LocalStack来操作字典中的stack。源码如下:
# 操作stack结构的代理类 class LocalStack(object): # 构造函数,创建一个Local实例(里面有一个字典__storage__) def __init__(self): self._local = Local() # 释放一个线程对应的数据 def __release_local__(self): self._local.__release_local__() # 获取线程或协程唯一标识符的方法 @property def __ident_func__(self): return self._local.__ident_func__ # 设置获取唯一标识符的方法 @__ident_func__.setter def __ident_func__(self, value): object.__setattr__(self._local, "__ident_func__", value) # def __call__(self): # def _lookup(): # rv = self.top # if rv is None: # raise RuntimeError("object unbound") # return rv # # return LocalProxy(_lookup) # 往字典中的stack键对应的栈中放数据(对应调用线程) def push(self, obj): rv = getattr(self._local, "stack", None) # 如果没有stack栈 if rv is None: # 设置一个空栈,rv和self._local.stack都指向该空列表 self._local.stack = rv = [] # 往栈中放数据 rv.append(obj) return rv # 从栈顶弹出数据 def pop(self): stack = getattr(self._local, "stack", None) # 如果栈不存在,返回None if stack is None: return None elif len(stack) == 1: # 如果栈中只有一个数据,则释放该线程或协程对应的栈 release_local(self._local) # 这里等价于self._local.__release_local__() # 将栈的唯一一个数据返回 return stack[-1] else: return stack.pop() # 获取栈顶元素,如果没有则返回None @property def top(self): """The topmost item on the stack. If the stack is empty, `None` is returned. """ try: return self._local.stack[-1] except (AttributeError, IndexError): return None
同样的,不用关心注释掉的部分。
我们可以看到LocalStack类在构造函数中初始化了一个Local对象,在该对象中的字典里,每个线程或协程都对应一个空间。而这个空间里只有一个元素,就是一个栈"stack"。
而LocalStack所提供的操作,例如push、pop、top等都是针对这个栈的。
所以LocalStack提供了一个线程或协程隔离的栈结构存储空间。
五、源码中对request和session的存储
在第4章中,我们了解了Flask源码对LocalStack的实现,知道其利用LocalStack对线程或协程进行数据隔离,并在其中使用栈结构来保存数据。
那么,我们看看LocalStack是如何存储和读取用户的上下文的。
1.模拟RequestContext
参考[Python自学] Flask框架 (3) (路由、CBV、自定义正则动态路由、请求处理流程、蓝图)中的请求处理流程章节,我们知道,当用户请求到达后,Flask将用户的请求信息和session都封装到了一个RequestContext类的对象中(叫做ctx变量)。
假设简单实现一个RequestContext类,模拟源码中的RequestContext类:
# 模拟一个RequestContext类,其中包含用户请求和session class RequestContext(object): def __init__(self): self.request = 'my request' self.session = 'my session'
2.仿照源码实现ctx的存储和读取
# 模拟一个RequestContext类,其中包含用户请求和session class RequestContext(object): def __init__(self): self.request = 'my request' self.session = 'my session' if __name__ == '__main__': # 创建保存上下文实例的栈(支持数据隔离) _request_ctx_stack = LocalStack() # 当用户请求到达时,request和session被封装到RequestContext中 # 将封装好的RequestContext对象保存到栈中 _request_ctx_stack.push(RequestContext()) # 根据参数,取栈中上下文里的request或session def _lookup_req_object(arg): ctx = _request_ctx_stack.top return getattr(ctx, arg) import functools # 通过functools.partial将其封装成两个偏函数,方便使用(源码中的request和session还包了一层LocalProxy类,可以看后面LocalProxy的章节) request = functools.partial(_lookup_req_object, 'request') session = functools.partial(_lookup_req_object, 'session') # 通过request和sesison获取上下文中的数据 print(request()) print(session())
3.源码中ctx存储的过程
1)请求到达时,服务器调用Flask的__call__方法,然后在其中调用wsgi_app方法:
def __call__(self, environ, start_response): return self.wsgi_app(environ, start_response)
2)在wsgi_app方法中实例化ctx,
def wsgi_app(self, environ, start_response): # 实例化RequestContext,在其中封装Request对象,并将session初始化为空 ctx = self.request_context(environ) error = None try: try: # 调用ctx的push方法 ctx.push() ... ...
3)ctx.push()中,将自己压入栈
def push(self): ... ... # 将自己(ctx对象)压入栈_request_ctx_stack _request_ctx_stack.push(self) ... ...
4)_request_ctx_stack是LocalStack的实例,该实例全局定义的
# globals.py # context locals _request_ctx_stack = LocalStack()
4.ctx存储过程图
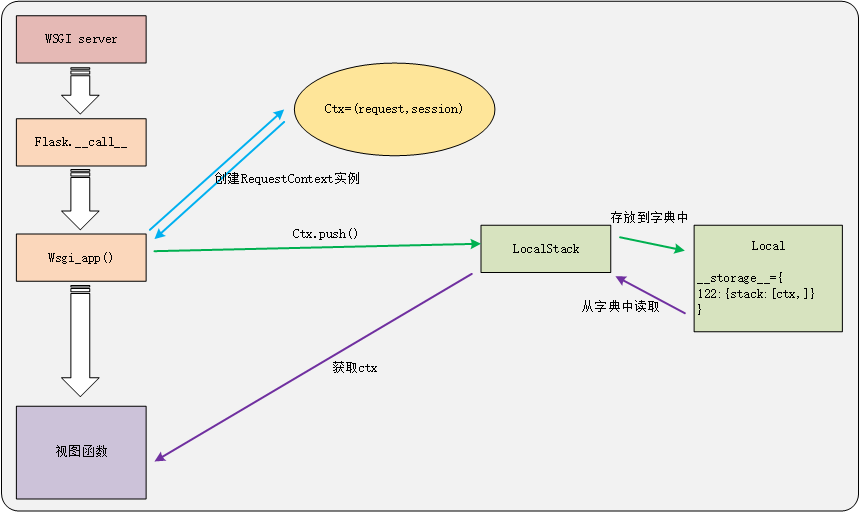
5.session的存储过程
总体来说,由于session和request都被封装在ctx对象中(RequestContext类的对象)。所以存储的过程是一样的。
但是session和request的不同点在于,数据获取的时机不同。
对于request:我们在wsgi_app()函数中,创建ctx对象的时候,就将environ作为参数传递进去,environ被封装成Request对象,然后放在ctx对象中。
对于session:wsgi_app()函数创建好ctx的时候,session只是被初始化为空,我们看RequestContext的构造函数源码:
class RequestContext(object): def __init__(self, app, environ, request=None, session=None): self.app = app if request is None: request = app.request_class(environ) self.request = request self.url_adapter = None try: self.url_adapter = app.create_url_adapter(self.request) except HTTPException as e: self.request.routing_exception = e self.flashes = None self.session = session ... ...
在ctx.push()中,ctx被压入到栈之后,对session进行了赋值:
def push(self): ... ... _request_ctx_stack.push(self) ... ... if self.session is None: session_interface = self.app.session_interface self.session = session_interface.open_session(self.app, self.request) if self.session is None: self.session = session_interface.make_null_session(self.app) ...
源码中的app.session_interface实际上是 SecureCookieSessionInterface类,session_interface是其一个对象,然后调用其中的open_session来对session进行赋值。
通过open_session源码,可以大致了解session的赋值过程:
def open_session(self, app, request): s = self.get_signing_serializer(app) if s is None: return None # 从cookie中获取名为session的数据(默认名为session) val = request.cookies.get(app.session_cookie_name) # 如果没有session,则session为空的SecureCookieSession对象 if not val: return self.session_class() max_age = total_seconds(app.permanent_session_lifetime) try: # 对拿到的数据做反序列化 data = s.loads(val, max_age=max_age) return self.session_class(data) except BadSignature: return self.session_class()
六、源码中的LocalProxy
1.LocalProxy类工作流程
在第五章的2.仿照源码实现ctx的存储和读取 中可以看到,我们使用functools.partial制造了两个偏函数,用于从ctx中获取request和session。如下代码:
request = functools.partial(_lookup_req_object, 'request') session = functools.partial(_lookup_req_object, 'session') # 通过request和sesison获取上下文中的数据 print(request()) print(session())
这是我们仿造源码实现的功能。真正的源码还对偏函数进行了一层封装,即使用LocalProxy类,
current_app = LocalProxy(_find_app) request = LocalProxy(partial(_lookup_req_object, "request")) session = LocalProxy(partial(_lookup_req_object, "session")) g = LocalProxy(partial(_lookup_app_object, "g"))
其中的current_app和g我们将在后面的章节中讨论。
LocalPorxy的源码如下:
class LocalProxy(object): # 构造函数,将request或session偏函数传入,即local参数 def __init__(self, local, name=None): # 将其保存到self.__local中 object.__setattr__(self, "_LocalProxy__local", local) ... def _get_current_object(self): # 返回self.__local(),即返回request或session对象 if not hasattr(self.__local, "__release_local__"): return self.__local() ... # 当我们使用request.xxx的时候就会从request对象中帮我们取值 def __getattr__(self, name): if name == "__members__": return dir(self._get_current_object()) return getattr(self._get_current_object(), name) # 当我们使用request['xxx']取值时,帮我们从request对象中取值 __getitem__ = lambda x, i: x._get_current_object()[i] ... ...
从源码中,我们可以看到,self.__local(self._LocalProxy__local)就是request和session的偏函数,所以self.__local()得到的就是request和session对象。
LocalProxy类中实现了__getattr__、__setattr__、__getitem__、__setitem__等方法,用于帮我们从request和session中取值。
所以,综上所述,LocalProxy就是帮我们从Request和Session对象中取值的中间代理,只是为了让我们取值更加方便。
2.修改后的ctx存储过程图
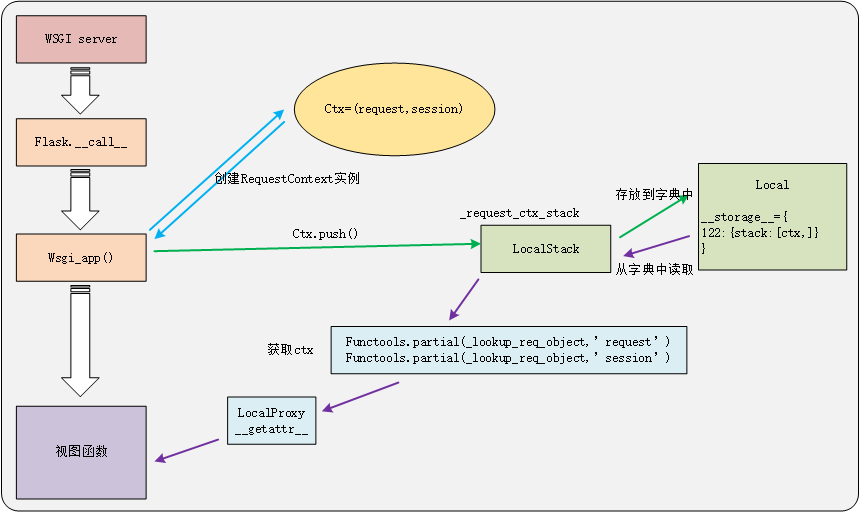
图中多了LocalProxy部分和偏函数部分。
在偏函数中,通过_lookup_req_object获取request和session对应的对象(ctx=_request_ctx_stack.top())。
在LocalProxy中通过__getattr__等特殊方法来获取request和session对象中的值。
七、flask-session组件
在第五章对session工作流程的解析中,我们知道从加密cookie中获取session,以及将session写到加密cookie中。都是使用的一个叫做SecureCookieSessionInterface的类。
那么,我们如果想将session存储到redis数据库中,则只需要使用其他的类来替换SecureCookieSessionInterface类即可。
1.安装flask-session
pip install flask-session
2.导入flask-session
from flask_session import Session
以前的老版本可能是:
from flask.ext.session import Session
3.使用flask-session
# 在Flask的全局配置中指定使用redis来保存session app.config['SESSION_TYPE'] = 'redis' # 然后将app对象传递给Session,在里面原本的app.session_interface = SecureCookieSessionInterface()会被替换为RedisSessionInterface() Session(app)
我们解析以下Session类的源码:
import os # 导入Session支持的各种Interface,例如redis、memcache、文件系统、MongoDB、SQL from .sessions import NullSessionInterface, RedisSessionInterface, \ MemcachedSessionInterface, FileSystemSessionInterface, \ MongoDBSessionInterface, SqlAlchemySessionInterface class Session(object): # 构造函数,app对象被传入 def __init__(self, app=None): self.app = app # 如果app不为空 if app is not None: self.init_app(app) # 调用init_app(app) def init_app(self, app): # 在这里替换app.session_interface=SecureCookieSessionInterface() app.session_interface = self._get_interface(app) # 在这个方法中,根据我们指定的SESSION_TYPE来返回对应的Interface类 def _get_interface(self, app): # 从全局配置复制一份 config = app.config.copy() # 注意,这里都是使用的setdefault,即配置不存在才设置 config.setdefault('SESSION_TYPE', 'null') config.setdefault('SESSION_PERMANENT', True) config.setdefault('SESSION_USE_SIGNER', False) config.setdefault('SESSION_KEY_PREFIX', 'session:') config.setdefault('SESSION_REDIS', None) config.setdefault('SESSION_MEMCACHED', None) config.setdefault('SESSION_FILE_DIR', os.path.join(os.getcwd(), 'flask_session')) config.setdefault('SESSION_FILE_THRESHOLD', 500) config.setdefault('SESSION_FILE_MODE', 384) config.setdefault('SESSION_MONGODB', None) config.setdefault('SESSION_MONGODB_DB', 'flask_session') config.setdefault('SESSION_MONGODB_COLLECT', 'sessions') config.setdefault('SESSION_SQLALCHEMY', None) config.setdefault('SESSION_SQLALCHEMY_TABLE', 'sessions') # 如果我们在全局配置中设置了SESSION_TYPE为redis,则返回RedisSessionInterface类 if config['SESSION_TYPE'] == 'redis': session_interface = RedisSessionInterface( config['SESSION_REDIS'], config['SESSION_KEY_PREFIX'], config['SESSION_USE_SIGNER'], config['SESSION_PERMANENT']) # 如果指定使用Memcached,则返回MemcachedSessioninterface类 elif config['SESSION_TYPE'] == 'memcached': session_interface = MemcachedSessionInterface( config['SESSION_MEMCACHED'], config['SESSION_KEY_PREFIX'], config['SESSION_USE_SIGNER'], config['SESSION_PERMANENT']) # 如果指定文件系统,则返回FileSystemSessionInterface类 elif config['SESSION_TYPE'] == 'filesystem': session_interface = FileSystemSessionInterface( config['SESSION_FILE_DIR'], config['SESSION_FILE_THRESHOLD'], config['SESSION_FILE_MODE'], config['SESSION_KEY_PREFIX'], config['SESSION_USE_SIGNER'], config['SESSION_PERMANENT']) # Mongodb,返回MongoDBSessionInterface类 elif config['SESSION_TYPE'] == 'mongodb': session_interface = MongoDBSessionInterface( config['SESSION_MONGODB'], config['SESSION_MONGODB_DB'], config['SESSION_MONGODB_COLLECT'], config['SESSION_KEY_PREFIX'], config['SESSION_USE_SIGNER'], config['SESSION_PERMANENT']) # SqlAlchemy,返回SqlAlchemySessionInterface类 elif config['SESSION_TYPE'] == 'sqlalchemy': session_interface = SqlAlchemySessionInterface( app, config['SESSION_SQLALCHEMY'], config['SESSION_SQLALCHEMY_TABLE'], config['SESSION_KEY_PREFIX'], config['SESSION_USE_SIGNER'], config['SESSION_PERMANENT']) else: # 如果都不符合,则返回NullSessionInterface类 session_interface = NullSessionInterface() return session_interface
我们可以看到,最核心的过程就是根据全局配置中指定的SESSION_TYPE类返回对应的Interface类,来代替默认的加密cookie。
4.redis的配置
如果我们在全局配置中指定了使用redis,那么肯定需要给Flask指定redis的IP、端口等信息。
我们首先观察RedisSessionInterface类构造函数的源码:
def __init__(self, redis, key_prefix, use_signer=False, permanent=True): if redis is None: from redis import Redis redis = Redis() self.redis = redis self.key_prefix = key_prefix self.use_signer = use_signer self.permanent = permanent
可以看到,RedisSessionInterface接收4个参数,第一个参数是redis实例,第二个参数是session存到redis中名字的前缀。第三个参数是否使用加密盐(对sessionid进行加密),第四个参数
此时,我们再看Session类源码中,使用RedisSessionInterface的时候传入的四个参数对应的全局配置项:
if config['SESSION_TYPE'] == 'redis': session_interface = RedisSessionInterface( config['SESSION_REDIS'], config['SESSION_KEY_PREFIX'], config['SESSION_USE_SIGNER'], config['SESSION_PERMANENT'])
从上述代码可以看出全局配置项SESSION_REDIS应该配置一个redis实例,SESSION_KEY_PREFIX应该配置一个前缀字符串。
所以,我们应该这样配置使用redis:
from flask import Flask from flask_session import Session import redis
app = Flask(__name__) app.config['SESSION_TYPE'] = 'redis' app.config['SESSION_REDIS'] = redis.Redis(host='111.111.111.111',port=6379,password='123456') Session(app) if __name__ == '__main__': app.run()
5.如何从redis中读取session
我们查看RedisSessionInterface类中的open_session方法源码:
def open_session(self, app, request): # 先从cookie中去拿session的id sid = request.cookies.get(app.session_cookie_name) # 如果sid为空(例如第一次请求) if not sid: # 生成一个sid,格式是uuid4 sid = self._generate_sid() # 返回一个空的session return self.session_class(sid=sid, permanent=self.permanent) # 是否使用加密盐 if self.use_signer: # 获取app中设置的加密盐字符串 signer = self._get_signer(app) if signer is None: return None try: # 解密 sid_as_bytes = signer.unsign(sid) sid = sid_as_bytes.decode() except BadSignature: sid = self._generate_sid() return self.session_class(sid=sid, permanent=self.permanent) if not PY2 and not isinstance(sid, text_type): sid = sid.decode('utf-8', 'strict') # 根据获取到的sid加上前缀,从redis中获取session的值 val = self.redis.get(self.key_prefix + sid) # 如果值不为空,则发反序列化,然后返回RedisSession对象(其中包含session数据和sid) if val is not None: try: data = self.serializer.loads(val) return self.session_class(data, sid=sid) except: return self.session_class(sid=sid, permanent=self.permanent) return self.session_class(sid=sid, permanent=self.permanent)
如果是第一次请求,则cookie没有带sessionid,所以会新建一个随机字符串(uuid4)作为sessionid,并且创建一个空的session对象。
如果是第二次请求,则cookie中带着sessionid,则从cookie中获取该sessionid。如果使用了加密盐,则使用盐解密。然后得到解密后的sid,加上我们指定的前缀字符串作为key,从redis中获取对应的session数据。如果获取到数据,则反序列化,并将其封装成session对象返回。
6.如何将session保存到redis
当用户请求处理过程中,对session进行了修改(例如保存了一个值在session中)。请求处理完毕后,在返回响应之前,会在RedisSessionInterface类中的save_session方法中将修改后的session保存到redis中,并且将sessionid设置到cookie中。
我们看一下save_session方法的源码:
def save_session(self, app, session, response): domain = self.get_cookie_domain(app) path = self.get_cookie_path(app) # 删除session if not session: if session.modified: self.redis.delete(self.key_prefix + session.sid) response.delete_cookie(app.session_cookie_name, domain=domain, path=path) return httponly = self.get_cookie_httponly(app) secure = self.get_cookie_secure(app) expires = self.get_expiration_time(app, session) val = self.serializer.dumps(dict(session)) # 给存放在redis中的session加上默认超时时间(31天) self.redis.setex(name=self.key_prefix + session.sid, value=val, time=total_seconds(app.permanent_session_lifetime)) # 如果使用加密盐 if self.use_signer: # 加密 session_id = self._get_signer(app).sign(want_bytes(session.sid)) else: # 否则不加密 session_id = session.sid # 将session的id写到响应的cookie中 response.set_cookie(app.session_cookie_name, session_id, expires=expires, httponly=httponly, domain=domain, path=path, secure=secure)
当参数中session为空时,执行删除session操作,从redis中删除对应session数据,主要用于当用户退出登录时。
当session不为空时,首先序列化session字典(对象.__dict__转换为字典)。然后将其存入redis,并且设置超时时间为默认的31天(可在全局配置中修改)。
如果使用了加密盐,则对sid进行加密,然后设置到response的cookie中,返回给用户。
八、app和g上下文
在前面的章节,我们了解了request+session形成的上下文管理流程。流程中使用了一个Local、一个LocalStack、两个LocalProxy,其中Local用于维护一个线程或协程隔离的字典,用于存放按线程或协程唯一标识符作为键的数据。
然后,LocalStack用于在Local的字典中维护一个栈结构,每个线程或协程对应一个栈,而用户的请求和session组成的ctx(上下文实例)就存放在这个栈中。我们通过LocalStack将请求对应的ctx压入和弹出,并且通过LocalProxy来方便的获取ctx中包含的Request和Session对象中的值。
LocalProxy为Flask用户提供的方便的request和session操作接口。
1.app和g的上下文
除了我们已经了解的request+session上下文,Flask中还有一组上下文管理流程,他们也使用一个Local、一个LocalStack以及两个LocalProxy。该上下文用于管理Flask的对象app以及g。
我们首先看以下全局对象的源码(globals.py):
# context locals # request+session的LocalStack,其中维护了一个Local对象 _request_ctx_stack = LocalStack() # app和g的LocalStack,其中也维护了一个Local对象 _app_ctx_stack = LocalStack() # app使用的LocalProxy current_app = LocalProxy(_find_app) request = LocalProxy(partial(_lookup_req_object, "request")) session = LocalProxy(partial(_lookup_req_object, "session")) # g使用的LocalProxy g = LocalProxy(partial(_lookup_app_object, "g"))
2.app和g上下文流程
app和g的上下文存储流程和request、session的存储流程相似。
request和session的上下文是在app.wsgi_app方法中创建的,然后调用了ctx.push将其压入对应的LocalStack。
但是app和g的上下文是在ctx.push方法中创建的,而且先于ctx压入LocalStack之前被压入自己对应的LocalStack。
源码:
def push(self): ... ... # 这里先从app上下文管理的LocalStack中去获取app_ctx app_ctx = _app_ctx_stack.top # 如果获取的app_ctx为空或者其中的app不是当前app if app_ctx is None or app_ctx.app != self.app: # 则新创建一个AppContext对象。app_ctx = AppContext()对象 app_ctx = self.app.app_context() # _app_ctx_stack.push(self) 将self,即app_ctx放入_app_ctx_stack(LocalStack) app_ctx.push() self._implicit_app_ctx_stack.append(app_ctx) else: self._implicit_app_ctx_stack.append(None) if hasattr(sys, "exc_clear"): sys.exc_clear() # 然后将ctx放入_request_ctx_stack(另一个LocalStack) _request_ctx_stack.push(self) ... ...
源码中,蓝色部分是ctx压入request、session对应的LocalStack。
黄色部分是app_ctx压入app、g对应的LocalStack。
3.使用app和g
如何使用保存在LocalStack中的app和g,这和使用request以及session是一样的,直接导入使用即可(他们是在globals.py中定义的全局变量)。
# 直接导入并使用 from flask import Flask,current_app,g
其中current_app就是app,current_app和g都对应一个LocalProxy对象。但是使用的话,像操作app本身一样操作即可。
4.g是什么
由于g和session的处理流程很相似,我们可以对他们进行对比:
1)session中的值是每次请求到才从加密cookie或redis中获取的。而g并不获取值。
2)响应返回的时候,session中的值被重新写入cookie或redis,然后session被销毁。当然g也会被销毁。
3)session是线程隔离的。g也是线程隔离的。
我们可以得出结论。g和session实际上的生命周期是一样的,都是一个请求的生命周期。
g和全局变量的对比:
1)普通的全局变量时在程序启动时就定义的,可以在任何时候任何地方直接使用。
2)g保存在全局变量Local对象中,但是其被线程唯一标识符所隔离,并且根据请求--->响应的周期进行创建和销毁。
所以得出结论,g只是针对某个请求的生命周期中的全局变量。在这个请求的生命周期内,可以在不同的地方存入和取出值。
5.g有什么用
当在一个请求的生命周期中,我们可以用g作为存放公共变量的地方。
例如使用g可以仿造出一个session:
@lg.before_request def before(): print('before') g.session = {} g.session['name'] = 'Leo' # 使用蓝图来调用装饰器(而不是使用app) @lg.route('/login', methods=['GET', 'POST']) def login(): if request.method == 'GET': print(g.session.get('name')) return "login"
因为before函数和login函数都在一个请求生命周期。但是对于每个请求,g中的内容是不一样的。
##

