[NoSQL数据库] Redis基础
一、NoSQL
NoSQL:Not only SQL。
NoSQL特点:
- 不支持SQL语法
- 存储结构和传统关系型数据库中的关系表不同,NoSQL中的数据采用KV形式
- NoSQL没有通用的语言,每种NoSQL数据库都有自己的API和语法,以及擅长的业务场景
- NoSQL的产品种类多:例如MongoDB、Redis、Hbase、Cassandia hadoop等。
NoSQL与SQL数据库的比较:
- SQL数据库适用于关系特别复杂的数据查询场景,NoSQL反之。
- 事务特性:SQL对事务的支持非常完善,而NoSQL反之(也支持事务)。
- 两者在不断的取长补短,呈现融合趋势。
二、Redis简介
Redis是一个开源的数据库,使用ANSI C语言编写,支持网络访问,可基于内存,也可日志持久化,是一种K-V数据库,并提供多种语言的API。
在2013年5月之前,其开发由VMware赞助,而2013年5月至2015年6月期间,其开发由毕威拓赞助,从2015年6月开始,Redis的开发由Redis Labs赞助。

Redis是NoSQL阵营中的一员,它通过多种键值数据类型来适应不同场景下的存储需求,借助一些高层的接口使其可以胜任缓存、队列系统的不同角色。
Redis提供了Java、C/C++、C#、 PHP 、JavaScript、 Perl 、Object-C、Python、Ruby、Erlang、Golang等多种主流语言的客户端。
三、Redis的特性
1.支持持久化,可以将内存数据保存到磁盘中,重启的时候可以再次加载进行使用。
2.Redis不仅仅支持简单的KV数据类型,还提供list、set、zset、hash等数据结构的存储。
3.Redis支持数据的备份,即master-slave模式的数据备份。
四、Redis的优势
1.性能极高:读速度可达110000次/s,写速度可达81000次/s
2.丰富的数据类型:list、set、hash、string以及Order set等数据类型
3.天生原子性:数据访问是原子性的,不存在访问数据冲突的问题
4.丰富的特性:Redis还支持发布订阅、通知、key过期的特性。
五、Redis安装与配置
1.Redis源码编译安装
在CentOS7下:
# 安装gcc编译器 yum install gcc -y # 下载redis wget http://download.redis.io/releases/redis-5.0.7.tar.gz # 解压缩 tar xzf redis-5.0.7.tar.gz # 移动文件夹到/usr/local中 mv redis-5.0.7 /usr/local/ # 进入redis目录 cd /usr/local/redis-5.0.7 # 编译 make all
# 安装tcl yum install tcl -y # 运行redis测试 make test
# 安装到/usr/local/bin下 make install
进入/usr/local/bin下查看安装好的redis命令:
[root@centos-base bin]# ll total 32772 -rwxr-xr-x. 1 root root 4366808 Jan 5 14:20 redis-benchmark -rwxr-xr-x. 1 root root 8125200 Jan 5 14:20 redis-check-aof -rwxr-xr-x. 1 root root 8125200 Jan 5 14:20 redis-check-rdb -rwxr-xr-x. 1 root root 4807880 Jan 5 14:20 redis-cli lrwxrwxrwx. 1 root root 12 Jan 5 14:20 redis-sentinel -> redis-server -rwxr-xr-x. 1 root root 8125200 Jan 5 14:20 redis-server
2.Redis配置
拷贝redis.conf:
cd /etc mkdir redis cd /usr/local/redis-5.0.7 cp redis.conf /etc/redis/redis.conf
修改配置:
vi /etc/redis/redis.conf
bind 192.168.1.181 127.0.0.1 # 服务IP地址 port 6379 # 服务端口 daemonize yes # 是否以守护进程形式运行 dbfilename dump.rdb # 持久化数据文件名称 dir /var/lib/redis # 持久化数据文件存放位置 logfile /var/log/redis/redis-server.log # 日志文件存放位置 database 16 # 一共16个数据库,编号1~15 slaveof # 设置主从复制(用于分布式)
注意:持久化数据文件和日志文件的存放地址,要事先创建存放文件目录。
cd /var/lib mkdir redis cd /var/log mkdir redis
配置文件参考:
(转自https://blog.csdn.net/ljphilp/article/details/52934933)


1 # Redis configuration file example 2 3 # Note on units: when memory size is needed, it is possible to specify 4 # it in the usual form of 1k 5GB 4M and so forth: 5 # 内存大小的配置,下面是内存大小配置的转换方式 6 # 7 # 1k => 1000 bytes 8 # 1kb => 1024 bytes 9 # 1m => 1000000 bytes 10 # 1mb => 1024*1024 bytes 11 # 1g => 1000000000 bytes 12 # 1gb => 1024*1024*1024 bytes 13 # 14 # units are case insensitive so 1GB 1Gb 1gB are all the same. 15 # 内存大小的配置,不区分大小写 16 17 ################################## INCLUDES ################################### 18 19 # Include one or more other config files here. This is useful if you 20 # have a standard template that goes to all Redis server but also need 21 # to customize a few per-server settings. Include files can include 22 # other files, so use this wisely. 23 # 24 # Notice option "include" won't be rewritten by command "CONFIG REWRITE" 25 # from admin or Redis Sentinel. Since Redis always uses the last processed 26 # line as value of a configuration directive, you'd better put includes 27 # at the beginning of this file to avoid overwriting config change at runtime. 28 # 29 # If instead you are interested in using includes to override configuration 30 # options, it is better to use include as the last line. 31 # 32 # include /path/to/local.conf 33 # include /path/to/other.conf 34 # 当配置多个redis时,可能大部分配置一样,而对于不同的redis,只有少部分配置需要定制 35 # 就可以配置一个公共的模板配置。 36 # 对于具体的reids,只需设置少量的配置,并用include把模板配置包含进来即可。 37 # 38 # 值得注意的是,对于同一个配置项,redis只对最后一行的有效 39 # 所以为避免模板配置覆盖当前配置,应在配置文件第一行使用include 40 # 当然,如果模板配置的优先级比较高,就在配置文件最后一行使用include 41 42 ################################ GENERAL ##################################### 43 44 # By default Redis does not run as a daemon. Use 'yes' if you need it. 45 # Note that Redis will write a pid file in /var/run/redis.pid when daemonized. 46 # yes为使用守护进程,此时redis的进程ID会被写进 pidfile的配置中 47 daemonize yes 48 49 # When running daemonized, Redis writes a pid file in /var/run/redis.pid by 50 # default. You can specify a custom pid file location here. 51 # 当redis以守护进程的方式启动时,redis的进程ID将会写在这个文件中 52 pidfile /var/run/redis.pid 53 54 # Accept connections on the specified port, default is 6379. 55 # If port 0 is specified Redis will not listen on a TCP socket. 56 # redis 启动的端口。【应该知道redis是服务端吧】 57 port 6379 58 59 # TCP listen() backlog. 60 # 61 # In high requests-per-second environments you need an high backlog in order 62 # to avoid slow clients connections issues. Note that the Linux kernel 63 # will silently truncate it to the value of /proc/sys/net/core/somaxconn so 64 # make sure to raise both the value of somaxconn and tcp_max_syn_backlog 65 # in order to get the desired effect. 66 # 最大链接缓冲池的大小,这里应该是指的未完成链接请求的数量 67 #(测试值为1时,仍可以有多个链接) 68 # 但该值与listen函数中的backlog意义应该是相同的,源码中该值就是被用在了listen函数中 69 # 该值同时受/proc/sys/net/core/somaxconn 和 tcp_max_syn_backlog(/etc/sysctl.conf中配置)的限制 70 # tcp_max_syn_backlog 指的是未完成链接的数量 71 tcp-backlog 511 72 73 # By default Redis listens for connections from all the network interfaces 74 # available on the server. It is possible to listen to just one or multiple 75 # interfaces using the "bind" configuration directive, followed by one or 76 # more IP addresses. 77 # 绑定ip,指定ip可以连接到redis 78 # 79 # Examples: 80 # 81 # bind 192.168.1.100 10.0.0.1 82 # bind 127.0.0.1 83 84 # Specify the path for the Unix socket that will be used to listen for 85 # incoming connections. There is no default, so Redis will not listen 86 # on a unix socket when not specified. 87 # 88 # 这个应该就是以文件形式创建的socket 89 # unixsocket /tmp/redis.sock 90 # unixsocketperm 755 91 92 # Close the connection after a client is idle for N seconds (0 to disable) 93 # 超时断链机制,如果一个链接在N秒内没有任何操作,则断开该链接 94 # N为0时,该机制失效 95 timeout 0 96 97 # TCP keepalive. 98 # 99 # If non-zero, use SO_KEEPALIVE to send TCP ACKs to clients in absence 100 # of communication. This is useful for two reasons: 101 # 102 # 1) Detect dead peers. 103 # 2) Take the connection alive from the point of view of network 104 # equipment in the middle. 105 # 106 # On Linux, the specified value (in seconds) is the period used to send ACKs. 107 # Note that to close the connection the double of the time is needed. 108 # On other kernels the period depends on the kernel configuration. 109 # 就像心跳检测一样,检查链接是否保持正常,同时也可以保持正常链接的通信 110 # 建议值为60 111 # 112 # A reasonable value for this option is 60 seconds. 113 tcp-keepalive 0 114 115 # Specify the server verbosity level. 116 # This can be one of: 117 # debug (a lot of information, useful for development/testing) 118 # verbose (many rarely useful info, but not a mess like the debug level) 119 # notice (moderately verbose, what you want in production probably) 120 # warning (only very important / critical messages are logged) 121 # 日志级别 122 loglevel notice 123 124 # Specify the log file name. Also the empty string can be used to force 125 # Redis to log on the standard output. Note that if you use standard 126 # output for logging but daemonize, logs will be sent to /dev/null 127 # 日志存放路径,默认是输出到标准输出,但当以守护进程方式启动时,默认输出到/dev/null(传说中的linux黑洞) 128 logfile "" 129 130 # To enable logging to the system logger, just set 'syslog-enabled' to yes, 131 # and optionally update the other syslog parameters to suit your needs. 132 # yes 表示将日志写到系统日志中 133 # syslog-enabled no 134 135 # Specify the syslog identity. 136 # 当syslog-enabled为yes时,指定系统日志的标示为 redis 137 # syslog-ident redis 138 139 # Specify the syslog facility. Must be USER or between LOCAL0-LOCAL7. 140 # 指定系统日志的设备 141 # syslog-facility local0 142 143 # Set the number of databases. The default database is DB 0, you can select 144 # a different one on a per-connection basis using SELECT <dbid> where 145 # dbid is a number between 0 and 'databases'-1 146 # redis的数据库格式,默认16个(0~15),默认使用第0个。 147 databases 16 148 149 ################################ SNAPSHOTTING ################################ 150 # 151 # Save the DB on disk: 152 # 153 # save <seconds> <changes> 154 # 155 # Will save the DB if both the given number of seconds and the given 156 # number of write operations against the DB occurred. 157 # 快照,即将数据写到硬盘上,在<seconds>秒内,至少有<changes>次写入数据库操作 158 # 则会将数据写入硬盘一次。 159 # 将save行注释掉则永远不会写入硬盘 160 # save "" 表示删除所有的快照点 161 # 162 # In the example below the behaviour will be to save: 163 # after 900 sec (15 min) if at least 1 key changed 164 # after 300 sec (5 min) if at least 10 keys changed 165 # after 60 sec if at least 10000 keys changed 166 # 167 # Note: you can disable saving at all commenting all the "save" lines. 168 # 169 # It is also possible to remove all the previously configured save 170 # points by adding a save directive with a single empty string argument 171 # like in the following example: 172 # 173 # save "" 174 175 save 900 1 176 save 300 10 177 save 60 10000 178 179 # By default Redis will stop accepting writes if RDB snapshots are enabled 180 # (at least one save point) and the latest background save failed. 181 # This will make the user aware (in a hard way) that data is not persisting 182 # on disk properly, otherwise chances are that no one will notice and some 183 # disaster will happen. 184 # 185 # If the background saving process will start working again Redis will 186 # automatically allow writes again. 187 # 188 # However if you have setup your proper monitoring of the Redis server 189 # and persistence, you may want to disable this feature so that Redis will 190 # continue to work as usual even if there are problems with disk, 191 # permissions, and so forth. 192 # 当做快照失败的时候,redis会停止继续向其写入数据,保证第一时间发现redis快照出现问题 193 # 当然,通过下面配置为 no,即使redis快照失败,也能继续向redis写入数据 194 stop-writes-on-bgsave-error yes 195 196 # Compress string objects using LZF when dump .rdb databases? 197 # For default that's set to 'yes' as it's almost always a win. 198 # If you want to save some CPU in the saving child set it to 'no' but 199 # the dataset will likely be bigger if you have compressible values or keys. 200 # 快照的时候,是否用LZF压缩,使用压缩会占一定的cpu,但不使用压缩,快照会很大 201 rdbcompression yes 202 203 # Since version 5 of RDB a CRC64 checksum is placed at the end of the file. 204 # This makes the format more resistant to corruption but there is a performance 205 # hit to pay (around 10%) when saving and loading RDB files, so you can disable it 206 # for maximum performances. 207 # 208 # RDB files created with checksum disabled have a checksum of zero that will 209 # tell the loading code to skip the check. 210 # 数据校验,快照末尾会存放一个校验值,保证数据的准确性 211 # 但数据校验会使性能下降约10%,默认开启校验 212 rdbchecksum yes 213 214 # The filename where to dump the DB 215 # 快照的名字 216 dbfilename dump.rdb 217 218 # The working directory. 219 # 220 # The DB will be written inside this directory, with the filename specified 221 # above using the 'dbfilename' configuration directive. 222 # 223 # The Append Only File will also be created inside this directory. 224 # 225 # Note that you must specify a directory here, not a file name. 226 # 227 # 快照存放的目录 228 # linux root下测试,会发现该进程会在当前目录下创建一个dump.rdb 229 # 但快照却放在了根目录/下,重启的时候,是不会从快照中恢复数据的 230 # 当把根目录下的dump.rdb文件拷贝到当前目录的时候,再次启动,就会从快照中恢复数据 231 # 而且以后的快照也都在当前目录的dump.rdb中做操作 232 # 233 # 值得一提的是,快照是异步方式的,如果在还未达到快照的时候,修改了数据,而且redis发生问题crash了 234 # 那么中间的修改数据是不会被保存到dump.rdb快照中的 235 # 解决办法就是用Append Only Mode的同步模式(下面将会有该配置项) 236 # 将会把每个操作写到Append Only File中,该文件也存放于当前配置的目录 237 # 建议使用绝对路径!!! 238 # 239 dir ./ 240 241 ################################# REPLICATION ################################# 242 243 # Master-Slave replication. Use slaveof to make a Redis instance a copy of 244 # another Redis server. Note that the configuration is local to the slave 245 # so for example it is possible to configure the slave to save the DB with a 246 # different interval, or to listen to another port, and so on. 247 # 248 # 主从复制,类似于双机备份。 249 # 配置需指定主机的ip 和port 250 # slaveof <masterip> <masterport> 251 252 # If the master is password protected (using the "requirepass" configuration 253 # directive below) it is possible to tell the slave to authenticate before 254 # starting the replication synchronization process, otherwise the master will 255 # refuse the slave request. 256 # 257 # 如果主机redis需要密码,则指定密码 258 # 密码配置在下面安全配置中 259 # masterauth <master-password> 260 261 # When a slave loses its connection with the master, or when the replication 262 # is still in progress, the slave can act in two different ways: 263 # 264 # 1) if slave-serve-stale-data is set to 'yes' (the default) the slave will 265 # still reply to client requests, possibly with out of date data, or the 266 # data set may just be empty if this is the first synchronization. 267 # 268 # 2) if slave-serve-stale-data is set to 'no' the slave will reply with 269 # an error "SYNC with master in progress" to all the kind of commands 270 # but to INFO and SLAVEOF. 271 # 272 # 当从机与主机断开时,即同步出现问题的时候,从机有两种处理方式 273 # yes, 继续响应客户端请求,但可能有脏数据(过期数据、空数据等) 274 # no,对客户端的请求统一回复为“SYNC with master in progress”,除了INFO和SLAVEOF命令 275 slave-serve-stale-data yes 276 277 # You can configure a slave instance to accept writes or not. Writing against 278 # a slave instance may be useful to store some ephemeral data (because data 279 # written on a slave will be easily deleted after resync with the master) but 280 # may also cause problems if clients are writing to it because of a 281 # misconfiguration. 282 # 283 # Since Redis 2.6 by default slaves are read-only. 284 # 285 # Note: read only slaves are not designed to be exposed to untrusted clients 286 # on the internet. It's just a protection layer against misuse of the instance. 287 # Still a read only slave exports by default all the administrative commands 288 # such as CONFIG, DEBUG, and so forth. To a limited extent you can improve 289 # security of read only slaves using 'rename-command' to shadow all the 290 # administrative / dangerous commands. 291 # slave只读选项,设置从机只读(默认)。 292 # 即使设置可写,当下一次从主机上同步数据,仍然会删除当前从机上写入的数据 293 # 【待测试】:主机与从机互为slave会出现什么情况? 294 # 【预期三种结果】:1. 提示报错 2. 主从服务器数据不可控 3. 一切正常 295 slave-read-only yes 296 297 # Slaves send PINGs to server in a predefined interval. It's possible to change 298 # this interval with the repl_ping_slave_period option. The default value is 10 299 # seconds. 300 # 301 # 从服务器向主服务器发送心跳包,默认10发送一次 302 # repl-ping-slave-period 10 303 304 # The following option sets the replication timeout for: 305 # 306 # 1) Bulk transfer I/O during SYNC, from the point of view of slave. 307 # 2) Master timeout from the point of view of slaves (data, pings). 308 # 3) Slave timeout from the point of view of masters (REPLCONF ACK pings). 309 # 310 # It is important to make sure that this value is greater than the value 311 # specified for repl-ping-slave-period otherwise a timeout will be detected 312 # every time there is low traffic between the master and the slave. 313 # 314 # 超时响应时间,值必须比repl-ping-slave-period大 315 # 批量数据传输超时、ping超时 316 # repl-timeout 60 317 318 # Disable TCP_NODELAY on the slave socket after SYNC? 319 # 320 # If you select "yes" Redis will use a smaller number of TCP packets and 321 # less bandwidth to send data to slaves. But this can add a delay for 322 # the data to appear on the slave side, up to 40 milliseconds with 323 # Linux kernels using a default configuration. 324 # 325 # If you select "no" the delay for data to appear on the slave side will 326 # be reduced but more bandwidth will be used for replication. 327 # 328 # By default we optimize for low latency, but in very high traffic conditions 329 # or when the master and slaves are many hops away, turning this to "yes" may 330 # be a good idea. 331 # 主从同步是否延迟 332 # yes 有延迟,约40毫秒(linux kernel的默认配置),使用较少的数据包,较小的带宽 333 # no 无延迟(减少延迟),但需要更大的带宽 334 repl-disable-tcp-nodelay no 335 336 # Set the replication backlog size. The backlog is a buffer that accumulates 337 # slave data when slaves are disconnected for some time, so that when a slave 338 # wants to reconnect again, often a full resync is not needed, but a partial 339 # resync is enough, just passing the portion of data the slave missed while 340 # disconnected. 341 # 342 # The biggest the replication backlog, the longer the time the slave can be 343 # disconnected and later be able to perform a partial resynchronization. 344 # 345 # The backlog is only allocated once there is at least a slave connected. 346 # 347 # 默认情况下,当slave重连的时候,会进行全量数据同步 348 # 但实际上slave只需要部分同步即可,这个选项设置部分同步的大小 349 # 设置值越大,同步的时间就越长 350 # repl-backlog-size 1mb 351 352 # After a master has no longer connected slaves for some time, the backlog 353 # will be freed. The following option configures the amount of seconds that 354 # need to elapse, starting from the time the last slave disconnected, for 355 # the backlog buffer to be freed. 356 # 357 # A value of 0 means to never release the backlog. 358 # 359 # 主机的后台日志释放时间,即当没有slave连接时,过多久释放后台日志 360 # 0表示不释放 361 # repl-backlog-ttl 3600 362 363 # The slave priority is an integer number published by Redis in the INFO output. 364 # It is used by Redis Sentinel in order to select a slave to promote into a 365 # master if the master is no longer working correctly. 366 # 367 # A slave with a low priority number is considered better for promotion, so 368 # for instance if there are three slaves with priority 10, 100, 25 Sentinel will 369 # pick the one with priority 10, that is the lowest. 370 # 371 # However a special priority of 0 marks the slave as not able to perform the 372 # role of master, so a slave with priority of 0 will never be selected by 373 # Redis Sentinel for promotion. 374 # 375 # By default the priority is 100. 376 # 当主机crash的时候,在从机中选择一台作为主机,数字越小,优先级越高 377 # 0 表示永远不作为主机,默认值是100 378 slave-priority 100 379 380 # It is possible for a master to stop accepting writes if there are less than 381 # N slaves connected, having a lag less or equal than M seconds. 382 # 383 # The N slaves need to be in "online" state. 384 # 385 # The lag in seconds, that must be <= the specified value, is calculated from 386 # the last ping received from the slave, that is usually sent every second. 387 # 388 # This option does not GUARANTEES that N replicas will accept the write, but 389 # will limit the window of exposure for lost writes in case not enough slaves 390 # are available, to the specified number of seconds. 391 # 392 # For example to require at least 3 slaves with a lag <= 10 seconds use: 393 # 394 # 当slave数量小于min-slaves-to-write,且延迟小于等于min-slaves-max-lag时, 395 # 主机停止写入操作 396 # 0表示禁用 397 # 默认min-slaves-to-write为0,即禁用。min-slaves-max-lag为10 398 # min-slaves-to-write 3 399 # min-slaves-max-lag 10 400 # 401 # Setting one or the other to 0 disables the feature. 402 # 403 # By default min-slaves-to-write is set to 0 (feature disabled) and 404 # min-slaves-max-lag is set to 10. 405 ################################## SECURITY ################################### 406 # Require clients to issue AUTH <PASSWORD> before processing any other 407 # commands. This might be useful in environments in which you do not trust 408 # others with access to the host running redis-server. 409 # 410 # This should stay commented out for backward compatibility and because most 411 # people do not need auth (e.g. they run their own servers). 412 # 413 # Warning: since Redis is pretty fast an outside user can try up to 414 # 150k passwords per second against a good box. This means that you should 415 # use a very strong password otherwise it will be very easy to break. 416 # 417 # redis密码,默认不配置,即无密码 418 # 这里注意,如果设置了密码,应该设置一个复杂度比较高的密码 419 # 因为redis的速度很快,每秒可以尝试150k次的密码测试,很容易对其进行暴力破解(跑码)。 420 # 疑问:这里为什么不设置一个针对主机的测试次数限制的,例如每10次,则禁止建立连接1个小时! 421 # requirepass foobared 422 423 # Command renaming. 424 # 425 # It is possible to change the name of dangerous commands in a shared 426 # environment. For instance the CONFIG command may be renamed into something 427 # hard to guess so that it will still be available for internal-use tools 428 # but not available for general clients. 429 # 430 # 命令重命名,将命令重命名为另一个字符串标识 431 # 如果命令为空串(""),则会彻底禁用该命令 432 # 命令重命名,会对写AOF(Append of file)文件、slave从机造成一些问题 433 # Example: 434 # 435 # rename-command CONFIG b840fc02d524045429941cc15f59e41cb7be6c52 436 # 437 # It is also possible to completely kill a command by renaming it into 438 # an empty string: 439 # 440 # rename-command CONFIG "" 441 # 442 # Please note that changing the name of commands that are logged into the 443 # AOF file or transmitted to slaves may cause problems. 444 445 ################################### LIMITS #################################### 446 447 # Set the max number of connected clients at the same time. By default 448 # this limit is set to 10000 clients, however if the Redis server is not 449 # able to configure the process file limit to allow for the specified limit 450 # the max number of allowed clients is set to the current file limit 451 # minus 32 (as Redis reserves a few file descriptors for internal uses). 452 # 453 # Once the limit is reached Redis will close all the new connections sending 454 # an error 'max number of clients reached'. 455 # 456 # 这只redis的最大连接数目,默认设置为10000个客户端 457 # 当超过限制时,将段开新的连接,并响应“max number of clients reached” 458 # maxclients 10000 459 460 # Don't use more memory than the specified amount of bytes. 461 # When the memory limit is reached Redis will try to remove keys 462 # according to the eviction policy selected (see maxmemory-policy). 463 # 464 # If Redis can't remove keys according to the policy, or if the policy is 465 # set to 'noeviction', Redis will start to reply with errors to commands 466 # that would use more memory, like SET, LPUSH, and so on, and will continue 467 # to reply to read-only commands like GET. 468 # 469 # This option is usually useful when using Redis as an LRU cache, or to set 470 # a hard memory limit for an instance (using the 'noeviction' policy). 471 # 472 # WARNING: If you have slaves attached to an instance with maxmemory on, 473 # the size of the output buffers needed to feed the slaves are subtracted 474 # from the used memory count, so that network problems / resyncs will 475 # not trigger a loop where keys are evicted, and in turn the output 476 # buffer of slaves is full with DELs of keys evicted triggering the deletion 477 # of more keys, and so forth until the database is completely emptied. 478 # 479 # In short... if you have slaves attached it is suggested that you set a lower 480 # limit for maxmemory so that there is some free RAM on the system for slave 481 # output buffers (but this is not needed if the policy is 'noeviction'). 482 # 483 # redis的最大内存限制,如果达到最大内存,会按照下面的maxmemory-policy进行清除 484 # 如果不能再清除或者maxmemory-policy为noeviction,则对于需要增加空间的操作,将会返回错误 485 maxmemory <1024*1024*1024> 486 487 # MAXMEMORY POLICY: how Redis will select what to remove when maxmemory 488 # is reached. You can select among five behaviors: 489 # 490 # volatile-lru -> remove the key with an expire set using an LRU algorithm 491 # allkeys-lru -> remove any key accordingly to the LRU algorithm 492 # volatile-random -> remove a random key with an expire set 493 # allkeys-random -> remove a random key, any key 494 # volatile-ttl -> remove the key with the nearest expire time (minor TTL) 495 # noeviction -> don't expire at all, just return an error on write operations 496 # 497 # Note: with any of the above policies, Redis will return an error on write 498 # operations, when there are not suitable keys for eviction. 499 # 500 # At the date of writing this commands are: set setnx setex append 501 # incr decr rpush lpush rpushx lpushx linsert lset rpoplpush sadd 502 # sinter sinterstore sunion sunionstore sdiff sdiffstore zadd zincrby 503 # zunionstore zinterstore hset hsetnx hmset hincrby incrby decrby 504 # getset mset msetnx exec sort 505 # 506 # The default is: 507 # 508 # 内存删除策略,默认volatile-lru,利用LRU算法,删除过期的key 509 maxmemory-policy volatile-lru 510 511 # LRU and minimal TTL algorithms are not precise algorithms but approximated 512 # algorithms (in order to save memory), so you can select as well the sample 513 # size to check. For instance for default Redis will check three keys and 514 # pick the one that was used less recently, you can change the sample size 515 # using the following configuration directive. 516 # 517 # LRU算法与最小TTL算法只是相对精确的算法,并不是绝对精确的算法 518 # 为了更精确,可以设置样本个数 519 # 比如设置3个样本,redis会选取三个key,并选择删除那个上次使用时间最远的 520 # maxmemory-samples 3 521 522 ############################## APPEND ONLY MODE ############################### 523 524 # By default Redis asynchronously dumps the dataset on disk. This mode is 525 # good enough in many applications, but an issue with the Redis process or 526 # a power outage may result into a few minutes of writes lost (depending on 527 # the configured save points). 528 # 529 # The Append Only File is an alternative persistence mode that provides 530 # much better durability. For instance using the default data fsync policy 531 # (see later in the config file) Redis can lose just one second of writes in a 532 # dramatic event like a server power outage, or a single write if something 533 # wrong with the Redis process itself happens, but the operating system is 534 # still running correctly. 535 # 536 # AOF and RDB persistence can be enabled at the same time without problems. 537 # If the AOF is enabled on startup Redis will load the AOF, that is the file 538 # with the better durability guarantees. 539 # 540 # Please check http://redis.io/topics/persistence for more information. 541 # 将对redis所有的操作都保存到AOF文件中 542 # 因为dump.rdb是异步的,在下次快照到达之前,如果出现crash等问题,会造成数据丢失 543 # 而AOF文件时同步记录的,所以会完整的恢复数据 544 545 appendonly no 546 547 # The name of the append only file (default: "appendonly.aof") 548 # AOF文件的名字 549 550 appendfilename "appendonly.aof" 551 552 # The fsync() call tells the Operating System to actually write data on disk 553 # instead to wait for more data in the output buffer. Some OS will really flush 554 # data on disk, some other OS will just try to do it ASAP. 555 # 556 # Redis supports three different modes: 557 # 558 # no: don't fsync, just let the OS flush the data when it wants. Faster. 559 # always: fsync after every write to the append only log . Slow, Safest. 560 # everysec: fsync only one time every second. Compromise. 561 # 562 # The default is "everysec", as that's usually the right compromise between 563 # speed and data safety. It's up to you to understand if you can relax this to 564 # "no" that will let the operating system flush the output buffer when 565 # it wants, for better performances (but if you can live with the idea of 566 # some data loss consider the default persistence mode that's snapshotting), 567 # or on the contrary, use "always" that's very slow but a bit safer than 568 # everysec. 569 # 570 # More details please check the following article: 571 # http://antirez.com/post/redis-persistence-demystified.html 572 # 573 # If unsure, use "everysec". 574 # redis的数据同步方式,三种 575 # no,redis本身不做同步,由OS来做。redis的速度会很快 576 # always,在每次写操作之后,redis都进行同步,即写入AOF文件。redis会变慢,但是数据更安全 577 # everysec,折衷考虑,每秒同步一次数据。【默认】 578 579 # appendfsync always 580 appendfsync everysec 581 # appendfsync no 582 583 # When the AOF fsync policy is set to always or everysec, and a background 584 # saving process (a background save or AOF log background rewriting) is 585 # performing a lot of I/O against the disk, in some Linux configurations 586 # Redis may block too long on the fsync() call. Note that there is no fix for 587 # this currently, as even performing fsync in a different thread will block 588 # our synchronous write(2) call. 589 # 590 # In order to mitigate this problem it's possible to use the following option 591 # that will prevent fsync() from being called in the main process while a 592 # BGSAVE or BGREWRITEAOF is in progress. 593 # 594 # This means that while another child is saving, the durability of Redis is 595 # the same as "appendfsync none". In practical terms, this means that it is 596 # possible to lose up to 30 seconds of log in the worst scenario (with the 597 # default Linux settings). 598 # 599 # If you have latency problems turn this to "yes". Otherwise leave it as 600 # "no" that is the safest pick from the point of view of durability. 601 # redis的同步方式中,always和everysec,快照和写AOF可能会执行大量的硬盘I/O操作, 602 # 而在一些Linux的配置中,redis会阻塞很久,而redis本身并没有很好的解决这一问题。 603 # 为了缓和这一问题,redis提供no-appendfsync-on-rewrite选项, 604 # 即当有另外一个进程在执行保存操作的时候,redis采用no的同步方式。 605 # 最坏情况下会有延迟30秒的同步延迟。 606 # 如果你觉得这样做会有潜在危险,则请将该选项改为yes。否则就保持默认值no(基于稳定性考虑)。 607 608 no-appendfsync-on-rewrite no 609 610 # Automatic rewrite of the append only file. 611 # Redis is able to automatically rewrite the log file implicitly calling 612 # BGREWRITEAOF when the AOF log size grows by the specified percentage. 613 # 614 # This is how it works: Redis remembers the size of the AOF file after the 615 # latest rewrite (if no rewrite has happened since the restart, the size of 616 # the AOF at startup is used). 617 # 618 # This base size is compared to the current size. If the current size is 619 # bigger than the specified percentage, the rewrite is triggered. Also 620 # you need to specify a minimal size for the AOF file to be rewritten, this 621 # is useful to avoid rewriting the AOF file even if the percentage increase 622 # is reached but it is still pretty small. 623 # 624 # Specify a percentage of zero in order to disable the automatic AOF 625 # rewrite feature. 626 # 自动重写AOF文件 627 # 当AOF日志文件大小增长到指定百分比时,redis会自动隐式调用BGREWRITEAOF来重写AOF文件 628 # redis会记录上次重写AOF文件之后的大小, 629 # 如果当前文件大小增加了auto-aof-rewrite-percentage,则会触发重写AOF日志功能 630 # 当然如果文件过小,比如小于auto-aof-rewrite-min-size这个大小,是不会触发重写AOF日志功能的 631 # auto-aof-rewrite-percentage为0时,禁用重写功能 632 633 auto-aof-rewrite-percentage 100 634 auto-aof-rewrite-min-size 64mb 635 636 ################################ LUA SCRIPTING ############################### 637 638 # Max execution time of a Lua script in milliseconds. 639 # 640 # If the maximum execution time is reached Redis will log that a script is 641 # still in execution after the maximum allowed time and will start to 642 # reply to queries with an error. 643 # 644 # When a long running script exceed the maximum execution time only the 645 # SCRIPT KILL and SHUTDOWN NOSAVE commands are available. The first can be 646 # used to stop a script that did not yet called write commands. The second 647 # is the only way to shut down the server in the case a write commands was 648 # already issue by the script but the user don't want to wait for the natural 649 # termination of the script. 650 # 651 # Set it to 0 or a negative value for unlimited execution without warnings. 652 # LUA脚本的最大执行时间(单位是毫秒),默认5000毫秒,即5秒 653 # 如果LUA脚本执行超过这个限制,可以调用SCRIPT KILL和SHUTDOWN NOSAVE命令。 654 # SCRIPT KILL可以终止脚本执行 655 # SHUTDOWN NOSAVE关闭服务,防止LUA脚本的写操作发生 656 # 该值为0或者负数,表示没有限制时间 657 lua-time-limit 5000 658 659 ################################## SLOW LOG ################################### 660 661 # The Redis Slow Log is a system to log queries that exceeded a specified 662 # execution time. The execution time does not include the I/O operations 663 # like talking with the client, sending the reply and so forth, 664 # but just the time needed to actually execute the command (this is the only 665 # stage of command execution where the thread is blocked and can not serve 666 # other requests in the meantime). 667 # 668 # You can configure the slow log with two parameters: one tells Redis 669 # what is the execution time, in microseconds, to exceed in order for the 670 # command to get logged, and the other parameter is the length of the 671 # slow log. When a new command is logged the oldest one is removed from the 672 # queue of logged commands. 673 # 记录执行比较慢的命令 674 # 执行比较慢仅仅是指命令的执行时间,不包括客户端的链接与响应等时间 675 # slowlog-log-slower-than 设定这个慢的时间,单位是微妙,即1000000表示1秒,0表示所有命令都记录,负数表示不记录 676 # slowlog-max-len表示记录的慢命令的个数,超过限制,则最早记录的命令会被移除 677 # 命令的长度没有限制,但是会消耗内存,用SLOWLOG RESET来收回这些消耗的内存 678 679 # The following time is expressed in microseconds, so 1000000 is equivalent 680 # to one second. Note that a negative number disables the slow log, while 681 # a value of zero forces the logging of every command. 682 slowlog-log-slower-than 10000 683 684 # There is no limit to this length. Just be aware that it will consume memory. 685 # You can reclaim memory used by the slow log with SLOWLOG RESET. 686 slowlog-max-len 128 687 688 ################################ LATENCY MONITOR ############################## 689 690 # The Redis latency monitoring subsystem samples different operations 691 # at runtime in order to collect data related to possible sources of 692 # latency of a Redis instance. 693 # 694 # Via the LATENCY command this information is available to the user that can 695 # print graphs and obtain reports. 696 # 697 # The system only logs operations that were performed in a time equal or 698 # greater than the amount of milliseconds specified via the 699 # latency-monitor-threshold configuration directive. When its value is set 700 # to zero, the latency monitor is turned off. 701 # 702 # By default latency monitoring is disabled since it is mostly not needed 703 # if you don't have latency issues, and collecting data has a performance 704 # impact, that while very small, can be measured under big load. Latency 705 # monitoring can easily be enalbed at runtime using the command 706 # "CONFIG SET latency-monitor-threshold <milliseconds>" if needed. 707 # 延迟监控器 708 # redis延迟监控子系统在运行时,会抽样检测可能导致延迟的不同操作 709 # 通过LATENCY命令可以打印相关信息和报告, 命令如下(摘自源文件注释): 710 # LATENCY SAMPLES: return time-latency samples for the specified event. 711 # LATENCY LATEST: return the latest latency for all the events classes. 712 # LATENCY DOCTOR: returns an human readable analysis of instance latency. 713 # LATENCY GRAPH: provide an ASCII graph of the latency of the specified event. 714 # 715 # 系统只记录超过设定值的操作,单位是毫秒,0表示禁用该功能 716 # 可以通过命令“CONFIG SET latency-monitor-threshold <milliseconds>” 直接设置而不需要重启redis 717 718 latency-monitor-threshold 0 719 720 ############################# Event notification ############################## 721 722 # Redis can notify Pub/Sub clients about events happening in the key space. 723 # This feature is documented at http://redis.io/topics/keyspace-events 724 # 725 # For instance if keyspace events notification is enabled, and a client 726 # performs a DEL operation on key "foo" stored in the Database 0, two 727 # messages will be published via Pub/Sub: 728 # 729 # PUBLISH __keyspace@0__:foo del 730 # PUBLISH __keyevent@0__:del foo 731 # 732 # It is possible to select the events that Redis will notify among a set 733 # of classes. Every class is identified by a single character: 734 # 735 # K Keyspace events, published with __keyspace@<db>__ prefix. 736 # E Keyevent events, published with __keyevent@<db>__ prefix. 737 # g Generic commands (non-type specific) like DEL, EXPIRE, RENAME, ... 738 # $ String commands 739 # l List commands 740 # s Set commands 741 # h Hash commands 742 # z Sorted set commands 743 # x Expired events (events generated every time a key expires) 744 # e Evicted events (events generated when a key is evicted for maxmemory) 745 # A Alias for g$lshzxe, so that the "AKE" string means all the events. 746 # 747 # The "notify-keyspace-events" takes as argument a string that is composed 748 # by zero or multiple characters. The empty string means that notifications 749 # are disabled at all. 750 # 751 # Example: to enable list and generic events, from the point of view of the 752 # event name, use: 753 # 754 # notify-keyspace-events Elg 755 # 756 # Example 2: to get the stream of the expired keys subscribing to channel 757 # name __keyevent@0__:expired use: 758 # 759 # notify-keyspace-events Ex 760 # 761 # By default all notifications are disabled because most users don't need 762 # this feature and the feature has some overhead. Note that if you don't 763 # specify at least one of K or E, no events will be delivered. 764 # 事件通知,当事件发生时,redis可以通知Pub/Sub客户端 765 # 空串表示禁用事件通知 766 # 注意:K和E至少要指定一个,否则不会有事件通知 767 notify-keyspace-events "" 768 769 ############################### ADVANCED CONFIG ############################### 770 771 # Hashes are encoded using a memory efficient data structure when they have a 772 # small number of entries, and the biggest entry does not exceed a given 773 # threshold. These thresholds can be configured using the following directives. 774 # 当hash数目比较少,并且最大元素没有超过给定值时,Hash使用比较有效的内存数据结构来存储。 775 # 即ziplist的结构(压缩的双向链表),参考:http://blog.csdn.net/benbendy1984/article/details/7796956 776 hash-max-ziplist-entries 512 777 hash-max-ziplist-value 64 778 779 # Similarly to hashes, small lists are also encoded in a special way in order 780 # to save a lot of space. The special representation is only used when 781 # you are under the following limits: 782 # List配置同Hash 783 list-max-ziplist-entries 512 784 list-max-ziplist-value 64 785 786 # Sets have a special encoding in just one case: when a set is composed 787 # of just strings that happens to be integers in radix 10 in the range 788 # of 64 bit signed integers. 789 # The following configuration setting sets the limit in the size of the 790 # set in order to use this special memory saving encoding. 791 # Sets的元素如果全部是整数(10进制),且为64位有符号整数,则采用特殊的编码方式。 792 # 其元素个数限制配置如下: 793 set-max-intset-entries 512 794 795 # Similarly to hashes and lists, sorted sets are also specially encoded in 796 # order to save a lot of space. This encoding is only used when the length and 797 # elements of a sorted set are below the following limits: 798 # sorted set 同Hash和List 799 zset-max-ziplist-entries 128 800 zset-max-ziplist-value 64 801 802 # HyperLogLog sparse representation bytes limit. The limit includes the 803 # 16 bytes header. When an HyperLogLog using the sparse representation crosses 804 # this limit, it is converted into the dense representation. 805 # 806 # A value greater than 16000 is totally useless, since at that point the 807 # dense representation is more memory efficient. 808 # 809 # The suggested value is ~ 3000 in order to have the benefits of 810 # the space efficient encoding without slowing down too much PFADD, 811 # which is O(N) with the sparse encoding. The value can be raised to 812 # ~ 10000 when CPU is not a concern, but space is, and the data set is 813 # composed of many HyperLogLogs with cardinality in the 0 - 15000 range. 814 # 关于HyperLogLog的介绍:http://www.redis.io/topics/data-types-intro#hyperloglogs 815 # HyperLogLog稀疏表示限制设置,如果其值大于16000,则仍然采用稠密表示,因为这时稠密表示更能有效使用内存 816 # 建议值为3000 817 hll-sparse-max-bytes 3000 818 819 # Active rehashing uses 1 millisecond every 100 milliseconds of CPU time in 820 # order to help rehashing the main Redis hash table (the one mapping top-level 821 # keys to values). The hash table implementation Redis uses (see dict.c) 822 # performs a lazy rehashing: the more operation you run into a hash table 823 # that is rehashing, the more rehashing "steps" are performed, so if the 824 # server is idle the rehashing is never complete and some more memory is used 825 # by the hash table. 826 # 827 # The default is to use this millisecond 10 times every second in order to 828 # active rehashing the main dictionaries, freeing memory when possible. 829 # 830 # If unsure: 831 # use "activerehashing no" if you have hard latency requirements and it is 832 # not a good thing in your environment that Redis can reply form time to time 833 # to queries with 2 milliseconds delay. 834 # 835 # use "activerehashing yes" if you don't have such hard requirements but 836 # want to free memory asap when possible. 837 # 每100毫秒,redis将用1毫秒的时间对Hash表进行重新Hash。 838 # 采用懒惰Hash方式:操作Hash越多,则重新Hash的可能越多,若根本就不操作Hash,则不会重新Hash 839 # 默认每秒10次重新hash主字典,释放可能释放的内存 840 # 重新hash会造成延迟,如果对延迟要求较高,则设为no,禁止重新hash。但可能会浪费很多内存 841 activerehashing yes 842 843 # The client output buffer limits can be used to force disconnection of clients 844 # that are not reading data from the server fast enough for some reason (a 845 # common reason is that a Pub/Sub client can't consume messages as fast as the 846 # publisher can produce them). 847 # 848 # The limit can be set differently for the three different classes of clients: 849 # 850 # normal -> normal clients including MONITOR clients 851 # slave -> slave clients 852 # pubsub -> clients subscribed to at least one pubsub channel or pattern 853 # 854 # The syntax of every client-output-buffer-limit directive is the following: 855 # 856 # 客户端输出缓冲区限制,当客户端从服务端的读取速度不够快时,则强制断开 857 # 三种不同的客户端类型:normal、salve、pubsub,语法如下: 858 # client-output-buffer-limit <class> <hard limit> <soft limit> <soft seconds> 859 # 860 # A client is immediately disconnected once the hard limit is reached, or if 861 # the soft limit is reached and remains reached for the specified number of 862 # seconds (continuously). 863 # So for instance if the hard limit is 32 megabytes and the soft limit is 864 # 16 megabytes / 10 seconds, the client will get disconnected immediately 865 # if the size of the output buffers reach 32 megabytes, but will also get 866 # disconnected if the client reaches 16 megabytes and continuously overcomes 867 # the limit for 10 seconds. 868 # 869 # By default normal clients are not limited because they don't receive data 870 # without asking (in a push way), but just after a request, so only 871 # asynchronous clients may create a scenario where data is requested faster 872 # than it can read. 873 # 874 # Instead there is a default limit for pubsub and slave clients, since 875 # subscribers and slaves receive data in a push fashion. 876 # 877 # Both the hard or the soft limit can be disabled by setting them to zero. 878 # 当达到硬限制,或者达到软限制且持续了算限制秒数,则立即与客户端断开 879 # 限制设为0表示禁止该功能 880 # 普通用户默认不限制 881 client-output-buffer-limit normal 0 0 0 882 client-output-buffer-limit slave 256mb 64mb 60 883 client-output-buffer-limit pubsub 32mb 8mb 60 884 885 # Redis calls an internal function to perform many background tasks, like 886 # closing connections of clients in timeout, purging expired keys that are 887 # never requested, and so forth. 888 # 889 # Not all tasks are performed with the same frequency, but Redis checks for 890 # tasks to perform accordingly to the specified "hz" value. 891 # 892 # By default "hz" is set to 10. Raising the value will use more CPU when 893 # Redis is idle, but at the same time will make Redis more responsive when 894 # there are many keys expiring at the same time, and timeouts may be 895 # handled with more precision. 896 # 897 # The range is between 1 and 500, however a value over 100 is usually not 898 # a good idea. Most users should use the default of 10 and raise this up to 899 # 100 only in environments where very low latency is required. 900 # redis调用内部函数执行的后台任务的频率 901 # 后台任务比如:清除过期数据、客户端超时链接等 902 # 默认为10,取值范围1~500, 903 # 对延迟要求很低的可以设置超过100以上 904 hz 10 905 906 # When a child rewrites the AOF file, if the following option is enabled 907 # the file will be fsync-ed every 32 MB of data generated. This is useful 908 # in order to commit the file to the disk more incrementally and avoid 909 # big latency spikes. 910 # 当修改AOF文件时,该设置为yes,则每生成32MB的数据,就进行同步 911 aof-rewrite-incremental-fsync yes
3.设置Redis服务
配置systemctl管理Redis服务:
# 编辑文件 vim /usr/lib/systemd/system/redis.service # 在redis.service文件中加入以下内容 并保存 ########################## [Unit] Description=Redis-5.0.7-6379 After=network.target [Service] Type=forking PIDfile=/var/run/redis-6379.pid ExecStart=/usr/local/bin/redis-server /etc/redis/redis.conf ExecReload=/bin/kill -s HUP $MAINPID ExecStop=/bin/kill -s QUIT $MAINPID PrivateTmp=true [Install] WantedBy=multi-user.target ########################### # 加载服务 systemctl daemon-reload
reids服务操作:
systemctl start redis # 启动
systemctl stop redis # 停止
systemctl restart redis # 重启
systemctl status redis # 查看状态
systemctl enable redis # 开机启动
systemctl disable redis # 取消开机启动
4.运行Redis
[root@centos-base system]# systemctl start redis [root@centos-base system]# systemctl status redis 鈼[0m redis.service - Redis-5.0.7-6379 Loaded: loaded (/usr/lib/systemd/system/redis.service; enabled; vendor preset: disabled) Active: active (running) since Sun 2020-01-05 15:19:46 CST; 4s ago Process: 27232 ExecStop=/bin/kill -s QUIT $MAINPID (code=exited, status=0/SUCCESS) Process: 27243 ExecStart=/usr/local/bin/redis-server /etc/redis/redis.conf (code=exited, status=0/SUCCESS) Main PID: 27244 (redis-server) CGroup: /system.slice/redis.service 鈹斺攢27244 /usr/local/bin/redis-server 127.0.0.1:6379 Jan 05 15:19:46 centos-base systemd[1]: Starting Redis-5.0.7-6379... Jan 05 15:19:46 centos-base systemd[1]: Started Redis-5.0.7-6379.
查看进程:
[root@centos-base system]# ps -ef | grep redis root 27244 1 0 15:19 ? 00:00:00 /usr/local/bin/redis-server 127.0.0.1:6379 root 27251 17132 0 15:22 pts/0 00:00:00 grep --color=auto redis
六、Redis连接
当Redis安装好,并启动后台服务后,我们就可以使用客户端来使用redis数据库。
1.连接redis
如果连接本地redis:
[root@centos-base system]# redis-cli 127.0.0.1:6379> ping PONG
直接使用redis-cli命令即可连接。
连接远程redis:
[root@centos-base redis-5.0.7]# redis-cli -h 192.168.1.181 -p 6379 192.168.1.181:6379> ping PONG 192.168.1.181:6379>
这里注意:
要想本地访问127.0.0.1:6379的话,则bind 127.0.0.1
如果想要同时提供给其他host远程访问192.168.1.181:6379的话,则配置bind 127.0.0.1 192.168.1.181
2.切换数据库
我们使用redis-cli连接redis的时候,默认连接的是第一个数据库,也就是index=0的数据库。
切换数据库命令:
[root@centos-base redis]# redis-cli 127.0.0.1:6379> select 1 OK 127.0.0.1:6379[1]>
select 1表示切换到1号数据库(第二个)。
七、Redis数据类型和操作
1.redis的数据类型
如下图所示:
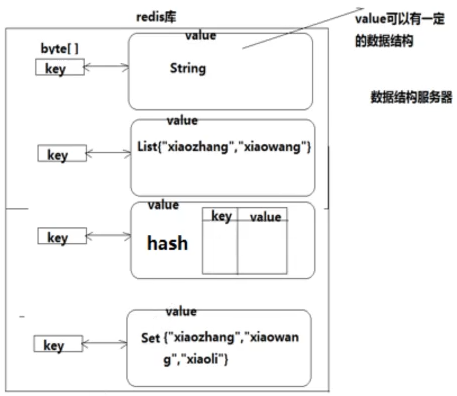
常用的数据类型有String、List、Hash、Set、sorted Set。
String:值为字符串类型。
List:值为一个列表。
Hash:值为多个KV对。
Set:值为一个集合,元素不重复。
Sorted Set:值为按某种规则排序的集合。
操作命令参考:http://redis.cn/commands.html官方中文文档。
命令查询与参考:http://doc.redisfans.com/
2.String数据操作
String类型的数据最Redis中最为基础和常见的数据存储类型。
在Redis中是二进制安全的,这意味着该类型可以存储任何格式的数据,如JEPG图片数据或JSON对象描述信息等。
在Redis中字符串类型的Value最大可容纳512M的内容。
查看数据库中(0~15某一个数据库)所有的数据:
[KEYS *]
127.0.0.1:6379> KEYS * 1) "age" 2) "name"
设置值:
[set key value]
set myname leo # 当myname不存在时,则设置值为leo
修改值:
set myname jone # myname存在,则修改其值为jone
设置值得过期时间:
[setex key Ns value]
setex myage 10 32 # 设置myage的值为32,过期时间为10s
127.0.0.1:6379> get myage # 10s内获取值为32 "32" 127.0.0.1:6379> get myage # 10s过后,获取值得空nil (nil)
获取值:
[get key]
127.0.0.1:6379> get myname "leokale"
一次设置多个值:
[mset key1 value1 key2 value2 key3 value3...]
# mset key1 value1 key2 value2 key3 value3 ... mset myname leo myage 32 gender male
一次获取多个值:
[mget key1 key2 key3...]
127.0.0.1:6379> mget myname myage gender 1) "leokale" 2) "32" 3) "male"
追加数据:
[APPEND key value]
127.0.0.1:6379> get myname "leo" 127.0.0.1:6379> APPEND myname kale (integer) 7 127.0.0.1:6379> get myname "leokale"
3.键命令(通用命令)
键命令主要用于通过键来操作数据,例如删除、是否存在、查看类型等。适用于所有数据类型。
删除数据:
[def key1 key2...]
127.0.0.1:6379> del gender # 删除gender (integer) 1 127.0.0.1:6379> get gender (nil)
判断数据是否存在:
[exists key1 key2...]
127.0.0.1:6379> EXISTS myname myage # 两个值都存在,返回2 (integer) 2 127.0.0.1:6379> EXISTS myname gender # gender已被删除,返回1 (integer) 1 127.0.0.1:6379> EXISTS myname # myname存在,返回1 (integer) 1
单独判断某个数据是否存在,则判断返回是否为1即可。
查看键对应值的数据类型:
[type key]
127.0.0.1:6379> type myname string
为某个数据设置过期时间:
[expire key Ns]
127.0.0.1:6379> EXPIRE myage 5 # 设置myage的过期时间为5s (integer) 1 127.0.0.1:6379> get myage # 5s内值为32 "32" 127.0.0.1:6379> get myage # 5s过后为nil (nil)
查看过期时间还剩多少:
[ttl key]
127.0.0.1:6379> ttl myage # 查看myage的过期时间还有多久,单位s (integer) 42 # 剩42s过期
4.Hash数据操作
哈希对应的是多个键值对组成的集合。
设置单个值:
[hset key field value] field表示属性的key
127.0.0.1:6379> hset hset1 name leo # 设置一个属性name,值为leo (integer) 1 127.0.0.1:6379> hset hset1 age 32 # 设置另一个属性age,值为32 (integer) 1
获取某个属性的值:
[hget key field]
127.0.0.1:6379> hget hset1 name "leo"
一次设置多个属性:
[hmset key field1 value1 field2 value2...]
127.0.0.1:6379> hmset h2 name jone age 11 gender male OK
一次获取多个属性的值:
[hmget key field1 field2...]
127.0.0.1:6379> hmget h2 name age gender # 同时获取name age gender的值 1) "jone" 2) "11" 3) "male"
查看hash中有哪些field属性:
[hkeys key]
127.0.0.1:6379> hkeys h2 # 查看hash h2中有哪些属性 1) "name" 2) "age" 3) "gender"
获取hash中所有field对应的值:
[hvals key]
127.0.0.1:6379> hvals h2 # 获取hash h2中所有属性的值 1) "jone" 2) "11" 3) "male"
删除hash中某个属性:
[hdel key field]
127.0.0.1:6379> hdel h2 gender # 删除h2中的gender属性 (integer) 1 127.0.0.1:6379> hkeys h2 # 查看h2中的属性,gender已删除 1) "name" 2) "age"
删除整个hash数据:
[del key]
127.0.0.1:6379> del hset1 # 删除hash数据hset1 (integer) 1
5.List数据操作
List中的元素类型为string,按照插入顺序排列。
从前面(左侧)插入数据:
[lpush key val1 val2 val3]
127.0.0.1:6379> lpush list1 a b c # 从列表前面插入数据a b c (integer) 3
查看列表中的数据:
[lrange key start end]
127.0.0.1:6379> lrange list1 0 2 # 查看index 0~2的数据 1) "c" 2) "b" 3) "a"
可以看出,lpush插入的数据,a最先插入,所以顺序是c b a。
查看列表所有元素:
[lrange key 0 -1]
127.0.0.1:6379> lrange list1 0 -1 # 查看index 0~2的数据 1) "c" 2) "b" 3) "a"
-1表示列表中的最后一个元素。
从后面(右侧)插入数据:
[rpush key val1 val2 val3...]
127.0.0.1:6379> rpush list1 0 1 2 # 从后面插入数据0 1 2 (integer) 6 127.0.0.1:6379> lrange list1 0 -1 # 查看list中的所有数据 1) "c" 2) "b" 3) "a" 4) "0" 5) "1" 6) "2"
在指定元素的前后插入数据:
[linsert key before val new_val]
[linsert key after val new_val]
127.0.0.1:6379> linsert list1 before a go #在a的前面插入go (integer) 7 127.0.0.1:6379> lrange list1 0 -1 1) "c" 2) "b" 3) "go" 4) "a" 5) "0" 6) "1" 7) "2"
127.0.0.1:6379> linsert list1 after go anywhere # 在go的后面插入anywhere (integer) 8 127.0.0.1:6379> lrange list1 0 -1 1) "c" 2) "b" 3) "go" 4) "anywhere" 5) "a" 6) "0" 7) "1" 8) "2"
设置某个index位置的值:
[lset key index val]
127.0.0.1:6379> lset list1 2 hello # 设置index=2的值 OK 127.0.0.1:6379> lrange list1 0 3 1) "c" 2) "b" 3) "hello" 4) "anywhere"
删除列表中的值:
[lrem key count val]
count>0:从前往后删除count个值为val的元素。
count<0:从后往前删除count个值为val的元素。
count=0:删除全部值为val的元素。
# count=2时 127.0.0.1:6379> rpush list2 a b a b a b a b (integer) 8 127.0.0.1:6379> lrem list2 2 a # 从前往后删除2个a (integer) 2 127.0.0.1:6379> lrange list2 0 -1 1) "b" 2) "b" 3) "a" 4) "b" 5) "a" 6) "b"
127.0.0.1:6379> lrem list2 -2 b # 从后往前删除2个b (integer) 2 127.0.0.1:6379> lrange list2 0 -1 1) "b" 2) "b" 3) "a" 4) "a"
127.0.0.1:6379> lrem list2 0 a # 删除所有a (integer) 2 127.0.0.1:6379> lrange list2 0 -1 1) "b" 2) "b"
6.Set数据操作
Set集合无序的,元素不能重复,值得类型都是String。
向集合中添加数据:
[sadd key val1 val2 val3...]
127.0.0.1:6379> sadd set1 zhangsan lisi wangwu (integer) 3
获取集合的所有数据:
[smembers key]
127.0.0.1:6379> SMEMBERS set1 1) "zhangsan" 2) "lisi" 3) "wangwu"
删除集合中的某些值:
[srem key val1 val2...]
127.0.0.1:6379> srem set1 lisi wangwu # 删除lisi和wangwu (integer) 2 127.0.0.1:6379> SMEMBERS set1 1) "zhangsan"
7.Zset数据操作
zset是有序的set集合,在zset中,会为每一个元素指定一个全职(double类型)。
向zset中添加元素:
[zadd key score1 val1 score2 val2 score3 val3...]
127.0.0.1:6379> zadd zset1 7 a1 8 a2 3 a3 1 a4 (integer) 4
a1的权重为7,a2为8,a3为3,a4为1。
获取zset中的值:
[zrange key 0 -1] 和List很像,可以用index来获取值,因为是有序的。
127.0.0.1:6379> zrange zset1 0 -1 1) "a4" 2) "a3" 3) "a1" 4) "a2"
按权值范围来获取值:
[zrangebyscore key min max]
127.0.0.1:6379> ZRANGEBYSCORE zset1 3 7 # 获取权值3-7的值 1) "a3" 2) "a1"
查看某值对应的权重:
[zscore key val]
127.0.0.1:6379> ZSCORE zset1 a2 # 查询值a2对应的权值 "8"
删除指定元素:
[zrem key val1 val2 val3...]
127.0.0.1:6379> zrem zset1 a2 # 删除值为a2的元素 (integer) 1
按权重范围删除:
[zremrangebyscore key min max]
127.0.0.1:6379> ZREMRANGEBYSCORE zset1 2 7 # 删除权重2-7的元素
(integer) 2
八、Python连接Redis
1.安装Redis包
pip install redis
2.连接Redis
import redis # 远程连接redis,地址为192.168.1.181:6379,默认连接的数据库为0.通过db参数修改 sr = redis.Redis(host='192.168.1.181', port=6379, db=0)
九、Python操作Redis
########################## String操作 ################################# # 设置值 res = sr.set("name", 'Zheng') print(res) # 返回True或False # 修改值 res = sr.set("name", 'Leo') print(res) # 返回True或False # 获取值 res = sr.get("name") print(res) # 返回值或None # 删除 res = sr.delete("name") print(res) # 可以同时删除多个delete("key1","key2"),返回删除成功的个数 # 获取所有的key res = sr.keys() print(res) # 返回key列表
=====

