并行计算基础(2)
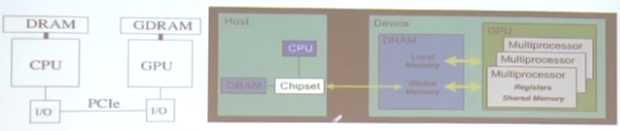
一、CPU和GPU交互
1.各自有自己的物理内存空间,CPU的是内存,GPU的是显存
2.通过PCI-E总线互连(8GB/S~16GB/S)
3.交互开销较大
GPU各存储访存速度:
Register寄存器,最快
Shared Memory,共享存储,很快
Local Memory,本地存储,在显存中,有缓存,相对较慢
Global Memory,全局存储,在显存中,有缓存,相对较慢
Constant Memory,在显存中,多级缓存,1-100时钟周期,比较快
Texture Memory,在显存中,多级缓存,1-100时钟周期,比较快
Instruction Memory,不可见的,在显存中,有缓存
二、GPU线程组织模型

线程组成Block,Block组成Grid。
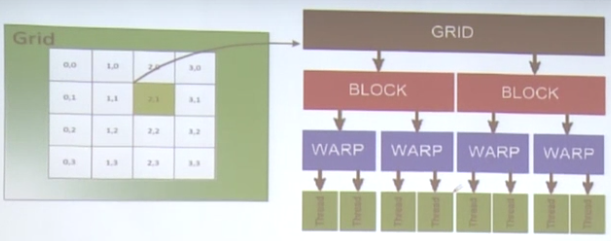
Warp是几个线程的组合,有一定特殊的规律,用于内部管理。
线程组织架构说明:
1.一个Kernel就是一个要运行的程序,里面有大量的线程。Kernel启动一个Grid,里面有若干个Blocks,由用户设定。Grid可以理解为一个公司。
2.一个Block中包含多个线程,一个Block内部的线程共享Shared Memory,可以同步“_syncthreads()”。Block可以理解为一个部门。
3.线程和线程块具有唯一的标识。
程序对于GPU也有一定的映射关系:
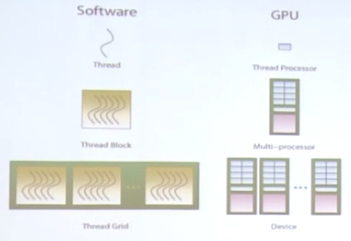
其中,一个线程对应一个CUDA core或ALU,一个Block对应一个SM或SMX,一个Grid对应多个SM,最大为整个设备。
GPU内存和线程的关系:
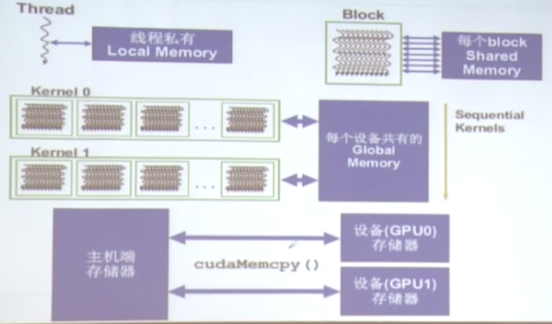
1.一个线程有自己的存储器,叫做Local Memory,是私有的,只能自己访问。例如私人的办工作,电脑等资源。
2.每个Block,有内部线程可共享的Shared Memory,相当于部门中的打印机等共享资源。
3.每个Grid(Kernal)之间有共享的Global Memory,也就是GPU设备的全局存储。相当于多个公司都可以访问的大楼。
4.主机端的存储器(内存)可以和不同的GPU设备的内存(显存)相互拷贝数据。
如下图所示:
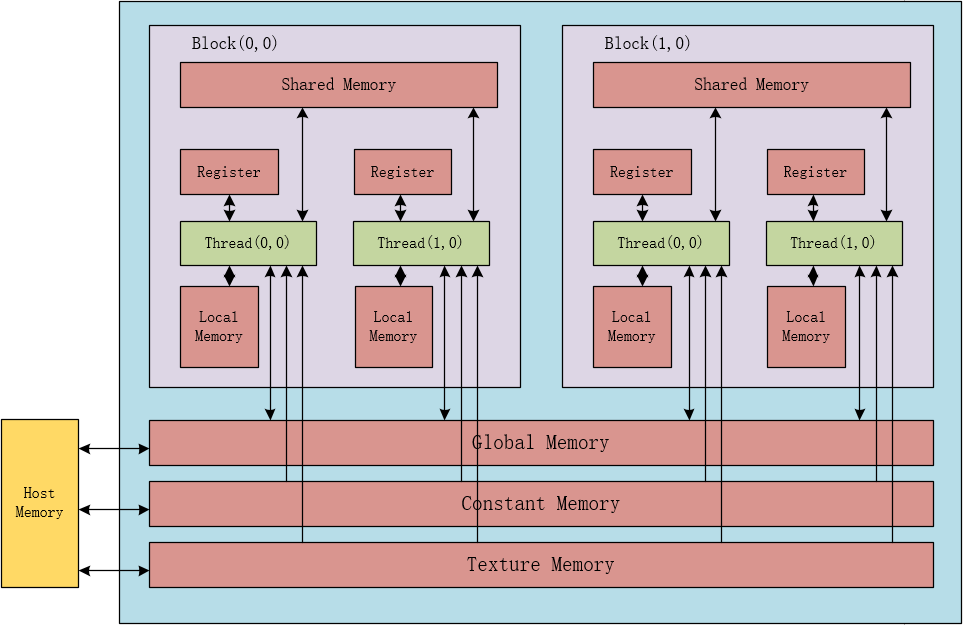
1.线程运算时与寄存器交互最快。
2.线程读取Local Memory时,由于该存储位于外部显存,所以速度相当较慢。
3.一个Block中共享Shared Memory。
4.各个Block中的线程都可以访问Global Memory。
5.Constant和Texture对于线程都是只读的存储。
6.Constant和Texture可以由主机端来读写。
三、CUDA编程模式
CUDA编程语言实际上是扩展的C语言(Extended C)
CUDA提供了许多特定的关键词。例如__device__,__global__,__host__等。
CUDA函数声明:
__device__ float DeviceFunc(); __global__ void KernelFunc(); __host__ float HostFunc();
1.由__device__修饰的函数声明表示该函数的执行位置是在GPU设备上,需要由其他GPU上的函数来调用。
2.由__global__修饰的函数是kernel函数,也是入口函数,在CPU上调用,在GPU上执行,必须返回void。
3.__host__修饰的函数是在主机端调用,也在主机端运行。
4.__device__和__host__可以同时作用于一个函数,说明该函数的操作在CPU和GPU上是一样的。
Kernel:
数据并行处理函数。
通过调用Kernel函数在设备端创建轻量级线程,线程由硬件负责创建并调度。
Kernel函数是在CPU上调用,然后再GPU上执行,是一个入口函数。
// 定义一个Kernel函数用__global__修饰 __global__ void VecAdd(float * A, float *B, float *C) { int i = threadIdx.x; C[i] = A[i] + B[i]; } int main() { //.....需要将A B都拷贝到显存 //.....在显存中分配C的空间 // 使用N个线程来计算 VecAdd<<<1, N>>> (A, B, C); return 0; }
线程层次Thread Hierarchies:
使用一个Block来处理:
__global__ void MatAdd(float A[N][N], float B[N][N], float C[N][N]) { // 线程有N*N个,xy代表线程索引 int i = threadIdx.x; int j = threadIdx.y; C[i][j] = A[i][j] + B[i][j]; } int main() { // 使用一个Block int numBlocks = 1; // 每个Block有N*N个线程 dim3 threadPerBlock(N, N); // 这里使用一个Block,每个Block有N*N个线程 MatAdd <<<numBlocks, threadPerBlock>>> (A, B, C); return 0; }
上述代码中,只使用一个Block(一个部门),该Block中有N*N个线程(人员)。这个Block是一个2D的Block。
Block中的线程:
在G80和GT200显卡中,每个Block最多512个线程,而Fermi架构的GPU每个Block可以有1024个线程,可以查阅相关GPU手册。
每个Block相当于一个SM,即核心。所以该Block中的线程都是工作在相同的处理器核心中的。他们共享所在核心的Shared Memory。
使用多个Block处理:
__global__ void MatAdd(float A[N][N], float B[N][N], float C[N][N]) { // 遍历每个Block的所有元素,并分别执行加法 int i = blockIdx.x * blockDim.x + threadIdx.x; int j = blockIdx.y * blockDim.y + threadIdx.y; if (i < N && j < N) { C[i][j] = A[i][j] + B[i][j]; } } int main() { // 每个Block有16*16个线程 dim3 threadPerBlock(16, 16); // 使用需要计算矩阵的尺寸来计算需要多少个Block dim3 numBlocks(N / threadPerBlock.x, N / threadPerBlock.y); // 这里使用一个Block,每个Block有N*N个线程 MatAdd <<<numBlocks, threadPerBlock>>> (A, B, C); return 0; }
Block与GPU核心(SM)数量关系:
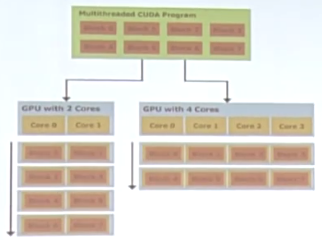
当GPU只有2个SM(核心)时,程序有需要8个Block,则需要通过2个核心4次运算才能完成。
如果是4个核心,则需要2次运算才能完成。
四、数据传输
使用cudaMalloc在device上申请内存空间:
// 该指针用于存放device上分配空间的首地址 float * Md = 0; // 申请设备内存大小为size int size = 16 * 16 * sizeof(float); // 这里必须传入&Md,即Md指针的地址。 // 因为cudaMalloc会将分配好的设备内存首地址赋值给Md,这个Md只能在Device上使用,不能直接在CPU程序中赋值等 cudaMalloc((void **)&Md, size); // 释放Md指向的设备内存空间 cudaFree(Md);
内存传输:
Host to Host
Host to Device
Device to Host
Device to Device
对应一下四种操作:
// 申请设备内存大小为size int size = 16 * 16 * sizeof(float); // M指向CPU上的空间 float * M = (float *)malloc(size); float * M2 = (float *)malloc(size); // Md指向GPU上的空间 float * Md = 0; float * Md2 = 0; cudaMalloc((void **)&Md, size); cudaMalloc((void **)&Md2, size); // 从主机端内存中拷贝数据到Device的Global Memory中 cudaMemcpy(Md, M, size, cudaMemcpyHostToDevice); // 从设备端拷贝数据到主机端 cudaMemcpy(M, Md, size, cudaMemcpyDeviceToHost); // 从主机端数据拷贝到主机端另一个空间,相当于memcpy cudaMemcpy(M, M2, size, cudaMemcpyHostToHost); // 从设备端拷贝数据到设备端另一个空间 cudaMemcpy(Md2, Md, size, cudaMemcpyDeviceToDevice);
五、矩阵乘法示例
// Md,Nd,Pd都是Width*Width的方阵,使用的Block中线程数也是W*W __global__ void MatMulKernel(float * Md, float * Nd, float * Pd, int Width) { // 横坐标为tx的列索引 int tx = threadIdx.x; // 纵坐标为ty的行索引 int ty = threadIdx.y; float Pvalue = 0; for (int k = 0;k < Width;++k) { // 处于tx的一行 float Mdelement = Md[ty * Width + k]; // 处于ty的一列 float Ndelement = Nd[k * Width + tx]; // Width元素做累加,得到坐标ty,tx的值 Pvalue += Mdelement * Ndelement; } // 将计算得到的ty,tx的值写入相应的位置 Pd[ty * Width + tx] = Pvalue; }
六、GPU上函数需要注意的问题
由于GPU特殊的工作情况和结构,在__Global__和__device__函数中,注意以下几点:
1.尽量少用递归(不鼓励)
2.不要使用静态变量
3.少用malloc(允许但不鼓励,因为并行的使用malloc,空间很快耗光)
4.小心通过指针实现的函数调用(注意指针时CPU端的还是GPU端的)
七、CUDA数据类型
矢量数据类型(同时适用于host和device代码):

通过函数make_<type name>构造:
int2 i2 = make_int2(1, 2); float4 f4 = make_float4(1.0f, 2.0f, 3.0f, 4.0f); cout << i2.x << i2.y << endl; cout << f4.x << f4.y << f4.z << f4.w << endl;
八、CUDA支持的部分函数
部分函数列表:

面向Device端,更快,精度降低:

九、线程同步
块内线程可以同步(Block内):
调用__syncthreads 创建一个barrier栅栏
每个线程在调用点等待块内所有线程执行到这个地方,然后再继续执行后续指令
Md[i] = Hd[j]; __syncthreads(); func(Md[i], Md[i + 1]);
如上述代码所示,func中同时需要Md[i]和Md[i+1],当Md[i]准备好时,Md[i+1]不一定准备好了,所以需要在前面等待Md[i+1]准备好后,再继续执行func函数。
__syncthreads会导致线程的暂停,破坏了线程执行的独立性,并可能由于线程同步的位置不同(条件分支中使用同步)导致同步死锁。所以在使用同步时一定要小心。
十、线程调度
以G80显卡为例:
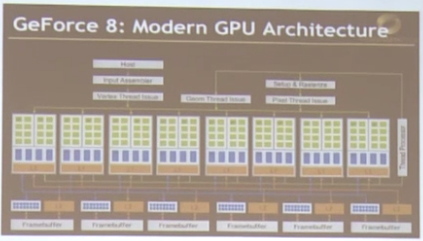
G80包含以下:
1.有16个核,也就是SM(8个绿色方框为一个SM)
2.每个SM有8个SP,也就是CUDA core或ALU(1个绿色方框)
3.每个SM最多可驻扎768个线程,128 X 6 = 768,每个SM可以保存6个上下文(蓝色部分)
4.总共可以同时驻扎12288个线程
5.但是由于只有128个CUDA core,同时也就只能执行128个线程
对于一个GPU设备来说,最大处理的线程量主要和CUDA core总量以及每个SM的上下文数量有关。但同时执行的线程数只与CUDA core数一致。
Warp:
针对Block中的线程,例如有64个线程(CUDA core),编号是连续的0-63。
假设一个Warp是32个线程组成(Warp的线程数和Block的线程数一般呈倍数关系,warpSize),则该Block中就有2个Warp,都运行在同一个SM上。第一个Warp线程编号为0-31,第二个Warp的线程编号为32-63。
Warp是线程调度的最小单位。
Warp的线程是天生同步的,也就是说他们必须是执行相同的指令流,当遇到分支可能导致执行的程序不同时(例如if else)则会出现串行的可能:

可能出现最差性能,就是1/N的性能。
例子:
1.如果一个SM分配了3个Block,其中每个Block含256个线程,那么总共有24个Warp(每个Warp 32个线程)。
2.GT200的一个SM最多可以驻扎1024个线程,那相当于1024/32=32个Warp。
3.假设每个Warp有32个线程,但每个SM只有8个SPs,如何分配?需要将一个Warp分成4份,然后在一个SM上轮换执行4次。流程如下:
指令已经预备
第一个周期8个线程进入SPs
在第二、三、四周期各进入8个线程
因此,分发一个Warp需要4个周期
4.对于目前的GPU来说,SM中所含的SP数一般都大于Warp含线程数量,所以以上分发流程一般不会再出现。
十一、内存模型
寄存器:
假设每个SM有8K个寄存器,有768个线程。则每个线程可以分到10个寄存器。
当超出限制时,则将因为Block的减少而减少。
例如,当一个线程需要用到11个寄存器,一个Block含256个线程。
本来如果每个线程使用寄存器不超出限制的时候,这个SM可以容纳3个Block(一个Block内的线程只能在同一个SM上执行),也就是刚好768个线程。
但由于寄存器超出限制,这个SM就只能容纳2个Block,即512个线程。所以就造成了资源的浪费。剩下未分配的SP也就只能闲着。
共享存储:
和寄存器类似原理类似。
假设每个SM最多8个Block,一共有16KB共享存储器。如果一个Block需要大于2K的共享存储器,则这个SM就不能容纳8个Block,同样造成资源浪费。
全局存储(显存):
访存延时(100个周期),访存较慢,片外存储
Host主机可读写
GT200 GPU访存带宽150GB/s,容量4GB,新的显卡的访存带宽已达到300-500GB/s,容量达到8-32GB
位于不同存储的变量定义:
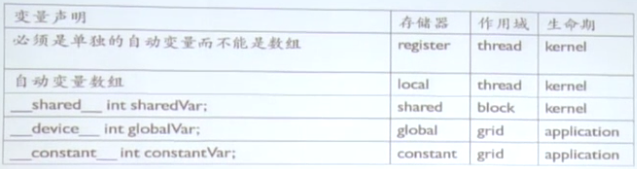
其中register和local存储我们不能操作。
__shared__定义存放在共享存储中的变量,这个变量只能是Block内部线程共享。
使用__device__关键字来定义全局存储(显存)中的变量。
__constant__用来定义常量(例如PI),存放在constant Memory中的。

