并行计算基础(1)(GPU架构介绍)
一、常用术语
Task:任务。可以完整得到结果的一个程序,一个程序段或若干个程序段。例如搬砖。
Parallel Task:并行任务。可以并行计算的任务。多个人搬砖。
Serial Execution:串行执行。一个人搬砖。
Parallel Execution:并行执行。多个人一起搬砖。
Shared Memory:共享存储。
Distributed Memory:分布式存储。砖放在不同的地方。
Communications:通信。几个人搬砖时互相安排下一次搬几个砖。
Synchronization:同步。若干个人一起拿砖、一起放砖,动作同步。
Granularity:粒度。任务划分时,任务的大小。
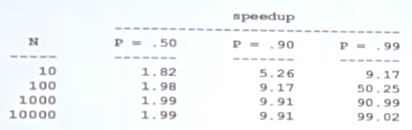
Observed Speedup:加速比。对比一个标志物,并行系统所能获得的性能提升。
Parallel Overhead:并行开销。
Scalability:可扩展性。并行数扩展后,性能是否线性提升,主要要注意并行通信等的开销问题。
二、Amdahl's Law并行加速比
如果有N个处理器并行处理:
$$\begin{aligned} speedup &=\frac{1}{\frac{P}{N}+S} \end{aligned}$$
并行化的可扩展性存在极限,主要取决于不能并行的部分(串行部分):
三、GPU
FLOPS:Floating-point Operations Per Second ,每秒浮点运算操作数量
GFLOPS:One billion FlOPs,每秒十亿次浮点运算
TFLOPS:1000 GFLOPs,每秒万亿次浮点运算
在CPU-style核心中:
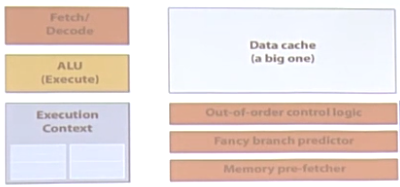
左边是主要进行计算的部分(干活),右边主要是为了让任务完成得更快而产生了一系列管理部件(占据了芯片的很大部分成本和面积)。
GPU结构的进化过程:
1.在GPU核心中,为其进行了瘦身,大量缩减了右边的管理机构,得到瘦身后的核,并使用多个核:

将这样的理念更深入的实现,就可以得到可以大量并行化的核:
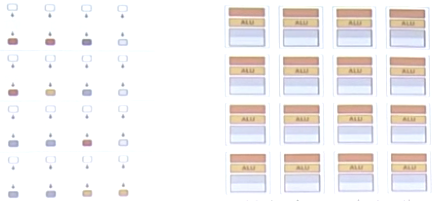
这一系列并行核芯可以同时执行多个程序片元(即程序段),这些程序片元需要共享相同的指令流。因为如果不是相同的指令流,则需要很复杂的控制机构,那就变成了CPU style了。
(上述概念相当于增加了干活的人)
2.我们可以增加核的数量,那我们也可以加宽核(增加每个核的ALU数):
在这个核中,我们就可以进行向量的运算(多个数据组成向量vector)。
(上述概念相当于增加了一个人可以同时处理的数据个数,一个人8把切西瓜的刀,一次切8个西瓜)
3.如何处理指令流中有分支的情况:
例如当x>0时,执行操作A,当x<0时,执行操作B:
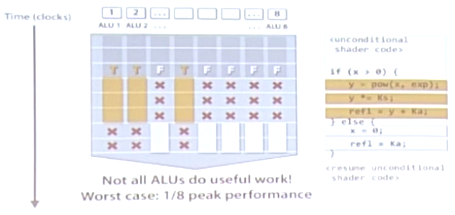
如图,8个ALU执行同一个指令流,但是其中有3个的数据大于0,执行A操作。而剩下5个数据小于0,执行B操作。此时,A和B操作只能错开来执行,不能同时执行。那么这就会导致ALU存在一个性能的最坏情况,白白浪费。
4.停滞stalls的问题:
当核心要处理的数据还没准备好时(处理很快,数据访问速度慢),或者对其他任务的结果有依赖。则需要停滞下来进行等待,这样很浪费性能。
我们可以通过使用大量的独立片元相互切换来使核心一直有事情做。

如上图所示,当任务1没准备好时,就去做任务2,2没准备好就做任务3......
在切换这些任务的过程中,需要保存每次运行的上下文信息,所以每个核心都有一个叫上下文存储池的存储空间。

将存储空间分块:

空间划分数量多,则可以切换的任务数多,但每个任务所能存放的上下文就比较小。反之任务数少,每个任务存放上下文多。
(上下文切换可以是软件管理的也可以是硬件管理的,还可以是两者结合的,例如GPU主要是硬件管理的,而且上下文非常多)
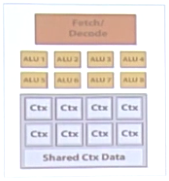
5.FLOPS计算
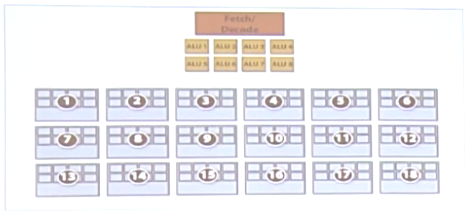
如上图所示:
1). 16个核心cores
2). 每个核心8个计算单元ALUs,一共128个ALUs,即16核心 X 8个ALUs = 128
3). 16核就可以承载16路指令流
4). 每个核可以存储4个任务的上下文,则可以同时跑64路的指令流,即16核 X 4任务 = 64
5). 总的可以承载512个程序片元,即64个指令流 X 每核8个ALUs = 512
6).FLOPS 为256GFLOPS, 16核 X 8 ALUs X 1GHz X 2 = 256GFLOPS(为什么要乘以2)
6.GPU设计总结(工人阶级的血汗史)
1).使用瘦身的核,来增加并行处理数
2).每个核中塞N个ALUs
3).让其不停的干活,即任务切换
7.物理GPU的设计
NVIDIA GeForce GTX 480采用Fermi架构:
有480个SP(stream processors)流处理器,实际上就是ALUs。取名也叫CUDA core。
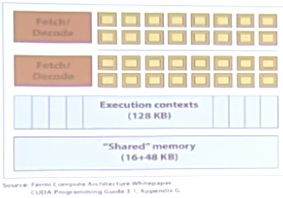
15个核心,这个核心叫SM,即流多处理器,Stream multiprocessor。
每个SM有两组,每组16个CUDA core,即32个ALUs。15 X 32 = 480。

GTX680:
每个SM中有192个CUDA cores(图中浅绿色部分)。SM更强,改名为SMX。
192个CUDA,但是每32个CUDA core作为一组,则需要6个组长,但实际上只有4个组长,这就需要动态的调度(具体调度方法不做了解)。

整个GTX680芯片由8个SMX组成。

8.显存
GPU芯片的很大部分面积都是CUDA core,而显存放在芯片的外面。
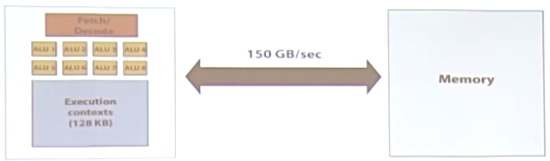
最重要的是访存带宽,因为CPU的运算是很快的,但是读写存储中的数据可能是很慢的。虽然目前GPU中的访存带宽做了专门的设计和优化,但对于GPU的运算能力来说还是不太够。但就算这样也比CPU快很多倍。
GPU中缓存的大小相对CPU更小,因为GPU的访存带宽比CPU大,所以处理好带宽的利用就好了。
减少带宽需求:
1).尽量减少数据的访问。
2).小数据打包访存,减少访存的次数。
9.高效的GPU任务具备的条件
1).具有成千上万的独立工作,尽量利用大量的ALU单元,大量的片元切换来掩藏延迟。
2).可以共享指令流,使用与SIMD处理。
3).最好是计算密集的任务,通信和计算开销比例合适,不要受制于访存带宽。

