计算机视觉基础-2——图像分类与卷积网络介绍
一、图像分类定义
可以用一个简单的公式来描述图像分类的过程:

训练:通过训练集{(x1,y1),...,{xn,yn}}来获得一个预测函数f,满足在训练集上的最小误差。
测试:向预测函数f输入一个从来没有见过的x,得到预测值y。

二、泛化能力
我们在训练的过程中,要注意所训练出来的模型的泛化能力。所谓泛化能力,就是要让模型认识不同形态、不同颜色等不同特征的同类事物,例如苹果,苹果有黄色的、绿色的、红色的等,当训练出来的模型不能只认识红色的,而要认识各种不同种类的苹果。
所以,我们在训练模型的时候,提供的训练集就要尽可能的包含多种同类事物(局部特征可能不同),让模型来自己学习他们的共性,从而获得泛化能力。

三、传统机器学习的训练和测试过程
在机器学习领域中,如果我们要对一个图片进行分类,想要让其具有良好的泛化能力,我们不能将原始的RGB图片直接作为输入,而是需要经过以下过程:

1.在训练的时候,首先要对图像进行特征提取,摒除一些干扰因素,例如杂乱的背景等等
2.使用分类算法进行训练,训练的时候用标签来计算损失,最后得到训练好的分类器(模型)。
3.测试时,同样要首先对图像做特征提取(要和训练时的特征提取操作一致),然后使用训练好的模型进行预测,得到预测值。
四、图像特征提取介绍
1.颜色特征
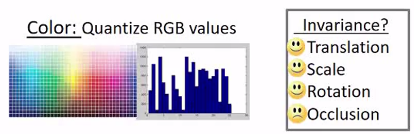
颜色特征是将图片的颜色做直方图,直方图就是其颜色分布的特征。
2.全局形状

通过PCA降维来提取全局形状特征,但是当形状旋转和扭曲的时候,效果不好。
3.局部形状
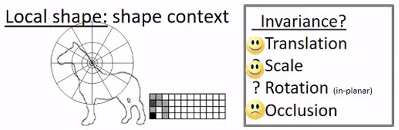
4.纹理
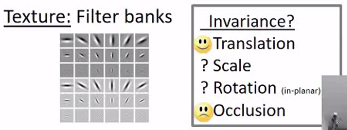
常用的图像特征有以下几种:
1.SIFT特征

SIFT是一种比较有用的特征,将一个区域划分为16格,每一个提取一个8维的梯度向量,然后将16个8维向量串起来得到一个128维的特征向量。主要用在图像分类和图像匹配等任务。
2.HOG特征

HOG主要用在目标检测领域,能够比较精确的将目标的形状给检测出来,所以在目标检测和跟踪方面用得比较多。
3.LBP特征

主要对人脸特征的提取比较好。
4.Harr特征
即角点特征,使用各种过滤器对图像进行处理,可以提取横向、纵向等方向的边界。
五、使用SVM来分类iris兰花


六、CNN结构初窥

相比于前面的机器学习对图像的分类来说,CNN可以将一个图片直接作为输入,然后通过卷积层和全连接层,就可以得到分类的输出,是一个端到端的过程。
七、深度学习中的激励函数
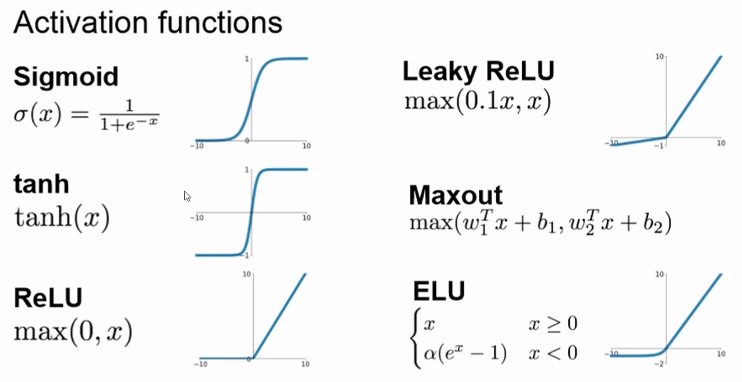
激励函数是一些非线性的函数,这些函数的特性有所不同:
1.Sigmoid函数可以将数值压缩到0-1的区间。
2.tanh可以将数值压缩到-1-1的区间。
3.Relu函数实现一个取正的效果,所有负数的信息都抛弃。
4.leaky Relu是一种相对折中的Relu,认为当数值为负的时候可能也存在一定有用的信息,那么就乘以一个系数0.1(可以调整或自动学习),从而获取负数中的一部分信息。
5.Maxout使用两套参数,取其中值大的一套作为输出。
6.ELU类似于Leaky Relu,只是使用的公式不同。
每一层的非线性激励函数组合起来,就可以形成一个非常复杂的非线性函数,也就可以有足够的能力来处理大量的信息(即可以保存大量的知识来指导分类)。
八、卷积运算过程
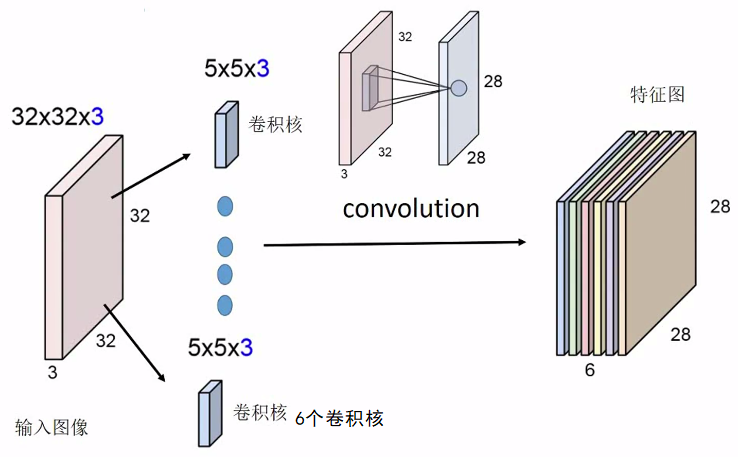
输入图像:32*32是图像的高和宽,其中的每一格是一个像素点,由于RGB图像有3个颜色通道,所以该图像的channel为3,一共就是32*32*3。
卷积核:卷积核的size一般是奇数*奇数,channel要与被卷积的图像相同,这里也为3。
特征图:就是卷积后的图像,宽和高一般情况下会变小(valid padding),但是我们可以通过padding的方式使之不发生变化,也就是“same”的padding方式。特征图的channel值应该是等于卷积核的个数,因为每一个卷积核对图像进行卷积,都会产生一个channel为1的矩阵,6个卷积核产生的结果就是6个图层的叠加,所以结果维度为28*28*6。
卷积的计算过程:
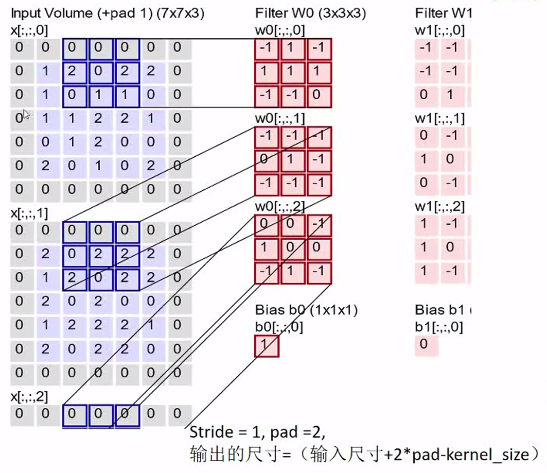
解释:
1.W0表示一个卷积核,大小是3*3*3,一共27个参数,这些参数都是通过BP算法来更新的。
2.卷积核的3和channel对应输入图像的3个channel,从第一格开始滑动,每次都计算自己覆盖的所有像素点,求他们的积,再求和。得到3个channel为1的矩阵。
3.注意上图中输入图像外围的灰色填充0,这就是padding,这样填充后,经过卷积计算,得到的结果矩阵与输入图像的高和宽一致,这叫“same” padding。
4.卷积核的3和channel分别得到的3个矩阵,在求和,可以得到一个高和宽与输入图像一致,channel为1的结果矩阵。
5.然后第二个卷积核W1再来做同样的操作,最终同样得到一个结果矩阵。
6.假设一共有6个卷积核,那么最终就会得到一个高宽与输入图像一致,channel为6的三维矩阵。
九、卷积层可视化
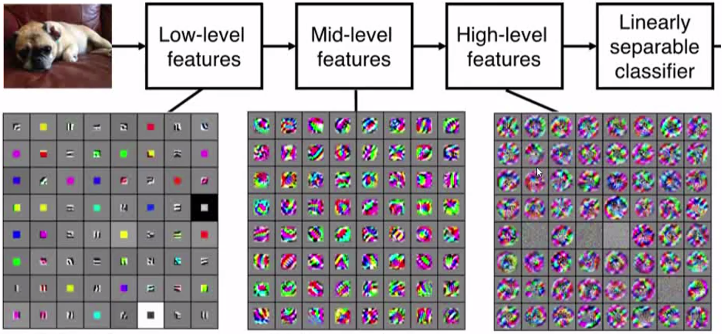
从上图可以看出,在接近输入层的卷积部分。提取到的图像特征很像前面机器学习用到的几种特征,所以在低级特征中,CNN就完成了各种常用特征的提取,并且将他们融合起来。
而更重要的是后面的中级特征和高级特征,这些特征是前面提到的机器学习特征很难获取的特征,这些特征才能真正表征一个图像的本质,从而提供给后面做精确的分类。
十、池化层
池化层实际上就是一个降采样的过程。
一般有两种常用的池化方式:
1.平均池化:Average pooling
2.最大池化:Max pooling
以最大池化为例:
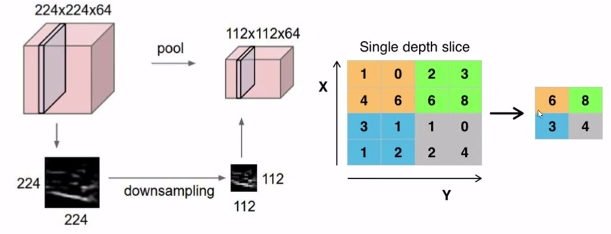
池化的核通常采用2x2的大小,平均池化就是计算2x2范围内的平均值,最大池化就是取该范围内的最大值。目前比较常用的是最大池化。
在经过池化后,原图像的channel是不发生改变的。
十一、全连接层
在经过卷积层、池化层后得到的结果矩阵,我们通过将其压平(flatting)后,就可以输入全连接层。

如图所示,结果矩阵压平后得到一个1x3072的向量,然后输入到拥有10个节点的全连接层,得到一个1x10的输出(使用softmax激励函数),就将图像分为10类了。
十二、损失函数
1.交叉熵损失函数
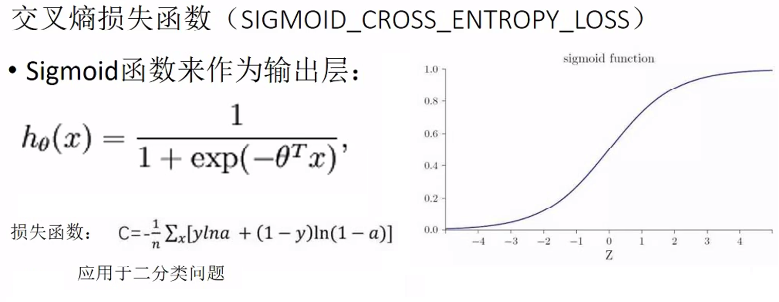
交叉熵损失函数主要用于二分类问题,一般配合Sigmoid函数作为输出层。
2.Softmax损失函数

Softmax作为输出层,他的损失函数和交叉熵损失函数很像。交叉熵损失函数实际上的softmax在二分类时的特例。当只有分个分类时,y1 = 1-y0,a1 = 1-a0带入损失函数可以得到L = -∑[ y0loga0+(1-y0)log(1-a0)]。
3.欧式距离损失函数

主要用于回归任务。
4.对比损失函数

用于训练Siamese网络(暹罗网络)。用于人脸对比等方面。
5.Triplet损失

三元损失有3个输入,A,P,N。我们要使A和P之间的距离尽可能小,而A和N之间的距离尽可能大。
十三、训练网络的过程
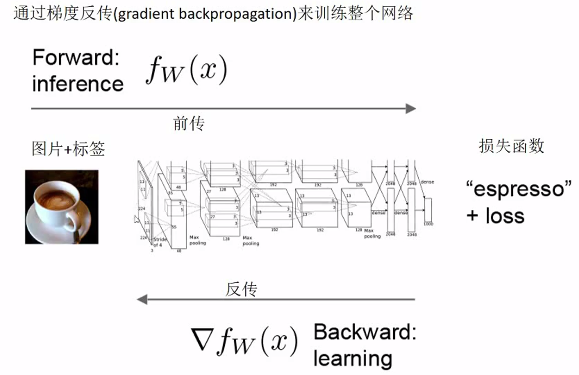
1.首先我们的输入图片经过N层的卷积层、池化层进行特征提取。
2.得到的结果矩阵经过flatting,变为向量,然后输入全连接层进行分类。
3.通过训练集标签和每一轮的分类结果进行比对,使用损失函数计算损失值。
4.将损失值通过梯度下降的方式反向传播,更新全连接层的参数以及卷积层的卷积核参数。
5.不断迭代,知道损失值变得收敛(变得很小,达到我们的预期),即逼近最优解。

