机器学习深度学习框架使用问题汇总
1.使用keras做mnist分类时,运行时GPU报错
错误信息如下:
2019-07-06 10:26:32.949617: I T:\src\github\tensorflow\tensorflow\core\platform\cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 2019-07-06 10:26:33.125786: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:1392] Found device 0 with properties: name: GeForce GTX 960 major: 5 minor: 2 memoryClockRate(GHz): 1.2785 pciBusID: 0000:02:00.0 totalMemory: 4.00GiB freeMemory: 3.33GiB 2019-07-06 10:26:33.125952: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:1471] Adding visible gpu devices: 0 2019-07-06 10:26:33.395215: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:952] Device interconnect StreamExecutor with strength 1 edge matrix: 2019-07-06 10:26:33.395314: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:958] 0 2019-07-06 10:26:33.395375: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:971] 0: N 2019-07-06 10:26:33.395553: I T:\src\github\tensorflow\tensorflow\core\common_runtime\gpu\gpu_device.cc:1084] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 3062 MB memory) -> physical GPU (device: 0, name: GeForce GTX 960, pci bus id: 0000:02:00.0, compute capability: 5.2) 2019-07-06 10:26:33.982153: E T:\src\github\tensorflow\tensorflow\stream_executor\cuda\cuda_blas.cc:459] failed to create cublas handle: CUBLAS_STATUS_ALLOC_FAILED 2019-07-06 10:26:33.982424: E T:\src\github\tensorflow\tensorflow\stream_executor\cuda\cuda_blas.cc:459] failed to create cublas handle: CUBLAS_STATUS_ALLOC_FAILED 2019-07-06 10:26:33.983696: E T:\src\github\tensorflow\tensorflow\stream_executor\cuda\cuda_blas.cc:459] failed to create cublas handle: CUBLAS_STATUS_ALLOC_FAILED 2019-07-06 10:26:33.983828: E T:\src\github\tensorflow\tensorflow\stream_executor\cuda\cuda_blas.cc:459] failed to create cublas handle: CUBLAS_STATUS_ALLOC_FAILED 2019-07-06 10:26:33.984097: E T:\src\github\tensorflow\tensorflow\stream_executor\cuda\cuda_blas.cc:459] failed to create cublas handle: CUBLAS_STATUS_ALLOC_FAILED 2019-07-06 10:26:33.985419: E T:\src\github\tensorflow\tensorflow\stream_executor\cuda\cuda_blas.cc:459] failed to create cublas handle: CUBLAS_STATUS_ALLOC_FAILED 2019-07-06 10:26:33.985513: W T:\src\github\tensorflow\tensorflow\stream_executor\stream.cc:2009] attempting to perform BLAS operation using StreamExecutor without BLAS support Traceback (most recent call last): File "C:\Users\Administrator\AppData\Roaming\Python\Python36\site-packages\tensorflow\python\client\session.py", line 1322, in _do_call return fn(*args) File "C:\Users\Administrator\AppData\Roaming\Python\Python36\site-packages\tensorflow\python\client\session.py", line 1307, in _run_fn options, feed_dict, fetch_list, target_list, run_metadata) File "C:\Users\Administrator\AppData\Roaming\Python\Python36\site-packages\tensorflow\python\client\session.py", line 1409, in _call_tf_sessionrun run_metadata) tensorflow.python.framework.errors_impl.InternalError: Blas GEMM launch failed : a.shape=(32, 784), b.shape=(784, 32), m=32, n=32, k=784 [[Node: dense_1/MatMul = MatMul[T=DT_FLOAT, _class=["loc:@training/RMSprop/gradients/dense_1/MatMul_grad/MatMul_1"], transpose_a=false, transpose_b=false, _device="/job:localhost/replica:0/task:0/device:GPU:0"](_arg_dense_1_input_0_2/_29, dense_1/kernel/read)]] [[Node: loss/mul/_61 = _Recv[client_terminated=false, recv_device="/job:localhost/replica:0/task:0/device:CPU:0", send_device="/job:localhost/replica:0/task:0/device:GPU:0", send_device_incarnation=1, tensor_name="edge_361_loss/mul", tensor_type=DT_FLOAT, _device="/job:localhost/replica:0/task:0/device:CPU:0"]()]]
解决办法:
在前面设置tensorflow对GPU内存的分配比例:
# 解决报错GPU运行报错的问题 # 这里导入tf,用来修改tf后端的配置 import tensorflow as tf from keras.backend.tensorflow_backend import set_session config = tf.ConfigProto() # 将显存容量调到只会使用30% config.gpu_options.per_process_gpu_memory_fraction = 0.3 # 使用设置好的配置 set_session(tf.Session(config=config))
2.Matplotlib和Qt5py的兼容问题
在Pycharm中使用matplotlib的时候,当取消了show plots in tool windows选项时,报错:
pycharm This application failed to start because it could not find or load the Qt
platform plugin "windows"
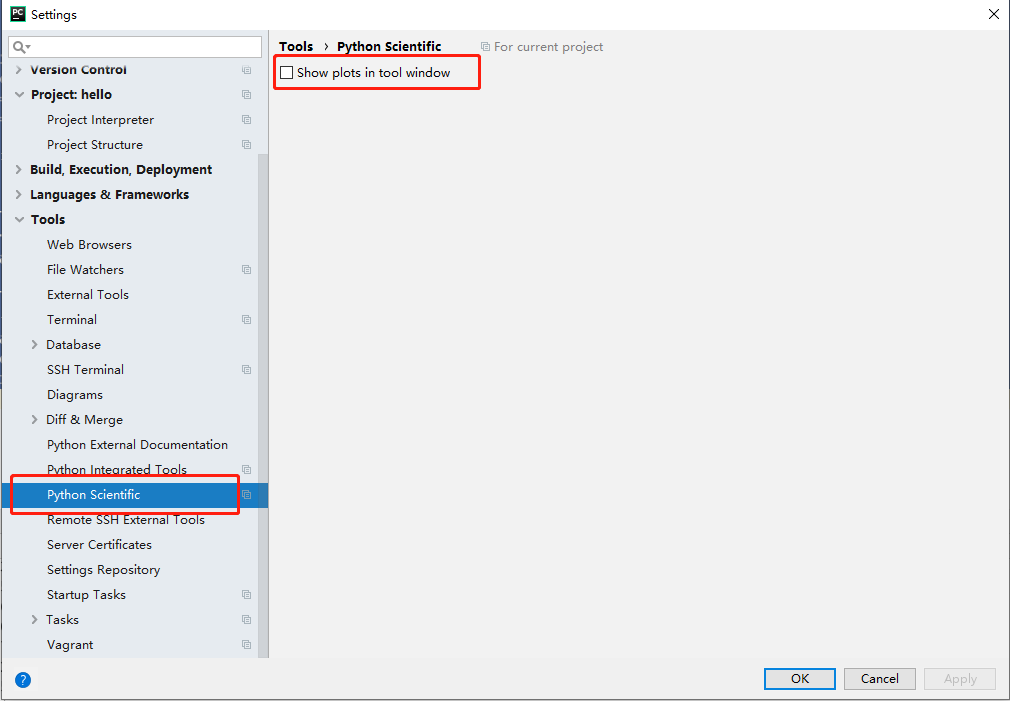
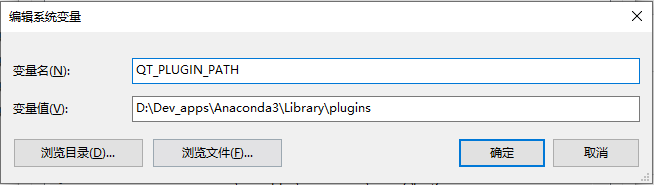
解决办法:
在系统变量中添加QT_PLUGIN_PATH
3.训练途中出现NaN数值,比如loss和accuracy等
1.一般出现NaN时,是因为有一些非法计算过程,例如log(0),所以我们要检查是否在计算过程中存在tf.math.log()等函数
如果有的话,可以使用tf.log(tf.clip_by_value(y,1e-8,1.0))
2.可以尝试调整学习率
4.使用tensorflow训练时出现调用cudnn错误
错误信息:
tensorflow/stream_executor/cuda/cuda_driver.cc:406 failed call to cuInit: CUDA_ERROR_UNKNOWN
解决方法:
在Nvida官网查看显卡所需驱动版本:https://www.geforce.cn/drivers

下载并安装更新,问题解决。
保持学习,否则迟早要被淘汰*(^ 。 ^ )***

