C++程序设计1(侯捷video 7-13)(big three、stack heap、new delete、内存分配、static、模板、namespace、复合、委托、虚函数、重载覆盖改写、设计模式)
一、Big three(拷贝构造、拷贝赋值、析构函数)(video7)
Big three指三个特殊函数,分别是拷贝构造函数、拷贝赋值和析构函数。
什么时候需要拷贝构造、拷贝赋值、析构函数:
当类中的数据是指针时,例如string类中保存字符串使用char *,那么就不能直接使用编译器给的默认Big three。因为默认的函数是按字节拷贝的,这样拷贝后的对象中的指针指向的位置和被拷贝的对象一样,这样不是真正的拷贝。
class mystring { public: //普通构造函数 mystring(const char* chr = 0); //拷贝构造函数 mystring(const mystring& mstr); //析构函数 ~mystring(); //拷贝赋值 mystring& operator = (const mystring& mstr) { //检测是否为自我赋值 if (this == &mstr) { return *this; } //先将已有的空间释放,否则会内存泄漏 delete[] mychar; //创建新的空间,大小和mstr.mychar指向空间一样大 mychar = new char[strlen(mstr.mychar) + 1]; //赋值内容 strcpy(mychar, mstr.mychar); //返回等号左边的mystring对象,以防连续赋值 return *this; } private: //变量是指针,必须实现拷贝赋值和拷贝构造 char * mychar; }; inline mystring::mystring(const char* chr) { //判断传入的指针是否为空(或默认为空) if (chr) { //如果不为空,则按chr的大小分配空间,并让mychar指向该空间 mychar = new char[strlen(chr) + 1]; //将chr的数据复制到mychar指向的空间中 strcpy(mychar, chr); //如果指针为空 }else { //创建一个大小为1的空间 mychar = new char[1]; //只保存一个\0 *mychar = '\0'; } } inline mystring::mystring(const mystring& mstr) { //分配一个和mstr.mychar字符串一样大的空间,并让mychar指向该空间 mychar = new char[strlen(mstr.mychar) + 1]; //将内容复制到mychar指向的空间中 strcpy(mychar, mstr.mychar); } inline mystring::~mystring() { //当对象生命周期要结束的时候,必须清理内存(堆空间),否则会内存泄漏 delete[] mychar; }
在上述代码中,拷贝构造函数做的事情实际上是深拷贝,而默认的拷贝构造函数做的事情是浅拷贝(只复制mstr.mychar指针的4byte到mychar中)。如下图所示:

代码中,以下部分非常重要:
//检测是否为自我赋值 if (this == &mstr) { return *this; }
如果this和mstr是同一个对象,那么如果没有自我赋值的检测,可能会导致程序出错。
因为我们在拷贝数据之前,第一步就是先delete[] mychar,那么也就是删除了mstr.mychar指向的空间。
第二步我们要参照mstr.mychar指向空间的大小来开辟空间就会出问题,更别提复制其中的内容。
所以,自我赋值检测非常重要。
二、为mystring类添加<<重载函数(video7)
//定义成员方法,获取mychar指针,不修改数据,加上const inline char * mystring::get_c_str() const { return this->mychar; } //重载操作符<<,使可以直接cout<<mystring_obj; inline ostream& operator << (ostream& os, const mystring& mstr) { os << mstr.get_c_str(); return os; }
三、stack和heap(video8)
Stack栈:存在于某个作用域(scope)的一块内存空间。例如当调用函数,函数本身即会形成一个stack用来放置它所接受的参数,以及返回地址。
Heap堆:是指由操作系统提供的一块global内存空间,程序可动态分配从中获得若干块(blocks)。当使用完毕后,有责任主动去释放这块内存。
//存在一个类(忽略定义) class Complex {}; //Global Object,存在于全局作用域,直到程序结束 Complex c4(1.0, 2.0); //某个作用域,例如某个函数内部 { //Stack Object,出作用域时自动清理,也叫Auto Object Complex c1(1.0,2.0); //c2指向的对象存在于heap堆中,叫Heap Object Complex * c2 = new Complex(1.0, 2.0); //static Object,出作用域该对象仍然存在,直到程序结束 static Complex c3(1.0, 2.0); delete c2; }
上述代码中:
c1对象是放在stack中的(c1中如果存在指针指向的空间,那么那块空间还是在堆里,但在c1生命周期完结的时候,有析构函数去释放他们)。
c2指针指向的对象是放在堆空间的,new关键字表示在堆空间中分配地址存在对象。该作用域的栈中只存放了c2这个指针(4 bytes)。记得使用完后在作用域内使用delete p;释放空间,否则会内存泄漏。
c3叫静态对象,该对象存在直到程序结束。
c4叫全局对象,该对象是在所有local scope外定义(全局作用域),存在直到程序结束。
四、new和delete关键字的工作流程(video8)
new的流程:
Complex * px = new Complex(1, 2);
编译器自动转化为以下操作:
Complex * px; //栈中分配一个指针空间 void *mem = operator new (sizeof(Complex)); //堆中分配空间,底层使用的是C语言的malloc(n) pc = static_cast<Complex*>(mem); //将void*转型为Complex* pc->Complex::Complex(1, 2); //调用构造函数相当于Complex::Complex(pc,1,2) pc表示this指针
简单介绍static_cast:static_cast<new_type>(expression)和C语言的类型强转是一样的。他们的区别一句话总结:static_cast在编译时会进行类型检查,而强制转换不会。
delete的流程:
mystring *ps = new mystring("hello"); delete ps;
编译器自动转化为以下操作:
mystring::~mystring(); //先调用析构函数,将对象中指针变量指向的空间释放掉 operator delete(ps); //然后再释放自己所占的堆空间,底层调用的是C的free(ps)
使用delete释放空间时遵循层次释放,如果对象里存在指向其他对象的指针(甚至多层嵌套),那么delete必须从最里层开始调,逐级释放内存。
五、VC当中的内存分配(video8)
假设我们要new一个Complex对象,该对象大小为8bytes。在Debug和Release模式下,内存分配是不同的。
注:仅限new的情况下。
Debug(左)Release(右)模式下:
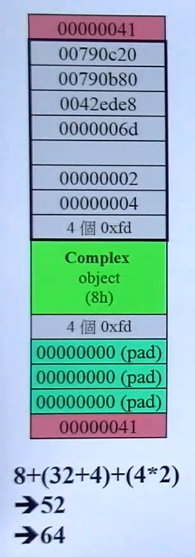
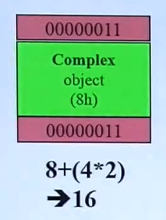
浅绿色:Complex对象所占实际空间,大小为8bytes。
上下砖红色:各4bytes,一共8bytes。是cookie,用来保存总分配内存大小,以及标志是给出去还是收回来。例如00000041,该数为16进制,4表示64,即总分配内存大小为64,1表示给出去(0表示收回来)。
灰色:Debug模式下使用的额外空间,前面32bytes,后面1bytes,一共36bytes。
深绿色:内存分配大小必须是16的倍数(这样砖红色部分里的数字最后都是0,可以用来借位表示给出去还是收回来),所以用了12byte的填充(padding)。
同样,String对象的空间分配,如图:(左Debug,右Release)


六、数组的内存分配(video8)
//使用new分配数组空间 char * m_data = new char[strlen(cstr) + 1]; //使用delete[]来释放数据空间 delete[] m_data;
对数组的空间分配,new叫做Array new,delete[]叫做Array delete。这两个要搭配使用,否则会出错。
注:仅限new的情况下。
Debug(左)Release(右)模式下,数组空间的分配:
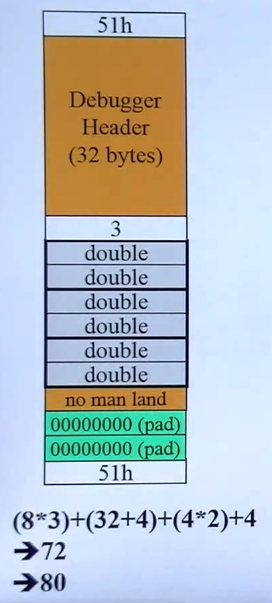

灰色:即3个Complex对象的大小,每个是8bytes,一共24bytes。
深绿色:填充为16的倍数。
前后白色:51表示80bytes,“给出去”。
黄色:Debug模式额外占用空间。
中间白色:用一个整数表示数组中对象个数。
Array new必须搭配Array delete使用,不然会有以下后果(内存泄漏):

使用Array delete,操作系统才知道,我要释放的是一个数组,那么会根据数组中元素的个数分别调用元素对象的析构函数,确保所有元素对象内部所指向的内存空间完全释放。然后再通过free来释放数组本身。
七、static静态关键字(video10)
前面所实例中,没有涉及static关键字。对象的属性会存放在每个对象相应的位置,也就是说,有几个对象,数据就有几份。但是类中的成员方法只有一份,那么不同的对象在调用一个成员方法的时候,是通过以下步骤来分别处理自己的数据的:
Complex c1, c2, c3; //c1,c2,c3分别调用real()来返回实部的值 cout << c1.real() << endl; cout << c2.real() << endl; cout << c3.real() << endl;
相当于以下伪代码:
Complex c1, c2, c3; cout << Complex::real(&c1); //this == &c1 cout << Complex::real(&c2); //this == &c2 cout << Complex::real(&c3); //this == &c3
即,谁调用real()成员方法,谁就是this指针指向的对象。以此来分别处理自己的数据。
当成员属性或成员方法前面加上static关键字,那么该属性或方法就和对象脱离了。
静态属性和一般的成员属性不同,一般的成员属性是每个对象各有一份,而静态数据一共只有一份,例如一个类叫账户,有100W个人来开户,每个人是一个账户对象,里面的金额等是普通属性,每个账户中都有这个属性。但是利率则应该是静态属性,全局只有一份,因为每个人的存款利率应该是一致的。
静态方法和一般成员方法是一样的,也只有一份。但是静态方法的不同点是,静态方法没有this指针。静态方法只能操作静态属性。
class Account{ public: //m_rate的声明 static double m_rate; static void set_rate(const double r) { m_rate = r; } }; //m_rate的定义 double Account::m_rate = 0.89;
使用:
//第一种调用方式,使用类名直接调用 cout << Account::m_rate << endl; //第二种调用方式,使用对象来调用 Account a; a.set_rate(0.50); cout << a.m_rate << endl;
八、利用static实现单例模式(Singleton)(video10)
class A { public: //对外接口,获取实例(该实例是唯一的) static A& getInstance(); //任意函数,供单例对象调用 void setup() { cout << "here is A.setup" << endl; } private: //构造函数放在private下,外部无法直接使用构造函数实例化对象 A(){} //用于保存那唯一的一份对象 static A a; }; A& A::getInstance() { //第一次调用时,产生静态的成员属性A a static A a; //返回 return a; }
使用:
A& p = A::getInstance();
p.setup();
九、模板(video10)
类模板:
//创建模板T template<typename T> class Complex { public: Complex(T r=0,T i=0):re(r),im(i){} Complex& operator += (const Complex&); T real() const { return re; } T imag() const { return im; } private: T re; T im; friend Complex& __doapl(Complex*, const Complex&); };
使用:
{ //当使用double类型时,编译器会将Complex类定义中的T全部替换为double,产生一份代码 Complex<double> c1(1.0, 2.2); //当使用int时,全部替换为int,又产生一份代码 Complex<int> c2(4, 5); }
但是,为不同的类型产生不同的代码是必要的,并不是缺点。因为如果手工去按类型定义类的话,同样是多份代码。
函数模板:
当我们设计一个函数可以对多种类型的数据使用时,例如:
template<class T> inline T& min(T& a,T& b){ return a < b ? a : b; }
函数模板在调用时无需使用<type>来指定,因为要使用函数模板,一定是调用函数,那么就会传实参,编译器就会进行实参推导。
函数模板和类模板是相同的,template中使用的typename和class也是相通的,可以替换使用。
十、命名空间namespace(video10)
namespace主要用来解决对人协调工作时的命名冲突问题。相当于把自己的代码包装一层,别人使用的时候可以以以下三种方式使用,我们以std为例:
//将命名空间std全部打开 using namespace std; int main() { //直接使用其中的方法 cin << ...; cout << ...; }
//按需打开,指定拿出的方法 using std::cout; int main() { //未指定的需要使用std::来使用 std::cin << ...; cout << ...; }
//完全使用std::func_name来使用 int main() { std::cin << ...; std::cout << ...; }
如何创建namespace:
//直接将代码包含在namespace leo内部 namespace leo { class Account { public: //m_rate的声明 static double m_rate; static void set_rate(const double r) { m_rate = r; } }; //m_rate的定义 double Account::m_rate = 0.89; }
面向对象编程、面向对象设计
类与类之间的三种关系:复合、集成、委托。
十一、复合Composition(video11)
复合表示has-a。即A类里有B类的对象(非指针)。
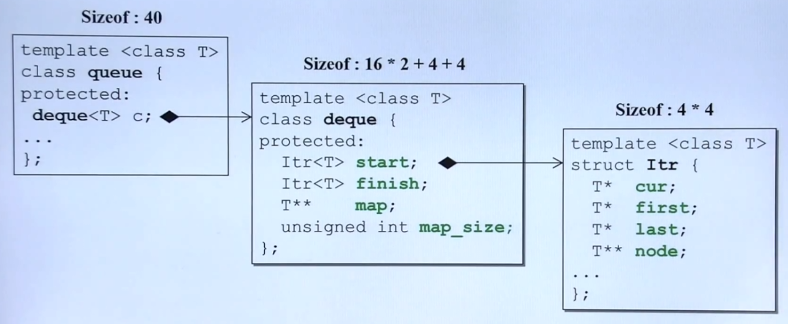
复合的图形表示,及构造和析构顺序:

如下代码所示:
class Person { public: Person() { printf("Class Person 构造\n"); } ~Person() { printf("Class Person 析构\n"); } void say() { printf("Hello"); } }; class Family { public: Family() { printf("Class Family 构造\n"); } ~Family() { printf("Class Family 析构\n"); } Person& getPerson() { return p; } private: //Family中存在Person对象p Person p; };
Family类中,存在一个Person对象。那么在初始化Family对象的时候,会根据上图里的先后顺序来构建对象。
void test() { Family f; } int main() { test(); return 0; }
打印的内容:
Class Person 构造
Class Family 构造
Class Family 析构
Class Person 析构
所以,我们可以看出,在定义Family对象f时,先调用的是Person的构造函数,然后再调用Family的构造函数,是一个由内而外的过程。
而在test()函数结束时,f对象的生命周期完结,是先调用了Family的析构函数,然后再调用Person的析构函数,是一个由外而内的过程。
十二、委托Delegation(video11)
委托表示A类里有B类的对象的指针。委托也可以叫 “ 基于引用的复合(Composition by reference)”。
当A拥有B对象的指针,那么在任何时间都可以通过指针来调用B对象做事情,所以叫做委托。
设计模式:Handle/Body
委托可以引申出一种非常出名的设计模式,叫Handle/Body,或叫Pointer to Implementation。即A为对外接口,B为具体实现,A中接口的操作全部调用B来完成,这样的好处就是A可以一直不变,B可以随意改变,甚至可以有多个不同的B实现方式。
委托的图形表示为:

一个典型的例子:
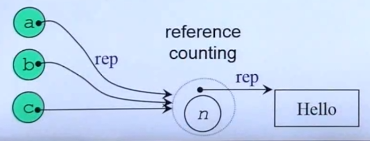
上图中有abc三个A类(假设是String类)的对象,三个对象中的rep指针可以指向同一个B对象(实际存放字符串的类对象),假设abc是互相复制得来的,那么abc中存放的字符串应该是一样的,那么我们就可以在B中实现reference counting,即引用计数,只需要一个B对象,就可以支撑abc三个A的对象,但前提是都不对字符串内容给进行修改。这样就可以节省内存空间。
当其中一个对象,例如a,要对字符串进行修改,那么可以单独再创建一个B对象给a单独修改,然后先前的B对象就从abc三个对象共享变为bc两个对象共享。这种操作叫做“Copy on write”。
十三、继承Inheritance(video11)
继承的图形表示为:(T表示使用了模板,未使用则去掉T)
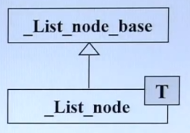
继承(public继承)传达的逻辑是is-a,表示“是一种”。例如B继承A,则说明B是A的一种。
代码如下:
struct _List_node_base { _List_node_base* _M_next; _List_node_base* _M_prev; }; template<typename _Tp> //_List_node继承_List_node_base(public方式继承) struct _List_node : public _List_node_base { _Tp _M_data };
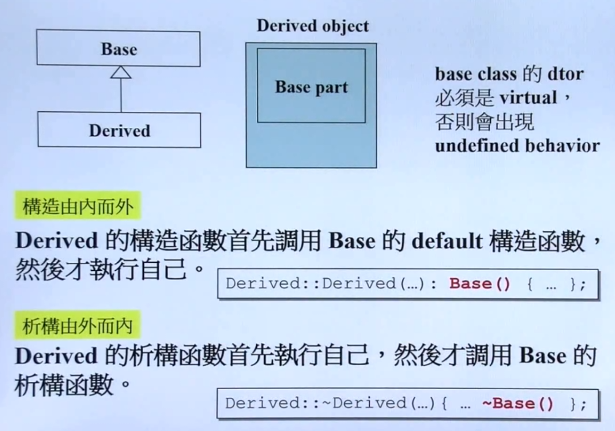
继承,相当于子类中包含了父类的成分(具体包含了多少,主要看继承的方式,public、protected、private)。
class Female { public: Female() { printf("Class Female 构造\n"); } ~Female() { printf("Class Female 析构\n"); } }; class Girl : public Female { public: Girl() { printf("Class Girl 构造\n"); } ~Girl() { printf("Class Girl 析构\n"); } };
void test() { Girl(); } int main() { test(); return 0; }
打印结果:
Class Female 构造
Class Girl 构造
Class Girl 析构
Class Female 析构
在构建子类对象时,要先构建其内部的父类成分,所以要先调用父类的default构造函数,再调用自己的构造函数,由内而外。
在销毁子类对象时,要先析构自己,再析构父类对象,由外而内。
注意:父类的析构函数必须是virtual的。否则会出现undefined behavior。所以,在设计类的时候,如果一个类设计为父类,则析构函数就设计为虚拟函数,或者一个类以后有可能成为父类,那么也可以设计为虚拟析构函数。
十四、虚函数 Virtual function(video12)
子类继承父类的时候,在public继承方式下,子类继承了所有父类的数据(成员属性),而且还继承了所有父类的函数调用权(只是调用的权利,函数还是只有父类的那一份)。
父类方法分为三类:
1.non-virtual函数:不希望子类(派生类derived class)重新定义(override,覆盖)它。override这个概念不能乱用,只有当子类重新定义基类同名虚函数时,才叫override。
2.virtual函数:希望派生类去重新定义这个函数,而且已经对其有一个默认定义(默认实现)。
3.pure virtual函数:希望派生类一定要重新定义这个函数,因为现在完全没有定义它(无默认定义)。
class Shape { public: //纯虚函数,用virtual function = 0的形式 virtual void drow() const = 0; //虚函数,应该有定义(可以是inline的,也可以在外部定义) virtual void error(const std::string& msg); //非虚函数,即普通函数 int objectID() const; //Todo... }; inline void Shape::error(const std::string& msg) { cout << msg << endl; } inline int Shape::objectID() const { printf("Function objectID\n"); return 0; } //定义一个长方形类,public继承Shape class Rectangle :public Shape { public: Rectangle() {} //实现drow(),这是必须实现的 void drow() const { printf("Rectangle Drow\n"); } //override error(),实现子类的个性化操作 void error(const string& msg) { cout << "Rect " << msg << endl; } };
其中Shape类不能直接实例化对象,因为其中包含drow()方法,这是一个纯虚函数,必须由子类来override。
所以我们要使用这个类的话,只能创建一个子类来继承他,然后覆写(override)他的所有纯虚方法,一般的虚函数(非纯虚)可以根据需求决定是否覆盖。
十五*、overload override overwrite的区别(video12)
参考来自:https://www.cnblogs.com/kuliuheng/p/4107012.html 感谢VictoKu
1. Overload(重载)
重载的概念最好理解,在同一个类声明范围中,定义了多个名称完全相同、参数(类型或者个数)不相同的函数,就称之为Overload(重载)。重载的特征如下:
(1)相同的范围(在同一个类中);
(2)函数名字相同;
(3)参数不同;
(4)virtual 关键字可有可无。
2. Override(覆盖)
覆盖的概念其实是用来实现C++多态性的,即子类重新改写父类声明为virtual的函数。Override(覆盖)的特征如下:
(1)不同的范围(分别位于派生类与基类);
(2)函数名字相同;
(3)参数列表完全相同;
(4)基类函数必须有virtual 关键字。
3. Overwrite(改写)
改写是指派生类的函数屏蔽(或者称之为“隐藏”)了与其同名的基类函数。正是这个C++的隐藏规则使得问题的复杂性陡然增加,这里面分为两种情况讨论:
(1)如果派生类的函数与基类的函数同名,但是参数不同。那么此时,不论有无virtual关键字,基类的函数将被隐藏(注意别与重载混淆)。
(2)如果派生类的函数与基类的函数同名,并且参数也相同,但是基类函数没有virtual关键字。那么此时,基类的函数被隐藏(注意别与覆盖混淆)。
十六*、设计模式Template Method(video12)
用虚函数和继承,实现一个非常有名的设计模式,叫Template Method。
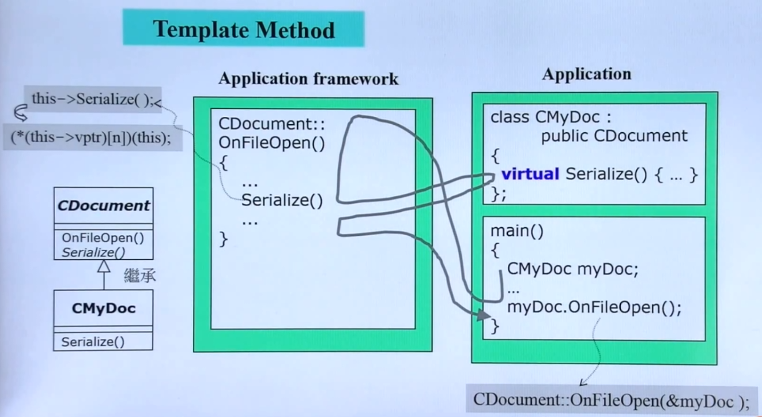
假设,我们要打开文件,并读取里面的内容,那么对于不同的文件,我们其实有很多步骤是相同的,例如找到文件目录,选中文件,打开文件,关闭文件等。但是可能我们有一个动作可能是各不相同的,例如读取其中的内容(各种文件内容格式不同,需要的处理也不同)。那么我们可以以下图中的做法:
步骤:
1.在父类CDocument中,实现共同的方法,例如OpenFile、CloseFile等。
2.CDocument中,将读文件内容的方法Serialize设计为虚函数或纯虚函数。
3.CMyDoc继承CDocument,实现Serialize()。
4.使用子类CMyDoc调用父类方法OnFileOpen(),按图中灰色曲线的顺序来调用内部函数。
这样就实现了关键功能的延迟实现,对于做应用架构(Application framework)的人来说,可以在1年前写好CDocument类,将这个架构卖给其他人,然后再由购买方自己来实现CMyDoc类。这就是典型的Template Method。
为什么会有灰色曲线的调用过程:
1.当子类myDoc调用OnFileOpen()的时候,实际上对于编译器是CDocument::OnFileOpen(&myDoc);因为谁调用,this指针就指向谁,所以调用这个函数,myDoc的地址被传进去了。
2.当OnFileOpen()函数运行到Serilize()的时候,实际上是运行的this->Serialize();由于this指向的是myDoc,所以调用的是子类的Serilize()函数。
代码示例:
class CDocument { public: void OnFileOpen() { cout << "dialog..." << endl; cout << "check file status..." << endl; cout << "open file..." << endl; Serialize(); cout << "close file..." << endl; cout << "update status..." << endl; } //父类的虚函数,当然这里是纯虚函数也是可以的,virtual void Serialize() = 0 virtual void Serialize() {} }; class CMyDoc :public CDocument { public: //这里实现了父类的虚函数Serialize() virtual void Serialize() { cout << "MyDoc Serialize..." << endl; } };
调用:
#include "CDocument.h" int main() { CMyDoc mc; mc.OnFileOpen(); return 0; }
输出:
dialog...
check file status...
open file...
MyDoc Serialize...
close file...
update status...
十七*、继承+委托的模式(video12)
假设我们要做一个类似PPT的多窗口功能,即多个窗口观察同一份数据,例如多窗口画图。也可以是不同类型的窗口(例如,数字、图标、饼图、直方图等)来观察同一份数据。
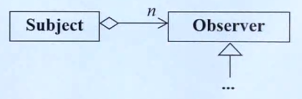
我们的数据设计在类Subject中,窗口(观察者)设计为Observer,这是一个父类,可以被继承(即可以支持派生出不同类型的观察者)。
用如下代码来实现:
//数据类 class Subject { private: int m_value; //保存观察者指针(相当于开的窗口指针) vector<Observer*> m_views; public: //添加观察者 void attach(Observer* obs) { m_views.push_back(obs); } void set_value(int value) { m_value = value; notify(); } void notify() { //通知所有的观察者,数据有更新 for (int i = 0;i < m_views.size();++i) { m_views[i]->update(this, m_value); } } }; //观察者基类 class Observer { public: //纯虚函数,提供给不同的实际观察者类来实现不同的特性 virtual void update(Subject*, int value) = 0; };
用图形来描述:
十八*、Composite设计模式(组合模式)(video13)
虽然文件夹和文件是不同的对象,但是他们都可以被放入到文件夹里,所以一定意义上,文件夹和文件又可以看作是同一种类型的对象,所以我们可以把文件夹和文件统称为目录条目(directory entry)。在这个视角下,文件和文件夹是同一种对象。
所以,我们可以将文件夹和文件都看作是目录的条目,将容器和内容作为同一种东西看待,可以方便我们递归的处理问题,在容器中既可以放入容器,又可以放入内容,然后在小容器中,又可以继续放入容器和内容,这样就构成了容器结构和递归结构。
这就引出了composite模式,也就是组合模式,组合模式就是用于创造出这样的容器结构的。是容器和内容具有一致性,可以进行递归操作。
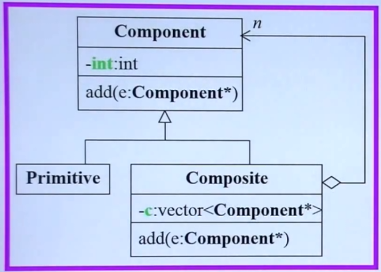
图中Primitive代表基本的东西,即文件。Composite代表合成物,即文件夹。Component表示目录条目。
Primitive和Composite都是一种Component,而Composite中可以存放其他的Composite和Primitive,所以Composite中的Vector存放的类型时Component指针,也就包含了Primitive和Composite两种对象的指针。
代码框架如下:
//一个比较抽象的类,相当于目录条目 class Component { int value; public: Component(int val) :value(val){} virtual void add(Component*) {} }; //相当于 文件类 class Primitive { public: Primitive(int val):Component(val){} }; //相当于 文件夹类 class Composite { vector<Component*> c; public: Composite(int val) :Component(val){} void add(Component* elem) { c.push_back(elem); } };
具体关于文件文件夹实例可以参照:https://www.jianshu.com/p/685dd6299d96 感谢:六尺帐篷
十九*、Prototype模式 原型模式(video13)
设计应用架构时,并不知道以后实现的子类名称,但有要提供给Client调用子类的功能怎么办?
例如十年前设计的架构,子类在十年后继承父类并实现功能。Client只能调用架构中的父类,如何通过父类调用到不知道名字的子类对象。使用Prototype模式:
#include <iostream> #include <vector> using namespace std; //可能是十年前写的框架,我们不知道子类的名字,但又希望通过该基类来产生子类对象 class Prototype { //用于保存子类对象的指针(让子类自己上报) static vector<Prototype *> vec; public: //纯虚函数clone,让以后继承的子类来实现,也是获取子类对象的关键 virtual Prototype* clone() = 0; //子类上报自己模板用的方法 static void addPrototype(Prototype* se) { vec.push_back(se); } //利用该基类在vec中查找子类模板,并且通过模板来克隆更多的子类对象 static Prototype* findAndClone(int idx) { return vec[idx]->clone(); } //子类实现自己操作的函数,hello()只是个例子 virtual void hello() const = 0; }; //定义静态vector,很重要,class定义中只是声明 vector<Prototype *> Prototype::vec; //十年后实现的子类,继承了Prototype class ConcreatePrototype : public Prototype{ public: //用于在Prototype.findAndClone()中克隆子类对象用 Prototype * clone() { //使用另一个构造函数,为了区分创建静态对象的构造函数,添加了一个无用的int参数 return new ConcreatePrototype(1); } //子类实现的具体操作 void hello() const { cout << "hello" << endl; } private: //静态属性,自己创建自己,并上报给父类Prototype static ConcreatePrototype se; //上报静态属性给父类 ConcreatePrototype() { addPrototype(this); } //clone时用的构造方法,参数a无用,只是用来区分两个构造方法 ConcreatePrototype(int a) {} }; //定义静态属性,很重要,有了这句,才会创建静态子类对象se ConcreatePrototype ConcreatePrototype::se;
步骤:
1.子类继承Prototype父类,定义静态属性的时候,自己创建一个自己的对象,此时调用的是无参数的构造函数。并将创建好的自己的指针通过addPrototype(this)上传给基类的vector容器保存。
2.基类定义好的纯虚函数clone(),由子类实现,并在其中通过另一个构造函数产生对象并返回。
3.在Client端,使用基类的findAndClone(),获取vector中的子类对象模板的指针,来调用子类对象的clone功能,返回一个新的子类对象,调用多次则可创建多个对象供用户使用。
4.创建出的子类对象可以调用在子类中实现的hello()方法,进行想要的操作。
Prototype* p = Prototype::findAndClone(0); p->hello();

