[Python自学] day-12 (Mysql、事务、索引、ORM)
一、Mysql数据库
1.Mysql概述
1)Mysql中的一些概念
- RDBMS:关系型数据库管理系统。Mysql是一种RDBMS。
Oracle:收费
Mysql:Oracle旗下免费
Sqlserver:微软
DB2:IBM
Postgresql
Sqlite:轻量级
access:轻量级
- 数据库:数据库是一些关联表的集合。
- 数据表:表述数据的矩阵。看起来像一个简单的电子表格(Excel)。
- 列:一列包含了相同类型的数据,例如电话号码,名称等。
- 行:一行表示一组相关的数据,例如一个用户的相关信息,名称、年龄、性别、电话等。
- 冗余:在查询表时,经常跨表关联查询效率会比较低,例如学生表和学院表,学生的属性中如果只保存学院的ID,那么想查询学生属于哪个学院,就需要关联两张表进行查询,如果想要提高效率,就可以在学生表中添加一个冗余字段dept_name,以后在查询时就只需要查询学生表即可。
- 主键:主键是唯一的(不重复的)。一个数据表只能有一个主键。可以使用主键来查询数据。
- 外键:外键用来关联两个表。(效率比较低)
- 复合键:复合键(组合键)将多个列作为一个索引建,一般用于符合索引。
- 索引:使用索引可以快速访问数据库表中的特定信息。索引是对数据库中一列或多列的值进行排序的一种结构,类似于书籍的目录。数据库中的索引是用的B+树查找。
- 参照完整性:参照的完整性要求关系中不允许引用不存在的实体。与实体完整性是关系模型必须满足的完整性约束条件,目的是保证数据的一致性。例如某表某列只有值1、2、3,我们在另外一个表不能引用4、5、6这些不存在的值。
2)Mysql数据库的优势
- Mysql是最流行的关系型数据库管理系统,在WEB应用方面Mysql是最好用的软件之一。由瑞典MySQL AB公司开发,被Oracle收购。
- Mysql是开源的,免费的。
- Mysql使用标准的SQL数据语言形式。
- Mysql可以允许安装在多种系统上,并且支持多种语言。例如C语言、C++、Python、Java、Perl、PHP、Ruby、Tcl等。
- Mysql支持大型数据库,支持5000万条记录的数据仓库,32位系统表文件最大4GB,64位系统支持最大的表文件为8TB。
- Mysql可以定制,采用GPL协议,可以修改源码来开发自己的Mysql系统。
3)Mysql的大小写
Mysql默认不区分表名大小写,即对表名大小写不敏感。与配置文件中的lower_case_table_names有关:
lower_case_table_names = 0 : 敏感,区分大小写
lower_case_table_names = 1 : 不敏感,不区分大小写
2.Mysql安装
1)Linux下安装
- 使用yum install mariadb-server -y安装,或者下载rpm包,使用rpm -ivh xxx.rpm安装。
- 启动服务systemctl start mariadb.service
- 设置开机启动systemctl enable mariadb.service
注:Mariadb是mysql的一个分支版本。效率比普通的mysql高,是mysql之父在Orable收购mysql后,从新发布的一个新的版本,除了名字不一样,使用端口等都是一样的。
2)Windows下安装
下载exe,双击安装
3.Mysql使用
1)登录mysql
刚安装好的Mysql,使用 mysql -uroot -p 来登录,默认没有密码。
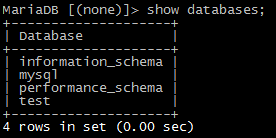
2)查看数据库列表
show databases;
3)进入某个数据库
use mysql;
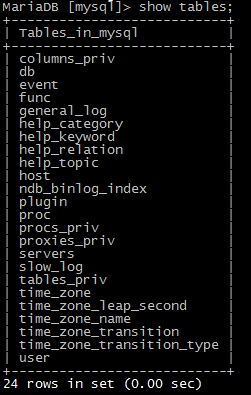
4)查看数据库中的表
show tables;
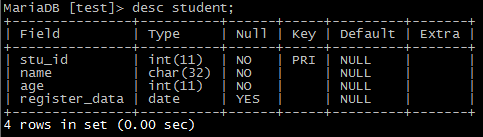
5)查看某个表的结构
desc user;
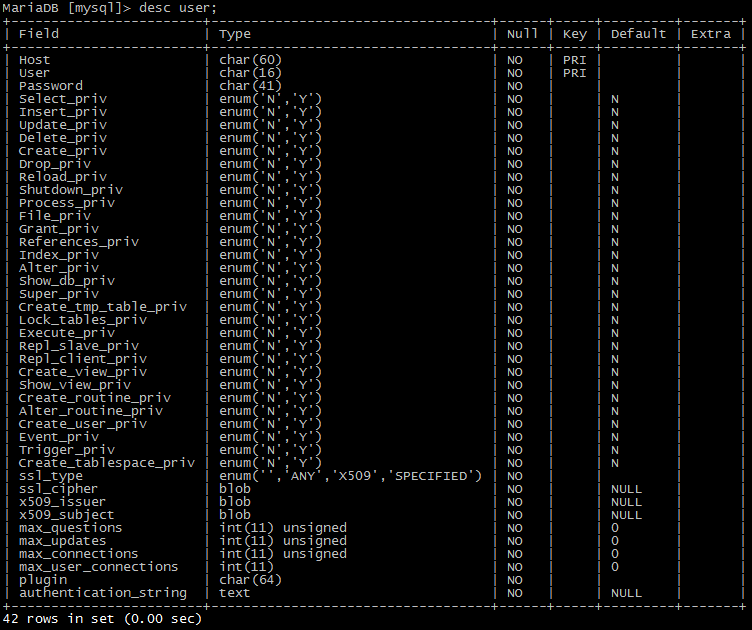
上图字段描述:
Field:表示一个字段(一列)。
Type:表示存放数据的类型。
NULL:是否允许为空。
KEY:键类型,主键、外键等。如果出现多个主键,说明是复合键。
DEFAULT:默认值。
Extra:额外的一些信息。
6)查看某个表里的所有内容
select * from user;
注:如果在命令行中由于数据太多显示不正常,可以使用select * from user\G来让数据可读(格式化)。
7)创建Mysql密码
- 无密码进入mysql数据库
- 执行update mysql.user set password=password('hanxinda123') where user='root';
- 执行flush privileges;
注:flush privileges;的作用是,将当前user和privilige表中的用户信息/权限设置从mysql库(MySQL数据库的内置库)中提取到内存里。MySQL用户数据和权限有修改后,希望在"不重启MySQL服务"的情况下直接生效,那么就需要执行这个命令。
8)创建用户并授权
grant all on test.* to 'leo'@'%' identified by 'hanxinda123';
grant all on test.* to 'leo'@'localhost' identified by 'hanxinda123'; #让用户可以在本机登录
all:表示所有权限,其中包含select,insert,update,delete,create,drop。
test.*:表示test数据库中的所有的表。
'leo'@'%':表示用户leo从除了localhost以外的所有主机登录。想在本机登录,补充执行'leo'@'localhost'
identified by:指定用户密码。
9)查看用户权限
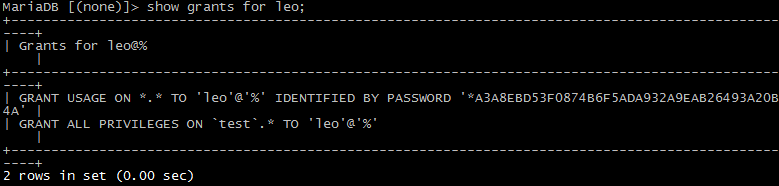
show grants for leo;
10)mysql配置文件
配置文件/etc/my.cnf,用于配置mysql的一些路径,日志存放位置等,一般不用修改。
4.Mysql支持的引擎
1)查看引擎信息
使用以下命令查询支持的数据库引擎:
show engines;
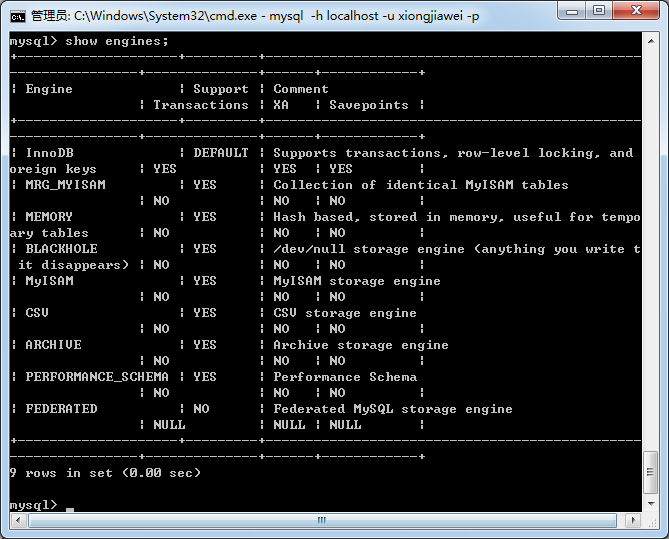
查看当前数据库使用的默认引擎:
SHOW VARIABLES LIKE 'storage_engine';
2)几种引擎的介绍
在MySQL中,不需要在整个服务器中使用同一种存储引擎,针对具体的要求,可以对每一个表使用不同的存储引擎。
InnoDB:
InnoDB是事务型数据库的首选引擎,支持事务安全表(ACID),支持行锁定和外键,上图也看到了,InnoDB是默认的MySQL引擎。
MyISAM:
MyISAM基于ISAM存储引擎,并对其进行扩展。它是在Web、数据仓储和其他应用环境下最常使用的存储引擎之一。MyISAM拥有较高的插入、查询速度,但不支持事物。
几种数据库引擎对比:
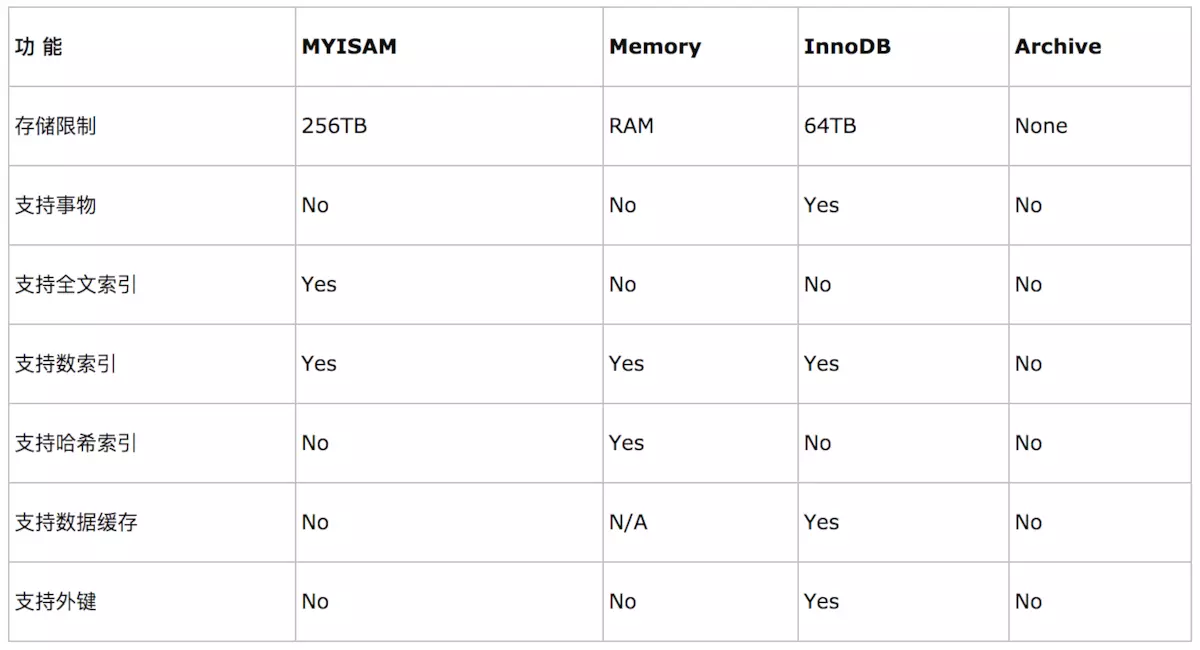
总结:
如果要提供提交、回滚、崩溃恢复能力的事物安全(ACID兼容)能力,并要求实现并发控制,InnoDB是一个好的选择。
如果数据表主要用来插入和查询记录,则MyISAM引擎能提供较高的处理效率。
如果只是临时存放数据,数据量不大,并且不需要较高的数据安全性,可以选择将数据保存在内存中的Memory引擎,MySQL中使用该引擎作为临时表,存放查询的中间结果。
如果只有INSERT和SELECT操作,可以选择Archive,Archive支持高并发的插入操作,但是本身不是事务安全的。Archive非常适合存储归档数据,如记录日志信息可以使用Archive。
Mysql各引擎的详细信息,参考:https://www.jianshu.com/p/4bb9f78b4f6d
5.Mysql管理命令
1)常用管理Mysql的命令
use db_name; 切换数据库
show databases; 查看所有数据库
show tables; 查看数据库中的所有表
show columns from table_name; 同desc table_name;
create database db_name charset utf8; 创建一个数据库,支持中文。默认的charset是latin1,只支持拉丁语类。
drop database db_name; 删除数据库。
show index from table_name; 显示某个表的详细索引信息,包含主键。
2)常用数据类型
int,varchar等
3)创建表
create table table_name (column_name column_type);
例如:
create table student( stu_id int not null auto_increment, name char(32) not null, age int not null, register_date data, primary key (stu_id) )
primary key (stu_id) 将stu_id设置为主键后,stu_id就变为不能重复的了。复合主键使用primary key (stu_id,name)
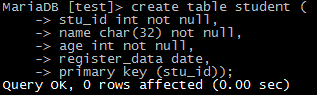
4)插入数据
insert into table_name (field1, field2,...,fieldn) values (value1, value2, ...,valuen);
例如:
insert into student (name, age, register_date) values ('leo', 23, '2019-01-22')
5)查询数据
select * from table_name; --查询表中所有数据。 select field1,field2,...,fieldn from table_name; --查询其中部分列。 select * from table_name where age>20; --按条件过滤查询。 select * from table_name where register_date like "2019-01%"; --使用like模糊查询。
6)更新数据
update table_name set field1=value1,field2=value2 where stu_id=5; --可以同时修改多条数据,可以加过滤条件。
7)删除数据
delete from table_name where name='alex';
8)排序
select * from student order by stu_id asc; --查询结果按stu_id升序排列。 select * from student order by stu_id desc; --查询结果按stu_id降序排列。 --注:默认是升序。
9)分组统计
select name, count(*) from student group by name; --按名称统计表中每个人有多少条数据。
例如:
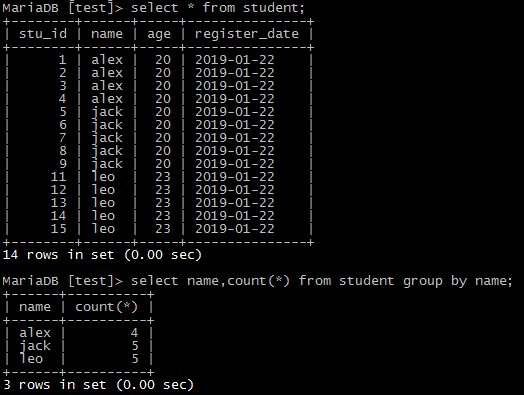
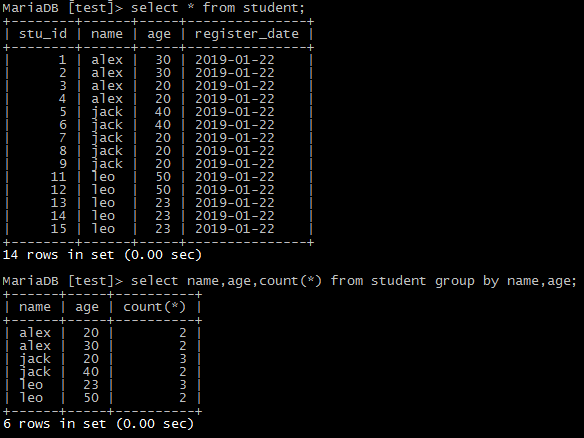
10)按多个字段进行分组统计
select name,age,count(*) from student group by name,age; --按名称统计表中每个人有多少条数据。
11)统计同名人的平均年龄
select name,avg(age) from student group by name;
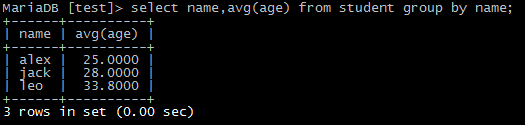
12)统计同名人的年龄综合
select name,sum(age) from student group by name;
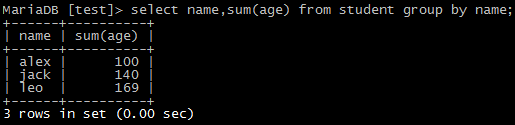
13)可以再加上一个总数(类似总计)
select name,sum(age) from student group by name with rollup;
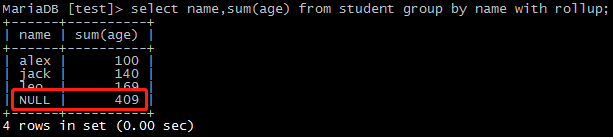
可以给这个NULL取个名字:
select coalesce(name,"TOTAL AGE"),sum(age) from student group by name with rollup;

14)创建外键
创建两个表,一个表为class,一个表为student,class中的cls_id为student中的外键。
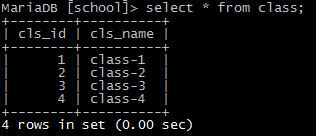
create table student (id int not null, name varchar(20) not null, age int not null, class_id int not null, primary key(id), FOREIGN KEY(class_id) REFERENCES class(cls_id) );
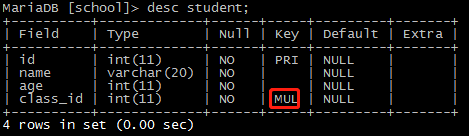
15)ALTER命令
alter table student drop register_date; --删除student表的register_data列。 alter table student add score int not null; --添加一列score。 alter table student modify age char(20) not null; --将age字段的类型修改为char(20)。 alter table student change name english_name varchar(20) not null; --将name字段的名称修改为english_name 类型为varchar(20)。 alter table student modify sex enum("F","M") not null default "F"; --将sex修改为枚举型,只能是F或M,默认F。
6.NULL值的处理
在Mysql中,提供三种对NULL的运算:
- IS NULL:判断为空。
- IS NOT NULL:判断不为空。
- <=>:NULL<=>NULL 返回True。不能使用NULL = NULL来判断(始终返回false)。
7.多表查询
例子:
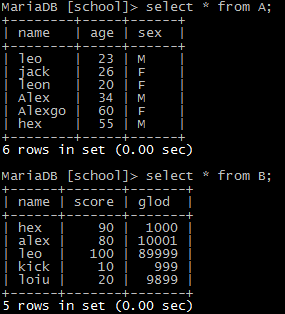
1)内连接(inner join)
按条件查询两个表中共同满足条件的部分结果。(并集)
select * from A inner join B on A.name = B.name;
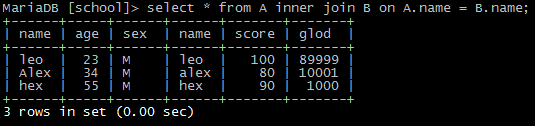
使用 select a.*,b.* from a,b where A.name=B.name; 具有相同效果。
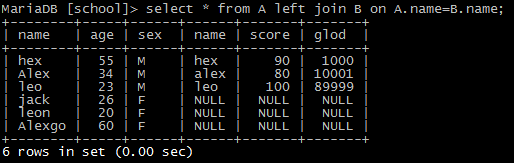
2)左连接(left join)
按A表为基准,结果包含交集部分,也包含其余A的部分。
select * from A left join B on A.name=B.name;
3)右连接(right join)
按B表为基准,结果包含交集部分,也包含其余B的部分。
select * from A right join B on A.name=B.name;
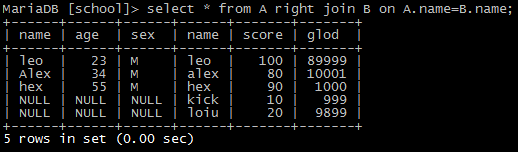
4)全连接(full join)
select * from A full join B on A.name=B.name; --但是mysql并不直接支持这种语法。
使用另一种方式实现:
select * from A left join B on A.name=B.name UNION select * from A right join B on A.name=B.name;
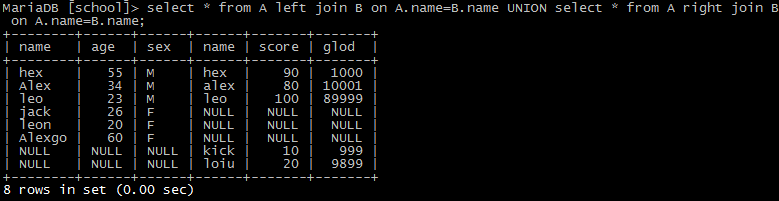
8.事务
1)事务的概念
事务主要用于处理操作量大,复杂度高的数据,比如需要删除一个人员,既需要删除人员基本信息,也需要删除与该人员相关的信息,如邮箱、文章等,这样就构成了一个事务。
- 在Mysql中只有使用了innodb数据库引擎的数据库或表才支持事务。
- 事务用来维护数据库的完整性,保证成批的SQL语句要么全部执行,要不都不执行。
- 事务用来管理insert,update,delete语句。
事务必须满足4个条件(ACID),Atomicity(原子性)、Consistency(稳定性)、Isolation(隔离性)、Durablity(可靠性)。
- 原子性:一组事务,要么成功,要么失败。
- 稳定性:有非法数据,事务撤回。
- 隔离性:事务独立运行,一个事务处理后的结果影响了其他事务,那么其他事务会撤回。事务的100%隔离,需要牺牲速度。
- 可靠性:软、硬件崩溃后,InnoDB数据表驱动会利用日志文件重构修改。可靠性和速度不可兼得,Innodb_flush_log_at_trx_commit选项,决定什么时候把事务保存到日志中。
为了让数据库或表支持事务,我们在创建的时候应该为其指定数据库引擎:
create table 表名( 列名 类型 是否可以为空, 列名 类型 是否可以为空 )ENGINE=InnoDB DEFAULT CHARSET=utf8
2)在Mysql控制台使用事务
begin; -- 事务开始,或使用start transaction; insert into A (name,age,sex) values ('leo', 22, 'M'); -- 插入一条数据 rollback; -- 回滚操作,该事务结束 begin; -- 重新开始另一个事务 insert into A (name,age,sex) values ('leo', 32, 'F'); -- 插入正确的数据 commit; -- 确认无误,提交,事务结束
其中,rollback和commit都代表当前事务结束。
9.索引
1)索引的概念
当我们需要关注某个表其中几列关键信息,我们可以对其添加索引。
索引包含单列索引和组合索引(多列组合形成的)。
索引创建后,应该确保该索引应用在SQL查询语句的条件部分(WHERE子句中的条件)。
实际上,索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录。
2)索引的优点
查询速度很快。使用了索引是兰博基尼的话,没使用索引就是人力三轮车。
3)索引的缺点
索引要避免滥用,虽然索引大大提高了查询速度,同时却降低更新表的速度,如对表进行insert、update和delete。因为更新表时,不仅要保存数据,还要保存一下索引文件。建立索引会占用磁盘空间的索引文件。
4)查看表的索引
show index from table_name;
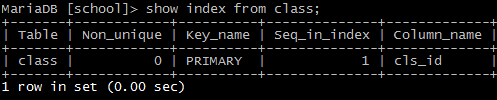
5)创建索引
create index index_name on student(name(20)); --为student表的name字段添加索引。这里的20表示索引长度,即使用name列的前多少个字符创建索引,如果这个length与name定义的长度一致,则使用全量创建索引。例如varchar和char适合使用部分长度来创建索引,可以节省磁盘空间。
6)在创建表的时候添加index
create table mytable ( id int not null primary key, name varchar(20) not null, index index_name (name(20)) );
7)通过修改表结构添加索引
alter mytable add index index_name on (name(20));
8)删除索引
drop index index_name on table_name;
9)唯一索引
与普通索引类似,不同的是,索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。
create UNIQUE index index_name on student(name(20)); --与普通索引相似,只是多了一个UNIQUE关键字。
10.锁
1)如何使用锁
当存在一个表,可能同时有多个连接进来对其进行修改(例如商品现存数量),则可能出现数据不准确的问题(有些线程并未修改成功)。
那么就需要用锁来解决这个问题:
第一个数据库链接开启了一个事务,使用for update进行了加锁:
begin; select * from tb1 for update; --for update就加上了锁 ... update tb1 set name='Leo' where id=2; commit;
在加锁期间(for update --> commit),其他连接进行操作:
--第一种(不加for update) begin; select * from tb1; --会直接返回结果 ... --第二种(使用for update) begin; select * from tb1 for update; --不会返回结果,等待锁释放 ...
当第一个连接执行commit后,锁立即被释放了,此时后面的连接才能获取到数据,并加上自己的锁,这样就能保证所有连接对数据的修改都是正确的。
2)锁的种类
在Mysql中,我们可以使用InnoDB和mysaim数据库引擎,他们虽然都提供锁,但是是有区别的:
-- innodb -- 支持事务 -- 支持锁(行锁、表锁) -- mysaim -- 不支持事务 -- 支持锁(表锁)
3)如何使用行锁
只需要在使用的时候加上行的过滤条件:
begin; select * from tb1 where id=2 for update; --加上了行锁,只对id=2的这行起效,加锁期间,其他连接操作id=2之外的行不受影响 ... commit;
二、python中使用Mysql
1.pymysql连接操作数据库
python2.x库安装:
linux下使用yum安装MySQL-python: yum install MySQL-python -y
或使用pycharm安装MySQL-python
但是MySQL-python,mysqldb在python3.x上不能使用。
python3.x使用pymysql库:
首先在pycharm中安装pymysql库。
pip install pymysql
1)执行查询
import pymysql # 创建连接(socket) conn = pymysql.connect(host='192.168.1.66', port=3306, user='root', passwd='hanxinda123', db='school' ) # 获取游标,类似 "MariaDB [school]>"这个东西 cursor = conn.cursor() # 使用游标来执行SQL effect_row = cursor.execute('select * from class') print(effect_row) # 打印4,说明表class中有4条数据 print(cursor.fetchone()) # 获取一条数据 print(cursor.fetchmany(2)) # 获取前2条数据 print(cursor.fetchall()) # 获取剩下的数据,一条数据只能被获取一次 # 关闭游标和链接 cursor.close() conn.close()
2)commit
如果在execute中运行插入、更新、删除等语句,默认开启事务功能,后面需要执行提交(commit)
一次执行多条SQL:
import pymysql # 创建连接(socket) conn = pymysql.connect(host='192.168.1.66', port=3306, user='root', passwd='hanxinda123', db='school' ) # 获取游标,类似 "MariaDB [school]>"这个东西 cursor = conn.cursor() # 定义多条数据的列表 data = [('class-10', 'leo'), ('class-11', 'jack'), ('class-12', 'lilei') ] # 直接插入多条 effect_row = cursor.executemany('insert into class (cls_name,cls_master_name) values (%s,%s)', data) # 默认是事务模式,需要提交 conn.commit() # 关闭游标和链接 cursor.close() conn.close()
2.DBUtils数据库连接池
为了提高数据库操作的效率,不用每次操作都重新建立连接,可以使用DBUtils连接池。
连接池的意思就是预先建立多个不断开的连接,每次操作数据库的时候就从连接池中获取一个连接,操作完毕后不断开,直接归还到连接池即可。
1)首先安装DBUtils(依赖pymysql)
pip install dbutils
2)DBUtils使用
from DBUtils.PooledDB import PooledDB, SharedDBConnection import pymysql POOL = PooledDB( creator=pymysql, # 使用链接数据库的模块 maxconnections=6, # 连接池允许的最大连接数,0和None表示不限制连接数 mincached=2, # 初始化时,链接池中至少创建的空闲的链接,0表示不创建 maxcached=5, # 链接池中最多闲置的链接,0和None不限制 maxshared=8, # 链接池中最多共享的链接数量,0和None表示全部共享。PS: 无用,因为pymysql和MySQLdb等模块的 threadsafety都为1,所有值无论设置为多少,_maxcached永远为0,所以永远是所有链接都共享。 blocking=True, # 连接池中如果没有可用连接后,是否阻塞等待。True,等待;False,不等待然后报错 maxusage=None, # 一个链接最多被重复使用的次数,None表示无限制 setsession=[], # 开始会话前执行的命令列表。如:["set datestyle to ...", "set time zone ..."] ping=0, # ping MySQL服务端,检查是否服务可用。# 如:0 = None = never, 1 = default = whenever it is requested, 2 = when a cursor is created, 4 = when a query is executed, 7 = always host='127.0.0.1', port=3306, user='root', password='123456', database='pooldb', charset='utf8' ) def func(): # 检测当前正在运行连接数的是否小于最大链接数,如果不小于则:等待或报raise TooManyConnections异常 # 否则 # 则优先去初始化时创建的链接中获取链接 SteadyDBConnection。 # 然后将SteadyDBConnection对象封装到PooledDedicatedDBConnection中并返回。 # 如果最开始创建的链接没有链接,则去创建一个SteadyDBConnection对象,再封装到PooledDedicatedDBConnection中并返回。 # 一旦关闭链接后,连接就返回到连接池让后续线程继续使用。 conn = POOL.connection() cursor = conn.cursor() cursor.execute('select * from tb1') result = cursor.fetchall() conn.close() if __name__ == '__main__': func()
3)如果不使用连接池
如果没有连接池,使用pymysql来连接数据库时,单线程应用完全没有问题,但如果涉及到多线程应用那么就需要加锁,一旦加锁那么连接势必就会排队等待,当请求比较多时,性能就会降低了。
三、ORM
全称是object relational mapping,对象映射关系。简单来说,Python这种面向对象的程序一切皆对象,但是我们使用的数据库确实关系型的,为了保证一致的使用习惯,通过orm将编程语言的对象模型和数据库的关系模型建立映射关系,这样我们在使用变成语言对数据库进行操作的时候可以直接使用编程语言的对象模型就可以了,而不直接使用原生的SQL语句。
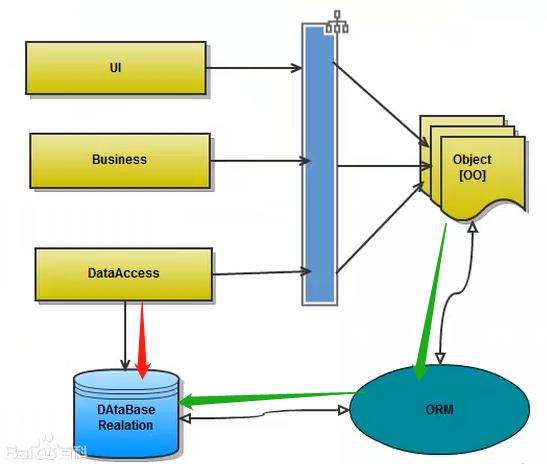
如图所示,传统情况下,我们通过原生SQL直接访问数据库(红色箭头),使用ORM,我们对数据库的操作都采用对象的方式(绿色箭头),由ORM来复制对象模型与SQL之间的转换。
四、SQLAlchemy
/'ælkɪmɪ/ 魔术、点金术
在Python中,最有名的ORM框架是SQLAlchemy。用户包含OpenStack等知名应用和公司。
1.SQLAlchemy安装
在pycharm中安装,或者使用 pip3 install sqlalchemy 在命令行中安装。
2.基本使用
1)创建表
import sqlalchemy from sqlalchemy import create_engine from sqlalchemy import Column, Integer, String from sqlalchemy.ext.declarative import declarative_base # 链接数据库,告诉sqlalchemy engine = create_engine('mysql+pymysql://root:hanxinda123@192.168.1.66/school', encoding='utf-8', echo=True ) Base = declarative_base() class Teacher(Base): __tablename__= 'teacher' id = Column(Integer, primary_key=True) name = Column(String(32)) cls_name = Column(String(32)) Base.metadata.create_all(engine)
其中,create_engine代表链接数据库,参数中的mysql+pymysql表示用的哪种数据库,用的哪种底层库。SQLAlchemy可以支持多种数据库和API库。例如:
Mysql-Python: mysql+mysqldb
pymysql: mysql+pymysql
Mysql-connector: mysql+mysqlconnector
cx_Oracle: oracle+cx_oracle
后面的代表<用户名>:<密码>@<主机名或IP>:[<port>]/<db_name>
echo=True表示打印调试信息,其中包含底层执行的SQL语句等。
2)创建表并插入数据
如果表已经存在,则不会再创建表,但不会报错。
import sqlalchemy from sqlalchemy import create_engine from sqlalchemy import Column, Integer, String from sqlalchemy.ext.declarative import declarative_base from sqlalchemy.orm import sessionmaker # 执行操作需要导入sessionmaker # 链接数据库,告诉sqlalchemy使用哪种数据库和API库,用户、密码、主机、数据库名等。 engine = create_engine('mysql+pymysql://root:hanxinda123@192.168.1.66/school', encoding='utf-8', echo=True ) Base = declarative_base() # 生成ORM基类 class Teacher(Base): __tablename__ = 'teacher' # 表名 id = Column(Integer, primary_key=True) # Integer即int name = Column(String(32)) # String对应sql中的varchar cls_name = Column(String(32)) Base.metadata.create_all(engine) Session_class = sessionmaker(bind=engine) # 创建与数据库的会话的session类,注意是类,不是对象 session = Session_class() # 生成session实例,相当于以前的cursor teacher_obj_1 = Teacher(name='alex', cls_name='class-11') teacher_obj_2 = Teacher(name='jack', cls_name='class-12') print(teacher_obj_1.name, teacher_obj_1.cls_name) # 此时还未创建 session.add(teacher_obj_1) # 将要创建的数据对象添加到session中。 session.add(teacher_obj_2) # 将要创建的数据对象添加到session中。 print(teacher_obj_1.name, teacher_obj_1.cls_name) # 此时还未创建 session.commit() # 统一提交,创建数据
3)查询
from sqlalchemy import create_engine from sqlalchemy import Column, Integer, String from sqlalchemy.ext.declarative import declarative_base from sqlalchemy.orm import sessionmaker # 执行操作需要导入sessionmaker # 链接数据库,告诉sqlalchemy使用哪种数据库和API库,用户、密码、主机、数据库名等。 engine = create_engine('mysql+pymysql://root:hanxinda123@192.168.1.66/school', encoding='utf-8' ) Base = declarative_base() # 生成ORM基类 class Teacher(Base): __tablename__ = 'teacher' # 表名 id = Column(Integer, primary_key=True) # Integer即int name = Column(String(32)) # String对应sql中的varchar cls_name = Column(String(32)) Base.metadata.create_all(engine) Session_class = sessionmaker(bind=engine) # 创建与数据库的会话的session类,注意是类,不是对象 session = Session_class() # 生成session实例,相当于以前的cursor # 取全部数据all() data = session.query(Teacher).filter_by(name='alex').all() for i in data: print(i.name, i.cls_name) # 取第一条数据first() data = session.query(Teacher).filter_by(name='alex').first() print(data.name, data.cls_name) # 条件为大于小于,只能使用filter(),参数必须写Teacher.id而不能直接写id,与filter_by相反 # 判断相等要使用'==',而filter_by使用'='。注意一下 data = session.query(Teacher).filter(Teacher.id > 1).all() for i in data: print(i.name, i.cls_name) # 多条件查询 data = session.query(Teacher).filter(Teacher.id > 1).filter(Teacher.name == 'alex').all() for i in data: print(i.name, i.cls_name)
4)修改
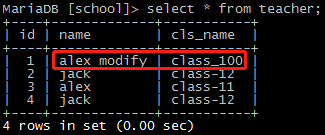
# 取第一条数据first() data = session.query(Teacher).filter_by(name='alex').first() print(data.name, data.cls_name) data.name = 'alex modify' # 直接对数据进行修改 data.cls_name = 'class_100' session.commit() # 提交到数据库
5)回滚
teacher_obj_1 = Teacher(name='hello', cls_name='class-3') session.add(teacher_obj_1) # 将要创建的数据对象添加到session中,实际上数据已经到数据库了,使用sql查询不到,但id已经自增了(相当于这条数据已经占了一个位置) session.rollback() # 回滚 data = session.query(Teacher).filter(Teacher.name == 'hello').all() for i in data: print(i.name, i.cls_name) # 无数据,因为回滚了
6)统计
# 统计 ct = session.query(Teacher).filter(Teacher.name.like('hello%')).count() print(ct)
7)分组
from sqlalchemy import func print(session.query(func.count(Teacher.name), Teacher.name).group_by(Teacher.name).all())
8)连表查询
# 第一种形式 res = session.query(Class, Teacher).filter(Class.cls_id == Teacher.id).all() for i in res: print(i[0].cls_id, i[1].id) # 第二种形式,但这种形式必须存在关联关系(外键),如果没有回报错 res = session.query(Class).join(Teacher).all() for i in res: print(i[0].cls_id, i[1].id)
9)添加外键
from sqlalchemy.orm import relationship from sqlalchemy import ForeignKey # 映射Teacher表 class Teacher(Base): __tablename__ = 'teacher' # 表名 id = Column(Integer, primary_key=True) # Integer即int name = Column(String(32)) # String对应sql中的varchar cls_name = Column(String(32)) # 映射class表 class Class(Base): __tablename__ = 'class' cls_id = Column(Integer, primary_key=True) cls_name = Column(String(20), nullable=False) cls_master_name = Column(String(20), nullable=False) teacher_id = Column(Integer, ForeignKey('teacher.id')) # 创建外键 Base.metadata.create_all(engine)
在创建表时,导入ForeignKey,然后在映射类中添加外键信息。
10)添加表关联关系(这个关系不是在数据库中,是在内存中的关系,relationship)
from sqlalchemy import create_engine from sqlalchemy import Column, Integer, String from sqlalchemy.ext.declarative import declarative_base from sqlalchemy.orm import sessionmaker # 执行操作需要导入sessionmaker from sqlalchemy.orm import relationship from sqlalchemy import ForeignKey # 链接数据库,告诉sqlalchemy使用哪种数据库和API库,用户、密码、主机、数据库名等。 engine = create_engine('mysql+pymysql://root:hanxinda123@192.168.1.66/school', encoding='utf-8' ) Base = declarative_base() # 生成ORM基类 # 映射class表 class Class(Base): __tablename__ = 'class' id = Column(Integer, primary_key=True) name = Column(String(20), nullable=False) # 映射Teacher表 class Teacher(Base): __tablename__ = 'teacher' id = Column(Integer, primary_key=True) name = Column(String(32)) cls_id = Column(Integer, ForeignKey('class.id')) # 创建一个关联关系,可以使用cls来获取对应Class表中的所有数据 # 同时创建反向关系,在Class表中可以使用thr获取Teacher表的全量数据 cls = relationship('Class', backref='thr') Session_class = sessionmaker(bind=engine) # 创建与数据库的会话的session类,注意是类,不是对象 session = Session_class() # 生成session实例,相当于以前的cursor # 必须存在关联关系(外键),如果没有回报错 res = session.query(Teacher).all() for i in res: print(i.id, i.name, i.cls.name)
重要:当一个表中有多个字段的外键都是一个表时,例如teacher的普通班级编号和管理班级编号都用外键关联一个班级表。那么需要在relationship("Class", foreign_keys=[mgmt_cls]) 指定关联关系和哪个外键绑定的。如下代码:
from sqlalchemy import create_engine from sqlalchemy import Column, Integer, String from sqlalchemy.ext.declarative import declarative_base from sqlalchemy.orm import sessionmaker # 执行操作需要导入sessionmaker from sqlalchemy.orm import relationship from sqlalchemy import ForeignKey # 链接数据库,告诉sqlalchemy使用哪种数据库和API库,用户、密码、主机、数据库名等。 engine = create_engine('mysql+pymysql://root:hanxinda123@192.168.1.66/school', encoding='utf-8' ) Base = declarative_base() # 生成ORM基类 # 映射class表 class Class(Base): __tablename__ = 'class' id = Column(Integer, primary_key=True) name = Column(String(20), nullable=False) # 映射Teacher表 class Teacher(Base): __tablename__ = 'teacher' id = Column(Integer, primary_key=True) name = Column(String(32)) cls_id = Column(Integer, ForeignKey('class.id')) mgmt_cls_id = Column(Integer, ForeignKey('class.id')) # 创建一个关联关系,可以使用cls来获取对应Class表中的所有数据 # 同时创建反向关系,在Class表中可以使用thr获取Teacher表的全量数据 cls = relationship('Class', foreign_keys=[cls_id]) mgmt_cls = relationship('Class', foreign_keys=[mgmt_cls_id]) # 创建表 Base.metadata.create_all(engine) Session_class = sessionmaker(bind=engine) # 创建与数据库的会话的session类,注意是类,不是对象 session = Session_class() # 生成session实例,相当于以前的cursor # 必须存在关联关系(外键),如果没有回报错 res = session.query(Teacher).all() for i in res: print(i.id, i.name, i.cls.name, i.mgmt_cls.name)
11)多对多表
例如书和作者的关系,一本书可以有多个作者,而一个作者又可以又多本书。
先创建book表和author表以及中间映射表,并且添加数据:
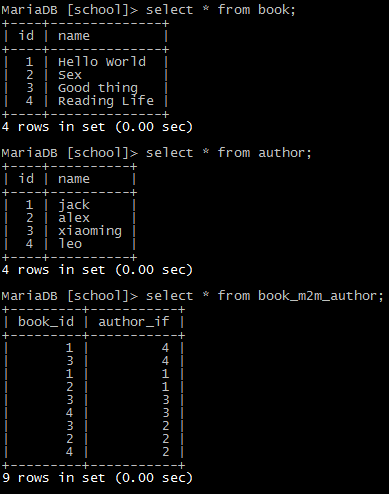
from sqlalchemy import create_engine from sqlalchemy import Column, Integer, String from sqlalchemy.ext.declarative import declarative_base from sqlalchemy.orm import sessionmaker from sqlalchemy.orm import relationship from sqlalchemy import ForeignKey from sqlalchemy import Table engine = create_engine('mysql+pymysql://root:hanxinda123@192.168.1.66/school', encoding='utf-8' ) Base = declarative_base() # 生成ORM基类 # 为什么要以这种方式创建中间表,因为这张表我们不用直接操作,ORM帮我们管理 m2m_table = Table('book_m2m_author', Base.metadata, Column('book_id', Integer, ForeignKey('book.id')), Column('author_if', Integer, ForeignKey('author.id')) ) class Book(Base): __tablename__ = 'book' id = Column(Integer, primary_key=True) name = Column(String(64), nullable=False) # 通过中间表,与author建立关联关系 authors = relationship('Author', secondary=m2m_table, backref='books') class Author(Base): __tablename__ = 'author' id = Column(Integer, primary_key=True) name = Column(String(20), nullable=False) # 创建表 Base.metadata.create_all(engine) Session_class = sessionmaker(bind=engine) # 创建与数据库的会话的session类,注意是类,不是对象 session = Session_class() # 生成session实 b1 = Book(name='Hello World') b2 = Book(name='Good thing') b3 = Book(name='Sex') b4 = Book(name='Reading Life') a1 = Author(name='jack') a2 = Author(name='leo') a3 = Author(name='alex') a4 = Author(name='xiaoming') # 书和作者的关联关系 b1.authors = [a1, a2] b2.authors = [a2, a3, a4] b3.authors = [a1, a3] b4.authors = [a3, a4] session.add_all([b1, b2, b3, b4, a1, a2, a3, a4]) session.commit()
创建结果:
读取结果:
# 通过作者查写了哪些书 author_obj = session.query(Author).filter(Author.name == 'alex').first() for b in author_obj.books: print(author_obj.name, b.name) # 通过书查是哪些作者写的 book_obj = session.query(Book).filter(Book.name == 'Sex').first() for a in book_obj.authors: print(book_obj.name, a.name)
删除关联关系:
# 通过作者查写了哪些书 author_obj = session.query(Author).filter(Author.name == 'alex').first() # 通过书查是哪些作者写的 book_obj = session.query(Book).filter(Book.name == 'Sex').first() # 从Sex这本书的作者中删除alex book_obj.authors.remove(author_obj) session.commit() # 提交
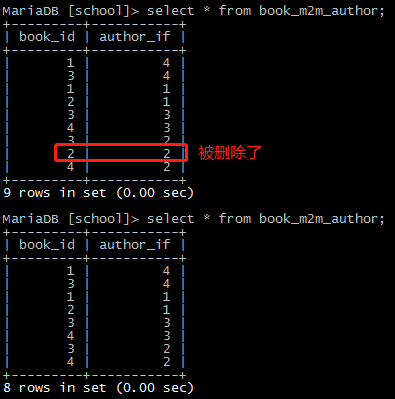
不用关心中间表,ORM会自动修改其中的记录。
12)处理中文的问题
我们在创建连接的时候虽然加上了encoding='utf-8',但是并无效果。
engine = create_engine('mysql+pymysql://root:hanxinda123@192.168.1.66/school', encoding='utf-8')
如何处理呢?
engine = create_engine('mysql+pymysql://root:hanxinda123@192.168.1.66/school?charset=utf8', encoding='utf-8')
即在链接串的最后加上 " ?charset=utf8 "。
##

