
如何在k8s中实现ELK日志统一管理
生产级实战:Kubernetes日志中枢EFK架构落地指南
在日均产生TB级日志的生产环境中,如何快速定位一句"Error 500"就像大海捞针?EFK(Elasticsearch+Fluentd+Kibana)日志体系正是解决这个痛点的黄金组合。本文将手把手带你搭建企业级日志中枢,并揭秘调优秘籍。
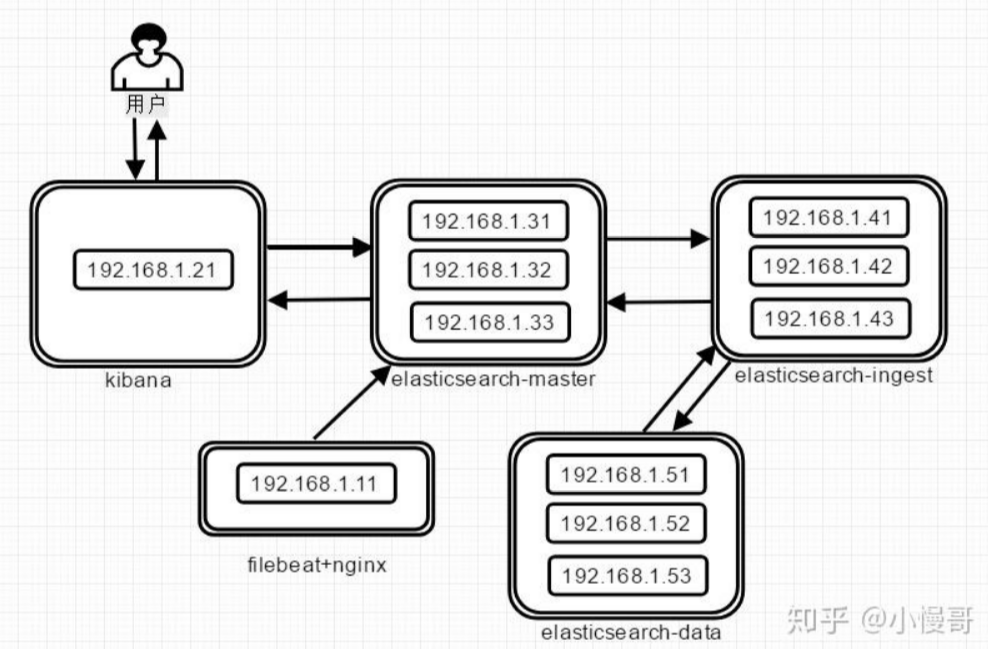
一、EFK组件角色解析
-
Fluentd:日志快递分拣员
- 部署方式:DaemonSet(每个节点1个实例)
- 核心能力:
- 实时采集容器标准输出日志
- 自动附加Kubernetes元数据(Pod名称/Namespace等)
- 支持日志格式转换与过滤
-
Elasticsearch:智能仓储系统
- 推荐架构:3个Master节点 + 5个Data节点
- 关键配置:
# values.yaml(helm部署示例) volumeClaimTemplate: accessModes: [ "ReadWriteOnce" ] storageClassName: "es-storage" resources: requests: storage: 500Gi -
Kibana:数据监控中心
- 典型功能:
- 日志关键字搜索(支持Lucene语法)
- 可视化仪表盘构建
- 告警规则配置(结合Elastic Alerting)
- 典型功能:
二、六步构建坚如磐石的日志体系
步骤1:部署Elasticsearch集群
# 使用Elastic官方Operator部署
kubectl apply -f https://download.elastic.co/downloads/eck/2.8.0/operator.yaml
步骤2:配置Fluentd日志流水线
# fluentd-configmap关键配置
<filter kubernetes.**>
@type record_transformer
enable_ruby true
<record>
pod_owner ${record.dig("kubernetes", "labels", "app")}
log_level ${record["log"].match(/ERROR|WARN|INFO/).to_s}
</record>
</filter>
<match **>
@type elasticsearch
host elasticsearch-master
port 9200
logstash_format true
buffer_chunk_limit 8MB
buffer_queue_limit 4096
</match>
步骤3:Kibana可视化配置
# 创建索引模式
PUT /_index_template/logs-template
{
"index_patterns": ["logs-*"],
"template": {
"mappings": {
"properties": {
"@timestamp": { "type": "date" },
"log_level": { "type": "keyword" }
}
}
}
}
步骤4:日志分级存储实战
# 通过Annotation标记重要日志
apiVersion: v1
kind: Pod
metadata:
annotations:
fluentd.io/exclude: "false"
fluentd.io/tier: "hot"
spec:
containers:
- name: payment-service
步骤5:敏感信息过滤
# 屏蔽信用卡号日志
<filter **>
@type grep
<exclude>
key message
pattern /(\d{4}-){3}\d{4}/
</exclude>
</filter>
步骤6:性能压测与调优
# 模拟日志洪峰
kubectl run log-generator --image=busybox -- sh -c "while true; do echo '压力测试日志...'; done"
三、高级技巧:让日志系统飞起来
-
冷热数据分层架构
hot节点(SSD):存放7天内日志 warm节点(HDD):存放30天内日志 cold节点(对象存储):归档历史日志 -
自动索引生命周期管理
PUT _ilm/policy/logs-policy { "policy": { "phases": { "hot": { "actions": { "rollover": { "max_size": "50GB" } } }, "delete": { "min_age": "30d", "actions": { "delete": {} } } } } } -
多租户隔离方案
# 按namespace创建独立索引
<match kubernetes.**>
@type elasticsearch
index_name logs-${record['kubernetes']['namespace_name']}
---
### 四、生产环境避坑指南
**坑1:日志洪峰导致Fluentd OOM**
- 症状:Fluentd Pod频繁重启
- 解决:
```yaml
resources:
limits:
memory: "2Gi"
requests:
memory: "1Gi"
# 增加磁盘缓存
buffer:
@type file
path /var/log/fluentd/buffer
坑2:Elasticsearch分片雪崩
- 症状:集群状态频繁Yellow/Red
- 黄金法则:
- 分片大小控制在10-50GB
- 每个节点分片数 ≤ 1000
- 定期执行分片均衡:
POST /_cluster/reroute?retry_failed
坑3:Kibana查询超时
- 优化方案:
# 启用字段数据缓存 PUT /_cluster/settings { "persistent": { "indices.breaker.fielddata.limit": "60%" } }
五、可观测性增强方案
-
关键日志告警
# 创建5分钟内ERROR超过100次的告警 POST _alerting/rule { "name": "应用错误告警", "conditions": { "script": "ctx.results[0].hits.total.value > 100" }, "actions": [{ "type": "email", "to": ["sre@example.com"] }] } -
日志关联TraceID
# Python应用示例 import logging from flask import g class TraceFilter(logging.Filter): def filter(self, record): record.trace_id = getattr(g, 'trace_id', 'none') return True logger.addFilter(TraceFilter()) -
成本控制三板斧
- 压缩存储:
PUT /_settings { "index.codec": "best_compression" } - 定期清理:
DELETE /logs-2023* - 采样非关键日志:
@type sample
- 压缩存储:
六、架构师检查清单
部署完成后,通过以下命令验证系统健康度:
# 检查日志采集状态
kubectl logs fluentd-abcde -f
# 查看ES集群状态
curl http://elasticsearch:9200/_cluster/health?pretty
# 测试Kibana查询
GET /logs-*/_search
{
"query": { "match": { "log_level": "ERROR" } }
}
当你的日志系统能满足以下指标,说明已达到生产级要求:
- 日志采集延迟 < 30秒
- 查询响应时间 P99 < 2秒
- 集群恢复时间 < 5分钟(节点故障场景)
- 存储成本下降40%(相比原始日志存储)
通过EFK打造的日志中枢,就像给Kubernetes集群装上了"全天候监控探头"。当你能在30秒内定位到引发凌晨告警的那个异常日志时,就会明白这一切的投入都是值得的。记住,好的日志系统不仅要能"记录历史",更要能"预测未来"。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号