hive复杂类型实战
1、hive 数组简单实践:
CREATE TABLE `emp`(
`name` string,
`emps` array<string>)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://node:9000/user/hive/warehouse/daxin.db/emp'
存入数据,借助insert into ... select :
insert into emp select "daxin",array('zhangsan','lisi','wangwu') from ptab;
hive> select * from emp;
OK
daxin ["zhangsan","lisi","wangwu"]
mali ["jack","lixisan","fala"]
Time taken: 0.045 seconds, Fetched: 2 row(s)
hive>
>
> select * from emp LATERAL VIEW explode(emps) tmp ;
OK
daxin ["zhangsan","lisi","wangwu"] zhangsan
daxin ["zhangsan","lisi","wangwu"] lisi
daxin ["zhangsan","lisi","wangwu"] wangwu
mali ["jack","lixisan","fala"] jack
mali ["jack","lixisan","fala"] lixisan
mali ["jack","lixisan","fala"] fala
Time taken: 0.047 seconds, Fetched: 6 row(s)
hive> select * from emp LATERAL VIEW explode(emps) tmp as empeeName ;
OK
daxin ["zhangsan","lisi","wangwu"] zhangsan
daxin ["zhangsan","lisi","wangwu"] lisi
daxin ["zhangsan","lisi","wangwu"] wangwu
mali ["jack","lixisan","fala"] jack
mali ["jack","lixisan","fala"] lixisan
mali ["jack","lixisan","fala"] fala
Time taken: 0.038 seconds, Fetched: 6 row(s)
hive>
> set hive.cli.print.header=true;
hive> select * from emp LATERAL VIEW explode(emps) tmp as empeeName ;
OK
emp.name emp.emps tmp.empeename
daxin ["zhangsan","lisi","wangwu"] zhangsan
daxin ["zhangsan","lisi","wangwu"] lisi
daxin ["zhangsan","lisi","wangwu"] wangwu
mali ["jack","lixisan","fala"] jack
mali ["jack","lixisan","fala"] lixisan
mali ["jack","lixisan","fala"] fala
Time taken: 0.046 seconds, Fetched: 6 row(s)
LATERAL VIEW explode(emps) tmp as empeeName 其中as后面的名字指定被拆分数组的字段名字为empeeName;
2、Hive复杂数据类型之Map
创建表语句: CREATE TABLE `userinfo`( `name` string, `info` map<string,string>) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION 'hdfs://node:9000/user/hive/warehouse/daxin.db/userinfo' 插入数据: insert into userinfo select "daxin",map("addr","liaoning") from ptab limit 1;
插入数据时候注意,map的key与value之间使用逗号分隔,而不是使用冒号!!!
hive> select * from userinfo;
OK
userinfo.name userinfo.info
daxin {"addr":"liaoning"}
Time taken: 0.04 seconds, Fetched: 1 row(s)
带有where条件查询:
hive> select * from userinfo where info['addr']="liaoning";
OK
userinfo.name userinfo.info
daxin {"addr":"liaoning"}
Time taken: 0.041 seconds, Fetched: 1 row(s)
hive> insert into userinfo select "zhansan",map("addr","beijing","sex","boy","word","coder") from ptab limit 1;
Query ID = liuguangxin_20181102201144_b74fcc0e-1c2d-49e6-9268-bdc97e79ba86
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1541155477807_0005, Tracking URL = http://10.12.141.138:8099/proxy/application_1541155477807_0005/
Kill Command = /Users/liuguangxin/bigdata/hadoop/bin/hadoop job -kill job_1541155477807_0005
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2018-11-02 20:11:50,234 Stage-1 map = 0%, reduce = 0%
2018-11-02 20:11:55,370 Stage-1 map = 100%, reduce = 0%
2018-11-02 20:11:59,478 Stage-1 map = 100%, reduce = 100%
Ended Job = job_1541155477807_0005
Loading data to table daxin.userinfo
Table daxin.userinfo stats: [numFiles=2, numRows=2, totalSize=60, rawDataSize=58]
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 HDFS Read: 9552 HDFS Write: 110 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
_c0 _c1
Time taken: 15.827 seconds
hive> select * from userinfo where info['addr1']="liaoning"; //当map中不存在key时候不会报错,只会查询不到数据
OK
userinfo.name userinfo.info
Time taken: 0.04 seconds
查看信息个数:
hive > select size(info) as infoCount,* from userinfo ;
OK
infocount userinfo.name userinfo.info
1 daxin {"addr":"liaoning"}
3 zhansan {"addr":"beijing","sex":"boy","word":"coder"}
Time taken: 0.045 seconds, Fetched: 2 row(s)
3、hive复杂数据类型Map
CREATE TABLE `fixuserinfo`( `name` string, `info` struct<addr:string,mail:string,sex:string>) COMMENT 'the count of info is fixed' ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION 'hdfs://node:9000/user/hive/warehouse/daxin.db/fixuserinfo'
插入数据:
参考一下:https://blog.csdn.net/xiaolang85/article/details/51330634
创建数据表
CREATE TABLE test(id int,course struct<course:string,score:int>)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
COLLECTION ITEMS TERMINATED BY ',';
数据
1 english,80
2 math,89
3 chinese,95
入库
LOAD DATA LOCAL INPATH '/home/hadoop/test.txt' OVERWRITE INTO TABLE test;
查询
hive> select * from test;
OK
1 {"course":"english","score":80}
2 {"course":"math","score":89}
3 {"course":"chinese","score":95}
Time taken: 0.275 seconds
hive> select course from test;
{"course":"english","score":80}
{"course":"math","score":89}
{"course":"chinese","score":95}
Time taken: 44.968 seconds
select t.course.course from test t;
english
math
chinese
Time taken: 15.827 seconds
hive> select t.course.score from test t;
80
89
95
Time taken: 13.235 seconds
4、数组查询数据的 : LATERAL VIEW explode(emps) tmp as empeeName使用:
对某一个字段进行展开,并将该字段指定一个名字,对于一个 表有多个array类型的表而言,每一条记录展开之后产生的记录数是该行记录的展开数组个数相乘,例如:
CREATE TABLE `empinfo`( `name` string, `emps` array<string>, `sal` array<string>);
表中的数据:
empinfo.name empinfo.emps empinfo.sal
daxin ["zhangsan","lisi","wangwu"] ["99999","88888","999999"]
mali ["11","22","33"] ["6666","7777","8888"]
查询语句:
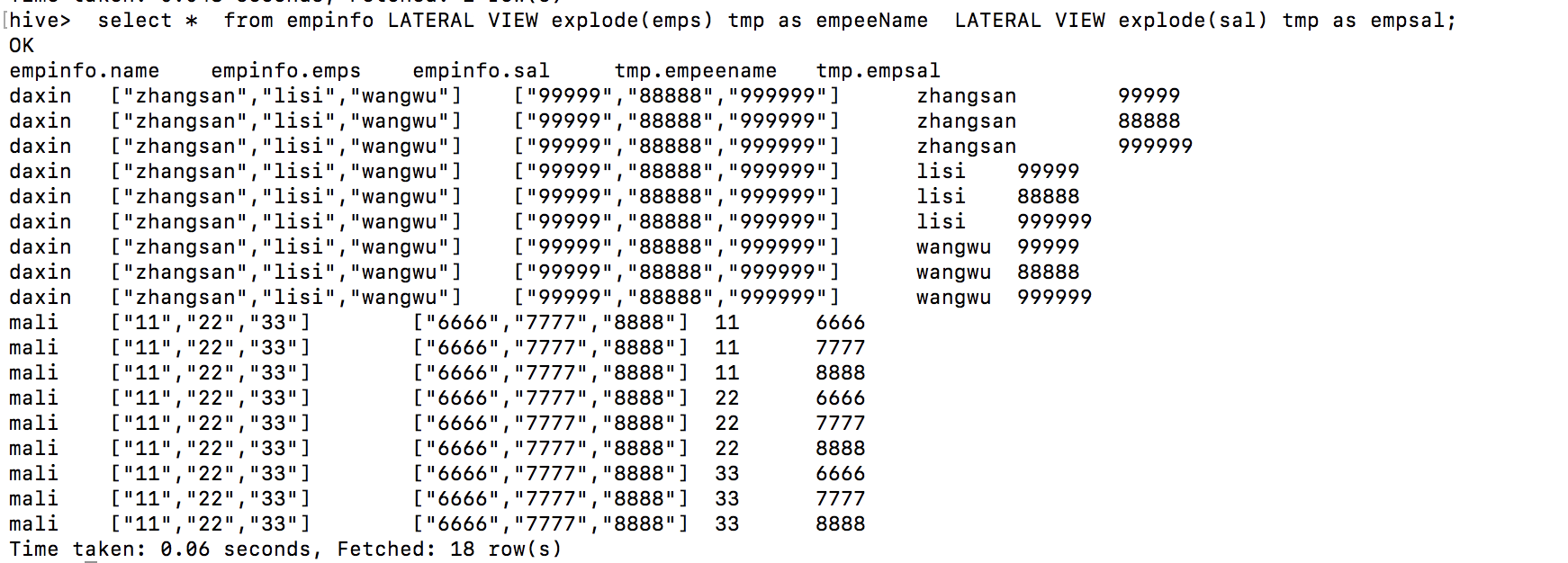
按照emps与sal进行展开,对与第一行数据的每一个数组都是3个元素,因此展开之后变成9条数据!第二行同理,所以共计18行记录!!!
5、Hive在线查看函数文档

参考官网:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF
参考:https://blog.csdn.net/wangtao6791842/article/details/37966035

 浙公网安备 33010602011771号
浙公网安备 33010602011771号