Spark排序与去重遇见的问题
答案:
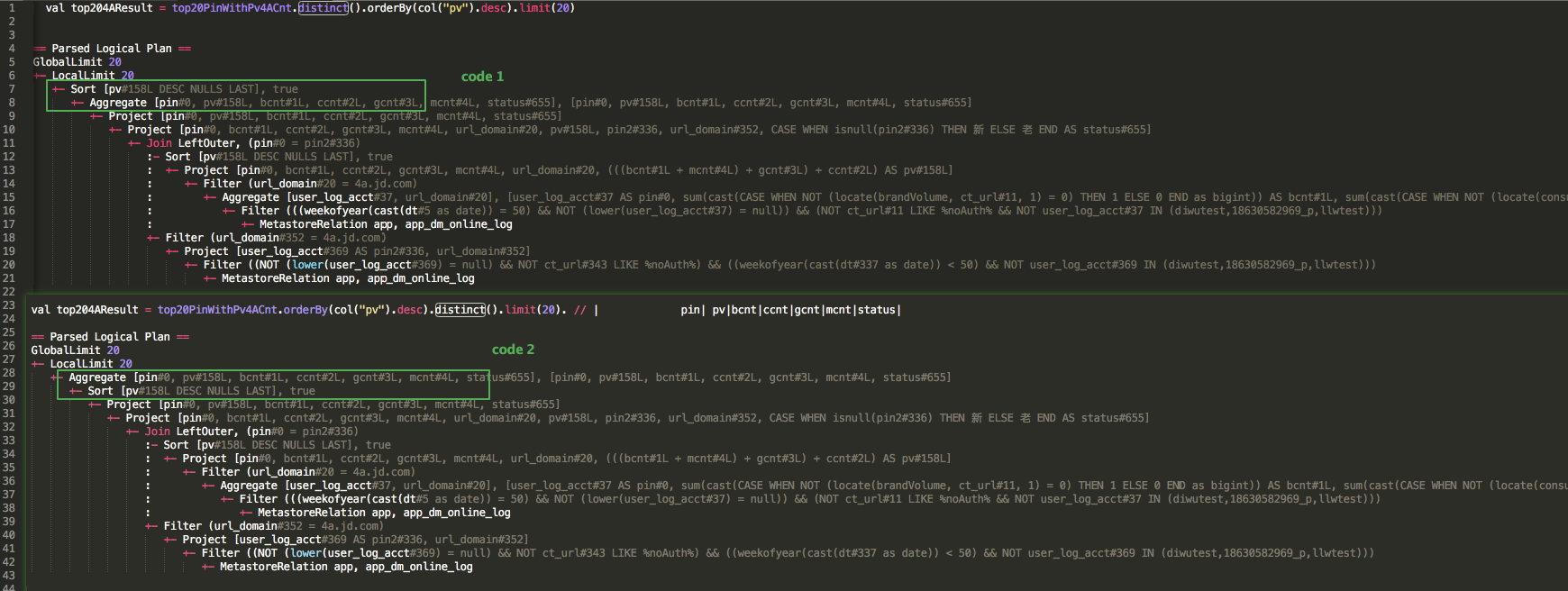
Spark的distinct是通过聚集去重的,可以简单理解为group by去重;
代码1:是先去重之后再排序取limit20是正确的,
代码2:是先排序之后再到各个节点进行去重之后再limit20,此时去重之后是无序的!!!!
有时候测试时候是单个节点计算体现不出来问题2存在的问题,因此单个节点小数据量的话又是一个分区则无法体现问题2,但是一但提交到集群多个节点运行时候问题就会暴露出来!!!!!
答案:
Spark的distinct是通过聚集去重的,可以简单理解为group by去重;
代码1:是先去重之后再排序取limit20是正确的,
代码2:是先排序之后再到各个节点进行去重之后再limit20,此时去重之后是无序的!!!!
有时候测试时候是单个节点计算体现不出来问题2存在的问题,因此单个节点小数据量的话又是一个分区则无法体现问题2,但是一但提交到集群多个节点运行时候问题就会暴露出来!!!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号